【论文笔记】Swin-Transformer系列阅读笔记
一、Swin Transformer V1
paper:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
github:https://github.com/microsoft/Swin-Transformer
本文提出了一个计算机视觉任务中的通用backbone模型:Swin Transformer。Swin将self-attention限制在局部窗口内进行,降低了Attention的计算量,同时利用滑动窗口机制使得不同窗口间建立联系,Swin在各个视觉任务屠榜(一个字:强)。
1、网络结构
Swin-T的网络结构如下所示,主要包含Patch Partion、Linear Embedding、Swin Transformer Block、Patch Merging等模块。
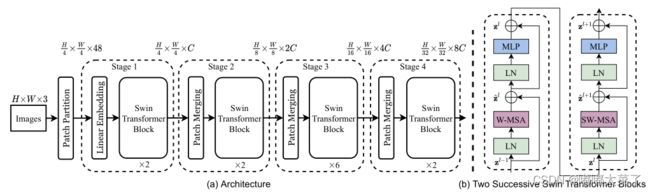
(a)Patch Partion/Linear Embedding
Patch Partion和Linear Embedding组合成Patch Embedding,通过步长为4、核大小为4的卷积实现1/4下采样。
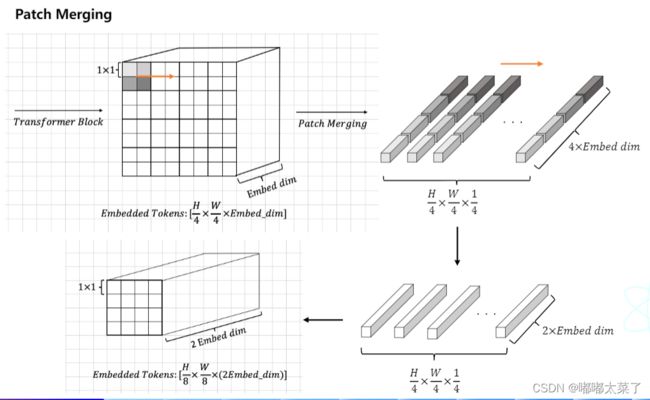
(b)Patch Merging
除了Patch Partion,其他所有的下采样通过Patch Merging实现,假设输入维度为[N, C, H, W]对于相邻的2x2个embedding,将其concat组合,得到特征图维度为[N, C, H/4, W/4],在接一个linear proj即可得到[N, 2C, H/4, W/4]的输出,降低分辨率的同时,增加特征维度,可参考下图。(下图来自朱欤博士的【从零开始学transformer】,链接在文末)
(c) Shifted Window based Self-Attention
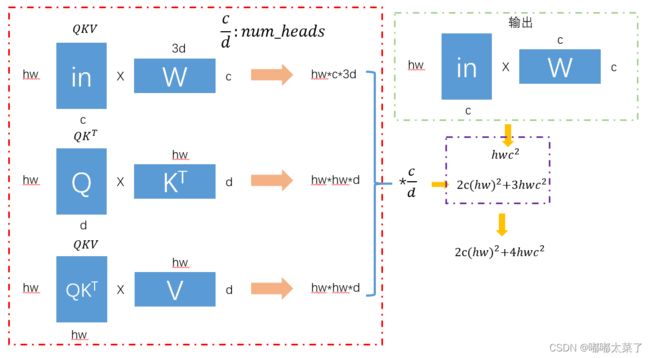
假设输入维度为[batch_size, hw, c],那么其计算量如下所示,当特征图分辨率较高时,hw较大,计算量非常大。
为了降低计算量,可以将其划分为不重复的窗口,计算量有显著降低(M为窗口尺寸):
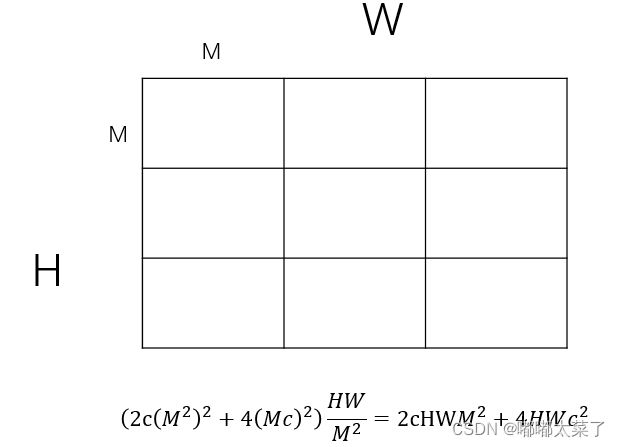
Attention计算量和划分窗口后的计算量对比:
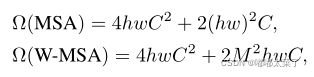
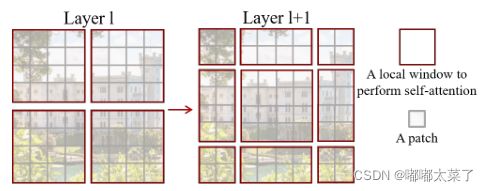
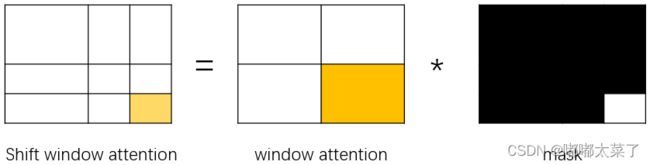
划分了窗口能够显著降低计算量,但是又引入了一个新问题:窗口间的联系没了。为了解决这个问题,引入了shifted windows。如下图所示,在划分窗口时,使窗口位置变化,即可在不同的窗口间添加联系。但是直接划分窗口又会引入新的问题:窗口的数量和包含的patch会变化。
解决方法也比较简单,使用cyclic shift替代window partition策略,将特征图的值整体偏移一定位置即可(torch.roll函数),论文中偏移量为M/2,M为window的尺寸。偏移后的窗口如下图红框所示,这里需要注意的是部分attention计算窗口范围变小了,为了有效计算,使用了mask方法。
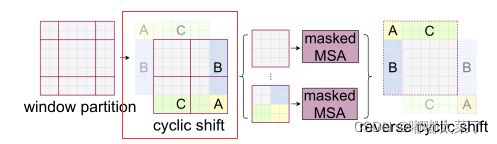
为了更好的叙述Attention计算过程,见下图,背景颜色表示未进行shift时的窗口划分策略(对应上图最左边的window partition),红框表示Attention计算窗口。
简单来说,就是窗口划分后,在各个窗口内计算Attention,如下图的ABCDFGHI区域。
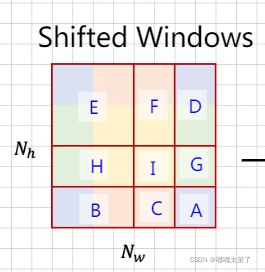
如何通过mask快速计算局部attention呢?如下图,只需要生成对应的mask即可。
看到了这里,可能看过源码的朋友们会有个疑问,因为源码中用了下式,使用加法而不是乘法:
![]()
这里是利用加法来降低计算量,源码中有这么一行代码(下方代码),将不感兴趣的mask区域填充值为-100,那么在softmax计算公式中的指数计算时,该项趋于0,即对计算结果无贡献。(用加法替代乘法降低计算量)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))(d)Relative position bias
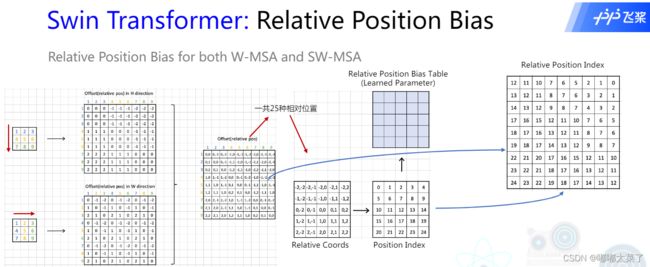
在self-attention中,引入了位置偏置B,因为相对位置的取值范围为[-M+1, M-1],所以设定可学习参数矩阵![]() ,
,![]() ,B的值从
,B的值从![]() 中取。实验证明使用Relative position bias好于不使用Relative position bias或者使用 absolute position embedding。
中取。实验证明使用Relative position bias好于不使用Relative position bias或者使用 absolute position embedding。
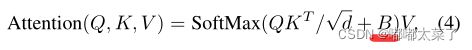
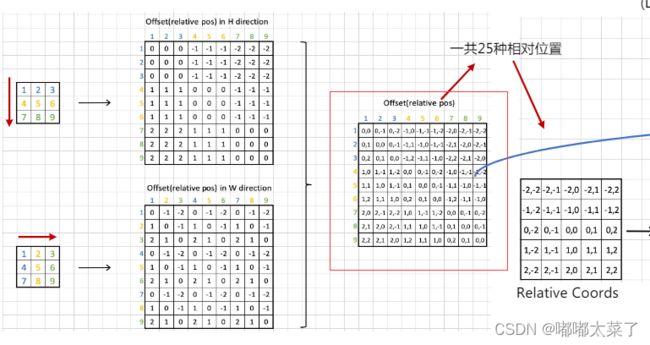
假设窗口大小为3,那么窗口内所有像素的相对位置共有(2*3-1)*(2*3-1)=25种可能(下图Relative Position),所以relative position bias的维度是(2M-1)x(2M-1)。(图片来自朱欤老师的从零开始学transformer,链接在文末)
PS:为什么这里的pos table大小是13x13,而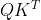 需要的B维度是49x49(window为7)?因为7x7的窗口,相对位置表是13x13,根据相对位置提取表中的bias即可。
需要的B维度是49x49(window为7)?因为7x7的窗口,相对位置表是13x13,根据相对位置提取表中的bias即可。
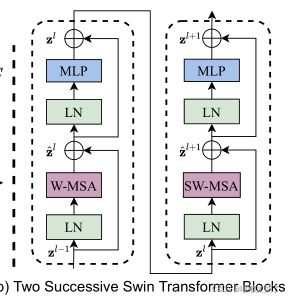
(e)Swin Transformer Block
2个连续的transformer block,间隔采用shifted window(SW-MSA表示shifted window multi-head self-attention,W-MSA表示 window multi-head self-attention)。
2、实验结果
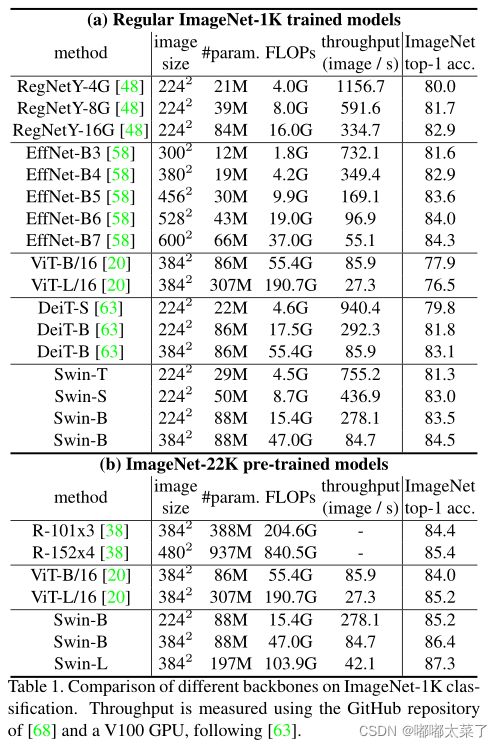
1、ImageNet-1k
在ImageNet-22k上预训练,ImageNet-1k准确率达到87.3%(太强了)。
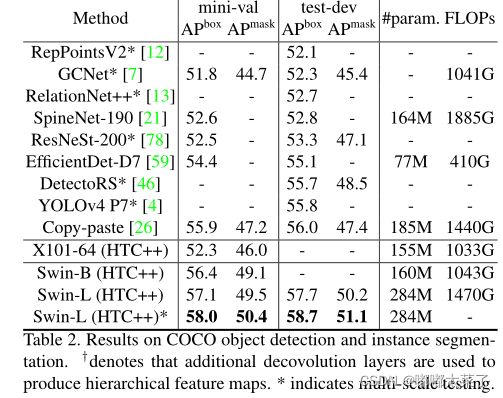
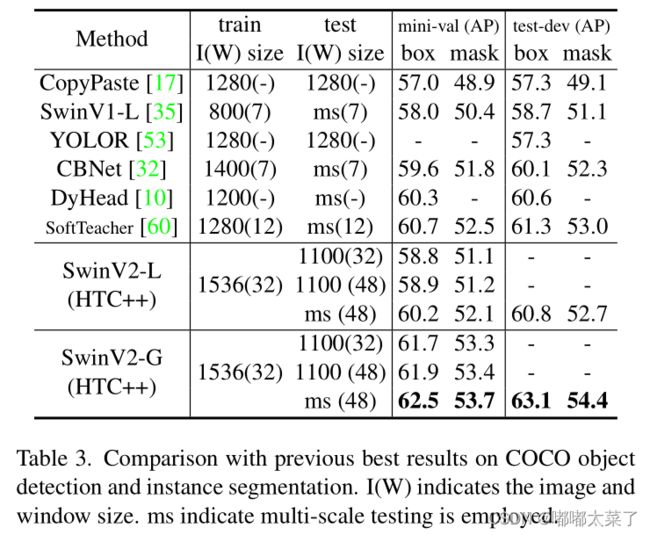
2、目标检测COCO
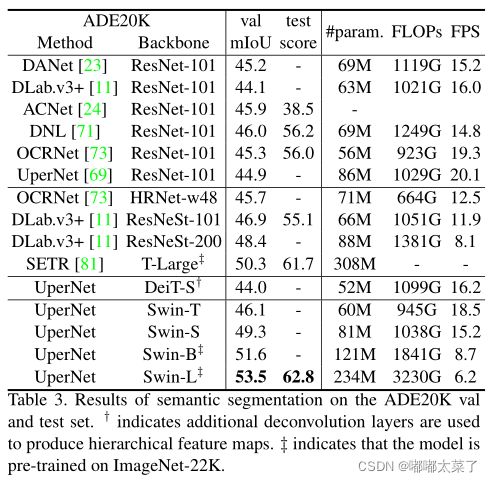
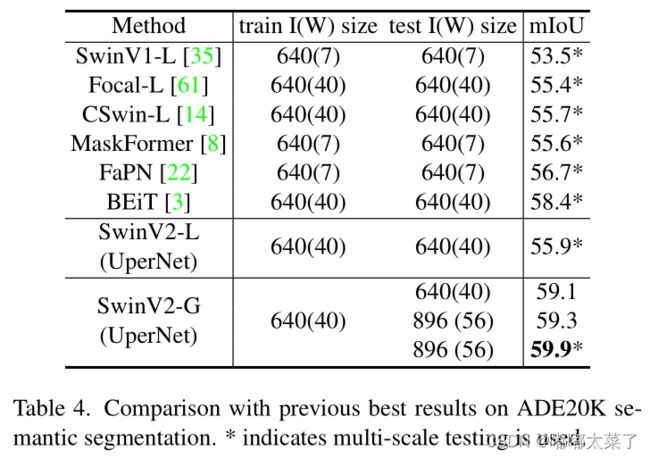
3、语义分割ADE20K
二、Swin Transformer V2
视觉模型在训练和应用时有如下困难:
(1)大模型训练不稳定;
(2)没有有效地方法将低分辨率预训练的模型应用于高分辨率下游任务(通常的方法是将位置编码直接插值,这种方法简单但是是次优解)。
针对上述问题,Swin Transformer V2提出了2个解决方案:
(1)使用post-norm和cosine attention提升大视觉模型的稳定性;
(2)使用log-spaced continuous position bias将低分辨率预训练模型迁移到高分辨率任务中。
1、扩增模型和分辨率遇到的问题
(a)模型扩增
当对原有的Swin Transformer模型(使用pre-norm结构)参数扩增的的时候,网络深层的激活值增加的非常快。如下图所示,量级达到了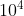 。
。
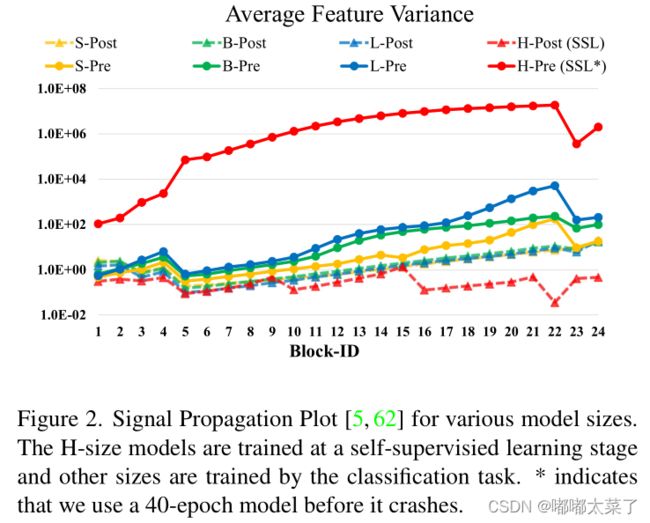
当模型参数扩充到6.68E时,训练已经无法进行,如下图:
(b)不同分辨率模型迁移
当把低分辨率小窗口训练的模型直接迁移到高分辨率大窗口任务上,准确率下降很多。如下图,把在256x256窗口大小为8的参数迁移到分辨率384x384窗口大小为12的任务上时(位置编码通过插值提高其分辨率),准确率下降的非常多。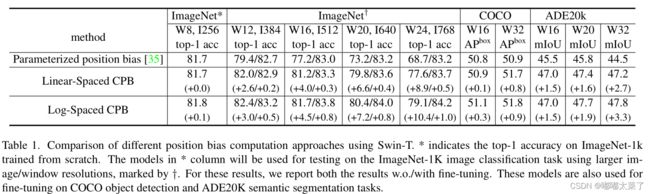
2、Scaling Up Model Capacity
针对参数扩增时模型难训练的问题,作者提出了post normalization和scaled cosine attention。
Post normalization
下图为Transformer的结构图,对于transformer block(红框部分),其主分支(shortcut)的值随着网络变深不停累加,导致层数越深其激活值越大,从而导致训练不稳定。将pre-norm结构修改为post-norm结构(红框下的结构),能够有效降低深层网络的激活值(激活值对比图往上面翻翻)。
为了稳定训练,6个Transformer block 额外引入一个LayerNorm。
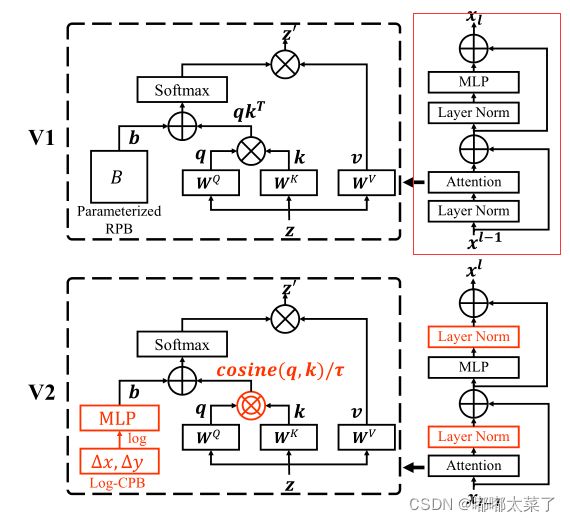
Scaled cosine attention
在原有的self-attention计算时,query和key(Q和K)向量的相似是通过点积计算的,那么计算得到的attention map的值就会被部分向量掌控。见下式,当softmax中某个值特别大的时候,其他的位置输出都接近0,从而部分向量决定了最终的输出。在采用了post-norm后,这种情况更为严重。

为了解决上述问题,作者提出了scaled cosine attention方法,![]() 就是上式中的softmax的输入,使用cosine attention输出值范围较小,从而softmax的输出不会出现极端(一个值接近1其他都接近0)。此外引入了一个可学习参数
就是上式中的softmax的输入,使用cosine attention输出值范围较小,从而softmax的输出不会出现极端(一个值接近1其他都接近0)。此外引入了一个可学习参数 ,τ被设置大于0.01。
,τ被设置大于0.01。
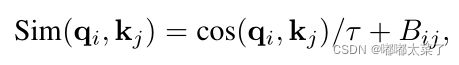
cosine similarity公式:
![]()
3、Scaling Up Window Resolution
当低分辨率的参数迁移到高分辨率任务上时,由于位置编码的维度已经固定,为了适应高分辨率任务,常用的解决方法是直接对其插值,但是插值法是次优的,会引起模型性能降低(Swin中是窗口大小改变会引起这个问题)。为了解决这个问题,作者提出了 log-spaced continuous position bias方法,使不同分辨率的模型参数迁移更平滑。
Continuous relative position bias
回顾一下Swin V1的relateive position bias,当窗口大小M确定后,那么bias table的大小就固定了。在窗口大小改变的情况下,常用插值的方法来改变bias table大小。针对这个问题,Swin V2提出一种优化方法:不构造bias table,使用一个2层带ReLU的MLP网络预测bias。
![]()
上式的 g指网络结构,其输入是下图中的红框部分,相对位置偏移。这么设计有个好处:当窗口的大小变化时,任然可以用g来预测不同位置偏移对应的bias。(不需要插值这种粗暴的方法)
使用神经网络预测bias可以有效避免使用插值法适应不同窗口大小的问题,但是又引入了一个新的问题:当窗口变化很大时,神经网络g的输入变化非常大。
为了解决这个问题,作者提出了Log-spaced coordinates。
Log-spaced coordinates
对位置偏移做对数变换,如下式:

通过对数变换,能够降低位置偏置变化范围。下表为对数变换后的范围对比,可以看出,通过对数变换能够降低输入的变化范围。
| 线性 | 对数 |
| [-7, 7]x[-7, 7] | [-2.079, 2.079]x[-2.079, 2.079] |
| [-15, 15]x[-15, 15] | [-2.773, 2.773]x[-2.773, 2.773] |
4、实验结果
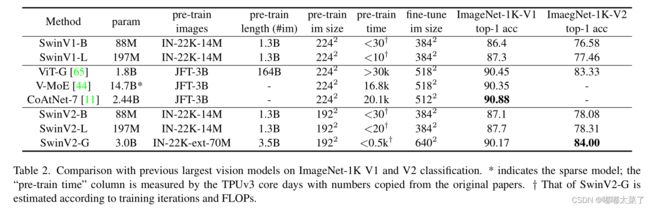
1、ImageNet 1k
2、目标检测 coco
3、ade20k
4、小节
关于GPU优化的一些内容都没写,可以自行看论文,原因很简单:反正我也训练不起[手动狗头]。
参考链接:
1、【从零开始学视觉Transformer】