TensorFlow1(一)全连接神经网络识别mnist数据集
首先我们来介绍一下mnist数据集
MNIST数据集由Yann LeCun搜集,是一个大型的手写体数字数据库,通常用于训练各种图像处理系统,也被广泛用于机器学习领域的训练和测试。MNIST数字文字识别数据集数据量不会太多,而且是单色的图像,较简单,适合深度学习初学者练习建立模型、训练、预测。MNIST数据库中的图像集是NIST(National Institute of Standards and Technology)的两个数据库的组合:专用数据库1和特殊数据库3。数据集是有250人手写数字组成,一半是高中生,一半是美国人口普查局。
MNIST数据集共有训练数据60000项、测试数据10000项。每张图像的大小为28*28(像素),每张图像都为灰度图像,位深度为8(灰度图像是0-255)。
模型(一)
这个模型是一个比较简单的全连接神经网络,我设置了两个全连接层,矩阵规格的变化如下:
( [ None , 28 * 28 ] * [ 28 * 28 , 10 ] + [ 10 ] ) * [ 10 , 10 ] + [ 10 ]
其中第一个全连接层的权重为[ 28 * 28 , 10 ] ,偏置为 [ 10 ]
其中第二个全连接层的权重为[ 10 , 10 ] ,偏置为 [ 10 ]
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
def full_connect():
# 用全连接对手写数字进行识别
# 1、准备数据
mnist = input_data.read_data_sets("data", one_hot=True)
x = tf.placeholder(dtype=tf.float32,shape=[None,28*28])
y_true = tf.placeholder(dtype=tf.float32,shape=[None,10])
# 2、构建模型
Weights_1 = tf.Variable(initial_value=tf.random_normal(shape=[784,10]))
bias_1 = tf.Variable(initial_value=tf.random_normal(shape=[10]))
Weights_2 = tf.Variable(initial_value=tf.random_normal(shape=[10,10]))
bias_2 = tf.Variable(initial_value=tf.random_normal(shape=[10]))
middle = tf.matmul(x,Weights_1) + bias_1
y_predict = tf.matmul(middle,Weights_2) + bias_2
# 3、构造损失函数
error = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true,logits=y_predict))
# 4、优化损失
optimizer = tf.train.AdamOptimizer(learning_rate=0.01).minimize(error)
# 计算准确率
equal_list = tf.equal(tf.argmax(y_true,1),
tf.argmax(y_predict,1))
accuracy = tf.reduce_mean(tf.cast(equal_list,tf.float32))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
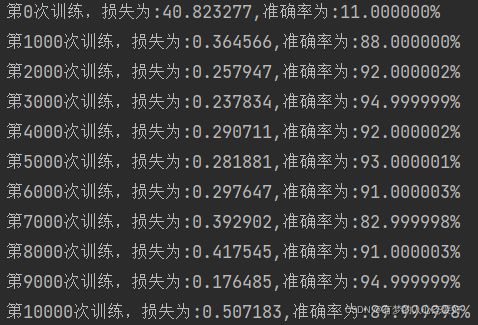
print("训练之前,损失为:%f" % sess.run(error,feed_dict={x:image,y_true:label}))
#开始训练
for i in range(30000):
image, label = mnist.train.next_batch(100)
a,loss,accuracy_rate = sess.run([optimizer,error,accuracy],feed_dict={x:image,y_true:label})
print("第%d次训练,损失为:%f" %(i+1,loss))
print("准确率为:%f" % accuracy_rate)
return None
if __name__ == "__main__":
full_connect()最后我们需要调节参数来提高准确率,我们能提升的方面如下:
1)增加训练次数
2)调节学习率
3)调节权重系数的初始化值
4)改变优化器
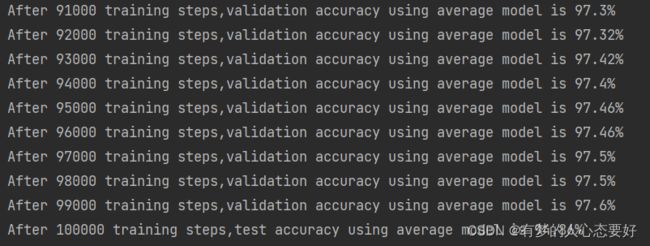
附带一张使用AdamOptimizer优化器,初始学习率为0.01,训练十万轮次的训练结果

模型(二)
这个模型也是两层的全连接神经网络,全连接层的规模如下:
( [ None , 28 * 28 ] * [ 28 * 28 , 500 ] + [ 500 ] ) * [ 500 , 10 ] + [ 10 ]
其中第一个全连接层的权重为[ 28 * 28 , 500 ] ,偏置为 [ 500 ]
其中第二个全连接层的权重为[ 500 , 10 ] ,偏置为 [ 10 ]
这个模型采用的是 GradientDescentOptimizer优化器,该优化器是一个梯度下降优化器,这个优化器实现了梯度下降算法。这个模型还增加了正则化方法,要比第一个模型更复杂,因此准确率也更高。
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("data",one_hot=True)
batch_size = 100 # 设置每一轮训练的batch的大小
learning_rate = 0.8 # 初始学习率
learning_rate_decay = 0.999 # 学习率的衰减
max_steps = 300000 # 最大训练步数
training_step = tf.Variable(0, trainable=False)
# 定义训练轮数的变量,一般将训练轮数变量的参数设为不可训练的 trainable = False
# 定义得到隐藏层到输出层的向前传播计算方式,激活函数使用relu() 向前传播过程定义为hidden_layer()函数
def hidden_layer(input_tensor, weights1, biases1, weights2, biases2, layer_name):
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
return tf.matmul(layer1, weights2) + biases2
# x在运行会话是会feed图片数据 y_在会话时会feed答案(label)数据
x = tf.placeholder(tf.float32, [None, 784], name="x-input")
y_ = tf.placeholder(tf.float32, [None, 10], name="y-output")
# 生成隐藏层参数,其中weights包含784*500=392000个参数
weights1 = tf.Variable(tf.truncated_normal([784, 500], stddev=0.1))
biases1 = tf.Variable(tf.constant(0.1, shape=[500]))
# 生成输出层参数,其中weights包含50000个参数
weights2 = tf.Variable(tf.truncated_normal([500, 10], stddev=0.1))
biases2 = tf.Variable(tf.constant(0.1, shape=[10]))
# y得到了前向传播的结果
y = hidden_layer(x, weights1, biases1, weights2, biases2, 'y')
# 实现一个变量的滑动平均首先需要通过train.ExponentiadlMoving-Average()函数初始化一个滑动平均类,同时需要向函数提供一个衰减率
averages_class = tf.train.ExponentialMovingAverage(0.99, training_step) # 初始化一个滑动平均类,衰弱率为0.99
# 同时这里也提供了num_updates参数,将其设置为training_step
averages_op = averages_class.apply(tf.trainable_variables()) # 可以通过类函数apply()提供要进行滑动平均计算的变量
# 再次计算经过神经网络前向传播后得到的y值,这里使用了滑动平均,但要牢记滑动平均只是一个影子变量
averages_y = hidden_layer(x, averages_class.average(weights1),
averages_class.average(biases1),
averages_class.average(weights2),
averages_class.average(biases2), 'average_y')
# 接下来我们进行交叉熵计算
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=tf.argmax(y_,1))
regularizer = tf.contrib.layers.l2_regularizer(0.0001)
regularization = regularizer(weights1) + regularizer(weights2)
loss = tf.reduce_mean(cross_entropy) + regularization
learning_rate = tf.train.exponential_decay(learning_rate,training_step,mnist.train.num_examples/batch_size,learning_rate_decay)
training_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=training_step)
with tf.control_dependencies([training_step,averages_op]):
train_op = tf.no_op(name="train")
crorent_predicition = tf.equal(tf.argmax(averages_y,1),tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(crorent_predicition,tf.float32))
with tf.Session() as sess:
tf.global_variables_initializer().run()
validate_feed = {x:mnist.validation.images,y_:mnist.validation.labels}
test_feed = {x:mnist.test.images,y_:mnist.test.labels}
for i in range(max_steps):
if i % 1000 == 0:
validate_accuracy = sess.run(accuracy,feed_dict=validate_feed)
print("After %d training steps,validation accuracy using average model is %g%%"%(i,validate_accuracy*100))
xs, ys = mnist.train.next_batch(batch_size=100)
sess.run(train_op, feed_dict={x: xs, y_: ys})
test_accuracy = sess.run(accuracy, feed_dict=test_feed)
print("After %d training steps,test accuracy using average model is %g%%" % (max_steps, test_accuracy * 100))
准确率如下: