context-aware learning to rank with self-attention
Transformer 在美团搜索排序中的实践_美团技术团队-CSDN博客引言美团搜索是美团 App 连接用户与商家的一种重要方式,而排序策略则是搜索链路的关键环节,对搜索展示效果起着至关重要的效果。目前,美团的搜索排序流程为多层排序,分别是粗排、精排、异构排序等,多层排序的流程主要是为了平衡效果和性能。其中搜索核心精排策略是 DNN 模型,美团搜索始终贴近业务,并且结合先进技术,从特征、模型结构、优化目标角度对排序效果进行了全面的优化。近些年,基于 Transfo...https://blog.csdn.net/MeituanTech/article/details/105569502NDCG及实现 - 知乎Normalized Discounted Cumulative Gain(归一化折损累计增益)NDCG用作排序结果的评价指标,评价排序的准确性。 推荐系统通常为某用户返回一个item列表,假设列表长度为K,这时可以用NDCG@K评价该排序列表与用户真… https://zhuanlan.zhihu.com/p/84206752阿里提出基于Transformer的个性化重排序模型PRM,首次用于大规模在线系统-InfoQ在推荐系统中,个性化排序是推荐系统的核心部分之一。阿里巴巴的研究人员在近期的一篇论文中提出了基于Transformer的重排序结构PRM,解决当前point-wise方式排序模型只考虑单个物品与用户之间相关性而忽略物品间相关性的问题,效果好于LambdaMART以及List-wise方式的DLCM,同时还开源了论文所使用的电商场景数据集。该论文已经被RecSys2019会议录用。本文是AI前线第1
https://zhuanlan.zhihu.com/p/84206752阿里提出基于Transformer的个性化重排序模型PRM,首次用于大规模在线系统-InfoQ在推荐系统中,个性化排序是推荐系统的核心部分之一。阿里巴巴的研究人员在近期的一篇论文中提出了基于Transformer的重排序结构PRM,解决当前point-wise方式排序模型只考虑单个物品与用户之间相关性而忽略物品间相关性的问题,效果好于LambdaMART以及List-wise方式的DLCM,同时还开源了论文所使用的电商场景数据集。该论文已经被RecSys2019会议录用。本文是AI前线第1 https://www.infoq.cn/article/a1tj74y7V2EKFikKYcwv 这篇文章是波兰第一电商平台allergro的ml研究院发的ltr的论文,后续还有一篇NeuralNDCG,属于一个系列,还出了个poster。整体看即有热点,又有应用,还是不错,作者也开源自己的实验代码,文章本身写的也挺好,简单易懂,我在视觉排序中用了,效果也不错。作者用transformer做特征提取,配合ordinal loss,整体上依然是对一个query下的value做排序,在我们的电商应用场景下,是一个sku对应的多张图的优选。在基于transformer做re-rank的工作中,目前又看到阿里和美团的相关工作。
https://www.infoq.cn/article/a1tj74y7V2EKFikKYcwv 这篇文章是波兰第一电商平台allergro的ml研究院发的ltr的论文,后续还有一篇NeuralNDCG,属于一个系列,还出了个poster。整体看即有热点,又有应用,还是不错,作者也开源自己的实验代码,文章本身写的也挺好,简单易懂,我在视觉排序中用了,效果也不错。作者用transformer做特征提取,配合ordinal loss,整体上依然是对一个query下的value做排序,在我们的电商应用场景下,是一个sku对应的多张图的优选。在基于transformer做re-rank的工作中,目前又看到阿里和美团的相关工作。
1.Introduction
评价指标通常采用IR(信息检索)的指标,MRR,NDCG,MAP。
the main goal of a ranking algorithm is to determine relative preference among a group of items.排序函数的主要目标就是确定一组中items之间的相对偏好,但是用户对列表中给定项目的偏好取决于同一列表中存在的其他项目。常见的排序算法尝试在损失函数级别对此类项目间依赖建模,列表中的项目仍然单独评分,但它们的相互作用对评估指标的影响在损失函数中得到考虑,比如pairwise,但是pointwise不考虑这种依赖性。
在本文中,we propose a learnable, context-aware, self-attention based scoring function, which allows for for modelling of interitem dependencies not only at the loss level but also in the computation of items’ scores.作者提了个基于transformer的评分函数,不仅在loss级别,且在对项目评分计算时对项目间依赖性建模。作者用transformer,也得到了一个permutation-equivariant评分函数,permutation-equivariant就是输入是原始输入的无序的对模型没影响。
2.problem formulation
X是训练数据,(x,y)是成对数据,x是多维的特征向量,一个y就是一个list,一个list中通常有多个x,y可以是多标签也可以是二分类的。在我的电商图优选场景中,y是多标签的5档评分,x是对应的5个合成图,是一一对应的,在一个list中的x可以是不定长的,通常在ltr中最重要的是评分函数f以及损失函数l,如下公式:
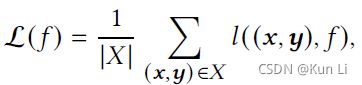
3.positional encodings
作者提到了permutation-equivariant的定义,The key property of the proposed context-aware model making it suitable for the ranking setting is that it is permutation-equivariant, i.e. the scores of items do not depend on the original ordering of the input.transformer是置换等变的意味着项目的得分不依赖于原始的排名。
The ranking problem can be viewed as either ordering a set of (unordered) items or as re-ranking, where the input list has already been sorted according to a weak ranking model. In the former case,the use of positional encodings is not needed. In the latter, they may boost the model’s performance.排序问题可以看成是对一组无序的items进行排序或者是重排序,重排序的话意味着原始的items已经是若排序的,一般走完精排的肯定是有排序的,无序的进行排序,是不需要位置编码的,但是重排序,位置编码会提高性能。
4.ordinal loss
提一下作者的主要采用的损失函数,评分函数是基于transformer,损失函数:假设作者的输入是(bs,最长的list的长度,特征向量的长度)(100,10,98),实际的标签维度是5,就是有5档分数,那么在计算标签时,y_pred的维度是(100,10,5),98输入之后linear先编码会变成64,之后会进入transformer的multi-head attention,出来的维度是(100,10,64),64到5实际上有一个linear层,y_true实际上应该是(100,10)的,作者通过with_ordinals函数也把它的形式变成了(100,10,5)怎么变呢,正常10维,这里的10是被人为填充的,有的list不足10,就填充-1,变成10维,在训练的预测中每一维对应一个5维经过了sigmoid的值,即在0-1之间的数,标签则是对应0-5之间的数(5档的话),现在把0-5之间的数变成如下形式,就产生了5维的列表,预测和标签值用bceloss计算损失。作者除了ordinal loss,还尝试了pointwise rmse,lambdaloss,ranknet,lambdarank,listnet,listmle.

def ordinal(y_pred, y_true, n, padded_value_indicator=PADDED_Y_VALUE):
"""
Ordinal loss.
:param y_pred: predictions from the model, shape [batch_size, slate_length, n]
:param y_true: ground truth labels, shape [batch_size, slate_length]
:param n: number of ordinal values, int
:param padded_value_indicator: an indicator of the y_true index containing a padded item, e.g. -1
:return: loss value, a torch.Tensor
"""
device = get_torch_device()
y_pred = y_pred.clone()
y_true = with_ordinals(y_true.clone(), n)
mask = y_true == padded_value_indicator
valid_mask = y_true != padded_value_indicator
ls = BCELoss(reduction='none')(y_pred, y_true)
ls[mask] = 0.0
document_loss = torch.sum(ls, dim=2)
sum_valid = torch.sum(valid_mask, dim=2).type(torch.float32) > torch.tensor(0.0, dtype=torch.float32, device=device)
loss_output = torch.sum(document_loss) / torch.sum(sum_valid)
return loss_output5.experiments
实验主要看作者的这个消融实验。

本文整体上来说在ltr上还是不错的,很简单,本质就是基于transformer做了个rank的模型,rank就不用pe,re-rank就用pe,其次还有个ordinal loss。