使用R语言对股票数据进行时间序列分析
tushareID:469251
R语言相对于python在做统计分析是十分方便的软件,时间序列分析在数理统计理论方面很有支撑,解释性也很强,理论已经很成熟,不了解的小伙伴可以去搜下相关课程。
这里记录一下简单的R语言做时间序列分析的流程。
数据来源于tushare导出的股价数据。使用91天的数据进行拟合模型,预测10天的数据。
数据预览:
library(xlsx)
library(mvtnorm)
library(DescTools)
library(forecast)
library(aTSA)
data <-read.xlsx2('data.xlsx',sheetIndex=1)
data_test <-read.xlsx2('data_1.xlsx',sheetIndex=1)
plot(data$close,type="l",xlab="时间",ylab="收盘价",main="收盘价时序图")
data_1<-as.numeric(data$close)
'原序列ADF检验'
adf.test(data_1)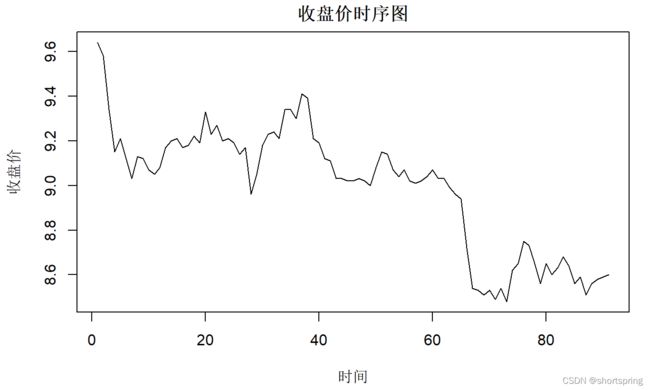
对原序列进行ADF检验:从原序列也能看出来其非平稳,非平稳的话需要进行差分。

对其进行二阶差分后,进行平稳性和白噪声检验。平稳性检验和白噪声检验均通过。
diff_data_1<-diff(data_1,diff=2)
plot(diff_data_1,type="l",main="1阶差分后时序图")
'1阶差分后工资性收入的ADF检验'
adf.test(diff_data_1)
'1阶差分后工资性收入的LB检验'
for(k in 1:4)
print(Box.test(diff_data_1,lag=1*k)) 

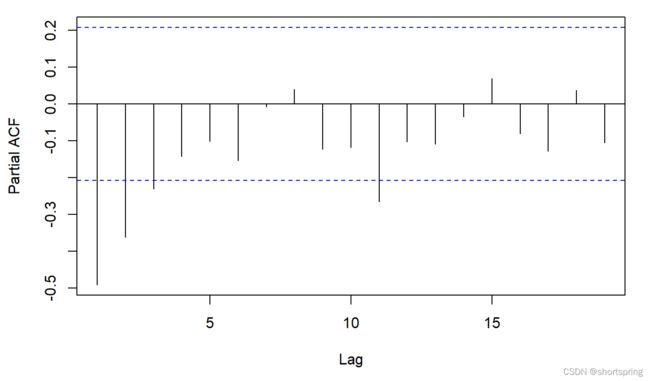
根据自相关图和偏自相关图来确定阶数。也可以根据AIC最小准则等来确定模型阶数。推荐根据通过自相关图和偏自相关图来确定阶数,往往会更准确一些。根据下面的自相关图1阶截尾,偏自相关图拖尾拟合ARIMA(0,2,1)模型。
acf(diff_data_1,main="自相关图") #画出自相关图
pacf(diff_data_1,main="偏自相关图") 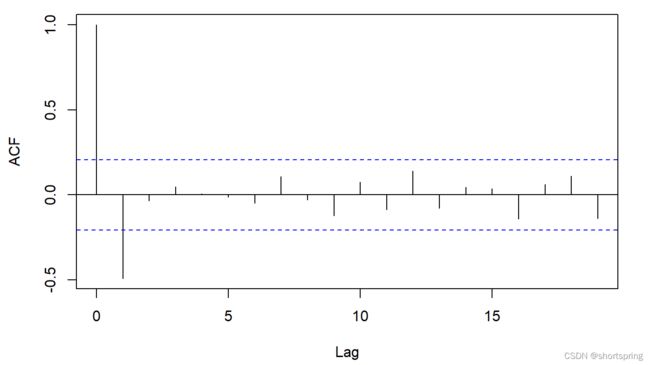
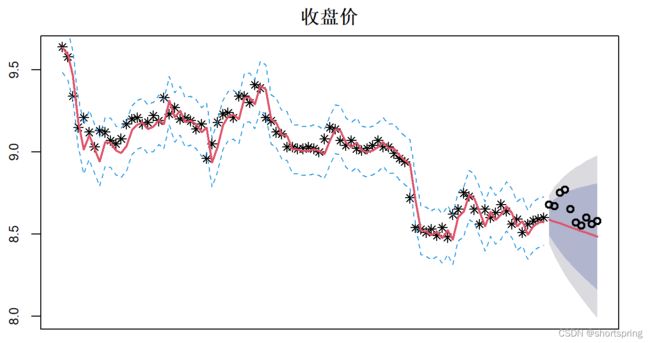
以下是预测结果,红色实线是拟合值,黑色星号是实际值,拟合效果虽然看起来不是很好,因为股票本就难以预测,,但通过这一套流程下来,用R做简单的时间序列是没有问题了,望有所帮助。
mod<-arima(data_1,order=c(0,2,1),transform.pars = T,method="ML")
"对模型参数进行检验"
t=abs(mod$coef)/sqrt(diag(mod$var.coef))
pt(t,length(data_1)-length(mod$coef),lower.tail = F)
"判断模型整体是否通过检验,对残差进行白噪声检验"
for(k in 1:4)
print(Box.test(mod$residuals,lag=1*k))
"进行预测,预测值及预测效果图如下"
fore <- forecast::forecast(mod,h=10)
'预测值'
fore$mean
a.fore=fore
a=mod
L1=a.fore$fitted-1.96*sqrt(a$sigma2)
U1=a.fore$fitted+1.96*sqrt(a$sigma2)
L2=ts(a.fore$lower[,2])
U2=ts(a.fore$upper[,2])
c1=min(data_1,L1,L2)
c2=max(data_1,L2,U2)
#d<-c(2011:2021)
#xlim=c(2011,2021),
par(cex.axis=0.8)
plot(fore,type="p",pch=8,lty=2,ylim=c(c1,c2),xaxt='n',xlab='年份',ylab='close',
main='收盘价')
lines(a.fore$fitted,col=2,lwd=2)
lines(a.fore$mean,col=2,lwd=2)
lines(L1,col=4,lty=2)
lines(U1,col=4,lty=2)
lines(c(92:101),data_test[,6],col=1,lwd=2,type="p")