Docker部署hadoop 和使用docker构建spark运行环境(全网最详细教程)
Docker部署hadoop 和使用docker构建spark运行环境(全网最详细教程)
首先查看版本环境(docker中没有下载docker和docker-compose的可以看我上一篇博客Docker综合实验(本文主要内容:1.安装配置docker 2.安装配置docker compose 3.部署docker应用))
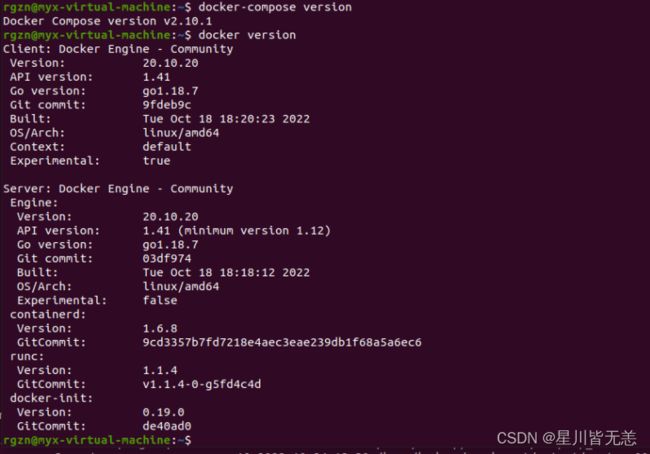
查看docker和docker-compose版本:
docker versiondocker-compose version
OK,环境没问题,我们正式开始Docker中部署hadoop
更新系统
sudo apt update
sudo apt upgrade
国内加速镜像下载修改仓库源
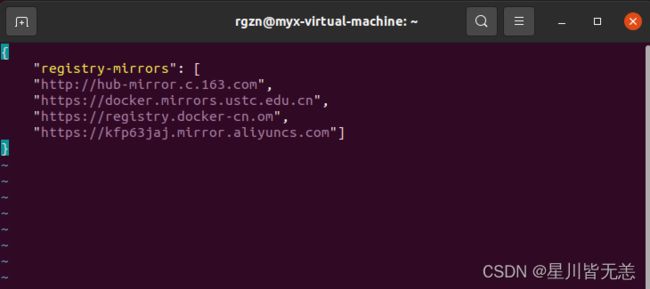
创建或修改 /etc/docker/daemon.json 文件
sudo vi /etc/docker/daemon.json{
"registry-mirrors": [
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn",
"https://registry.docker-cn.com",
"https://kfp63jaj.mirror.aliyuncs.com"]
}
重载docker让CDN配置生效
sudo systemctl daemon-reloadsudo systemctl restart docker
抓取ubuntu 20.04的镜像作为基础搭建hadoop环境
sudo docker pull ubuntu:20.04
使用该ubuntu镜像启动,填写具体的path替代
sudo docker run -it -v
例如
sudo docker run -it -v ~/hadoop/build:/home/hadoop/build ubuntu 
容器启动后,会自动进入容器的控制台
在容器的控制台安装所需软件
apt-get update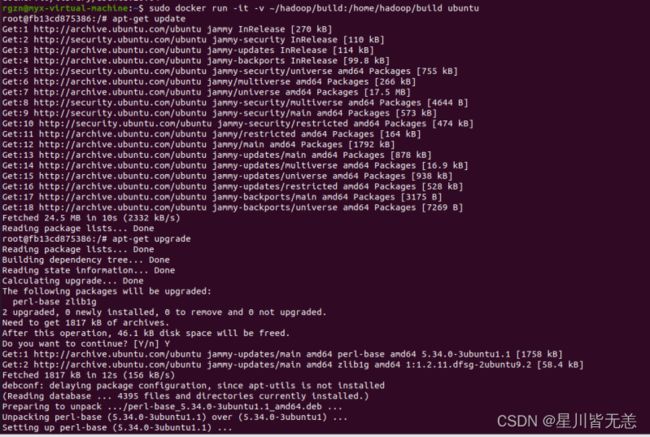
apt-get upgrade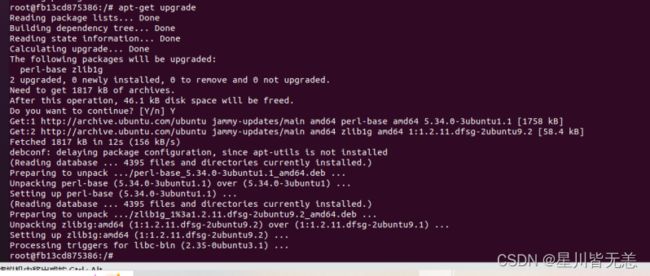
安装所需软件
apt-get install net-tools vim openssh-server 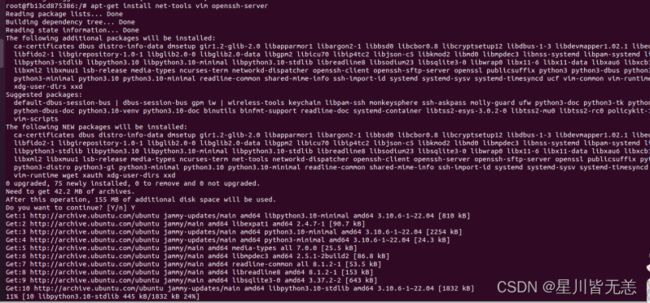
/etc/init.d/ssh start让ssh服务器自动启动
vi ~/.bashrc在文件的最末尾按O进入编辑模式,加上:
/etc/init.d/ssh start 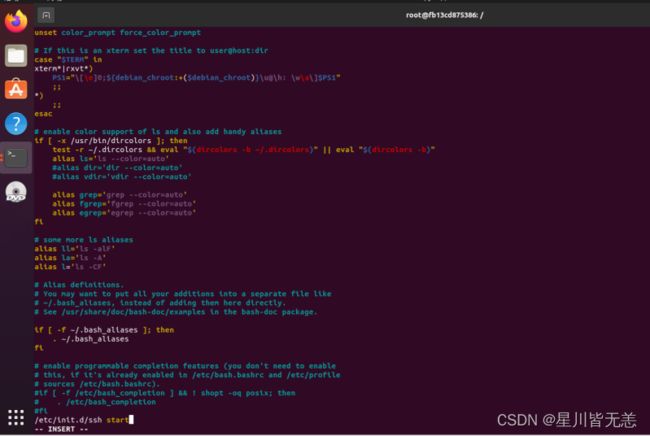
按ESC返回命令模式,输入:wq保存并退出。
让修改即刻生效
source ~/.bashrc
配置ssh的无密码访问
ssh-keygen -t rsa连续按回车

cd ~/.sshcat id_rsa.pub >> authorized_keys![]()
进入docker中ubuntu里面的容器
docker start 11f9454b301fdocker exec -it clever_gauss bash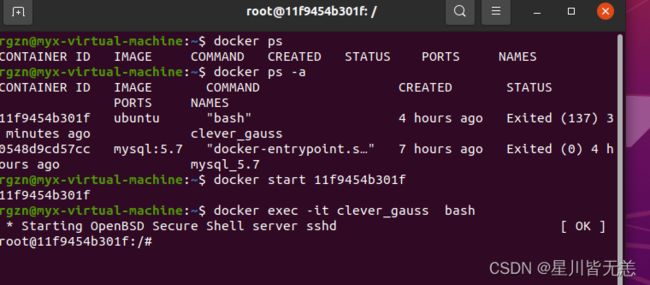
安装JDK 8
hadoop 3.x目前仅支持jdk 7, 8
apt-get install openjdk-8-jdk在环境变量中引用jdk,编辑bash命令行配置文件
vi ~/.bashrc在文件的最末尾加上
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
export PATH=$PATH:$JAVA_HOME/bin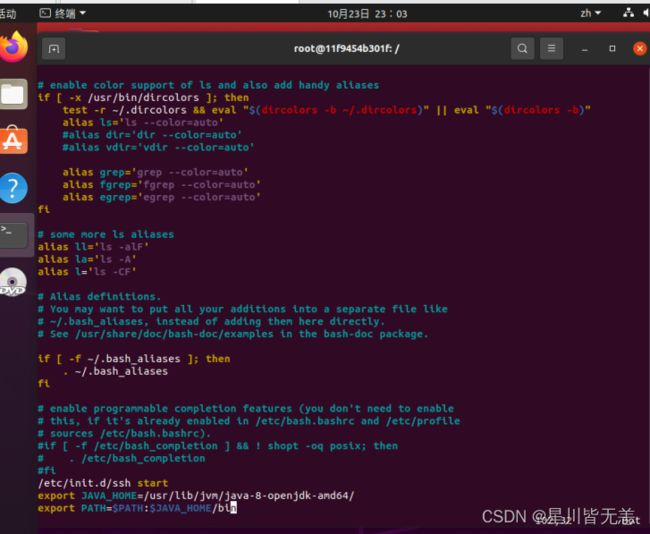
让jdk配置即刻生效
source ~/.bashrc![]()
测试jdk正常运作
java -version
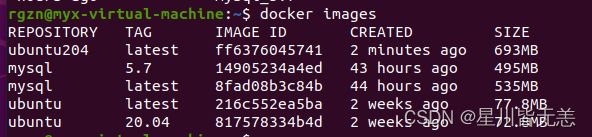
将当前容器保存为镜像
sudo docker commit
sudo docker commit 11f9454b301f ubuntu204 #我的是ubuntu204
可以看到该镜像已经创建成功,下次需要新建容器时可直接使用该镜像
注意!!!此过程的两个相关路径如下(不要搞混了):
下载hadoop,下面以3.2.3为例
https://hadoop.apache.org/releases.html
cd ~/hadoop/buildwget https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz(这种方法能下载但是会出现下载的包大小不对,我们可以用第二种方法)
方法二:
在自己电脑浏览器输入下载https://dlcdn.apache.org/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz
下载到自己电脑上 通过winscp上传到虚拟机中
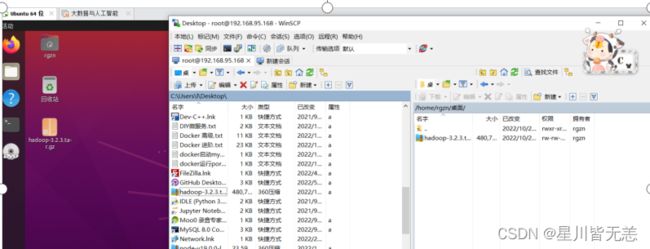
然后有安装包的目录打开终端, 输入
sudo mv hadoop-3.2.3.tar.gz ~/hadoop/build移动文件到目录 ~/hadoop/build

在容器控制台上解压hadoop(就是之前创建的容器的控制台,不是自己的控制台!
docker start 11f9454b301fdocker exec -it clever_gauss bashcd /home/hadoop/buildtar -zxvf hadoop-3.2.3.tar.gz -C /usr/local![]()
安装完成了,查看hadoop版本
cd /usr/local/hadoop-3.2.3./bin/hadoop version
为hadoop指定jdk位置
vi etc/hadoop/hadoop-env.sh![]()
查找到被注释掉的JAVA_HOME配置位置,更改为刚才设定的jdk位置
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/hadoop联机配置
配置core-site.xml文件
vi etc/hadoop/core-site.xml加入:
hadoop.tmp.dir
file:/usr/local/hadoop-3.2.3/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://master:9000
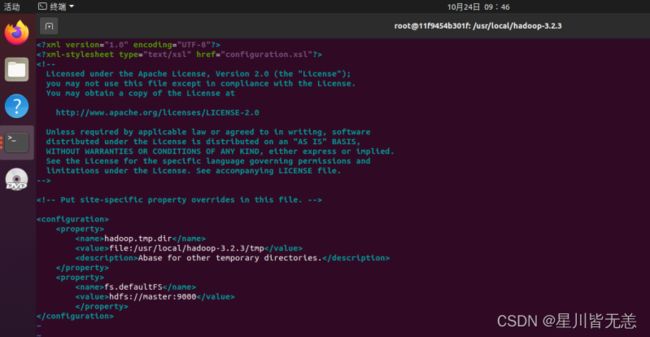
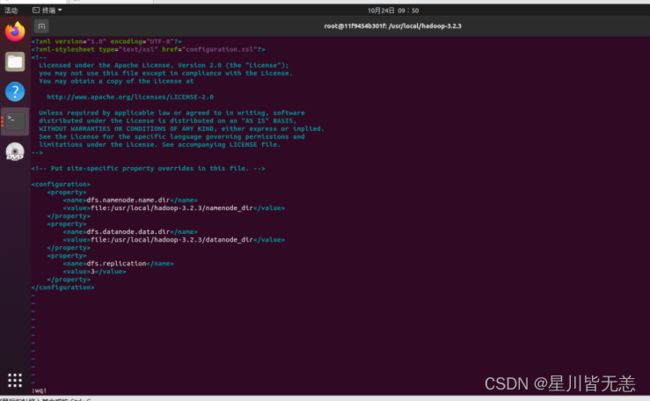
配置hdfs-site.xml文件
vi etc/hadoop/hdfs-site.xml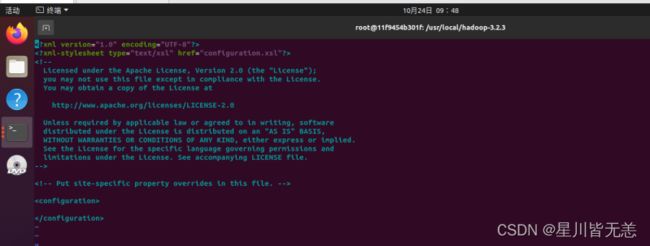
加入
dfs.namenode.name.dir file:/usr/local/hadoop-3.2.3/namenode_dir dfs.datanode.data.dir file:/usr/local/hadoop-3.2.3/datanode_dir dfs.replication 3
MapReduce配置
该配置文件的定义:
https://hadoop.apache.org/docs/r
配置mapred-site.xml文件
vi etc/hadoop/mapred-site.xml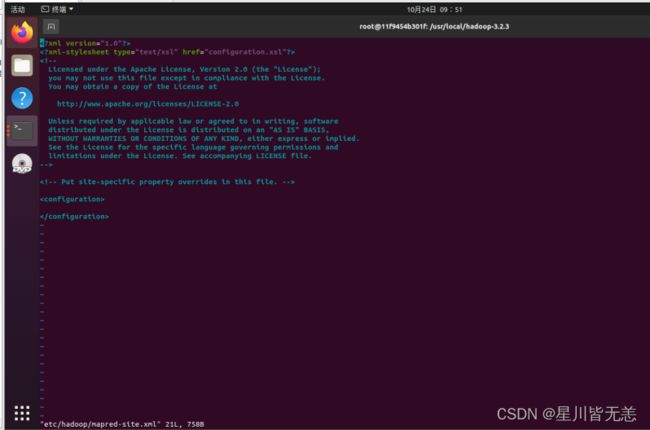
加入:
mapreduce.framework.name
yarn
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.map.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}
mapreduce.reduce.env
HADOOP_MAPRED_HOME=${HADOOP_HOME}

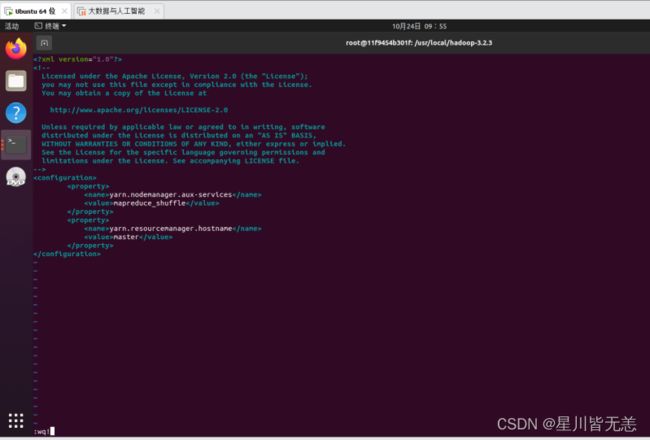
配置yarn-site.xml文件
vi etc/hadoop/yarn-site.xml
加入
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
master
服务启动权限配置
配置start-dfs.sh与stop-dfs.sh文件
vi sbin/start-dfs.sh 和 vi sbin/stop-dfs.shvi sbin/start-dfs.shHDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root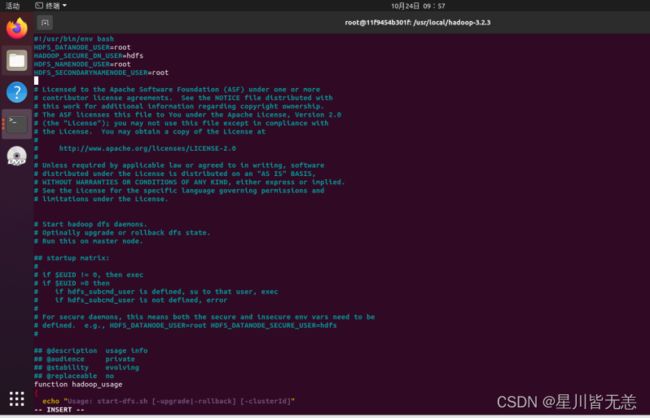
继续修改配置文件
vi sbin/stop-dfs.shHDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root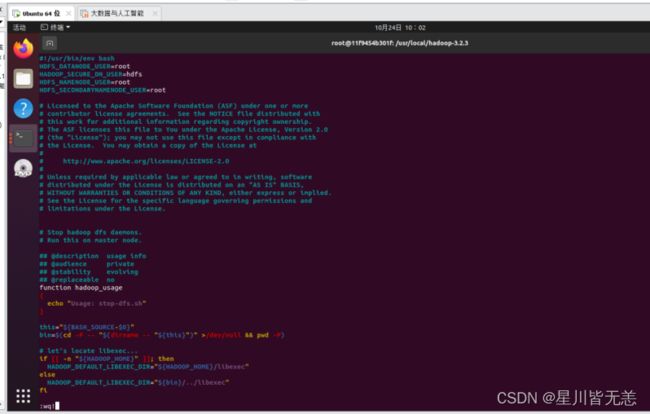
配置start-yarn.sh与stop-yarn.sh文件
vi sbin/start-yarn.sh 和 vi sbin/stop-yarn.shvi sbin/start-yarn.shYARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root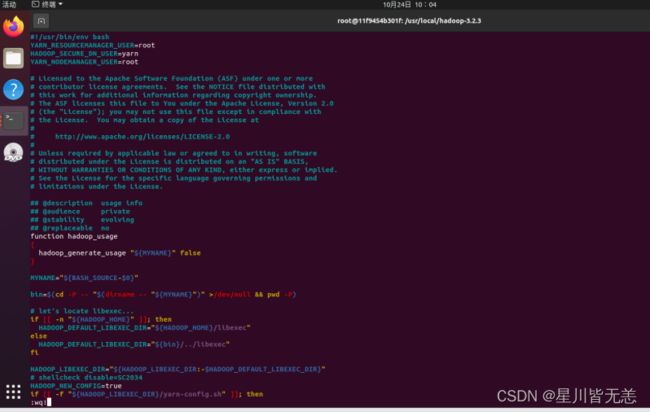
vi sbin/stop-yarn.shYARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root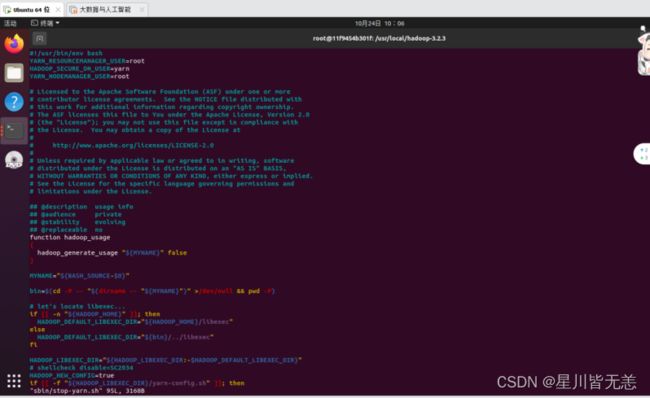
核心文件一定不能配错,否则后面会出现很多问题!
配置完成,保存镜像
docker ps
docker commit 11f9454b301f ubuntu-myx保存的镜像名为 ubuntu-myx


启动hadoop,并进行网络配置
打开三个宿主控制台,启动一主两从三个容器
master
打开端口映射:8088 => 8088
sudo docker run -p 8088:8088 -it -h master --name master ubuntu-myx
启动节点worker01
sudo docker run -it -h worker01 --name worker01 ubuntu-myx
节点worker02
sudo docker run -it -h worker02 --name worker02 ubuntu-myx
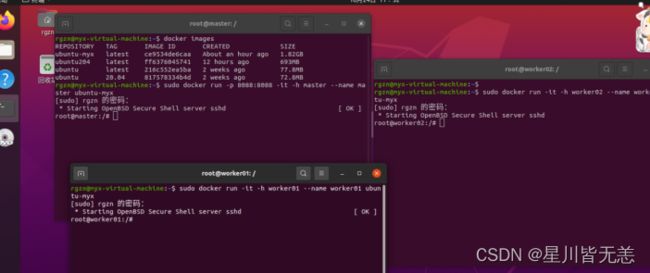
分别打开三个容器的/etc/hosts,将彼此的ip地址与主机名的映射信息补全(三个容器均需要如此配置)
vi /etc/hosts使用以下命令查询ip
ifconfig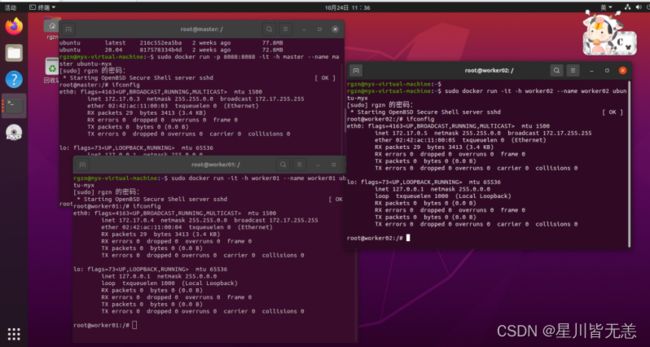
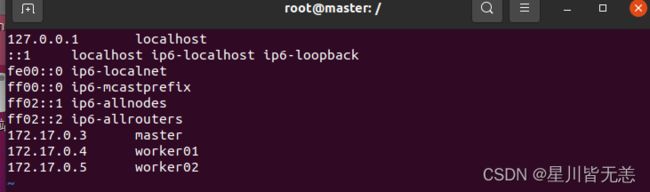
添加信息(每次容器启动该文件都需要调整)
172.17.0.3 master
172.17.0.4 worker01
172.17.0.5 worker02
检查配置是否有效
ssh masterssh worker01ssh worker02master 连接worker01节点successfully:
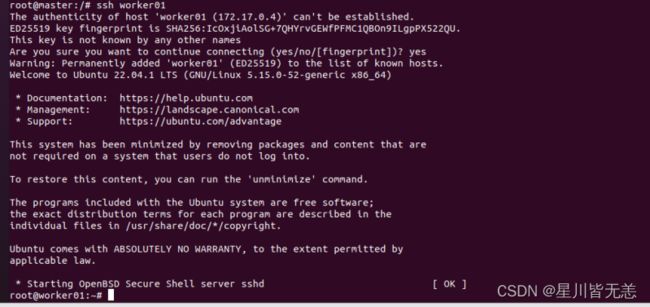
worker01节点连接master 成功:
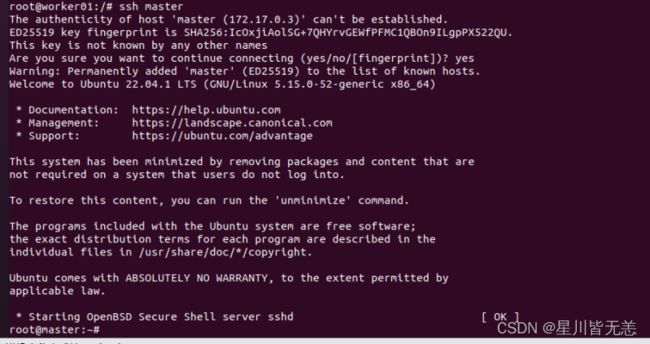
worker02连接worker01节点successfully:

在master容器上配置worker容器的主机名
cd /usr/local/hadoop-3.2.3vi etc/hadoop/workers
删除localhost,加入
worker01
worker02
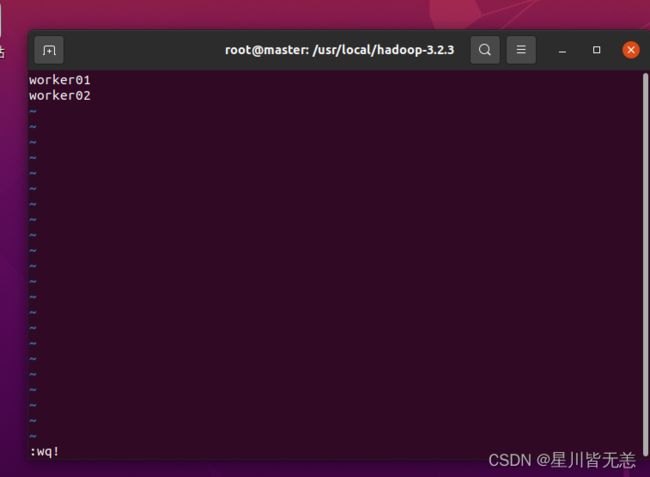
网络配置完成
启动hadoop
在master主机上
cd /usr/local/hadoop-3.2.3./bin/hdfs namenode -format正常启动
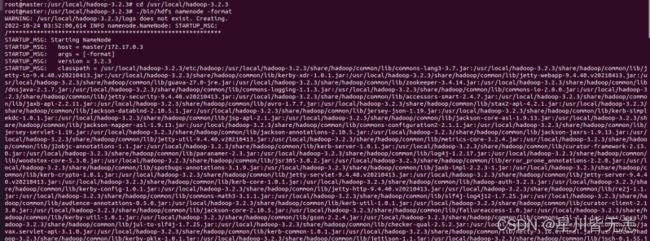
启动服务
./sbin/start-all.sh
效果如下表示正常
在hdfs上建立一个目录存放文件
假设该目录为:/home/hadoop/input
./bin/hdfs dfs -mkdir -p /home/hadoop/input./bin/hdfs dfs -put ./etc/hadoop/*.xml /home/hadoop/input![]()
查看分发复制是否正常
./bin/hdfs dfs -ls /home/hadoop/input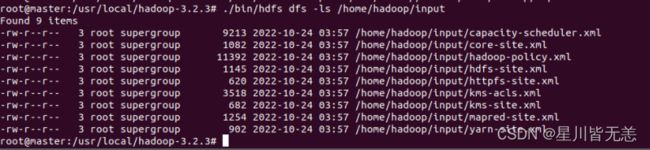
运行案例:
在hdfs上建立一个目录存放文件
例如
./bin/hdfs dfs -mkdir -p /home/hadoop/wordcount把文本程序放进去
./bin/hdfs dfs -put hello /home/hadoop/wordcount查看分发情况
./bin/hdfs dfs -ls /home/hadoop/wordcount

运行MapReduce自带wordcount的示例程序(自带的样例程序运行不出来,可能是虚拟机性能的问题,这里就换成了简单的wordcount程序)
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.3.jar wordcount /home/hadoop/wordcount /home/hadoop/wordcount/output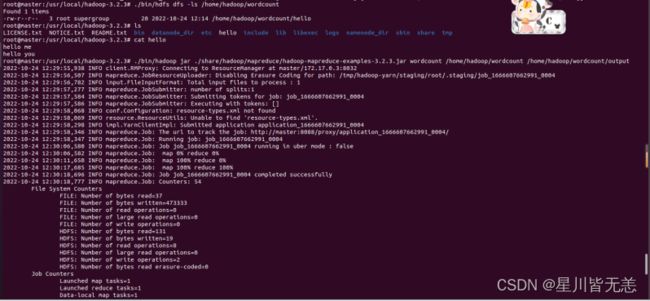
运行成功:

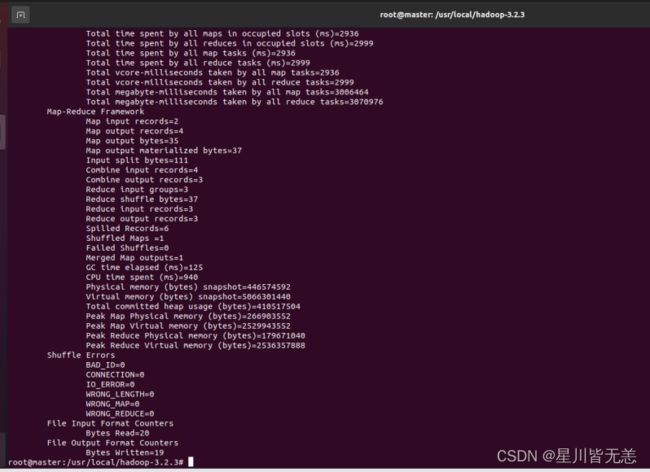
运行结束后,查看输出结果
./bin/hdfs dfs -ls /home/hadoop/wordcount/output./bin/hdfs dfs -cat /home/hadoop/wordcount/output/*
至此,Docker部署hadoop成功!跟着步骤走一般都没有什么问题。
下面我们使用docker构建spark运行环境
<使用docker构建spark运行环境>
使用docker hub查找我们需要的镜像
参考 Docker Hub
curl -LO https://raw.githubusercontent.com/bitnami/containers/main/bitnami/spark/docker-compose.yml
提示:curl: (7) Failed to connect to raw.githubusercontent.com port 443: Connection refused
![]()
原因应该是国外的ip,撞墙了 直接看解决方案吧
解决方案:
1、打开网站,https://www.ipaddress.com/,在此网站中查询一下 raw.githubusercontent.com对应的IP 地址
到这个网站查找这个域名绑定的ip

Vi etc/hosts
末尾加上:
185.199.108.133 raw.githubusercontent.com
curl运行成功

curl -LO https://raw.githubusercontent.com/bitnami/containers/main/bitnami/spark/docker-compose.yml
docker-compose up


安装 Spark 的 docker 镜像
docker pull bitnami/spark:latest
docker pull bitnami/spark:[TAG]
 git clone出现 fatal: unable to access ‘https://github.com/...‘的解决方法
git clone出现 fatal: unable to access ‘https://github.com/...‘的解决方法

查阅了一些资料,发现需要在hosts文件中添加映射。
vi /etc/hosts在hosts文件中加入两行
140.82.113.4 github.com
140.82.113.4 www.github.com
git clone

 cd bitnami/APP/VERSION/OPERATING-SYSTEM
cd bitnami/APP/VERSION/OPERATING-SYSTEM
找到对应目录:
cd /home/rgzn/containers/bitnami//spark/3.2/debian-11

# . 表示当前目录
docker build -t bitnami/spark:latest .参数说明:
-t :指定要创建的目标镜像名
. :Dockerfile 文件所在目录,可以指定Dockerfile 的绝对路径
找到包含 Dockerfile 的目录并执行命令来自己构建映像

使用yml部署文件部署spark环境
spark.yml文件可以从本机编辑好再上传的虚拟机或服务器。spark.yml文件内容如下:
version: '3.8'
services:
spark-master:
image: bde2020/spark-master
container_name: spark-master
ports:
- "8080:8080"
- "7077:7077"
volumes:
- ~/spark:/data
environment:
- INIT_DAEMON_STEP=setup_spark
spark-worker-1:
image: bde2020/spark-worker:latest
container_name: spark-worker-1
depends_on:
- spark-master
ports:
- "8081:8081"
volumes:
- ~/spark:/data
environment:
- "SPARK_MASTER=spark://spark-master:7077"
spark-worker-2:
image: bde2020/spark-worker:latest
container_name: spark-worker-2
depends_on:
- spark-master
ports:
- "8082:8081"
volumes:
- ~/spark:/data
environment:
- "SPARK_MASTER=spark://spark-master:7077"
使用yml部署文件部署spark环境
cd /usr/local/bin创建文件sudo vim spark.yml
sudo chmod 777 spark.yml
在spark.yml文件所在的目录下,执行命令:
sudo docker-compose -f spark.yml up -d![]()
查看容器创建与运行状态
sudo docker ps
对输出进行格式化
sudo docker ps --format '{{.ID}} {{.Names}}'
使用浏览器查看master的web ui界面
127.0.0.1:8080

http://192.168.95.171:50070

进入spark-master容器
sudo docker exec -it
sudo docker exec -it 98600cfa9ba7 /bin/bash![]()
查询spark环境,安装在/spark下面。
ls /spark/bin![]()
进入spark-shell
/spark/bin/spark-shell --master spark://spark-master:7077 --total-executor-cores 8 --executor-memory 2560m或者
/spark/bin/spark-shell
进入浏览器查看spark-shell的状态

测试:创建RDD与filter处理
创建一个RDD
val rdd=sc.parallelize(Array(1,2,3,4,5,6,7,8))
打印rdd内容
rdd.collect() 查询分区数
查询分区数
rdd.partitions.size
选出大于5的数值
val rddFilter=rdd.filter(_ > 5)
打印rddFilter内容
rddFilter.collect()
退出spark-shell
:quit
运行案列成功!
以上就是Docker部署hadoop 和使用docker构建spark运行环境,我也是为这教程准备了好久,环境没啥问题的话按着操作基本都能完成docker部署hadoop和运行spark,祝大家一切顺利!
“与其临渊羡鱼,不如退而结网”