《PyTorch深度学习实践》 第 12 讲
第11讲 卷积神经网络(基础篇)
B站 刘二大人 ,传送门——Pytorch深度学习实践 循环神经网络(基础篇)
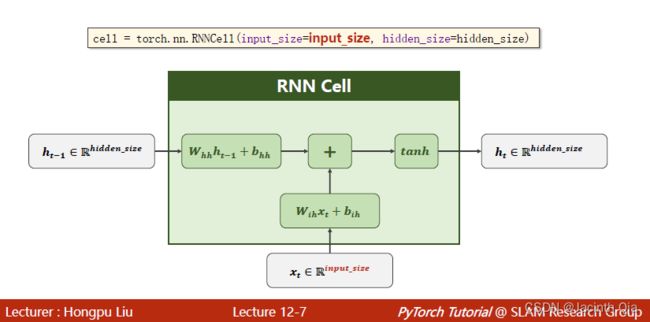
一. How to use RNNCell
说明:
1. RNNCell需要手动循环,循环seq_len次
2. 模型定义时的两个主要参数:input_size 和 hidden_size
3. 输入输出的shape:
.ℎ=(ℎ,)
.ℎ=(ℎ,ℎ)

代码演示(也可参照Pytorch官网,传送门:RNNCell )
# 1. 利用RNNCell,需要手动循环
import torch
seq_len = 3
batch = 2
input_size = 4
hidden_size = 2
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
dataset = torch.randn(seq_len, batch, input_size)
hidden = torch.zeros(batch, hidden_size)
for idx, inputs in enumerate(dataset): # idx==seq_len
print('='*10,idx,'='*10)
hidden = cell(inputs, hidden)
print(inputs)
print(inputs.shape)
print(hidden.shape)二. How to use RNN
说明:
1. RNN自动循环
2. 模型定义时的三个主要参数:input_size 、 hidden_size、num_layers
3. 输入输出的shape:
cell = torch.nn.RNN(input_size,hidden_size,num_layers)
output , hidden = cell (input , hidden)
输入:input (seq_len, batch_size, input_size) ; hidden(num_layers, batch_size, hidden_size)
输出:output (seq_len, batch_size, ihidden_size);hidden(num_layers, batch_size, hidden_size)

代码演示(也可参照Pytorch官网,传送门: RNN)
# 2. 使用RNN,自动循环
import torch
batch_size=2
seq_len=3
input_size=4
hidden_size=2
num_layers=1
cell = torch.nn.RNN(input_size=input_size,hidden_size=hidden_size,num_layers=num_layers)
inputs = torch.randn(seq_len,batch_size,input_size)
hidden = torch.randn(num_layers,batch_size,hidden_size)
outputs,hidden = cell(inputs,hidden)
print(outputs)
print(outputs.shape) # 3,2,2
print(hidden)
print(hidden.shape) # 1,2,2
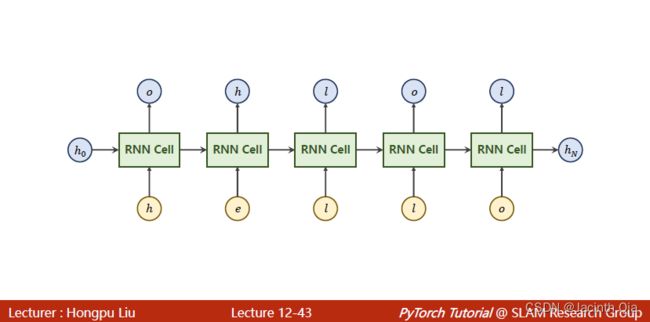
三. Using RNNCell Examples(hello-->ohlol)
说明:
1. RNNCell 输入要求是数字元素的向量,通过创建字母字典以及one-hot编码形式,将输入string(hello)转为数字向量。
2. hello :seq_len(序列长度)为字母的总数5,input_size为不重复的字母个数4,batch_size为1(个人理解为输入字符串/词的个数)
3. ohlol:output_size为不重复的字母个数4
4. 采用的损失函数模型为交叉熵损失


代码演示:
# 3. hello-->ohloh RNNCell
import torch
input_size = 4
batch_size = 1
hidden_size = 4
idx2char = ['e', 'h', 'l', 'o'] # 设置一个字典
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size) # -1代表seq_len,为5
labels = torch.LongTensor(y_data).view(-1, 1) # LongTensor是Tensor的int64类型 seq_len*1
class Model(torch.nn.Module):
def __init__(self, batch_size, input_size, hidden_size):
super(Model, self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size=self.input_size, hidden_size=self.hidden_size)
def forward(self, input, hidden):
hidden = self.rnncell(input, hidden) # 输出与隐层命明一致:输出是hidden,隐层也是hidden
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size, self.hidden_size)
net = Model(batch_size, input_size, hidden_size)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.1)
for epoch in range(15):
loss = 0
optimizer.zero_grad()
hidden = net.init_hidden()
print('Predicted string:', end='')
for input, label in zip(inputs, labels): # inputs:seq_len*batch_size*input_size-->input:batch_size*input_size; labels:seq_len*1-->label:1
hidden = net(input, hidden) # 输出和隐层命明必须一致
loss += criterion(hidden, label) # hidden:batch_size*hidden_size,即hidden_size;label:1 构建计算图,loss.item()-->loss
_, idx = hidden.max(dim=1)
print(idx2char[idx.item()], end='')
loss.backward() # loss.backward()要放for input,……层外面-->否则报错:计算图已被释放。因为loss+=,需要将五个序列的loss相加才是整个的loss,之后再进行后向传播backward
optimizer.step()
print(',Epoch [%d/15] loss =%.4f' % (epoch, loss.item()))
四. Using RNN Examples(hello-->ohlol)
说明:
1. RNN 与RNNCell区别在于:
1)RNN可以自循环,而RNNCell不能;
2)模型主要参数:RNN比RNNCell 多了 num_layers,并且size也不同
3)输入size和输出个数不同
代码演示:
# 4. hello-->ohlol RNNCell
import torch
input_size = 4
hidden_size = 4
batch_size = 1
num_layers = 1
seq_len = 5
idx_char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
one_hot_char = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
inputs = [one_hot_char[x] for x in x_data]
inputs = torch.Tensor(inputs).view(seq_len, batch_size, input_size)
labels = torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__() # 未知数在命明函数(net = Model())处赋值
self.rnn = torch.nn.RNN(input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers)
def forward(self, input): # input未知数在调用net是赋值,net(……)
hidden = torch.zeros(num_layers, batch_size, hidden_size)
out, _ = self.rnn(input,
hidden) # 输出为两个,out:seq_len*batch_size*input_size; hidden:num_layers*batch_size*hidden_size
return out.view(-1, hidden_size) # (seq_len*batch_size,hidden_size)
net = Model()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
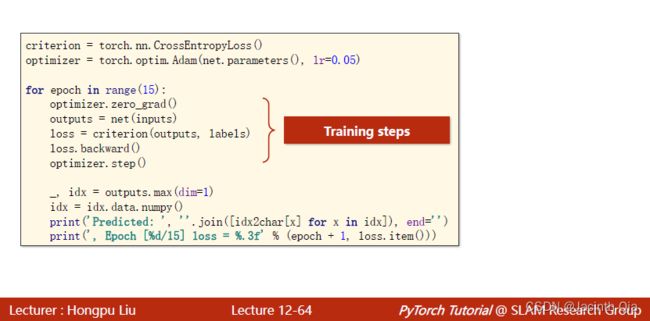
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
# print(outputs)
# print(labels)
loss.backward()
optimizer.step() # loss.backward()和optimizer.step()要放在输出内容的前面,循环更新之后输出
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted: ', ''.join([idx_char[x] for x in idx]), end='')
print(',''Epoch [%d/14] loss=%.4f' % (epoch, loss.item()))五. Embedding编码
说明:
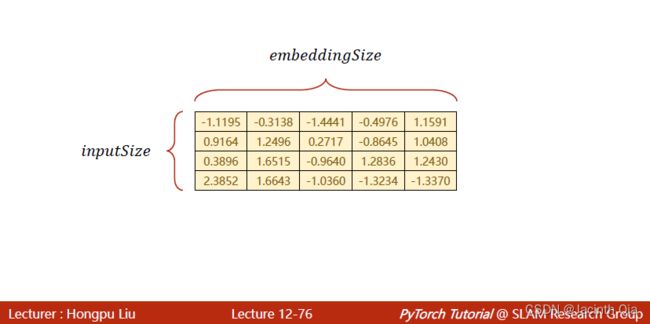
1. One-hot vs Embedding

2. embedding 编码 将input_size转换为embedding size ,之后输入到RNN网络
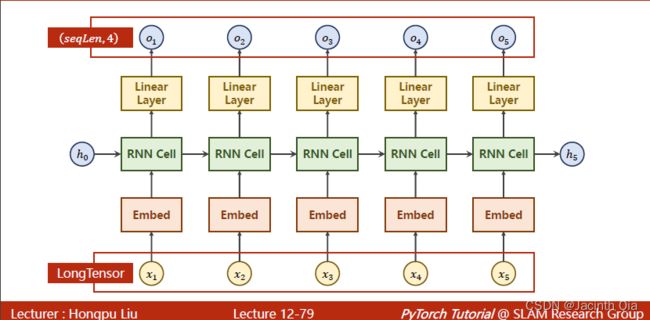
代码实现:
1.错误:. 刘老师课件上代码有一处错误:
在准备输入数据,inputs = torch.Tensor(x_data).view(1,5)
因为x_data是一个列表,而非向量,需要通过view进行转换
2. 注意:输入先经过Embedding,其输出输入到RNN网络,所以RNN中input_size=embedding_size 而非程序最开始定义的 input_size (不要问我是怎么注意到这个问题的,问就是被虐过)
# 5. Using embedding(not one-hot) and linear layer
import torch
num_class = 4 # 最后经过线性层输出的类别数
input_size = 4
hidden_size = 8 # 经过RNN层输出的类别数,但不是最后的类别数
embedding_size = 10
batch_size = 1
num_layers = 2
seq_len = 5
idx_char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3] # x在此处是一个列表,而非一个向量
y_data = [3, 1, 2, 3, 2]
inputs = torch.LongTensor(x_data).view(1, 5) # Embedding函数的Input:LongTensor类型 inputs:(batch_size,seq_len)
labels = torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.emb = torch.nn.Embedding(input_size, embedding_size) # input:(*) ,output:(*,embedding_size)
self.rnn = torch.nn.RNN(input_size=embedding_size, # 此处的输入size是经过embedding之后的embedding_size
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True) # If True, then the input and output tensors are provided as (batch, seq, feature) instead of (seq, batch, feature).
self.fc = torch.nn.Linear(hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(num_layers, batch_size, hidden_size)
x = self.emb(x) # Input(x):(batch_size,seq_len) Output(x):(batch_size,seq_len,embedding_size)
out, _ = self.rnn(x, hidden) # out:(batch_size,seq_len,hidden_size)
out = self.fc(out) # Output(out):(batch_size,seq_len,num_class)
return out.view(-1, num_class) # return:(batch_size*seq_len,num_class)
net = Model()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs) # return:(batch_size*seq_len,num_class)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted:', ''.join(idx_char[x] for x in idx), end='')
print(',Epoch [%d/14] loss=%.3f' % (epoch, loss.item()))