ITK-SNAP + c3d 处理 3D 图像以及 DICOM 格式
❤️❤️❤️ c3d 是一个免费的、强大到无以复加的 3D 图像处理工具,它尤其在深度学习医学图像研究和应用中能发挥出无与伦比的生产力 —— 我
我将以 Pancreas-CT 数据集及其标签为例,简要介绍 c3d 处理 dicom 格式 3D 图像(dicom 转成 nii)、Nifti 格式 3D 图像的常用功能
下载安装 c3d 和 ITK-SNAP
官网下载地址:http://www.itksnap.org/pmwiki/pmwiki.php?n=Downloads.C3D
记得把 c3d 命令加入到环境变量中,方便调用。
数据
-
Pancreas-CT(raw dicom files):
https://wiki.cancerimagingarchive.net/display/Public/Pancreas-CT
-
Labels(Nifiti files)
https://zenodo.org/record/1169361/files/label_tciapancreasct_multiorgan.tar.gz?download=1
处理 dicom 图片
dicom 图片是一系列 .dcm 格式的文件组成的一个文件夹,没错,一个 dicom 图片是一个文件夹。
接下来我们使用 c3d 把一个 dicom 图片(PANCREAS_0001)转成 Nifti(.nii.gz) 格式:
-
进入到 dicom 图片文件夹
Pancreas-99667的父目录$ cd \Pancreas-CT\PANCREAS_0001\11-24-2015-PANCREAS0001-Pancreas-18957 -
使用命令
c3d -dicom-series-list获取 dicom series id$ c3d -dicom-series-list Pancreas-99667 输出: SeriesNumber Dimensions NumImages SeriesDescription SeriesID 512x512x240 240 Pancreas 1.2.826.0.1.3680043.2.1125.1.68878959984837726447916707551399667.512512那长串序列就是 dicom series id。
-
使用命令
c3d -dicom-series-read读取 dicom 文件并保存成.nii.gz格式$ c3d -dicom-series-read Pancreas-99667 1.2.826.0.1.3680043.2.1125.1.64196995986655345161142945283707267.512512 -o PANCREAS_0001.nii.gz不一会儿,当前文件夹下便生成了由 dicom 格式转换而来的 Nifty 图像。
需要注意的是每次运行
c3d -dicom-series-list命令获取到的 dicom series id 是不同的,一定要即时获取 ID,即时复制该 ID 来读取图片,使用错误的 dicom series id 会报错说找不到 series dicom files。
处理 nii 图片
c3d 提供了许多可选参数来处理 .nii.gz 格式的 3D 图像,比如:-info、-region、-resample、-type、-thresh、-voxel-sum 等等,给深度学习医学图像的数据预处理带来了许多便利。
-
进入到 label_tcia_multiorgan 文件夹
$ cd label_tcia_multiorgan -
使用
c3d label0002.nii.gz -info命令查看该 label 的信息$ c3d label0002.nii.gz -info 输出: Image #1: dim = [512, 512, 195]; bb = {[0 0 0], [460 460 195]}; vox = [0.898438, 0.898438, 1]; range = [0, 14]; orient = RPS -
使用以下命令 cropped 3D label,并 resample 到指定的分辨率
$ c3d label0002.nii.gz -region 84x153x0vox 378x279x169vox -resample 144x144x144 -type short -o label_processed.nii.gz其中:
-
-region vOrigin vSize:第一个参数 vOrigin 是裁剪的起始点(原点)位置(xyz),第二个参数 vSize(xyz)是从起始点开始需裁剪的大小,参数的格式如上命令所示,其中的乘号x为英文字母x。 -
-resample:通过改变体素间距来改变图像大小。 -
-type:指定输出图像的像素值类型,默认为 float,这里 label 图像的分割标签像素值为整形,所以指定为 short。
这里不得不提到如何寻找
-region的裁剪起始点及裁剪大小:使用 ITK-SNAP 软件打开 label 图像:
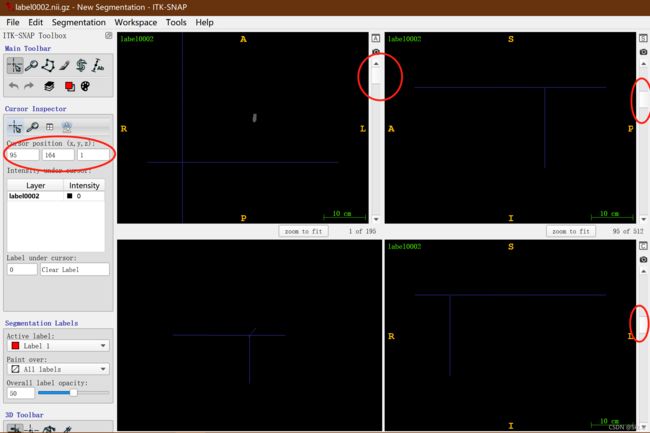
- 先后在三个视图中向上滑动红圈中的滑块,使图中的有色标签都正好看不到,然后记录左边大红圈中 xyz 的坐标值(95,164,1),以此为裁剪起始点;
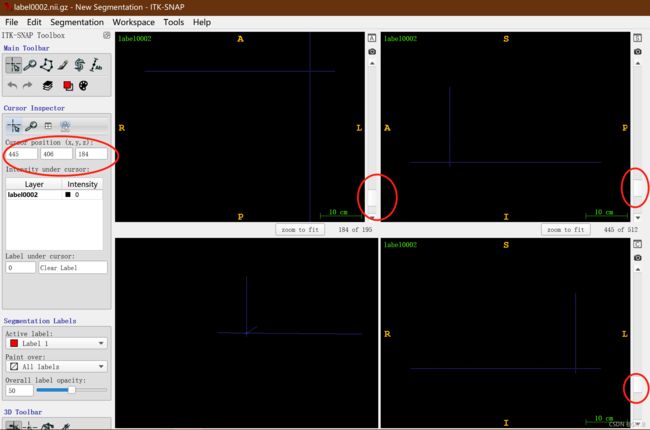
- 先后在三个视图中向下滑动红圈中的滑块,使图中的有色标签都正好看不到,然后记录左边大红圈中 xyz 的坐标值(445,406,184),以此为裁剪终点;
裁剪大小 vSize 便可由以上两个坐标相减得到:(445,406,184)-(95,164,1)=(350,242,183),即,vSize = 350x242x183vox,vOrigin = 95x146x1vox。
-
-
使用相同的命令处理 3D Pancreas-CT。
同理,Pancreas-CT 图像也使用同样的裁剪坐标。
使用 python 进行批处理
- 转 dicom 为 nii
import os
import subprocess
# from subprocess import call
list_of_labels = [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 16, 17, 18, 19, 20, 21, 22, 24, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49]
root = '~/pancreas_ct/' # 原 Pancreas-CT 数据集文件夹
saved_dir = root + "preprocess/Pancreas_CT/" # 转换完成的 nii.gz 保存路径
if not os.path.exists(saved_dir):
os.mkdir(saved_dir)
for i in range(len(list_of_labels)):
name = 'PANCREAS_' + str(list_of_labels[i]).zfill(4)
print('name:', name)
dict0 = root + 'Pancreas-CT/' + name
dict1 = next(os.walk(dict0))[1][0]
dict1 = os.path.join(dict0, dict1)
dict2 = next(os.walk(dict1))[1][0]
dict2 = os.path.join(dict1, dict2).replace("\\", "/") # windows下使用 \ 来拼接路径,这会出错
print("dict2:", dict2)
# 首先要获取 dicom series id
list_command = 'c3d -dicom-series-list ' + dict2
proc = subprocess.Popen(list_command, stdout=subprocess.PIPE, shell=True)
out, err = proc.communicate() # out 就是执行命令的输出结果, type=bytes
p_status = proc.wait() # 等待子进程结束
line = out.splitlines()[1].decode() # Decode the bytes
series_id = line.split()[-1]
print('reading series_id:', series_id)
# 使用 dicom read 来读取 dicom 及转换格式
# saved_name = saved_dir + name + '.nii.gz'
read_command = 'c3d -dicom-series-read ' + dict2 + ' ' + series_id + ' -o ' + name + '.nii.gz'
proc = subprocess.Popen(read_command, stdout=subprocess.PIPE, shell=True)
p_status = proc.wait()
# subprocess.call(read_command)
print("err:", err)
print("out:", out)
print(f'{name} has been converted to nii.gz')
# 查看值为 0 的体素数量
count_command = 'c3d ' + name + '.nii.gz -thresh 0 0 1 0 -voxel-sum'
proc = subprocess.Popen(count_command, stdout=subprocess.PIPE, shell=True)
out, err = proc.communicate()
p_status = proc.wait()
print('out check:', out.decode())
c3d label.nii.gz -thresh 0 0 1 0 -voxel-sum表示:把在 range(0,0) 之间的体素设成 1,其余体素设成 0,-voxel-sum计算整个图像的体素值之和。这里即计算值为 0 的体素数量。
- 裁剪 nii 图像
import os
import subprocess
# from subprocess import call
import pandas
label_path = r"~\label_tcia_multiorgan" # 标签数据集文件夹
ct_path = r"~\preprocess\Pancreas_CT" # 转换完成的 nii.gz格式 Pancreas-CT 图像文件夹
df1 = pandas.read_csv('cropping.csv') # cropping.csv 通过上面的方法记录下来的裁剪坐标,你可以用你的方式记录
print(len(df1))
for i in range(1, 43 + 1, 1): # len(list_of_labels)):
# Image #1: dim = [512, 512, 210]; bb = {[0 0 0], [439.296 439.296 210]}; vox = [0.858, 0.858, 1]; range = [
# -2048, 1371]; orient = RPS
list_id = int(df1.loc[i - 1, :]['original_id'])
new_id = int(df1.loc[i - 1, :]['id'])
name_ct = 'PANCREAS_' + str(list_id).zfill(4)
name_label = 'label' + str(list_id).zfill(4)
name_ct_path = os.path.join(ct_path, name_ct).replace("\\", "/")
name_label_path = os.path.join(label_path, name_label).replace("\\", "/")
print('name', name_ct, 'label', name_label)
info_command = 'c3d ' + name_label_path + ' -info'
proc = subprocess.Popen(info_command, stdout=subprocess.PIPE, shell=True)
line, err = proc.communicate()
p_status = proc.wait()
print("line:", line.decode().split())
dim_z = int(line.decode().split()[6][:-2])
print('dimension_z_str', dim_z)
print(df1.loc[i - 1, :])
# print(df1.loc[i-1,:]['extent_ant'])
A1 = int(df1.loc[i - 1, :]['extent_ant'])
A2 = int(df1.loc[i - 1, :]['extent_post'])
A3 = int(df1.loc[i - 1, :]['extent_left'])
A4 = int(df1.loc[i - 1, :]['extent_right'])
A5 = int(df1.loc[i - 1, :]['extent_inf'])
A6 = int(df1.loc[i - 1, :]['extent_sup'])
# 读取裁剪坐标
region1 = str(A3) + 'x' + str(512 - A2) + 'x' + str(dim_z - A6) + 'vox ' + str(A4 - A3) + 'x' + str(
A2 - A1) + 'x' + str(A6 - A5) + 'vox'
print('region', region1) # vOrigin: 84x153x0vox vSize: 378x279x169vox
# 裁剪 label
label_command = 'c3d ' + name_label_path + '.nii.gz -region ' + region1 + \
' -int 0 -resample 144x144x144 -type short -o label_ct' + str(new_id) + '.nii.gz'
proc = subprocess.Popen(label_command, stdout=subprocess.PIPE, shell=True)
out, err = proc.communicate()
p_status = proc.wait()
print("out:", out.decode())
# 用同样的坐标裁剪 CT
scan_command = 'c3d ' + name_ct_path + '.nii.gz -type float -region ' + region1 + \
' -resample 144x144x144 -o pancreas_ct' + str(new_id) + '.nii.gz'
proc = subprocess.Popen(scan_command, stdout=subprocess.PIPE, shell=True)
out, err = proc.communicate()
p_status = proc.wait()
print("out:", out.decode())
print('pancreas_ct' + str(new_id) + '.nii.gz')
# 查看值为 0 的体素数量
count_command = 'c3d pancreas_ct' + str(new_id) + '.nii.gz -thresh 0 0 1 0 -voxel-sum'
proc = subprocess.Popen(count_command, stdout=subprocess.PIPE, shell=True)
out, err = proc.communicate()
p_status = proc.wait()
print("out:", out.decode())
# line = (out.splitlines()[1])
# series_id = str.split(line)[-1]
# print('reading series_id',series_id)