pytorch_cifar10 学习记录(91%准确率)
目录
一、首次尝试深度学习
1.1训练参数
网络结构:
1.2训练结果
1.3 总结
二、修改网络和学习率,初次使用GPU炼丹(kaggle线上炼丹)
2.1训练参数
三、cifar10数据增强后进行炼丹
3.1 参数设置
3.2训练记录
3.2.1 0-100轮训练
3.2.2 100-150轮训练
3.2.3 150-200轮训练
四、加深网络(kaggle 使用 tensorboard)
五、使用残差网络
一、首次尝试深度学习
1.1训练参数
网络结构:
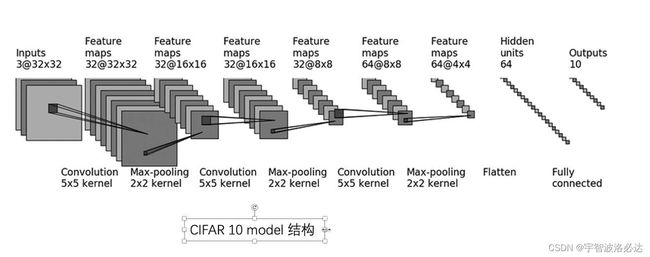
注:在每个Convolution层后面加了Relu
学习率:0.001
优化器:SGD
训练:使用CPU(我电脑没有独显。。寄)训练约30h
1.2训练结果
在test集上的准确率为59.33%
之后我把调用摄像头,使用该模型分辨图像,发现识别还是经常出现错误。
比如下图的“猫猫车”:
1.3 总结
学习率设置的太低了点,再加上我使用CPU训练,导致炼丹堪称龟速。
二、修改网络和学习率,初次使用GPU炼丹(kaggle线上炼丹)
2.1训练参数
网络结构:看了一些帖子,发现有人把最后的全连接层从两个改成了三个,训练结果有了进步。
Flatten(), # 7 Flatten层
Linear(1024, 256), # 8 全连接层
Linear(256, 64), # 8 全连接层
Linear(64, 10) # 9 全连接层所以我也这样改了。
理由是在其他帖子上看到的:
“ 我们知道全连接层,卷积层都是线性运算,所以他们后面都要加激活函数引进非线性。
但是只用一层全连接层+激活函数的话由于全连接层的参数量太大,没办法解决非线性的问题。(其实都是猜测而已,毕竟玄学炼丹)
所以多加几层。”
学习率:改为了动态的,从0.05-0.001之间递减
learning_rate_max = 0.05
learning_rate_min = 0.001
learning_rate = learning_rate_max - (learning_rate_max - learning_rate_min) * (i + 1)/epoch训练:注册了个kaggle的号,不得不说真的好用,一周免费用GPU30多个小时,体验了一波GPU炼丹,不得不说真的爽。大概用了40min,训练了120轮,最后发现test的准确率最多也就73%,接着训练发现虽然loss在飞快的下降,但是准确率也在下降,下降到69%的时候,我担心是过拟合了,所以就终止了炼丹。
2.2总结
训练时间过长,可能会出现过拟合的情况。
看了一些帖子,他们有人能用把准确率提高到90+,我也第一次看到了数据增强这个词。所以决定使用数据增强后,再进行炼丹。
我对数据增强有个疑问,为什么在数据集的transforms上加改动就行了?怎么创建新照片?新照片的label咋办?为啥数据增强后,数据集长度没变?
最后才明白数据增强没有增强数据集的长度,而是增强了特征。
(4 封私信 / 68 条消息) 请问使用pytorch进行数据增强之后数据量是否会增加? - 知乎 (zhihu.com) https://www.zhihu.com/question/535402700这个帖子完美的回答了我的疑问
https://www.zhihu.com/question/535402700这个帖子完美的回答了我的疑问
三、cifar10数据增强后进行炼丹
3.1 参数设置
train_transforms = transforms.Compose([
transforms.ToTensor(), # 转化为tensor类型
# 从[0,1]归一化到[-1,1]
transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]),
transforms.RandomHorizontalFlip(), # 随机水平镜像
transforms.RandomErasing(scale=(0.04, 0.2), ratio=(0.5, 2)), # 随机遮挡
transforms.RandomCrop(32, padding=4), # 随机裁剪
])
test_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
训练集经过归一化、水平镜像、遮挡、裁剪的步骤后,特征获得增强
3.2训练记录
3.2.1 0-100轮训练
学习率:0.005-0.001递减
最后测试集的正确率是78%
3.2.2 100-150轮训练
学习率:0.005-0.001递减
最后测试集的正确率是80.1%
训练期间,发现训练初期正确率一直在大范围波动(5%左右),所以猜测可能是初期的学习率高的原因
3.2.3 150-200轮训练
学习率:0.002-0.001递减
最后测试集的正确率是81.24%
四、加深网络(kaggle 使用 tensorboard)
之前的网络有三次卷积,我改成了四次。(下面注释的是之前的三层网络)
class Model(Module):
def __init__(self):
super(Model, self).__init__()
self.neuralnet = Sequential(
Conv2d(in_channels=3, out_channels=64, kernel_size=(3, 3), padding=1),
BatchNorm2d(64),
Conv2d(in_channels=64, out_channels=64, kernel_size=(3, 3), padding=1),
BatchNorm2d(64),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, ceil_mode=False),
Conv2d(in_channels=64, out_channels=128, kernel_size=(3, 3), padding=1),
BatchNorm2d(128),
Conv2d(in_channels=128, out_channels=128, kernel_size=(3, 3), padding=1),
BatchNorm2d(128),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, ceil_mode=False),
Conv2d(in_channels=128, out_channels=256, kernel_size=(3, 3), padding=1),
BatchNorm2d(256),
Conv2d(in_channels=256, out_channels=256, kernel_size=(3, 3), padding=1),
BatchNorm2d(256),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, ceil_mode=False),
Conv2d(in_channels=256, out_channels=512, kernel_size=(3, 3), padding=1),
BatchNorm2d(512),
Conv2d(in_channels=512, out_channels=512, kernel_size=(3, 3), padding=1),
BatchNorm2d(512),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, ceil_mode=False),
# Conv2d(in_channels=3, out_channels=32, kernel_size=(5, 5), padding=2),
# ReLU(inplace=True),
# MaxPool2d(kernel_size=2, ceil_mode=True),
# Conv2d(in_channels=32, out_channels=32, kernel_size=(5, 5), padding=2),
# ReLU(inplace=True),
# MaxPool2d(kernel_size=2, ceil_mode=True),
# Conv2d(in_channels=32, out_channels=64, kernel_size=(5, 5), padding=2),
# ReLU(inplace=True),
# MaxPool2d(kernel_size=2, ceil_mode=True),
#
Flatten(), # 7 Flatten层
Linear(2048, 256), # 8 全连接层
Linear(256, 64), # 8 全连接层
Linear(64, 10) # 9 全连接层
)
def forward(self, input):
out = self.neuralnet(input)
return out网络结构如下:
(图来自他人的文章)(41条消息) Pytorch实战:8层神经网络实现Cifar-10图像分类验证集准确率94.71%_雪地(>^ω^<)的博客-CSDN博客_cifar10验证集

之后为了可视化训练过程,我想在kaggle上使用tensorboard,但是发现打不开网站,所以我把Loss和accuracy保存成了numpy类型,以.npy文件保存,下载到本地后再使用tensorboard就可以了。
之后训练了200轮,学习率在0.01-0.001之间线性递减
loss和accuracy如下:
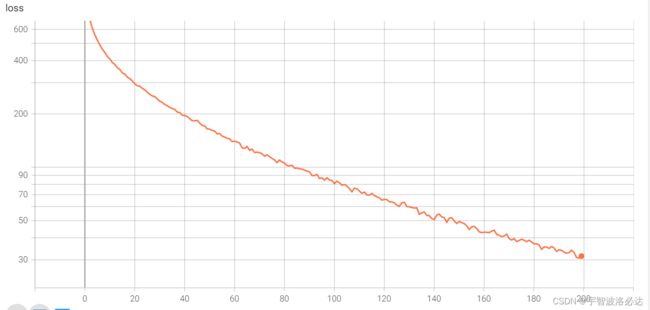
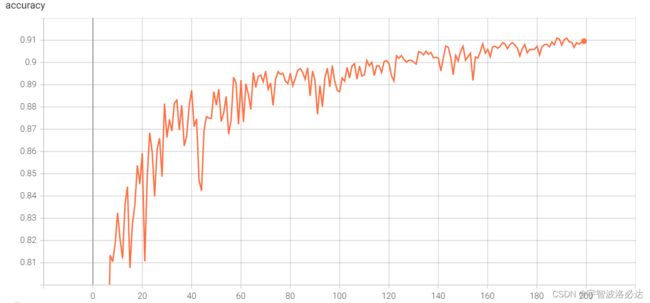
最后的准确率达到了91%左右
发现曲线似乎没有完全收敛,还有进步空间?再去训练看一看。
但是调用摄像头,使用准确率91%的网络进行训练,却发现实际效果实在是一般
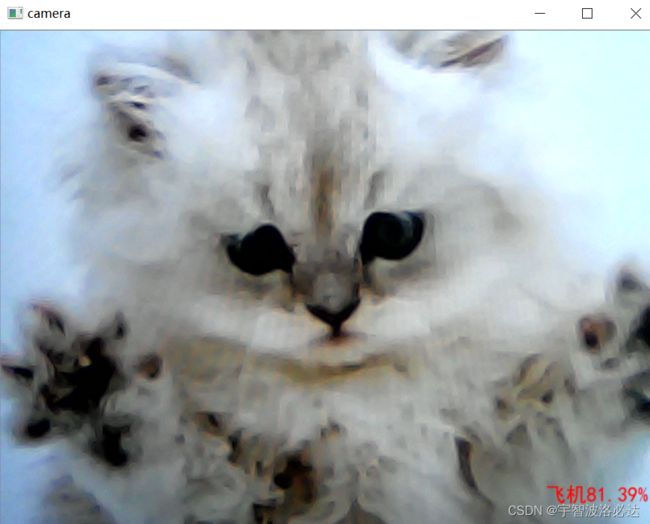
搜了一下,网上说可能是过拟合,需要加drop层。所以我加在了flatten层后面。设置概率为0.4。
又得从头训练咯。
五、使用残差网络
猜测部署效果不好可能是过拟合的原因,在询问了几个朋友之后,我决定尝试在网络中加入残差模块。
重写网络模型:
# @Time : 2022/9/4 9:45
# @Author :lgl
# @e-mail :[email protected]
# @Time : 2022/8/25 14:43
import torch
from torch.nn import Module, Sequential, Conv2d, MaxPool2d, Flatten, Linear, ReLU, BatchNorm2d, Dropout
from torch.utils.data import DataLoader
class Conv_Block(Module):
def __init__(self, inchannel, outchannel, res=True):
super(Conv_Block, self).__init__()
self.res = res # 是否带残差连接
self.left = Sequential(
Conv2d(inchannel, outchannel, kernel_size=(3, 3), padding=1, bias=False),
BatchNorm2d(outchannel),
ReLU(inplace=True),
Conv2d(outchannel, outchannel, kernel_size=(3, 3), padding=1, bias=False),
BatchNorm2d(outchannel),
)
self.shortcut = Sequential(Conv2d(inchannel, outchannel, kernel_size=(1,1), bias=False),
BatchNorm2d(outchannel))
self.relu = Sequential(
ReLU(inplace=True))
def forward(self, x):
out = self.left(x)
if self.res:
out += self.shortcut(x)
out = self.relu(out)
return out
class Res_Model(Module):
def __init__(self, res=True):
super(Res_Model, self).__init__()
self.block1 = Conv_Block(inchannel=3, outchannel=64)
self.block2 = Conv_Block(inchannel=64, outchannel=128)
self.block3 = Conv_Block(inchannel=128, outchannel=256)
self.block4 = Conv_Block(inchannel=256, outchannel=512)
# 构建卷积层之后的全连接层以及分类器:
self.classifier = Sequential(Flatten(), # 7 Flatten层
Dropout(0.4),
Linear(2048, 256), # 8 全连接层
Linear(256, 64), # 8 全连接层
Linear(64, 10)) # 9 全连接层 ) # fc,最终Cifar10输出是10类
self.relu = ReLU(inplace=True)
self.maxpool = Sequential(MaxPool2d(kernel_size=2)) # 1最大池化层
def forward(self, x):
out = self.block1(x)
out = self.maxpool(out)
out = self.block2(out)
out = self.maxpool(out)
out = self.block3(out)
out = self.maxpool(out)
out = self.block4(out)
out = self.maxpool(out)
out = self.classifier(out)
return out
res_neural_networks = Res_Model()
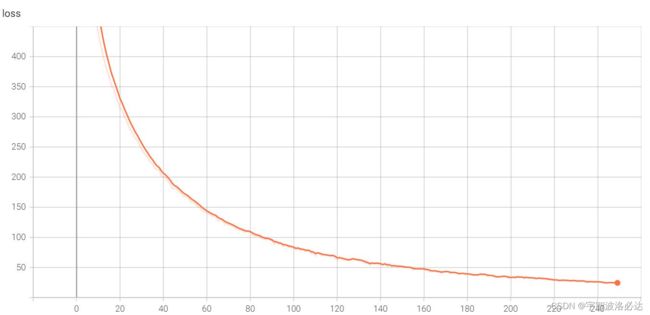
之后在kaggle上进行训练,最终准确率为91.25%
准确率变化情况:
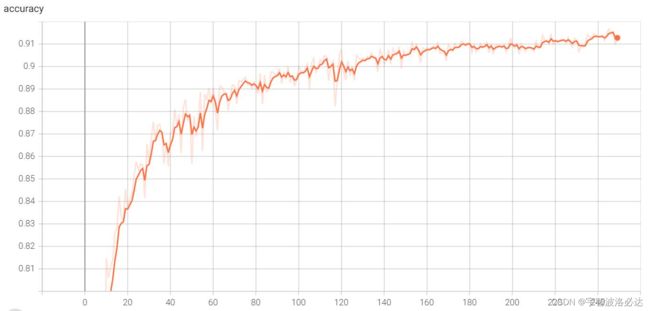
loss变化情况:
之后把该模型部署到摄像头上,观察一下效果:
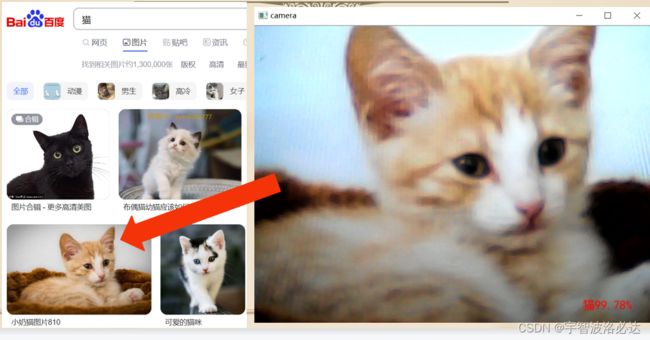
效果还是比较令我满意的。
这个就暂时更新到这里吧,如果以后学到了新东西再来更新。
源代码链接:
(49条消息) cifar10-pytorch-模型源文件、train、test、use等源代码,kaggle上训练好的模型-Python文档类资源-CSDN文库 https://download.csdn.net/download/ereqewe/86514528
https://download.csdn.net/download/ereqewe/86514528