从零开始学习pytorch之计算图与动态图机制
计算图(Computational Graph)
前言
在学习了张量的一系列操作后,我们知道深度学习就是对张量进行计算和操作。随着张量种类和计算的增多,会导致各种各样想不到的问题,比如我们多个操作之间该并行还是顺序执行;如何协同各种底层设备以及如何避免各种冗余的操作等等,这些问题都会影响到我们的运算效率,甚至都会引入到一些不必要的bug,而计算图就是为了解决这一个问题而产生的。
-
计算图是用来描述运算的有向无环图。
-
计算图有两个主要元素:节点(Node)和边(Edge),节点表示数据,如向量、矩阵;张量表示运算,如加减乘除卷积等
-
用计算图表示
y = (x+w)*(w+1)
将上式进行拆分a=x+w; b=w+1; y=a*b


叶子节点
用户创建的节点称为叶子节点,如x和w
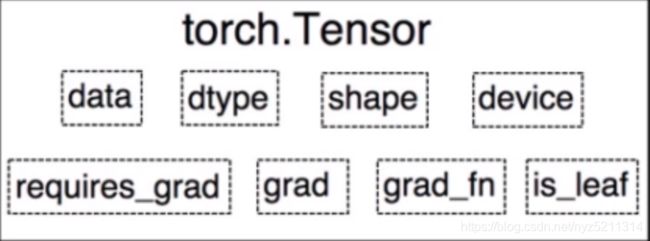
is_leaf:指示张量是否为叶子节点
代码查看叶子节点和梯度
import torch
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
# 查看梯度
print("gradient:\n", w.grad, x.grad, a.grad, b.grad, y.grad)
#查看叶子节点
print("is_leaf:\n", w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf, y.is_leaf)
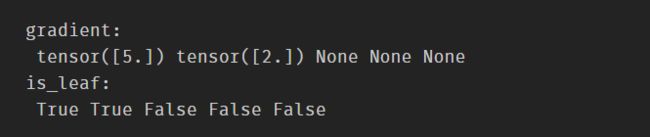
由此可见只有叶子节点才存在梯度,我们没有创建的变量梯度会被释放掉。当然,如果想要获得非叶子节点的梯度也是有办法的,只要在反向传播之前使用retain_grad()的方法即可保存相应张量的梯度。
import torch
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
a.retain_grad()
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
# 查看梯度
print("gradient:\n", w.grad, x.grad, a.grad, b.grad, y.grad)
#查看叶子节点
print("is_leaf:\n", w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf, y.is_leaf)

grad_fn:记录创建该张量时所用的方法(函数)
如上面我们所举栗子用到的函数:
y.grad_fn = < MulBackward0 >
a.grad_fn = < AddBackward0 >
b.grad_fn = < AddBackward0 >
print("grad_fn:\n",w.grad_fn, x.grad_fn, a.grad_fn, b.grad_fn, y.grad_fn)
![]()
Pytorch中动态图机制(Dynamic Graph)
前言
神经网络根据计算图的搭建方式,可将计算图分为动态图和静态图。
- 动态图
运算与搭建同时进行,动态图好比我们出去旅行是自由行,灵活性强,可以随时改变计划,所以易调节。 - 静态图
先搭建图,后运算,静态图就相当于我们跟团旅行,效率高,不需要自己操心,但是有不灵活的缺点。
而我们的pytorch是使用动态图搭建的,与tensorflow相比方便调试,是科研的不二之选。