RNN详解
文章目录
- 回顾FNN
- RNN基本模型
-
- 基本结构
- 通过时间反向传播
- 几种特殊RNN
-
- 基于上下文的RNN
- 双向RNN
- 基于编码—解码的序列到序列架构
- RNN缺陷:无法做到长期依赖
-
- 权值 W W W角度
- 梯度消失/爆炸角度
- RNN应用
回顾FNN
先来回顾一下前馈神经网络(FNN),网络结构如下图所示:
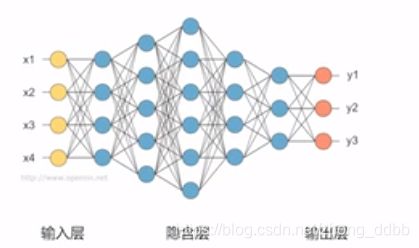
对于每个神经元进行如下运算:
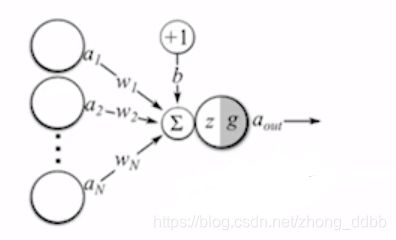
先进行加权求和
z = b + ∑ i = 1 N w i x i z = b+ \sum_{i=1}^N w_i x_i z=b+i=1∑Nwixi
在进行非线性变换:
g ( x ) = σ ( x ) = 1 1 + e − x a o u t = g ( z ) = σ ( ∑ i = 1 N w i x i + b ) g(x)= \sigma(x)=\frac{1}{1+e^{-x}}\\ a_{out} = g(z) = \sigma(\sum_{i=1}^N w_i x_i +b) \\ g(x)=σ(x)=1+e−x1aout=g(z)=σ(i=1∑Nwixi+b)
所以,整个神经网络相当于一个复合函数。
RNN基本模型
基本结构
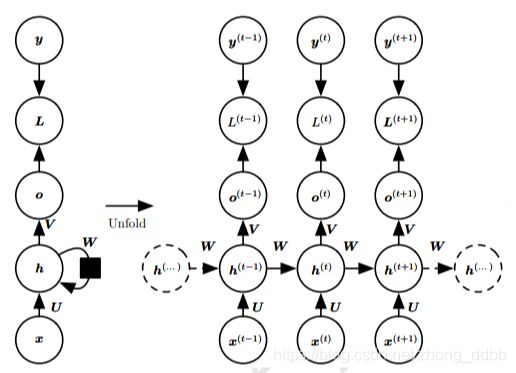
循环神经网络的结构如下:
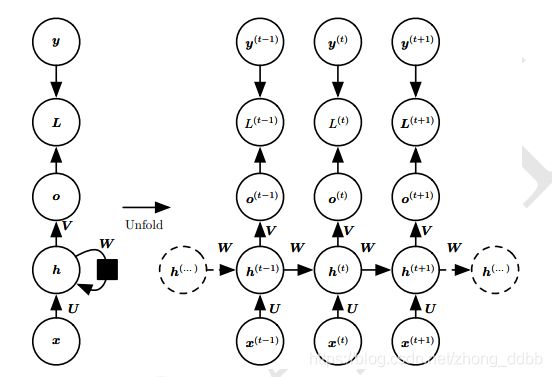
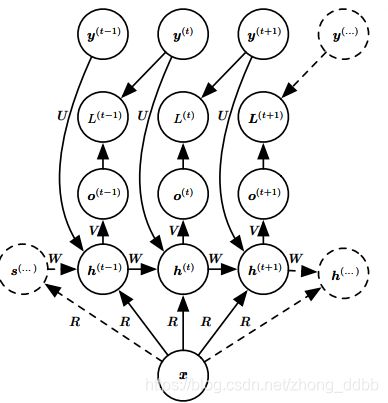
将输入序列 x x x映射到输出值 o o o的对应序列。损失 L L L衡量每个输出 o o o与相应的训练目标 y y y的距离。
输入到隐藏的连接由权重矩阵为 U U U,隐藏到隐藏的循环连接由权重矩阵为 W W W,隐藏到输出的连接由权重矩阵为 V V V。RNN是共用一组参数。
该模型中的前向传播定义如下:
a ( t ) = b + W h ( t − 1 ) + U x ( t ) h ( t ) = tanh ( a ( t ) ) o ( t ) = c + V h ( t ) y ^ ( t ) = s o f t m a x ( o ( t ) ) \begin{aligned} &\mathbf a^{(t)} = \mathbf b + \mathbf W \mathbf h^{(t-1)} + \mathbf U \mathbf x^{(t)} \\ &\mathbf h^{(t)} = \tanh(\mathbf a^{(t)}) \\ &\mathbf o^{(t)} = \mathbf c + \mathbf V \mathbf h^{(t)} \\ & \hat {\mathbf y} ^{(t)} = softmax(\mathbf o^{(t)}) \end{aligned} a(t)=b+Wh(t−1)+Ux(t)h(t)=tanh(a(t))o(t)=c+Vh(t)y^(t)=softmax(o(t))
这个循环网络将一个输入序列映射到相同长度的输出序列。与 x x x序列配对的 y y y的总损失是所有时间步的损失之和。采用极大似然函数的负数作为损失函数:
L ( { x ( 1 ) , … , x ( τ ) } , { y ( 1 ) , … , y ( τ ) } ) = ∑ t L ( t ) = − ∑ t log P m o d e l ( y ( t ) ∣ { x ( 1 ) , … , x ( τ ) } ) \begin{aligned} &L(\{x^{(1)},\ldots,x^{(\tau)}\},\{y^{(1)},\ldots,y^{(\tau)}\}) \\ &= \sum_{t} L^{(t)} \\ &= -\sum_{t} \log P_{model}(y^{(t)}|\{x^{(1)},\ldots,x^{(\tau)}\}) \end{aligned} L({x(1),…,x(τ)},{y(1),…,y(τ)})=t∑L(t)=−t∑logPmodel(y(t)∣{x(1),…,x(τ)})
接下来通过时间反向传播(back-propagation through time,BPTT)来更新网络参数。
每一次梯度计算涉及执行一次前向传播,接着是由右到左的反向传播。运行时
间是 O ( τ ) O(τ ) O(τ),并且不能通过并行化来降低,因为前向传播图是固有循序的; 每个时间
步只能一前一后地计算。前向传播中的各个状态必须保存,直到它们反向传播中被
再次使用,因此内存代价也是 O ( τ ) O(\tau) O(τ)。
通过时间反向传播
循环神经网络的参数包括 U , V , W , b , c \mathbf U,\mathbf V,\mathbf W,\mathbf b,\mathbf c U,V,W,b,c,对于每一个节点N,需要基于N后面的节点的梯度,递归进行计算。
从最终的损失的节点开始递归:
∂ L ∂ L ( t ) = 1 \frac{\partial L}{\partial L^{(t)}} = 1 ∂L(t)∂L=1
如下图所示:
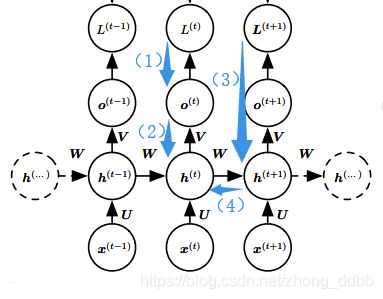
可知通过时间反向传播梯度,注意 h ( t ) \mathbf h^{(t)} h(t) 同时具有 o ( t ) \mathbf o^{(t)} o(t) 和 h ( t + 1 ) \mathbf h^{(t+1)} h(t+1) 后续两个节点,所以 L L L对 h ( t ) \mathbf h^{(t)} h(t)的求导包括两个部分 L ( t ) L^{(t)} L(t)对 h ( t ) \mathbf h^{(t)} h(t)的求导和 L ( t + 1 ) L^{(t+1)} L(t+1)对 h ( t ) \mathbf h^{(t)} h(t)的求导。
(1)损失函数 L L L关于时间步 t t t 的输出 o ( t ) \mathbf o^{(t)} o(t) d的梯度,先给出求导结果:
( ∇ o ( t ) L ) i = ∂ L ∂ o i ( t ) = ∂ L ∂ L ( t ) ∂ L ( t ) ∂ o i ( t ) = y ^ i ( t ) − 1 i , y ( t ) = { y ^ i ( t ) − 1 y ^ i ( t ) − 0 (\nabla_{\mathbf o^{(t)}} L)_i = \frac{\partial L}{\partial o_{i}^{(t)}} = \frac{\partial L}{\partial L^{(t)}} \frac{\partial L^{(t)}}{\partial o_{i}^{(t)}} = \hat {y}_i ^{(t)} -\mathbf 1_{i,y^{(t)}} = \begin{cases} \hat {y}_i ^{(t)} - 1 \\ \hat {y}_i ^{(t)} - 0 \end{cases} (∇o(t)L)i=∂oi(t)∂L=∂L(t)∂L∂oi(t)∂L(t)=y^i(t)−1i,y(t)={y^i(t)−1y^i(t)−0
上式可以理解为:期望输出的概率—该位置对应的真实label, 1 i , y ( t ) 1_{i,y^{(t)}} 1i,y(t)表示label,有两种取值0或1。
这个求导过程比较复杂,可以参考softmax回归详解,文中详细推导了以下结论:
若:
s i = e z i ∑ j = 1 K e z i i = 1 , 2 , … , K L ( w ) = − log P ( y ( i ) ∣ x ( i ) ; w ) s_{i} = \frac{e^{z_i}}{\sum_{j=1}^K e^{z_i}} \quad i=1,2,\ldots,K\\ L(w) = - \log P(y^{(i)}|x^{(i)};w) \\ si=∑j=1Keziezii=1,2,…,KL(w)=−logP(y(i)∣x(i);w)
则:
∂ L ∂ z i = s i − y i \frac{\partial \mathrm{L}}{\partial \mathrm{z}_{i}}= s_i - y_i ∂zi∂L=si−yi
其中:
s i s_i si 为经过softmax的结果,可以理解为概率,对应RNN中的 y ^ i ( t ) \hat {y}_i ^{(t)} y^i(t)。
y i = 1 或 y i = 0 y_i=1 或 y_i =0 yi=1或yi=0,对应RNN中的 1 i , y ( t ) 1_{i,y^{(t)}} 1i,y(t)。
z i z_i zi对应RNN的输出 o ( t ) \mathbf o^{(t)} o(t)。
(2)所以 L L L 对 h ( τ ) \mathbf h^{(\tau)} h(τ) 求导
∇ h ( τ ) L = V T ∇ o ( τ ) L \nabla_{\mathbf h^{(\tau)}}L = \mathbf V^T \nabla_{\mathbf o^{(\tau)}} L ∇h(τ)L=VT∇o(τ)L
(3)最终的梯度下降包括两个部分。
∇ h ( t ) L = ( ∂ h ( t + 1 ) ∂ h ( t ) ) ⊤ ( ∇ h ( t + 1 ) L ) + ( ∂ o ( t ) ∂ h ( t ) ) ⊤ ( ∇ o ( t ) L ) = W ⊤ ( ∇ h ( t + 1 ) L ) diag ( 1 − ( h ( t + 1 ) ) 2 ) + V ⊤ ( ∇ o ( t ) L ) \begin{array}{l} \nabla_{h^{(t)}} L=\left(\frac{\partial \boldsymbol{h}^{(t+1)}}{\partial \boldsymbol{h}^{(t)}}\right)^{\top}\left(\nabla_{\boldsymbol{h}^{(t+1)}} L\right)+\left(\frac{\partial \boldsymbol{o}^{(t)}}{\partial \boldsymbol{h}^{(t)}}\right)^{\top}\left(\nabla_{\boldsymbol{o}^{(t)}} L\right) \\ =\boldsymbol{W}^{\top}\left(\nabla_{\boldsymbol{h}^{(t+1)}} L\right) \operatorname{diag}\left(1-\left(\boldsymbol{h}^{(t+1)}\right)^{2}\right)+\boldsymbol{V}^{\top}\left(\nabla_{\boldsymbol{o}^{(t)}} L\right) \end{array} ∇h(t)L=(∂h(t)∂h(t+1))⊤(∇h(t+1)L)+(∂h(t)∂o(t))⊤(∇o(t)L)=W⊤(∇h(t+1)L)diag(1−(h(t+1))2)+V⊤(∇o(t)L)
其中:
∂ h ( t + 1 ) ∂ h ( t ) = ∂ tanh ( b + W h ( t ) + U x ( t + 1 ) ) ∂ h ( t ) = W T d i a g ( 1 − ( h ( t + 1 ) ) 2 ) \begin{aligned} \frac{\partial \boldsymbol{h}^{(t+1)}}{\partial\boldsymbol{h}^{(t)}} &= \frac{\partial \tanh(\mathbf b + \mathbf W \boldsymbol h^{(t)} + \mathbf U \mathbf x^{(t+1)} )}{\partial\boldsymbol{h}^{(t)}} \\ &= \mathbf W^T diag(1-(\boldsymbol h^{(t+1)})^2) \end{aligned} ∂h(t)∂h(t+1)=∂h(t)∂tanh(b+Wh(t)+Ux(t+1))=WTdiag(1−(h(t+1))2)
注: tanh ′ ( x ) = 1 − ( t a n h ( x ) ) 2 \tanh'(x) = 1- (tanh(x))^2 tanh′(x)=1−(tanh(x))2
d i a g ( 1 − ( h ( t + 1 ) ) 2 ) diag(1-(\boldsymbol h^{(t+1)})^2) diag(1−(h(t+1))2) 是包含元素 1 − ( h i ( t + 1 ) ) 2 1-(h_i^{(t+1)})^2 1−(hi(t+1))2的对角矩阵。
(4)更新参数
通过前面的步骤,可以得到以下参数梯度:
∇ c L = ∑ t ( ∂ o ( t ) ∂ c ) ⊤ ∇ o ( t ) L = ∑ t ∇ o ( t ) L ∇ b L = ∑ t ( ∂ h ( t ) ∂ b ( t ) ) ⊤ ∇ h ( t ) L = ∑ t diag ( 1 − ( h ( t ) ) 2 ) ∇ h ( t ) L ∇ V L = ∑ t ∑ i ( ∂ L ∂ o i ( t ) ) ∇ V o i ( t ) = ∑ t ( ∇ o ( t ) L ) h ( t ) ⊤ ∇ W = ∑ t ∑ i ( ∂ L ∂ h i ( t ) ) ∇ W ( t ) h i ( t ) = ∑ t diag ( 1 − ( h ( t ) ) 2 ) ( ∇ h ( t ) L ) h ( t − 1 ) ⊤ ∇ U L = ∑ t ∑ i ( ∂ L ∂ h i ( t ) ) ∇ U ( t ) h i ( t ) = ∑ t diag ( 1 − ( h ( t ) ) 2 ) ( ∇ h ( t ) L ) x ( t ) ⊤ \begin{aligned} \nabla_{c} L &=\sum_{t}\left(\frac{\partial \boldsymbol{o}^{(t)}}{\partial \boldsymbol{c}}\right)^{\top} \nabla_{\boldsymbol{o}^{(t)}} L=\sum_{t} \nabla_{\boldsymbol{o}^{(t)}} L \\ \nabla_{\boldsymbol{b}} L &=\sum_{t}\left(\frac{\partial \boldsymbol{h}^{(t)}}{\partial \boldsymbol{b}^{(t)}}\right)^{\top} \nabla_{\boldsymbol{h}^{(t)}} L=\sum_{t} \operatorname{diag}\left(1-\left(\boldsymbol{h}^{(t)}\right)^{2}\right) \nabla_{\boldsymbol{h}^{(t)}} L \\ \nabla_{\boldsymbol{V}} L &=\sum_{t} \sum_{i}\left(\frac{\partial L}{\partial o_{i}^{(t)}}\right) \nabla_{\boldsymbol{V}} o_{i}^{(t)}=\sum_{t}\left(\nabla_{o^{(t)}} L\right) \boldsymbol{h}^{(t)^{\top}} \\ \nabla_{\boldsymbol{W}} &=\sum_{t} \sum_{i}\left(\frac{\partial L}{\partial h_{i}^{(t)}}\right) \nabla_{\boldsymbol{W}^{(t)}} h_{i}^{(t)} \\ &=\sum_{t} \operatorname{diag}\left(1-\left(\boldsymbol{h}^{(t)}\right)^{2}\right)\left(\nabla_{\boldsymbol{h}^{(t)}} L\right) \boldsymbol{h}^{(t-1)^{\top}} \\ \nabla_{U} L &=\sum_{t} \sum_{i}\left(\frac{\partial L}{\partial h_{i}^{(t)}}\right) \nabla_{\boldsymbol{U}^{(t)}} h_{i}^{(t)} \\ &=\sum_{t} \operatorname{diag}\left(1-\left(\boldsymbol{h}^{(t)}\right)^{2}\right)\left(\nabla_{\boldsymbol{h}^{(t)}} L\right) \boldsymbol{x}^{(t)^{\top}} \end{aligned} ∇cL∇bL∇VL∇W∇UL=t∑(∂c∂o(t))⊤∇o(t)L=t∑∇o(t)L=t∑(∂b(t)∂h(t))⊤∇h(t)L=t∑diag(1−(h(t))2)∇h(t)L=t∑i∑(∂oi(t)∂L)∇Voi(t)=t∑(∇o(t)L)h(t)⊤=t∑i∑(∂hi(t)∂L)∇W(t)hi(t)=t∑diag(1−(h(t))2)(∇h(t)L)h(t−1)⊤=t∑i∑(∂hi(t)∂L)∇U(t)hi(t)=t∑diag(1−(h(t))2)(∇h(t)L)x(t)⊤
几种特殊RNN
基于上下文的RNN
将向量序列 X = ( x ( 1 ) , … , x ( n x ) ) \mathbf X = (\boldsymbol x^{(1)},\ldots,\boldsymbol x^{(n_x)}) X=(x(1),…,x(nx)) 作为输入,而不是仅接收单个向量 x \boldsymbol x x 作为输入。这类RNN适用于很多任务如图注,其中单个图像作为模型的输入,然后产生描述图像的词序列。观察到的输出序列的每个元素 y ( t ) y^{(t)} y(t) 同时用作输入(对于当前时间步)和训练期间的目标(对于前一时间步)。
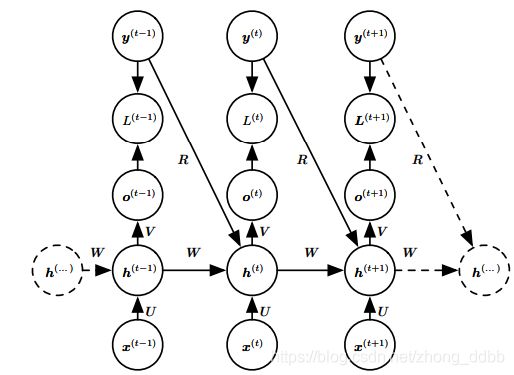
此RNN包含从前一个输出到当前状态的连接。
双向RNN
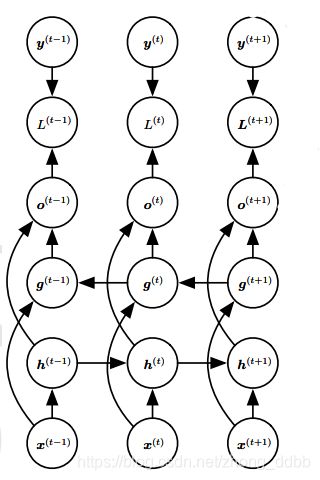
双向RNN是指结合时间上从序列起点开始移动的RNN和另一个时间上从序列末尾开始移动的RNN,典型的双向RNN如下图所示:
其中 h ( t ) \boldsymbol h^{(t)} h(t)代表通过时间向前移动的子RNN的状态, g ( t ) \boldsymbol g^{(t)} g(t)代表通过时间向后移动的子RNN的状态,此时,输出单元 o ( t ) \boldsymbol o^{(t)} o(t) 可以受益于输入 h ( t ) \boldsymbol h^{(t)} h(t) 关于过去的相关信息以及输入 g ( t ) \boldsymbol g^{(t)} g(t) 中关于未来的相关信息。
基于编码—解码的序列到序列架构
这种RNN最大的特点是输入序列和输出序列不一定等长。
主要想法是:
(1)编码器RNN处理输入序列,编码器输出上下文C,这个C是一个概况输入序列 X = ( x ( 1 ) , … , x ( n x ) ) \mathbf X = (\boldsymbol x^{(1)},\ldots,\boldsymbol x^{(n_x)}) X=(x(1),…,x(nx)) 的向量或向量序列。
(2)解码器RNN则以固定长度向量为条件产生输出序列 Y = ( y ( 1 ) , … , y ( n y ) ) \mathbf Y = (\boldsymbol y^{(1)},\ldots,\boldsymbol y^{(n_y)}) Y=(y(1),…,y(ny))。
(3)两个RNN共同训练以最大化 log P ( y ( 1 ) , … , y ( n y ) ∣ x ( 1 ) , … , x ( n x ) ) \log P(\boldsymbol y^{(1)},\ldots,\boldsymbol y^{(n_y)}|\boldsymbol x^{(1)},\ldots,\boldsymbol x^{(n_x)}) logP(y(1),…,y(ny)∣x(1),…,x(nx))

主要应用有语音识别,机器翻译和问答系统。
RNN缺陷:无法做到长期依赖
权值 W W W角度
回顾RNN模型
循环联系:
h ( t ) = W T h ( t − 1 ) \boldsymbol h^{(t)} = \boldsymbol W^T \boldsymbol h^{(t-1)} h(t)=WTh(t−1)
可以简化为:
h ( t ) = ( W t ) T h ( 0 ) \boldsymbol h^{(t)} = (\boldsymbol W^t)^T \boldsymbol h^{(0)} h(t)=(Wt)Th(0)
当 W \boldsymbol W W 符合下列形式的特征分解:
W = Q Σ Q T \boldsymbol W = \boldsymbol Q \boldsymbol \Sigma \boldsymbol Q^T W=QΣQT
其中 Q \boldsymbol Q Q是正交矩阵。
所以:
h ( t ) = Q T Σ t Q h ( 0 ) \boldsymbol h^{(t)} = \boldsymbol Q^T \boldsymbol \Sigma^t \boldsymbol Q \boldsymbol h^{(0)} h(t)=QTΣtQh(0)
对于 Σ t \boldsymbol \Sigma^t Σt ,经过 t t t次相乘后,即:经过多个阶段的传播后:如果特征值小于1,特征值将衰减到零。如果特征值大于1,经过 t t t次相乘后,特征值将激增。任何不与最大特征向量对齐的 h ( 0 ) \boldsymbol h^{(0)} h(0)的部分将最终被丢弃,无法做到长期依赖。
梯度消失/爆炸角度
如下图所示:
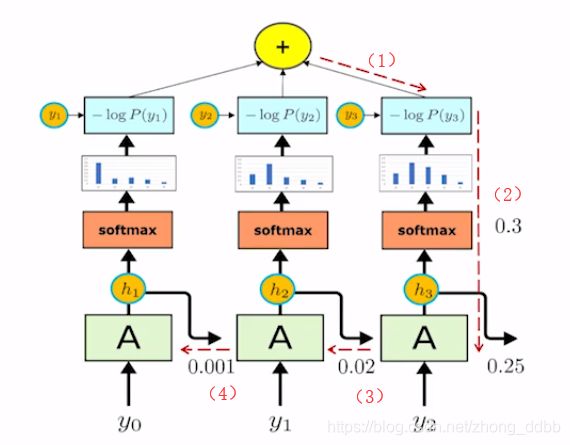
如上图(1)-(4)的反向传播过程:
∂ J ∂ y 0 = ∂ J ∂ h 3 ∂ h 3 ∂ h 2 ∂ h 2 ∂ h 1 ∂ h 1 ∂ y 0 \frac{\partial J}{\partial y_0} = \frac{\partial J}{\partial h_3}\frac{\partial h_3}{\partial h_2} \frac{\partial h_2}{\partial h_1} \frac{\partial h_1}{\partial y_0} ∂y0∂J=∂h3∂J∂h2∂h3∂h1∂h2∂y0∂h1
如果这个过程中:
(1)这一连串偏导数都小于1,这些小数连乘,可能会导致最终的结果趋于0,甚至等于0,造成梯度消失。梯度消失意味着无法通过加深网络层数来提升预测效果,只有靠近输出的几层才真正起到学习的作用,这样RNN很难学习到输入序列中的长距离依赖关系。
(2)这一连串偏导数都大于1,这些数连乘,可能会导致最终的结果趋于无穷大,造成梯度爆炸。以通过梯度裁剪来缓解,即当梯度的范式大于某个给定值的时候,对梯度进行等比缩放。
为了解决以上两个问题,我们引入LSTM。
RNN应用
RNN通常用于处理离散序列数据(离散线性,长度可变);
从RNN结构来理解其应用:
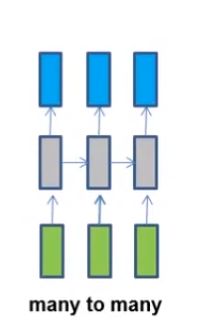
(1)词性标注,输入是每个词对应的向量,输出是词对应的词性。网络结构如下:
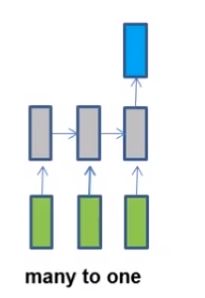
(2)情感分析,输入一句话,输出其情感的倾向标签。网络结构如下:
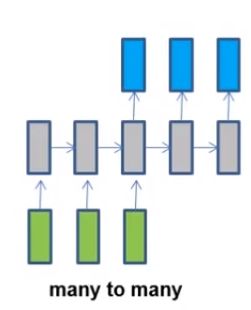
(3)机器翻译,输入是一种语言,输出是另一种语言。网络结构如下:
(4)图片文字生成,输入是一张图片,生成图片的描述。网络结构如下:
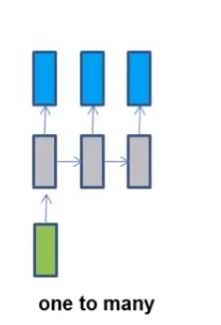
从功能的角度理解RNN应用:
(1)序列数据的分析,如市场趋势预测。
(2)序列数据的生成,如基于图片的诗歌创作。
(3)序列数据的转换,如语音识别,机器翻译。