PowerBI多元回归预测数据(R语言)
前几天写了一篇直接在PowerBI里面使用度量值做一元回归的内容,虽然灵活性很高,但是实际中对一个结果影响的因素是很多的,还是使用多元回归的场景更多。而且我们借助统计分析包不仅可以计算出回归参数,还可以看看一些衡量模型的重要指标,比如R2/调整的R2,还可以通过置信区间的设置来求出预测区间。
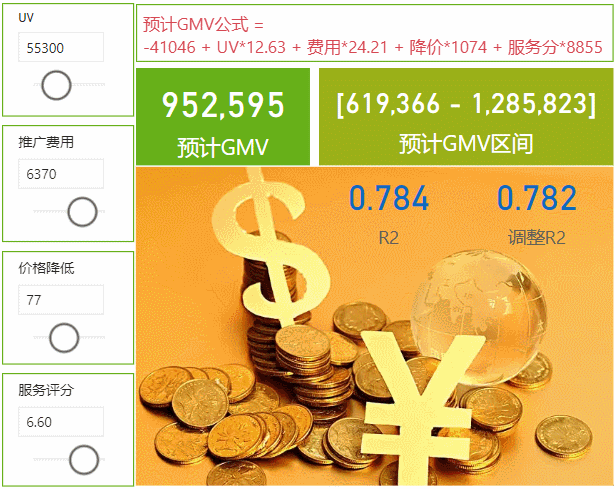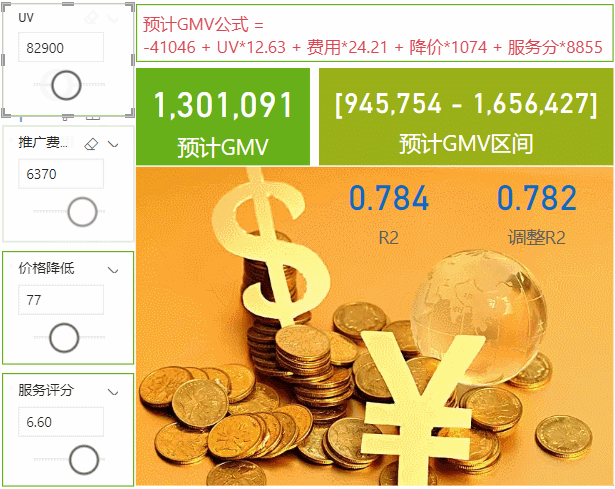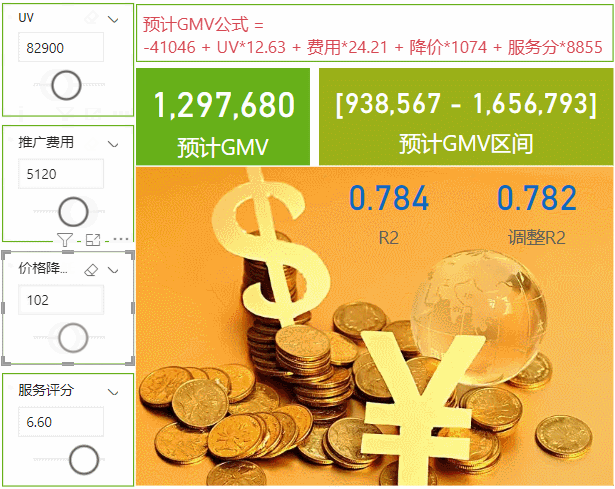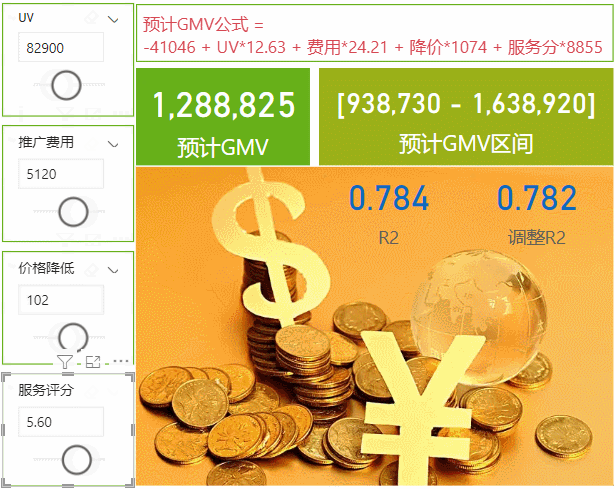
我们这次的案例是有四个影响GMV值得因素,UV访客数、推广费用的投入、整体商品降价水平(优惠力度)和客服的服务评分,通过计算这四个因素的具体影响值来求出预测GMV,本次使用的是在PowerBI数据集的基础上调用R script来实现,下次再来用Python实现。数据和模型会放在最后供下载学习使用,数据如下↓
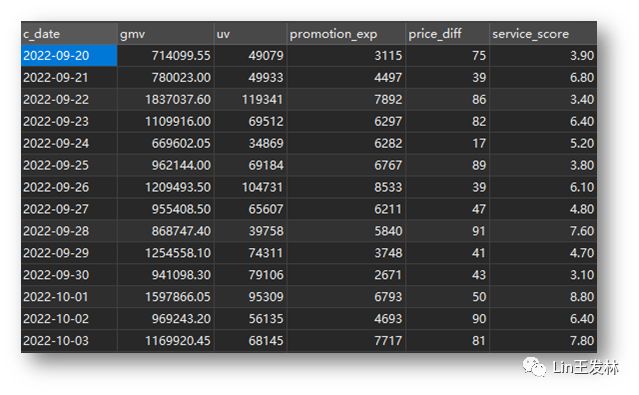
下面开始实现,首先在PowerQuery里面加载数据,加载的数据和我们原始数据内容一样,当然如果是订单明细数据,只需要进行一下按日期Group by就行了。
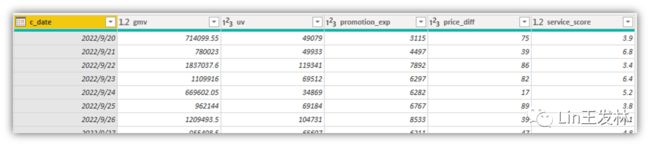
这就是我们需要处理的数据样式,就是表格,在R语言里面叫做数据框,然后我们需要在PowerQuery里面调用R语言脚本,在Transform菜单下面最后一列↓
点击后就会出现R语言脚本的编辑器,这里就不介绍R语言如何实现多元线性回归模型的了,我记得之前R语言的集合里面有详细介绍《R语言_018回归》,有兴趣的可以翻去看看。主要就是使用lm拟合多个参数,然后我们这里再把拟合的结果求出来就行了,代码也很简单,如下↓
fit <- lm(gmv ~ uv + promotion_exp + price_diff + service_score,
data=dataset)
df<- data.frame(coef(fit))
names(df)[names(df)=="coef.fit."] <- "coefficients"
df['variables'] <- row.names(df)再多说一句,不管是调用R语言还是Python,不管PowerQuery里面当前的流程是怎么命名的,在脚本编辑器里面的数据集都是用dataset命名的。最后运行结果如下↓
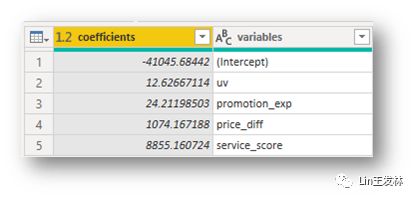
于是我们已经得到了我们最需要的几个参数,根据我们的历史数据,得出来的截距是-41045,uv的影响是12.62(每新增100个用户就会带来1262的GMV),费用投入影响是24.21(每投入100元带来2421的GMV),降价影响1074(每降价1元带来1074GMV),服务评分影响是8855(评分每增加0.1分GMV增加885)。总体看来各项因素对GMV都有一定的影响,在此基础上,我们如果想要达到目标的GMV,就可以从这几方面入手了。
然后回到PowerBI,我们把这几个参数用度量值写下来,再把公式写出来,DAX语句和结果如下↓
Intercept = CALCULATE(SUM('回归系数'[coefficients]),'回归系数'[variables]="(Intercept)")
UV = CALCULATE(SUM('回归系数'[coefficients]),'回归系数'[variables]="uv")
promotion_exp = CALCULATE(SUM('回归系数'[coefficients]),'回归系数'[variables]="promotion_exp")
price_diff = CALCULATE(SUM('回归系数'[coefficients]),'回归系数'[variables]="price_diff")
service_score = CALCULATE(SUM('回归系数'[coefficients]),'回归系数'[variables]="service_score")
预测公式 =
"预计GMV公式 = " & UNICHAR(10) &
FORMAT([Intercept],"#0") &
" + UV*" & FORMAT([UV],"#0.00") &
" + 费用*" & FORMAT([promotion_exp],"#0.00") &
" + 降价*" & FORMAT([price_diff],"#0") &
" + 服务分*" & FORMAT([service_score],"#0")
预计GMV = [Intercept] + [UV]*[UV Value] + [promotion_exp]*[推广费用 Value] + [price_diff]*[价格降低 Value] + [service_score]*[服务评分 Value]


关键值和预测GMV的公式我们都有了,我们就可以带入相关值进行预测了,只需要新建四个参数就行了,然后新建一个预测的度量值就行了,度量值和结果如下↓
预计GMV = [Intercept] + [UV]*[UV Value] + [promotion_exp]*[推广费用 Value] + [price_diff]*[价格降低 Value] + [service_score]*[服务评分 Value]
当然我们还没有结束,前面说过我们我们还可以加入很多值来判断这个模型的好坏,其中一个很重要的指标就是R2和调整的R2,当然我们还可以检验线性关系、共线性等问题。这里我们以R2举例,还是在PowerQuery里面来实现,只需要把R语言代码改一下就行了,代码和结果如下↓
fit <- lm(gmv ~ uv + promotion_exp + price_diff + service_score,
data=dataset)
s1 <- summary(fit)
df <- data.frame(name = c("R2","R2ajd"),
values = c(s1$r.squared,s1$adj.r.squared))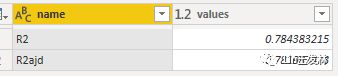
得到了R2和调整的R2,0.78,说明这个多元线性回归模型还是相当的不错,如果在真实场景中有这么高的R2,就烧高香把。简单说明前面的4个因素就已经能够解释78%的结果了,价值非常高,再去找找其他因素整个模型就越来越完美了,然后我们照例把度量值建立起来,等一下放在图里面,DAX语句如下↓
R2 = CALCULATE(SUM([values]),'R2'[name]="R2")
R2ajd = CALCULATE(SUM([values]),'R2'[name]="R2ajd")
上面我们是进行点预测的,就是影响参数值固定的,变量后预测的结果是一个固定的值,有时候我们还想看看预测的区间,看看整个区间我们能不能够接受,这里我们就可以调用R语言里面回归拟合结果的置信区间范围值了,默认是95%的置信区间,我们就选用默认值,然后会求出区间两界限的参数值,R语言代码和结果如下↓
fit <- lm(gmv ~ uv + promotion_exp + price_diff + service_score,
data=dataset)
dfc <- confint(fit)#提供模型参数的置信区间(默认95%)
dfcd <- data.frame(name = c("Intercept","uv","promotion_exp","price_diff","service_score"),
pct2.5 = dfc[,1],
pct97.5 = dfc[,2])
从结果我们就可以很清晰的看到上界和下界参数值了,然后我们再在PowerBI里面把各参数的度量值写出来,DAX语句如下↓
p25 Intercept = CALCULATE(SUM([pct2.5]),'置信区间'[name]="Intercept")
p25 price_diff = CALCULATE(SUM([pct2.5]),'置信区间'[name]="price_diff")
p25 promotion_exp = CALCULATE(SUM([pct2.5]),'置信区间'[name]="promotion_exp")
p25 service_score = CALCULATE(SUM([pct2.5]),'置信区间'[name]="service_score")
p25 UV = CALCULATE(SUM([pct2.5]),'置信区间'[name]="uv")
p97 Intercept = CALCULATE(SUM([pct97.5]),'置信区间'[name]="Intercept")
p97 price_diff = CALCULATE(SUM([pct97.5]),'置信区间'[name]="price_diff")
p97 promotion_exp = CALCULATE(SUM([pct97.5]),'置信区间'[name]="promotion_exp")
p97 service_score = CALCULATE(SUM([pct97.5]),'置信区间'[name]="service_score")
p97 UV = CALCULATE(SUM([pct97.5]),'置信区间'[name]="uv")然后根据度量值,把上下界的GMV预测函数写出来,顺便把合并的区间写出来,DAX语句如下↓
预计GMV上线 =
[p97 Intercept] + [p97 UV]*[UV Value] + [p97 promotion_exp]*[推广费用 Value] + [p97 price_diff]*[价格降低 Value] + [p97 service_score]*[服务评分 Value]
预计GMV下线 =
[p25 Intercept] + [p25 UV]*[UV Value] + [p25 promotion_exp]*[推广费用 Value] + [p25 price_diff]*[价格降低 Value] + [p25 service_score]*[服务评分 Value]
预计GMV区间 = "[" & FORMAT([预计GMV下线],"#,##0") & " - " & FORMAT([预计GMV上线],"#,##0") & "]"最后我们把所有度量值,点预测和区间预测结果,R2值放在一起,只需要进行参数调整就可以来进行数据预测了↓
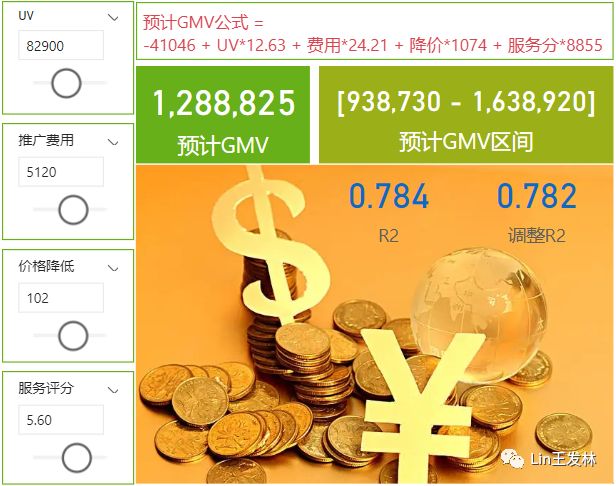
当然这里我们不能够选择历史数据的范围,如果我们需要调整历史数据的范围,我们只能在PowerQuery里面进行调整,或者我们可以写固定的日期值,比如我们可以固定最近90天或者180天的数据,这里每天数据就会自动滚动变化了,用最新的只预测效果应该也会更好,我们这里使用90天的数据来看一下结果↓
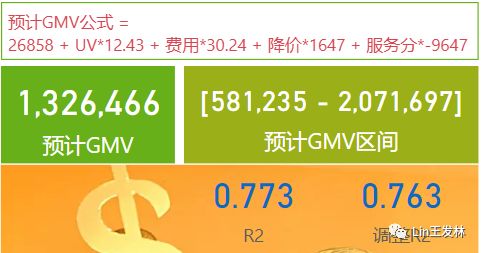
可以看到结果还是有所差异的,不过R2还是很不错,说明这个模型还是不错的,今天写的有点多了,过两天再来用Python实现一下。
End


◆ PowerBI_RFM客户关系模型
◆ PowerBI饼图、圈图、旭日图
◆ Excel时间序列预测函数
◆ Python操作MySQL数据库
◆ Python企业微信机器人