【机器学习】使用UE4制作KITTI格式数据集
目录
简介
KITTI数据集简介
Label解析
type
truncate
Occluded
Alpha
Bbox
Dimensions
Location
Rotation_y
简介
项目中使用到一个3D bounding box的开源项目,项目中使用的是KITTI自动驾驶数据集,队友使用NVIDIA Deep learning Dataset Synthesizer生成我们项目所需的虚拟数据集,需要将json格式的虚拟数据集转换成KITTI格式的数据集来使用。做完这一部分会自己尝试一下生成虚拟数据集部分。
要完成格式转换就需要将KITTI数据集label的各项参数搞懂。本文前部分会总结一些我现在所理清的参数含义,参考了KITTI的devkit中的readme文档和matlab部分的代码,还有很多没有完全搞清的部分。先记录搞明白的部分。
KITTI数据集简介
The data acquisition platform of KITTI dataset is equipped with two gray cameras, two color cameras, a velodyne 64 line 3D lidar, four optical lenses and a GPS navigation system.
The entire dataset we are using now is based on CAM2.
KITTI数据集的数据采集平台装配有2个灰度摄像机,2个彩色摄像机,一个Velodyne64线3D激光雷达,4个光学镜头,以及1个GPS导航系统。
- 相机:x 轴向右,y 轴向下,z 轴向前
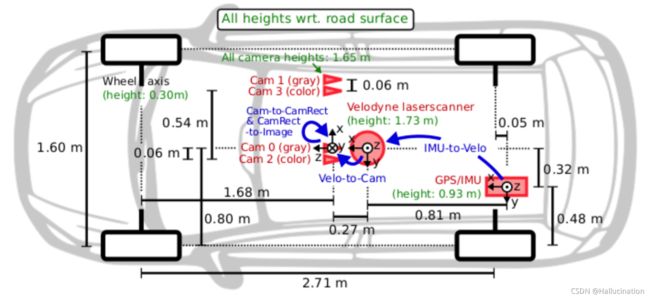
因为本项目不需要激光雷达和GPS等其他设备,只需要图像摄像头所得到的图像来生成3D Bounding box,所以只关注了Cam2的内容,训练使用的数据集也只是Left color images。
如果要使用虚拟引擎来制作虚拟数据集,坐标系需要和KITTI中相机的坐标系相对应。
Label解析
先从训练集来看,label文件中每个object有15个参数,每个参数的具体解释可以在devkit的readme文件中找到。
举例来说,这张图片是训练集中的其中一张
截取label文件的其中一句来分析:
Car 0.00 0 -1.56 564.62 174.59 616.43 224.74 1.61 1.66 3.20 -0.69 1.69 25.01 -1.59
对应devkit中readme文件对label的解析:
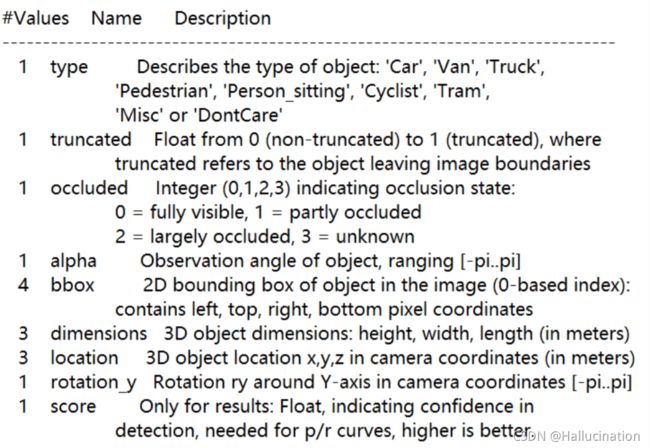
type
- type : Car
物体的分类为车
truncate
- truncated : 0
物体的完整程度(物体在边界之外的比例)
范围:float 0-1,0代表物体完整地在图片中
本例子中车完整地在图片中间,所以此参数为0
Occluded
- Occluded : 0
物体是否有缺损
0 = fully visible 完全可见
1 = partly occluded 部分缺损
2 = largely occluded 大部分缺损
3 = unknown 辨认不出
Alpha
- Alpha : -1.56
见后文和rotation_y放在一起解释。
Bbox
- Bbox : 564.62(left_x1), 174.59(top_y1), 616.43(right_x2), 224.74(bottom_y2)
2D bounding box:(x1, y1) 左上角坐标 (x2, y2) 右下角坐标
(pixel coordinates)二维像素坐标系
注意:NVIDIA虚拟引擎生成的虚拟数据导出的json文件中top_left和bottom_right的坐标中x和y是反的!

源自: Dataset_Synthesizer/NDDS.pdf at master · NVIDIA/Dataset_Synthesizer · GitHub page28
Dimensions
- Dimensions : 1.61(height), 1.66(width), 3.20(length) (in meters)
物体3D bounding box的长宽高(米),建立自身的坐标系
KITTI:
用于计算3DDB:(devkit/matlab/readLabels.m)
% 3D bounding box corners
This coordinate system is based on the object itself.
x_corners = [l/2, l/2, -l/2, -l/2, l/2, l/2, -l/2, -l/2];
y_corners = [0,0,0,0,-h,-h,-h,-h];
z_corners = [w/2, -w/2, -w/2, w/2, w/2, -w/2, -w/2, w/2];

注意:UE4生成数据的坐标系和上图的坐标系是不一样的,UE4使用的是标准的笛卡尔三维坐标系。如果只是变换坐标系是不难计算的,难点在于KITTI数据集中是使用物体3D bounding box的长宽高来生成物体在以自身建立的坐标系中各个顶点的坐标,从而使用旋转和加上物体原点在全局坐标系的坐标来得到每个顶点的全局三维坐标;而UE4直接生成每个顶点的全局三维坐标,如果需要还原到KITTI数据集中dimension项参数需要使用旋转和物体原点的坐标来反推物体的长宽高。
(这里还不知道应该怎么做,需要再查一些资料再有结论)
Location
- Location : -0.69(x), 1.69(y), 25.01(z)(in meters)
以物体3DDB自身建立的坐标系原点在系统坐标系的位置。
Rotation_y
- Rotation_y : -1.59 [-pi~pi] yaw angle
和前文的alpha是两种偏航角,yaw angle。
在三维空间中旋转有yaw、pitch、roll三种,分别对应y轴、x轴、z轴的旋转

因为在平地上的车不会有roll和pitch两种旋转,只会有yaw偏航角的变化,所以在KITTI数据集中只考虑yaw angle。
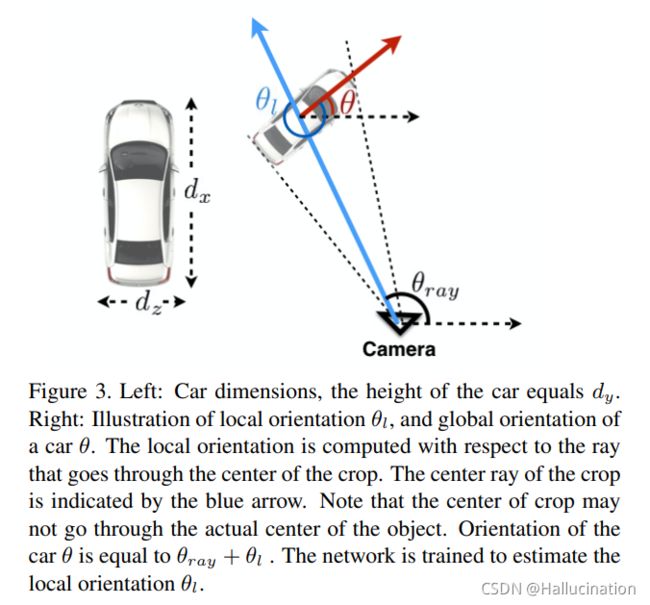
Note that following KITTI’s convention of assuming zero roll and zero pitch, the orientation is reduced to simply yaw. Thus the above two orientations are referred to as global yaw and local yaw as well.
此处的rotation_y指的是egocentric yaw angle,即以物体为中心的偏航角,前文的alpha指的是allocentric yaw angle,即从摄像头和物体的连线与物体行驶方向的角度。如下图所示,(a)图中的egocentric yaw是不变的,因为车一直直线行驶,而allocentric yaw是一直在变的。(b)图中的allocentric yaw是不变的,即摄像头和物体的连线与物体行驶方向的角度是不变的,一直是直角。

在3DDB原论文中解释的alpha和rotation_y的关系:
% Rotate the 3D bounding box with yaw angle(rotate around Y axis
(object.ry = rotation_y)
R = [+cos(object.ry), 0, +sin(object.ry);
0, 1, 0;
-sin(object.ry), 0, +cos(object.ry)];
corners_3D = R*[x_corners;y_corners;z_corners];
3x3 * 3x8 = 3x8
计算物体在旋转后的坐标
最终得到的3DDB的各点坐标:
% Translate 3D bounding box
object.t(1:3) : 3D object location in camera coordinates(见location部分)
corners_3D(1,:) = corners_3D(1,:) + object.t(1);
corners_3D(2,:) = corners_3D(2,:) + object.t(2);
corners_3D(3,:) = corners_3D(3,:) + object.t(3);
UE4生成的数据是四元数,这里我们需要的值是yaw angle,所以需要做四元数和欧拉角的转换
参考: 四元数与欧拉角(Yaw、Pitch、Roll)的转换_xiaoma_bk的博客-CSDN博客_四元数与欧拉角
(未完)