机器学习——从基本概念到入手
机器学习——从基本概念到入手
-
- 基本概述
-
- 什么是机器学习
- 什么是数据集
- 机器学习的算法怎么分类
-
- 监督学习
- 无监督学习
- 数据集
-
- Sklearn数据集的基本操作
-
- 小数据集的获取
- 大数据集的获取
- 获取数据的返回类型
- 数据集的划分
-
- sklern划分数据集API
- 特征工程
-
- 特征提取
-
- 字典特征提取
- 文本特征提取
- 中文特征提取
- Tf-idf文本特征提取
- 特征预处理
-
- 归一化(小数据)
- 标准化(大数据)
- 特征降维
-
- 特征选择
-
- Filter(过滤式)
-
- 方差选择法(低方差特征过滤)
- 相关系数(特征之间的相关程度)
- 主成分分析
基本概述
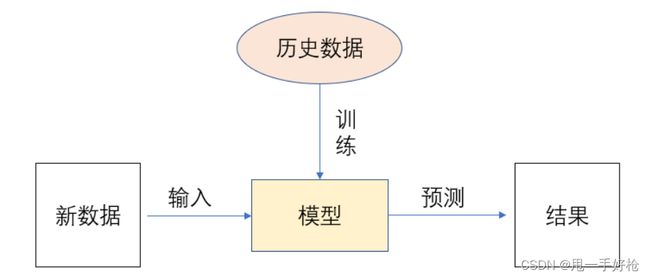
什么是机器学习
从数据中自动分析获得模型,并利用模型对未知模型对位置数据进行预测。
什么是数据集
构成:特征值 + 目标值
如下:前面四个(房子面积、位置、朝向、楼层都是特征值、价格是我们的目标值)——>是我们自己设置的。
样本:每一行数据我们称之为一个样本。
注:有些数据集可以没有数据集。
| 房子面积 | 房子位置 | 房子朝向 | 房子楼层 | 价格(目标值) |
|---|---|---|---|---|
| 80 | 9 | 0 | 9 | 80 |
| 100 | 4 | 1 | 1 | 120 |
| 80 | 10 | 3 | 10 | 100 |
机器学习的算法怎么分类
| 目标值 | 算法类别 | |
|---|---|---|
| 类别 | 分类问题 | 监督学习 |
| 连续性数值 | 回归问题 | 监督学习 |
| 无 | 无监督学习 | 无监督学习 |
监督学习
定义:输入数据是由输入特征值和目标值所组成。函数可以是一个连续的值(称为回归),或是输出的是有限个离散的值(称为分类)。
无监督学习
定义:输入的数据是由输入特征值组成的。
数据集
Sklearn数据集的基本操作
| sklearn.datasets | 加载获取流行数据集 |
|---|---|
| datasets.load_*() | 获取小规模数据集,数据包含在datasets中 |
| datasets.fetch_*(data_home = None) | 获取大规模数据集,需要从网络中下载,data_home = ’ 下载目录 ‘,默认是’ scikit_learn_data ’ |
小数据集的获取
# 加载并返回鸢尾花数据集(常用)
sklearn.datasets.load_iris()
| 名称 | 数量 |
|---|---|
| 类别 | 3 |
| 特征 | 4 |
| 样本数量 | 150 |
| 每个类别数量 | 50 |
# 加载并获取波士顿放假数据集
sklearn.datasets.load_boston()
| 名称 | 数量 |
|---|---|
| 目标类别 | 5-50 |
| 特征 | 13 |
| 样本数量 | 506 |
大数据集的获取
sklearn.datasets.fetch_*(data_home = None, subset = '?')
# suset: 'train', 'test', 'all', 选择要加载的数据集
获取数据的返回类型
无论是load还是fetch,其返回类型均是dataset.base.Bunch(字典格式)
- data: 特征数据组
- target: 标签数组
- DESCR: 数据描述
- feature_names: 特征名
- target_names: 标签名
注:我们可以通过dict.key获取键值对,也可以通过dict[“key”]获取键值对
测试:
from sklearn.datasets import load_iris
def datasets_demo():
iris = load_iris()
# 直接全部打印出来,你会发现,你不想看了,nnd,乱成一遭
print("鸢尾花数据集:\n", iris)
print("鸢尾花数据集描述:\n", iris["DESCR"])
print("鸢尾花数据集特征名字:\n", iris.feature_names)
print("鸢尾花数据集标签名字:\n", iris.target_names)
print("鸢尾花数据集特征数据:\n", iris.data)
print("鸢尾花数据集标签数据:\n", iris.target)
return None
if __name__ == '__main__':
datasets_demo()
数据集的划分
| train(训练集) | test(测试集) |
|---|---|
| 用于训练,构建模型 | 用于检验模型,评估模型是否有效 |
sklern划分数据集API
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(*.data, *.target, test_size =*, random_state = *)
# x:表示训练集
# y:表示测试集
# test_size:测试集大小,一般为float
# random_state:随机数种子,进行随机采样,相同的种子,采样结果相同
代码测试:
def datasets_demo1():
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split( iris.data, iris.target, test_size = 0.2, random_state = 22)
print("训练集特征值:\n", x_train, x_train.shape)
return None
特征工程
定义:使用专业背景只是和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
意义:会直接影响机器学习效果。
特征提取
作用:将任意数据(文本、图像等),转化成可以用于机器学习的数字特征。(为了更好的让计算机去处理数据)
API:
sklearn.feature_extraction
字典特征提取
作用:对字典数据进行特征值化
sklearn.feature_extraction.DictVectorize(sparse = True...)
from sklearn.feature_extraction import DictVectorizer
| 函数 | 传入值 | 返回值 |
|---|---|---|
| DictVectorizer.fit_transform(x) | x:字典或者字典的迭代器 | sparse矩阵 |
| DictVectorizer.inverse_transform(x) | x:array数组或者sparse矩阵 | 转换前的数据格式 |
| DictVectorizer.get_feature_names() | none | 返回类别名称 |
代码测试:
def dict_demo():
data = [{'city' : '北京', 'temperature' : 100}, {'city' : '上海', 'temperature' : 60}, {'city' : '深圳' , 'temperature' : 30}]
# 1. 实例化转换器类
transform = DictVectorizer(sparse=False)
# 2. 调用函数.fit_transform,但是返回的是洗漱矩阵,只表示了非 0 值,想要全部表示,要在实例化对象时令sparse = false
data_new = transform.fit_transform(data)
print("data_feature_name:\n", transform.get_feature_names())
print("data_new:\n", data_new)
return None
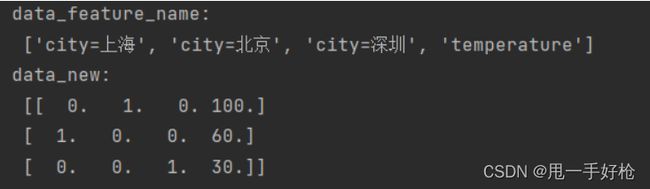
总之,就是把字典中每一个不同的**’ key '**,当成特征。
文本特征提取
作用:对文本数据进行特征值化,统计每个样本特征词出现的个数。
| 函数 | 输入 | 输出 |
|---|---|---|
| sklearn.frature_extraction.text.CountVectorizer(stop_words = [‘停用词’]) | 返回词频矩阵 | |
| CountVectorizer.fit_transform(x) | x:字典或者字典的迭代器 | sparse矩阵 |
| CountVectorizer.inverse_transform(x) | x:array数组或者sparse矩阵 | 转换前的数据格式 |
| CountVectorizer.get_feature_names() | none | 返回单词列表 |
代码测试
def dict_Textdemo():
data = ["too young to simple", "too poor too tried"]
# 1. 实例化
transform = CountVectorizer()
# 2. 调用函数
data_new = transform.fit_transform(data)
print("data_feature_name:\n", transform.get_feature_names())
print("data_new:\n", data_new.toarray())
return None
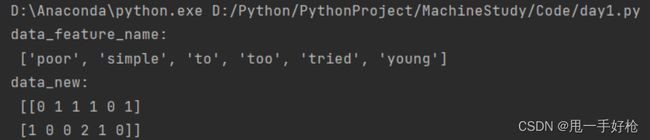
注:上述对中文的特征提取不友好,不能自动的划分词义,并且手动划分会将单个汉字给省略。
中文特征提取
其原理与文本特征提取相同,不同的地方是需要import jiba这个库,进行分词,因为中文不是按照空格间隔开,无法判断短语单词。
def cut_word(text):
# 将根据jieba处理后的文本分割(“按空格”)
text = " ".join(list(jieba.cut(text)))
return text
return None
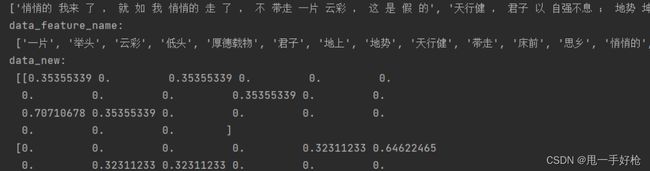
def count_chinese_demo2():
data = [
"悄悄的我来了,就如我悄悄的走了,不带走一片云彩,",
"天行健,君子以自强不息;地势坤,君子以厚德载物。",
"床前明月光,疑是地上霜,举头望明月,低头思故乡。"
]
data_new = []
# 0. 将中文文本进行分词
for sent in data:
data_new.append(cut_word(sent))
print(data_new)
# 1. 实例化对象
transform = CountVectorizer()
# 2. 调用函数
data_final = transform.fit_transform(data_new)
print("data_feature_name:\n", transform.get_feature_names())
print("data_new:\n", data_final.toarray())
return None
结果展示:

Tf-idf文本特征提取
关键词:在某一个类别的文章中出现的次数很多,但是在其他类别的文章中出现的次数很少。
主要思想:如果某一个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为该词语和短语具有很好的类别区分能力,适合用于分类。
作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
tf:词频,某一个给定词语在文件中出现的概率。
idf:逆向文档频率,一个词语普遍重要性的度量。
idf计算:总文件数目除以包含该词语的文件数目,再将得到的商取以10为底的对数得到。
tf-idf = tf * idf
# 实例化
TfidfVectorizer = sklearn.feature_extractiion.text.TfidfVectorizer(stop_words = )
# 方法
TfidfVectorizer.fit_transform(X)
# X:文本或者包含文本字符串的可迭代对象
# 返回值是一个sparse矩阵
TfidfVectorizer.inverse_transform(X)
# X:sparse矩阵或array数组
# 返回值,转换前的数据格式
TfidfVectorizer.get_feature_names()
# 返回值,单词列表
代码
def tfidf_demo():
data = [
"悄悄的我来了,就如我悄悄的走了,不带走一片云彩,这是假的",
"天行健,君子以自强不息;地势坤,君子以厚德载物。这是真的",
"床前明月光,疑是地上霜,举头望明月,低头思故乡。这是思乡"
]
data_new = []
# 0. 将中文文本进行分词
for sent in data:
data_new.append(cut_word(sent))
print(data_new)
# 1. 实例化对象
transform = TfidfVectorizer()
# 2. 调用函数
data_final = transform.fit_transform(data_new)
print("data_feature_name:\n", transform.get_feature_names())
print("data_new:\n", data_final.toarray())
return None
结果:TfidfVectorizer、CountVectorizer都是文本特征提取,转换器内置方法不同
特征预处理
定义:通过一些转换函数将特征数据转化成更加适合算法模型的特征数据过程。(归一化、标准化——无量纲化)
无量纲化:使不同规格的数据转换到统一规格
为什么要进行归一化、标准化?
原因:特征的单位或大小相差较大,或者某特征的方差比其它的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其他的特征。
归一化(小数据)
实验数据并且学习笔记均来自于黑马程序员,下面用到的文件可自取:
链接:https://pan.baidu.com/s/1M2YsslnHRXE8fh36ixnBQA
提取码:1234
–来自百度网盘超级会员V3的分享
定义:通过对原始数据进行变化把数据映射到(0,1]之间
X ′ = x − m i n m a x − m i n X^{'} = \frac{x - min}{max - min} X′=max−minx−min
x :该特征对应数值
min:该列特征的最小值
max:该列特征的最大值
X ′ ′ = X ′ ∗ ( m x − m i ) + m i X^{''} = X^{'} * (mx - mi) +mi X′′=X′∗(mx−mi)+mi
mx:映射后范围的最大值
mi:映射后范围的最小资
API
# 实例化对象
MinMaxScalar = sklearn.preprocessing.MinMaxScaler(feature_range = (0, 1))
MinMaxScalar.fit_transform(X)
# X:numpy.array格式的数据[n_samples , n_features]
# 返回值:转换后形状相同的array
代码测试:三步走:一、拿数据 二、实例化sklearn中的对象 三、运行实例化对象的函数
def minmax_demo():
# 获取数据
data = pd.read_csv(r"D:\Python\PythonProject\MachineStudy\text\dating.txt")
# print("data\n", data)
data = data.iloc[:, :3]
# 实例化转换器对象
transform = MinMaxScaler()
data_new = transform.fit_transform(data)
print(data_new)
总结:最大最小是变化的,并且最大最小值容易受到异常点的影响,故其鲁棒性较差,只适合传统精确小数据场景。
标准化(大数据)
定义:将原始数据进行变化,把数据变换到均值为0,标准差为1的范围内
X ′ = x − m e a n σ X^{'} = \frac{x-mean}{\sigma } X′=σx−mean
mean:均值
σ:标准差
API
# 实例化对象
StandarScale = sklearn.preprocessing.StandarScale()
StandaeScale.fit_transform(X)
# X:numpy.array格式的数据[n_samples , n_features]
# 返回值:转换后形状相同的array
代码测试:
def stand_demo():
# 获取数据
data = pd.read_csv(r"D:\Python\PythonProject\MachineStudy\text\dating.txt")
# print("data\n", data)
data = data.iloc[:, :3]
# 实例化转换器对象
transform = StandardScaler()
data_new = transform.fit_transform(data)
print(data_new)
特征降维
定义:再某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程。
- 降低随机变量个数
特征选择
定义:数据中包含冗余或相关变量(特征、属性、指标等),旨在原有特征中找出主要特征。
Filter(过滤式)
方差选择法(低方差特征过滤)
特征方差小:某个特征大多数样本值比较相近
特征方差大:某个特征大多数样本都有差别
API
# 实例化对象
Variance = sklearn.feature_selection.VarianceThreshold(threshold = 0.0)
# 作用:删除所有低方差特征
variance.fit_transform(X)
# X:numpy.array格式的数据[n_samples , n_features]
# 返回值:训练集差异低于threshold的特征删除
代码测试:(过滤一些不必要的特征)
def variance_demo():
data = pd.read_csv(r"D:\Python\PythonProject\MachineStudy\text\factor_returns.csv")
# print(data)
data = data.iloc[:, 1:-2]
# print(data)
transform = VarianceThreshold(threshold=5)
data_new = transform.fit_transform(data)
print(data_new)
相关系数(特征之间的相关程度)
皮尔逊相关系数:反映变量之间相关关系密切程度的统计指标
相关系数就是其绝对值越接近1,说明相关性越大,如果本身是负数,称为负相关,如果是正数,称为正相关。
API
from scipy.stats import personr
x:(N,) array_like
y: (N,) array_like
Returns: (Person’s correlation coefficient, p-value)
主成分分析
定义:高维数据转换成低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量。
作用:数据维数压缩,尽可能降低原数据的维度(复杂度),损失少量信息。
API
# 实例化对象
sklearn.decomposition.PCA(n_components = None)
# n_components:小数表示保留百分之多少的信息。整数表示减少到多少特征。
PCA.fit_fit_transform(X)
# X:numpy.array格式的数据[n_samples , n_features]
# 返回值:转换后指定维度的array