GCN——初步理解
最近在看关于知识图谱融合的最新文献过程中,发现在实现embedding的时候采用最多、效果极佳的方法就是利用维基的词向量作为GCN的输入,从而得到包含语义和空间结构的embedding。所以这两天找了些关于GCN的资料看,并做个简单记录,方便以后复习,若发现错误或不太准确的地方,恳请指正。
一、宏观理解GCN是什么?——特征提取器
在CNN、RNN如此强大的模型之后,为什么出现GCN?
CNN:针对图像(二维数据结构),它的核心在于其kernel,一个滑动窗口,通过卷积来提取特征。因为图像具有平移不变性:滑动窗口无论移动到图片的哪一个位置,其内部的结构都是一模一样的,因此CNN可以实现参数共享。这就是CNN的精髓所在。
RNN:针对自然语言(序列信息,一维结构),通过各种门的操作,使得序列前后的信息互相影响,从而很好地捕捉序列的特征。
上面讲的图片或者语言,都属于欧式空间的数据,因此才有维度的概念,欧式空间的数据的特点就是结构很规则。但是现实生活中,其实有很多很多不规则的数据结构,典型的就是图结构,或称拓扑结构,如社交网络、化学分子结构、知识图谱等等;即使是语言,实际上其内部也是复杂的树形结构,也是一种图结构;而像图片,在做目标识别的时候,我们关注的实际上只是二维图片上的部分关键点,这些点组成的也是一个图的结构。【引用:https://zhuanlan.zhihu.com/p/71200936】
由此,针对图这种十分不规则、无限维,不具备平移不变性的的结构,CNN和RNN就无法发挥作用,很多学者从上个世纪就开始研究怎么处理这类数据了。这里涌现出了很多方法,例如GNN、DeepWalk、node2vec等等,GCN只是其中一种,这里只讲GCN。
现在就不难理解,GCN实际上可以看作一个特征提取器(类似于CNN的作用),不同的是它的处理对象为图结构数据。利用GCN提取出的特征,我们可以实现节点分类(node classification)、图分类(graph classification)、边预测(link prediction),还可以得到图的嵌入表示(graph embedding)。
二、对GCN思想的理解
我看很多资料都从谱域讲到空域,一路下来描述了很多,就我个人而言没看懂。不求完全掌握每一个理论知识,只是想理解整个思想的我,果断放弃钻研。
现在我们来看看GCN核心部分的内容:
它是一个神经网络层,且仅仅是一个全连接层。(下图是一个2层的GCN例子)
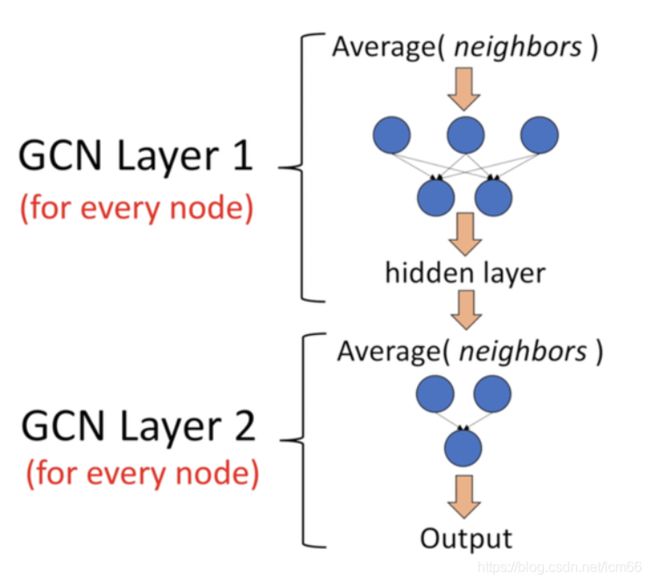
假设有一组图数据,包含N个节点(node),每个节点有自己的特征信息,我们设这些节点的特征组成一个N×D维的矩阵X,然后各个节点之间的关系也会形成一个N×N维的矩阵A,即,邻接矩阵(adjacency matrix)。那么X和A便是我们模型的输入。
该网络的传播方式为:
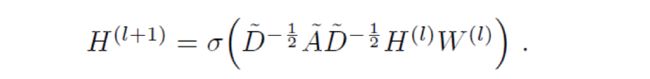
其中,
(1)A波浪=A+I,I是单位矩阵;
(2)D波浪是A波浪的度矩阵(degree matrix);
(3)H是每一层的特征,对于输入层的话,H0就是X;
(4)σ是非线性激活函数。
至于为什么要这样去设计一个公式,先不考虑。现在只需要知道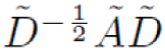 这个部分是可以事先计算得到的,因为D波浪由A计算得来,而A是输入之一。对于不需要去了解数学原理、只想应用GCN来解决实际问题的人来说,就只需知道:这个GCN设计了一个强大的公式,用这个公式就可以很好地提取图的特征,就够了。
这个部分是可以事先计算得到的,因为D波浪由A计算得来,而A是输入之一。对于不需要去了解数学原理、只想应用GCN来解决实际问题的人来说,就只需知道:这个GCN设计了一个强大的公式,用这个公式就可以很好地提取图的特征,就够了。
进一步理解。引用一张图:
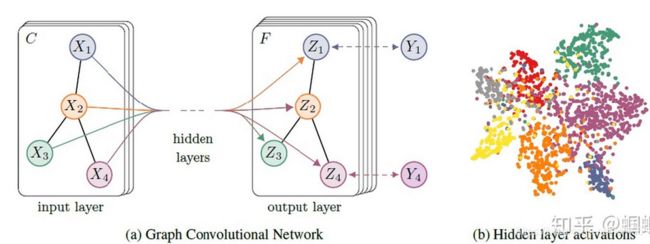
上图中的GCN输入一个图,通过若干层GCN每个node的特征从X变成了Z,但是,无论中间有多少层,node之间的连接关系,即A,都是共享的。也就是说解决了上面说的不具备平移不变性问题。其思路是:借鉴CNN,将卷积分为三步:
(1)选定中心节点后,确定邻域:对每个节点选择固定个数的节点作为邻居;
(2)给邻域结点编号;
(3)参数共享:选择固定大小的窗口进行参数共享。

三、GCN公式为什么这样设计
参考论文作者,由简入繁:
每一层GCN的输入都是邻接矩阵A和node的特征H,那么我们考虑直接做一个内积,再乘一个参数矩阵W,然后激活一下,就相当于一个简单基础的神经网络层嘛。如下:
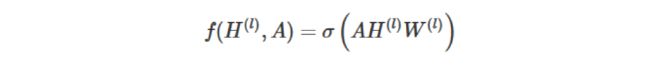
实验证明,即使就这么简单的神经网络层,就已经很强大。
上面这个简单的模型存在几个局限:
(1)由于A的对角线上都是0,所以在和特征矩阵H相乘的时候,只会计算一个node的所有邻居的特征的加权和,该node自己的特征却被忽略了。因此,做了一个小小的改动,给A加上一个单位矩阵I,这样就让对角线元素变成1了。
(2)A是没有经过归一化的矩阵,这样与特征矩阵相乘会改变特征原本的分布,产生一些不可预测的问题。所以我们对A做一个标准化处理。首先让A的每一行加起来为1,我们可以乘以一个 ![]() ,D就是度矩阵。考虑每一列做到归一化,所以我们可以进一步把
,D就是度矩阵。考虑每一列做到归一化,所以我们可以进一步把![]() 拆开与A相乘,得到一个对称且归一化的矩阵
拆开与A相乘,得到一个对称且归一化的矩阵![]() 。此设计与对称归一化拉普拉斯矩阵十分类似,而在谱图卷积的核心就是使用对称归一化拉普拉斯矩阵,这也是GCN的卷积叫法的来历。(具体的我也不懂,只知道是这样,从而说明了谱域的图卷积是空域图卷积的子集。)
。此设计与对称归一化拉普拉斯矩阵十分类似,而在谱图卷积的核心就是使用对称归一化拉普拉斯矩阵,这也是GCN的卷积叫法的来历。(具体的我也不懂,只知道是这样,从而说明了谱域的图卷积是空域图卷积的子集。)
通过对上面两个局限的改进,我们便得到了最终的层特征传播公式:
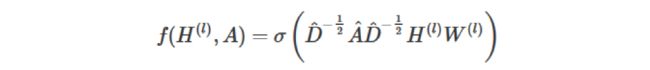
四、从数学角度简单模拟
下面用一个例子记录GCN强大公式是如何起作用的。
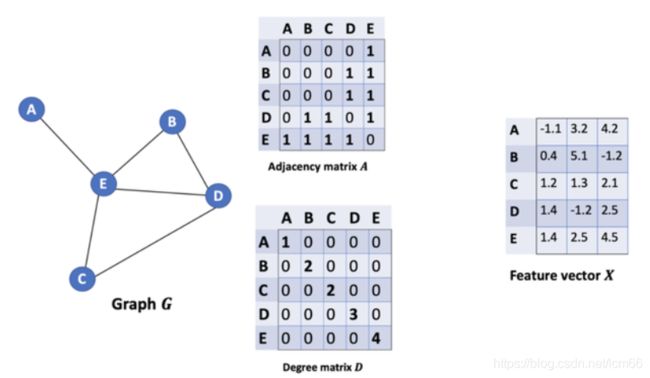
【引用:https://baijiahao.baidu.com/s?id=1678519457206249337&wfr=spider&for=pc】
直接将矩阵A与矩阵X相乘,得到的矩阵第一行就是与A相连接的E节点的特征向量(如下图)。同理,得到的矩阵的第二行是D和E的特征向量之和,通过这个方法,我们可以得到所有邻居节点的向量之和。
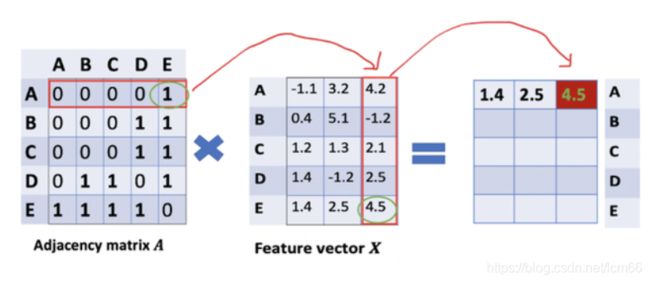
此时的计算还存在上述章节三中提到的局限(1)忽略了节点本身的特征。按理得到的矩阵第一行应该包含结点A和E的信息,所以做出改进:
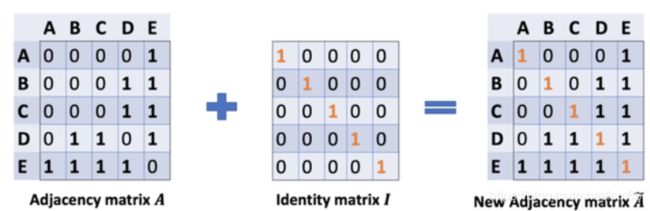
通过给每个节点增加一个自循环,我们得到新的邻接矩阵。
对于局限(2)矩阵缩放,实现归一化。
在矩阵缩放中,通常考虑乘上一个对角矩阵,正好度矩阵D为对角矩阵,一定存在这某种关联,所以有了如下的改进:
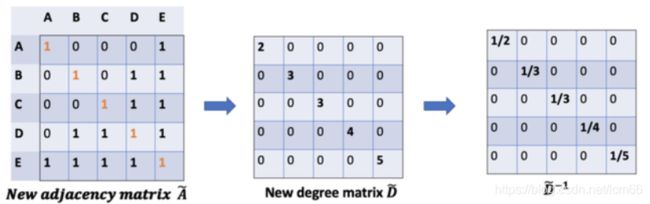
因此,通过D取反和X的乘法,我们可以取所有邻居节点的特征向量(包括自身节点)的平均值。
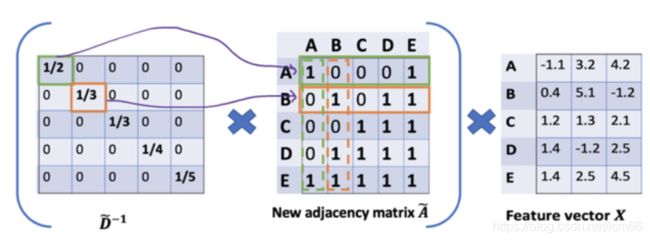
按照上图左乘一个D波浪逆矩阵,我们只是按行缩放(即,行归一化),而忽略了对应的列(虚线框)。【缩放方法给我们提供了 "加权 "的平均值。我们在这里做的是给低度的节点加更多的权重,以减少高度节点的影响。这个加权平均的想法是,我们假设低度节点会对邻居节点产生更大的影响,而高度节点则会产生较低的影响,因为它们的影响力分散在太多的邻居节点上。】
所以,进行了两次归一化处理,左乘和右乘了D波浪的-1/2逆。
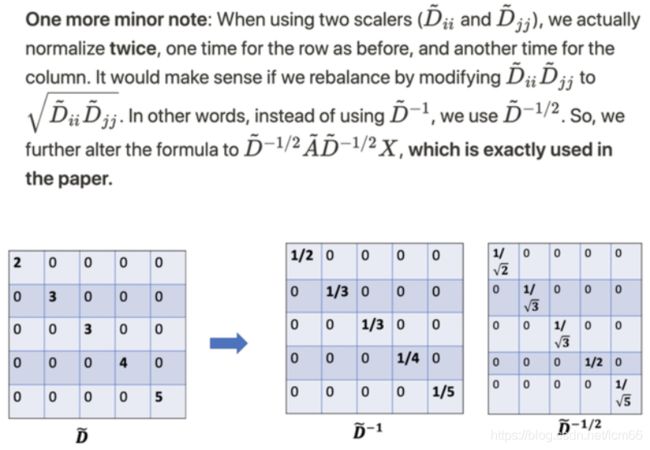
至此,强大的GCN公式诞生。
五、其他关于GCN的点滴
- 对于很多网络,我们可能没有节点的特征,这个时候可以使用GCN吗?答案是可以的,如论文中作者对那个俱乐部网络,采用的方法就是用单位矩阵 I 替换特征矩阵 X。
- 我没有任何的节点类别的标注,或者什么其他的标注信息,可以使用GCN吗?当然,就如前面讲的,不训练的GCN,也可以用来提取graph embedding,而且效果还不错。
- GCN网络的层数多少比较好?论文的作者做过GCN网络深度的对比研究,在他们的实验中发现,GCN层数不宜多,2-3层的效果就很好了。
- GCNs同时使用节点特征和结构进行训练。
- 该框架目前仅限于无向图(加权或不加权)。但是,可以通过将原始有向图表示为一个无向的两端图,并增加代表原始图中边的节点,来处理有向边和边特征。