Pytorch中常见transform的使用
本次实验练习了pytorch中数据的读取,Dataset类的使用,以及transform模块的使用。
一、Pytorch简介
PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。
2017年1月,由Facebook人工智能研究院(FAIR)基于Torch推出了PyTorch。它是一个基于Python的可续计算包,提供两个高级功能:1、具有强大的GPU加速的张量计算(如NumPy)。2、包含自动求导系统的深度神经网络。
二、Pytorch的环境配置
关于Pytorch的环境配置网上有好多教学,这里不做赘述。
三、Dataset类的基本使用
Dataset类:处理数据,提供一种方式挑选数据及其对应的label。
Dataloader类:对Dataset挑选后的数据进行打包,为后面的网络提供不同的数据形式。
1、首先导入Dataset类
from torch.utils.data import Dataset
2、创建一个类,继承Dataset类
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
# os.path.join的意思是把这两个路径拼接
# 如root路径是dataset\train,label路径是ants,拼接后的结果是dataset\train\\ants
self.path = os.path.join(self.root_dir, self.label_dir)
# os.listdir(path)
# 作用:传入任意一个path路径,返回的是该路径下所有文件和目录组成的列表;
self.img_path = os.listdir(self.path)
# 这个函数作用是获取其中的每一个图片
def __getitem__(self, idx):
# idx是图片的索引,img_name是获取图片
img_name = self.img_path[idx]
# 把图片的路径也拼接上
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
# 打开图片
img = Image.open(img_item_path)
# 需要用到标签
label = self.label_dir
# 返回标签和读取的图片
return img, label
def __len__(self):
# 返回有多少张图
return len(self.img_path)
四、常见transform的使用
首先导入SummaryWriter函数,此函数的作用是将图片在浏览器中显示。
writer = SummaryWriter('logs')
img = Image.open('images/220927.png').convert('RGB')
1、ToTensor方法:
这个类可以接受的图像类型为Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.
# ToTensor的使用
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("TotTensor", img_tensor)
在终端输入
tensorboard --logdir="logs" --port=6007
点击链接进入浏览器输出图像如下
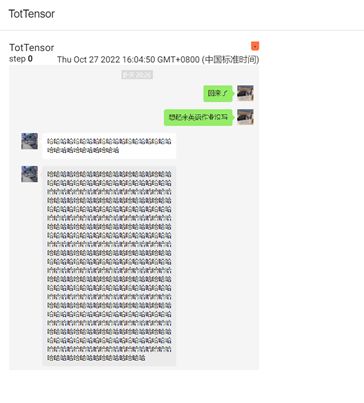
这个方法的作用是将图片转换为tensor类型。
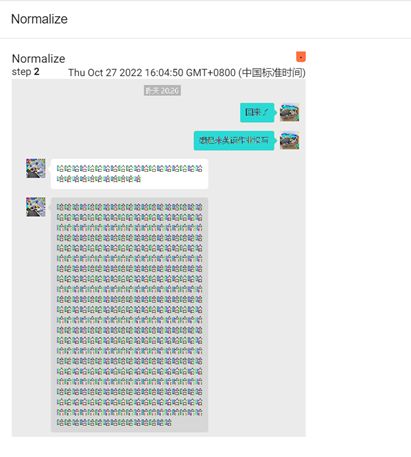
2、Normalize方法
归一化类,需要传入均值和标准差。
tran_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
# 传入需要归一化的图片
img_norm = tran_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image('Normalize', img_norm, 2)
输出结果如下
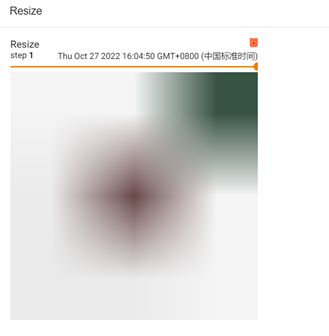
3、Resize方法
即改变图片尺寸
trans_resize = transforms.Resize((3, 3))
img_resize = trans_resize(img_tensor)
print(img_resize)
writer.add_image('Resize', img_resize, 0)
输出结果如下
4、Compose方法
compose()用法:其中的参数需要的是一个列表,列表中的数据类型是transforms,意义是把两个类的方法合并。
trans_resize_2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize, trans_resize_2])
img_resize_2 = trans_compose(img_tensor)
print(img_resize_2)
writer.add_image('resize', img_resize_2, 1)
输出结果如下

五、dataset类与transform的结合使用
首先下载数据集,因为仅作练习使用,所以下载较小的CIFAR10数据集。
root是保存的目录,train=True时下载的时训练集,反之下载数据集,将下载的数据集转换为tensor类型
train_set = torchvision.datasets.CIFAR10(root='./dataset', train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=dataset_transform, download=True)
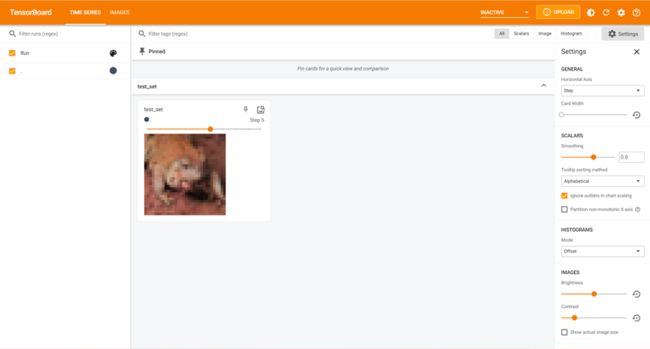
取测试集的前十张图片传入浏览器
writer = SummaryWriter('logs')
for i in range(10):
img, target = test_set[i]
writer.add_image('test_set', img, i)
writer.close()
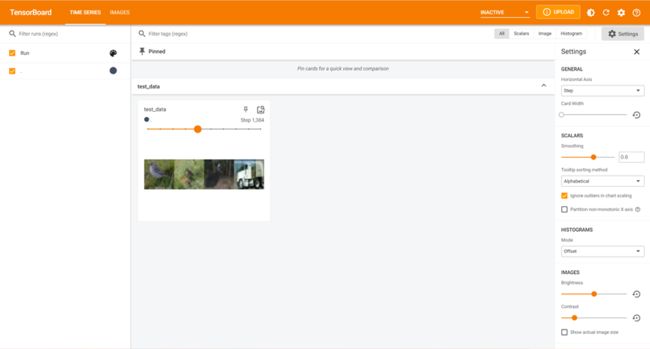
输出结果如下
2、dataloader的使用
Dataloader类:对Dataset挑选后的数据进行打包,为后面的网络提供不同的数据形式。
准备的测试数据集
test_data = torchvision.datasets.CIFAR10('./dataset', train=False, transform=torchvision.transforms.ToTensor())
batch_size=4的意思是每次从数据集中取出4个数据进行打包
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
将打包好的图片在浏览器中显示
step = 0
writer = SummaryWriter('dataloader')
for data in test_loader:
imgs, targets = data
writer.add_images('test_data', imgs, step)
step = step+1
writer.close()
输出结果如下