[[概率论与数理统计-2]:随机函数、概率、概率函数、概率分布函数
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/123608954
目录
第1章 随机与非随机事件
1.1 确定性事件与不确定性事件(随机事件)
第2章 随机变量与随机函数
2.1 随机变量
2.2 基于取值范围的随机变量种类:离散型与连续性随机变量
2.3 基于因果关系的随机变量的种类:自变量与因变量
2.4 随机函数:自变量与因变量的关系
2.5 随机变量的个数:一元随机变量与多元随机变量
第3章 单随机变量的取值:事件
3.1 随机事件与随机概率关系
3.2 事件:随机变量的取值
3.3 复合事件的关系
第4章 单随机变量取某个值的可行性大小:概率
4.1 概率的一般性描述(以离散型随机变量为入门基础)
4.2 概率表达式与随机函数表达式的关系
4.3 概率函数 ~= 随机函数 ~= 随机变量 ~= 概率密度函数
4.4 离散型-概率函数/随机变量
4.5 连续型-概率函数/随机变量
第1章 随机与非随机事件
1.1 确定性事件与不确定性事件(随机事件)
![[[概率论与数理统计-2]:随机函数、概率、概率函数、概率分布函数_第1张图片](http://img.e-com-net.com/image/info8/db8cd1fec2d34f20aa0782c3d8767700.jpg)
从随机现象说起,在自然界和现实生活中,一些事物都是相互联系和不断发展的。在它们彼此间的联系和发展中,根据它们是否有必然的因果联系,可以分成截然不同的两大类:
(1)一类是确定性的现象:
这类现象是在一定条件下,必定会导致某种确定的结果。举例来说,在标准大气压下,水加热到100摄氏度,就必然会沸腾。事物间的这种联系是属于必然性的。通常的自然科学各学科就是专门研究和认识这种必然性的,寻求这类必然现象的因果关系,把握它们之间的数量规律。
线性或非线性拟合以及机器学习的算法,实际就是找出输入与输出之间的因果关系,并通过数学函数的形式表达出来。由于从现存现象中采集到的样本数据是不精确的,导致数学模型以及模型对应的参数也不是唯一的,而是需要根据样本进行训练和拟合,拟合出来的模型与实际内在模型之间会存在一定的误差。
找到拟合的规律(训练好的模型)后,就可以对新的现象进行预测,即根据现象推断结果。
前面刚刚探讨的线性拟合的机器学习,就属于这种类型的规律发现。
![[[概率论与数理统计-2]:随机函数、概率、概率函数、概率分布函数_第2张图片](http://img.e-com-net.com/image/info8/d5b297f22895418d9b0d07a9391ccc63.jpg)
深度学习、机器学习都是在输入和输出之间建立某种数学模型,在输入和输出之间进行映射、推理、判断,推广到人的大脑的运作、计算机视觉、现实社会活动,甚至整个宇宙,或许也是这样。
(2)另一类是不确定性的现象。
这类现象是在一定输入条件下,它的结果是不确定的。出现的某种结果,只是出现该结果的可能性大小,而不是必然性结果。
举例来说,同一个工人在同一台机床上加工同一种零件若干个,它们的尺寸总会有一点差异。
又如,在同样条件下,进行小麦品种的人工催芽试验,各棵种子的发芽情况也不尽相同,有强弱和早晚的分别等等。
为什么在相同的情况下,会出现这种不确定的、不一样的结果呢?这对于确定性现象的数学模型来讲,是不可理喻的。对于特定的数学模型,特定的输入,必然是特定的输出。
这是因为,我们说的“相同条件”是指一些主要条件来说的,除了这些主要条件外,还会有许多次要条件、偶然因素、高影响低频次因素又是人们无法事先全部掌握的或由于简化模型的需要忽略这些因素。
正因为这样,我们在这一类现象中,就无法用必然性的因果关系,对个别现象的结果事先做出确定的答案。事物间的这种关系是属于偶然性的,这种现象叫做偶然现象,或者叫做随机现象。
在自然界,在生产、生活中,随机现象十分普遍,也就是说随机现象是大量存在的。比如:每期体育彩票的中奖号码、同一条生产线上生产的灯泡的寿命等,都是随机现象。因此,我们说:随机现象就是:在同样条件下,多次进行同一试验或调查同一现象,所的结果不完全一样,而且无法准确地预测下一次所得结果的现象。随机现象这种结果的不确定性,是由于一些次要的、偶然的因素影响所造成的。
我们采集到的样本,大多数都不是精确的,或许背后的原因正是随机现象,确定性是相对的,而不确定性才是绝对的。确定性是局部的,而不确定性是全局的,在足够长的时间长河中,不去确定的因素到处存在,有些不确定性时间发生的概率非常低,周期非常长而已,然后他们一旦发生,对结果就会产生非常不一样的影响。
随机现象从表面上看,似乎是杂乱无章的、没有什么规律的现象。但实践证明,如果同类的随机现象大量重复出现,它的总体就呈现出一定的规律性。大量同类随机现象所呈现的这种规律性,随着我们观察的次数的增多而愈加明显。比如掷硬币,每一次投掷很难判断是那一面朝上,但是如果多次重复的掷这枚硬币,就会越来越清楚的发现它们朝上的次数大体相同。
我们把这种由大量同类随机现象所呈现出来的集体规律性,叫做统计规律性。
概率论和数理统计就是研究大量同类随机现象的统计规律性的数学学科。
第2章 随机变量与随机函数
2.1 随机变量
简单地说,随机变量是指随机事件的数值上的表现,通过一个变量来标识随机事件,可以是因变量,也可以是自变量。
简单地说,随机变量是指随机事件的数量表现。
例如一批注入某种毒物的动物,在一定时间内死亡的只数;
某地若干名男性健康成人中,每人血红蛋白量的测定值;等等。
另有一些现象并不直接表现为数量,例如人口的男女性别、试验结果的阳性或阴性等,但我们可以规定男性为1,女性为0,则非数量标志也可以用数量来表示。这些例子中所提到的量,尽管它们的具体内容是各式各样的,但从数学观点来看,它们表现了同一种情况,这就是每个变量都可以随机地取得不同的数值,而在进行试验或测量之前,我们要预言这个变量将取得某个确定的数值(不是概率)是不可能的。
2.2 基于取值范围的随机变量种类:离散型与连续性随机变量
按照随机变量可能取得的值,可以把它们分为两种基本类型:
![[[概率论与数理统计-2]:随机函数、概率、概率函数、概率分布函数_第3张图片](http://img.e-com-net.com/image/info8/5ddf5a166331497b9dc20fd29bb4a3ae.jpg)
(1)离散型随机变量:
如果随机变量X的值可以逐个列举出来,则X为离散随机变量;
离散型随机变量是指其数值只能由自然数或整数单位计算,例如:企业个数、员工人数、设备台数等等,其数值一般由计数方法取得.
离散型(discrete)随机变量即在一定区间内变量取值为有限个或可数个。
例如某地区某年人口的出生数、死亡数,某药治疗某病病人的有效数、无效数等。
离散型随机变量通常依据概率质量函数分类,主要分为:伯努利随机变量、二项随机变量、几何随机变量和泊松随机变量。
形象解释:
如上图所示:左边是梯子,右边是:斜坡
像阶梯一样能说出多少层的,可描述为离散型随机变量;
像斜坡一样不能说出多少层的,可描述为连续型随机变量。
(2)连续型随机变量:
如果随机变量X的值无法逐个列举,则X为连续随机变量。
在一定区间内,可任意取值的变量叫连续随机变量,其数值是连续不断的,相邻两个值之间可无限分割,即可取无限个值. 例如:生产零件的规格尺寸、人的身高、人的体重等等. 其数值只能由测量或计量的方法取得.
连续型(continuous)随机变量即在一定区间内变量取值有无限个,或数值无法一一列举出来。
例如某地区男性健康成人的身长值、体重值,一批传染性肝炎患者的血清转氨酶测定值等。
有几个重要的连续随机变量常常出现在概率论中,如:均匀随机变量、指数随机变量、伽马随机变量和正态随机变量。如下图所示:

![[[概率论与数理统计-2]:随机函数、概率、概率函数、概率分布函数_第4张图片](http://img.e-com-net.com/image/info8/7d4cc625a59c49b7ae9baf16ad566c6b.jpg)
2.3 基于因果关系的随机变量的种类:自变量与因变量
根据因果关系,随机变量又分:
(1)自变量X
自变量通常用X表示,是某个区间的数值,可以是[-无穷,+无穷]的连续型数值,也可以是离散型数值。
(2)因变量Y
因变量通常用Y表示,是X为某个数值的概率值,其值表示概率,因此其值始终被限制在[0, 1]之间。
与普通函数的因变量不同的是:这里的因变量的含义是概率,其数值始终在【0,1】区间。
2.4 随机函数:自变量与因变量的关系
随着X数值的变化,Y的值也跟这变化。Y与X的关系,就是随机函数y=f(x)。
随机函数是相对于普通的确定性函数而言的。
这里的x是随机变量的取值,y是x取某个随机值时对应的概率值。
![[[概率论与数理统计-2]:随机函数、概率、概率函数、概率分布函数_第5张图片](http://img.e-com-net.com/image/info8/0287fc000dcf428fa5334e67663fd598.jpg)
比如均匀分布:
X取值范围为[a,b]
随机性表明:在任何以时刻,x的数值不是确定的,是[a,b]区间的任意值。
均匀分布表明:在任意点出现的概率y是相等的,都为1/(b-a)
因此,概率分布函数y = f(x)= 1/(b-a)
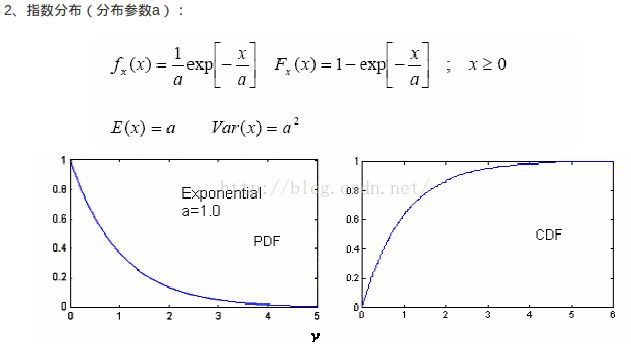
比如指数分布:
X取值范围为(0,无穷)
随机性表明:在任何以时刻,x的数值不是确定的,是(a,b)区间的任意值。
指数分布表明:在任意点出现的概率值y与x取值本身具备一定指数关系。
因此,概率分布函数y = f(x)= a*e^(-bx)
2.5 随机变量的个数:一元随机变量与多元随机变量
y = f(X1,X2, Xn),X1, X2....Xn为随机变量。
当n=1时,为一元随机变量,y为随机变量出现某个值的概率。
但n>1时,为多元随机变量,y为随机变量各自为某个值的联合概率。
y的值始终在[0, 1]区间。
案例:
如果一次掷一个骰子,这称为单随机变量X,每个X的取值为(1, 2,3,3,4,5,6),随机变量X取每个值的概率都是1/6.
如果一次掷两个骰子,这称为二元随机变量(X,Y), X和Y的各自取值都是(1, 2,3,3,4,5,6),随机变量X取每个值的概率都是1/6.。
第3章 单随机变量的取值:事件
3.1 随机事件与随机概率关系
随机变量的取值是不确定的,为了描述随机变量取某个数值的这种不确定性,就需要一种手段和方法,用到了两个关键概率来描述随机变量取值以及取值的不确定性。
(1)事件:是指随机变量的取值范围,可以是离散点,如抛硬币的取值正面或反面,即数值量化的取值为1或0。再如掷色子,骰子的点数用随机变量X表示,X的取值为1,2,3,4,5,6,这6个数值代表了随机变量X可能出现的随机事件。
(2)概率:表示随机变量中,每个事件的不确定性大小,用P来标识,P用来标识随机变量取某个数值与其对应的不确定性的大小。
为了区别普通的函数,采用该概率P来描述随机函数。
y= f(x) => p = P(x)
小p是:概率值
大P是:概率函数
x:是随机变量,离散型随机变量的取值,称为随机事件,如X=A,B两种取值,即两种随机事件。
这里的两个案例中,随机变量X为随机事件的概率是相等的:
如果是两个取值,则每个事件的概率为1/2。
如果是6个事件(1,2,3,4,5,6个数值),则么个事件的概率是1/6。
这种随机变量为每个离散数值的概率是均匀分布,也称为等概率事件。
![[[概率论与数理统计-2]:随机函数、概率、概率函数、概率分布函数_第6张图片](http://img.e-com-net.com/image/info8/8d49dfd9a3884df1881b07e1392029cb.png)
在实际生活中,随机变量X取不同值(不同事件)的概率并不一定相等,比如单随机变量X的正态分布。
X去不同值就不是等概率分布的,而是按照如下的图形分布,在u值处的概率最大,取值越远离u,其概率越小。
随机变量的取值随机事件,可以取任意一个随机事件值 。
每个随机事件出现不确定性的,其可性能也并不一定完全相同,这就是概率。
3.2 事件:随机变量的取值
基本事件:为了某个目的,不可再分的时间,如骰子的1-6个点数,就是6个基本事件,硬币的正面和反面,就是2个基本事件,分别用1或0标识。
复合事件:由多个不同的基本事件组成的事件,就是符合事件,如点数小于4的事件,包含了点数1,点数2,点数3这三个基本事件。它就是符合事件。
在上图中,有6个基本事件1, 2, 3,4,5,6,每个事件的概率均匀分布为1/6
![[[概率论与数理统计-2]:随机函数、概率、概率函数、概率分布函数_第9张图片](http://img.e-com-net.com/image/info8/8c0cc2ecfaff43ddacb037fbe57e9847.png)
上图中,有2个基本事件0或1,每个事件并不是等概率分布,0出现的概率70%, 1出现的可能性为30%。
离散时间和连续事件:并非所有的事件都是离散的,也连续的,如果X的正态分布,X的每个取值就是随机事件的X的事件,X的取值可以是连续的。
样本空间:所有可能的事件组成了随机变量的X的样本空间。
整个样本空间本质是复合事件,是所有基本样本的复合,其概率为1,因此样本空间是必然事件。
3.3 复合事件的关系
复合事件:由多个不同的基本事件组成的事件,就是符合事件,如点数小于4的事件,包含了点数1,点数2,点数3这三个基本事件。它就是符合事件。
由于复合事件是有多个基本事件组成,因此,不同的复合事件之间就不一定完全独立了。
![[[概率论与数理统计-2]:随机函数、概率、概率函数、概率分布函数_第11张图片](http://img.e-com-net.com/image/info8/409ff7804915463aaff3bc2bcaf77d08.jpg)
![[[概率论与数理统计-2]:随机函数、概率、概率函数、概率分布函数_第12张图片](http://img.e-com-net.com/image/info8/5332224804bf4b3299a1b66992b92852.jpg)
符合A包含的基本事件,也被B符合事件所包含。

![[[概率论与数理统计-2]:随机函数、概率、概率函数、概率分布函数_第13张图片](http://img.e-com-net.com/image/info8/22b8ffcace0e4ed6bca51eee659eb139.jpg)
![[[概率论与数理统计-2]:随机函数、概率、概率函数、概率分布函数_第14张图片](http://img.e-com-net.com/image/info8/d402dfc3f9de42dcb15fb45dbf37a109.jpg)
![[[概率论与数理统计-2]:随机函数、概率、概率函数、概率分布函数_第15张图片](http://img.e-com-net.com/image/info8/22d3cb2a8bdf4f32a756862a8df60853.jpg)
![[[概率论与数理统计-2]:随机函数、概率、概率函数、概率分布函数_第16张图片](http://img.e-com-net.com/image/info8/c0c6d6aea9b843c4a8ffee86248000b0.jpg)
![[[概率论与数理统计-2]:随机函数、概率、概率函数、概率分布函数_第17张图片](http://img.e-com-net.com/image/info8/6bd9d9f5414e48e58511dd65fd0fc605.jpg)
第4章 事件发生/出现可能性的大小:概率
单随机变量取某个值的可行性大小:概率
4.1 概率的一般性描述(以离散型随机变量为入门基础)
概率,亦称“或然率”,它是反映随机事件出现的可能性大小。
随机事件是指在相同条件下,可能出现,也可能不出现的那些事件。
例如,从一批有正品和次品的商品中,随意抽取一件,“抽得的是正品”就是一个随机事件。设对某一随机现象进行了n次试验与观察,其中A事件出现了m次,即其出现的频率为m/n。经过大量反复试验,常有m/n越来越接近于某个确定的常数(此论断证明详见伯努利大数定律)。该常数即为事件A出现的概率,常用P (A) 表示。

概率大小的两种定义方法:
(1)频率定义
随着人们遇到问题的复杂程度的增加,等可能性逐渐暴露出它的弱点,特别是对于同一事件,可以从不同的等可能性角度算出不同的概率,从而产生了种种悖论。另一方面,随着经验的积累,人们逐渐认识到,在做大量重复试验时,随着试验次数的增加,一个事件出现的频率,总在一个固定数的附近摆动,显示一定的稳定性。R.von米泽斯把这个固定数定义为该事件的概率,这就是概率的频率定义。从理论上讲,概率的频率定义是不够严谨的。
(2)统计定义
在一定条件下,重复做n次试验,Na为N次试验中事件A发生的次数,如果随着n逐渐增大,频率Na/N逐渐稳定在某一数值p附近,则数值p称为事件A在该条件下发生的概率,记做P(A)=p。这个定义称为概率的统计定义。
4.2 概率表达式与随机函数表达式的关系
统计概率表示为:p = P(A) =》 随机变量等于离散随机事件A的概率,这里的p是某个特定的概率值,而不是变量。
随机变量表示为:p = P(X) => X是随机变量,其值可以为随机事件A,也可以为其他的随机事件,这里的p是变量,是概率型变量。
因此 p=P(A)的含义是:随机变量X=A事件的概率值,即 p = P({X=A}), 简写成p=P(A),也可以简写成:p = P{X=A}, 也可以简写成p = P(X=A).
比如,普通函数:y = f(x) = 2x+1。
当x = 3(相当于随机事件A)时,y的值为:
y = f(x=3) =f{x=3} = f(3)= 2 * 3 + 1 = 7.
更进一步的例子:p = P{X>3},表示X>3的概率。
4.3 概率函数 ~= 随机函数 ~= 随机变量 ~= 概率密度函数
y = f(x)
随机变量:体现了自变量x的特性,自变量x是随机变量,但没有体现因变量y,也没有体现函数f。
随机函数:体现了因变量与自变量的函数关系y=f(x),也指明了自变量x是随机变量,但没有指明因变量y的范围和特征。
概率函数:体现了因变量与自变量的函数关系y=f(x),也指明了因变量y是概率值,但没有明确指明因变量x的范围与特征,但由于是因变量是概率,隐含了自变量x是随机变量,整个函数是随机函数。因此概率函数更能够体现在概率领域,自变量与因变量的函数关系。
在概率论中,没有概率函数说法,取而代之的是: 概率密度函数。这里用来概率函数的目的为了过渡,为了更好理解的方便。
当然,在实际课本中,很多时候用随机变量的特性来参数概率函数的特性。
(1)概述
有了取不同数值的自变量X和因变量概率值Y之后,概率函数就出现了。
首先,概率函数,是函数,函数表达的是因变量y与自变量的数学关系,用y = f(x)表达。
其实,概率函数,是概率,即用来表达因变量y是概率的函数,用y = f(x)表达。
因此,概率函数是普通函数在概率领域的扩展,一种在概率领域的专有称呼,其实概率函数就是一个普通函数而已。但是,因为概率函数是应用概率领域,y值不会像普通函数出现任意值,概率函数的y值只能被限制在[0, 1]之间。
(2)概率函数的分类:X取值的连续性
- 离散型概率函数 =》 X为离散型随机变量
- 连续型概率函数 =》 X为连续型随机变量
(3)概率函数的分类:因变量的个数
- 单变量:一元概率函数,为二维平面几何图形。
- 多变量:多元概率函数,为多维空间几何图形。
(4)概率函数的分类:根据函数的几何形态
- 均匀分布
- 指数分布
- 正态分布
4.4 离散型-概率函数/随机变量
离散型随机变量:如果随机变量X只可能取有限个或至多可列个值,则称X为离散型随机变量。
设X为离散型随机变量,它的一切可能取值为X1,X2,……,Xn,……,记
P=P{X=xn},n=1,2...
离散型随机函数:随机变量为离散随机变量的随机函数,这样的随机函数的概率,也是离散的。
4.5 连续型-概率函数/随机变量
连续型随机变量:是指如果随机变量X的所有可能取值不可以逐个列举出来,而是取数轴上某一区间内的任一点,是连续的点。
连续型随机函数:随机变量为连续随机变量的随机函数,这样的随机函数的概率,也是连续的 。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/123608954