峰会回顾 | 基于StarRocks,百草味如何通过数据赋能快消品行业
作者:朱齐天,百草味数据部负责人(本文为作者在 StarRocks Summit Asia 2022 上的分享,分享主题是“如何用数据赋能快消品行业提升业务能力”)
快消品的行业特点是“快”,其受众为年轻人,具有高频次、受众广、低客单的特点。百草味作为一家休闲食品品牌运营企业,具备全渠道运营能力(给用户多渠道的选择,包括线上平台和线下商超)。
2020年加入百事后,作为百事的子公司,随着业务快速与集团接轨,百草味越来越多的业务需要通过数据来驱动,变得更加合理化、规范化以及高效化。
朱齐天老师主导百草味全渠道从 0 到 1 的数据平台建设、指标体系梳理、数仓模型设计及优化工作。本文主要介绍以下四个部分:
-
数据平台演进心得
-
技术成长源于业务变更
-
概念先行 OR 问题驱动
-
数据架构未来构想
#01
数据平台演进心得
—
首先和大家分享下百草味数据平台演进的情况:
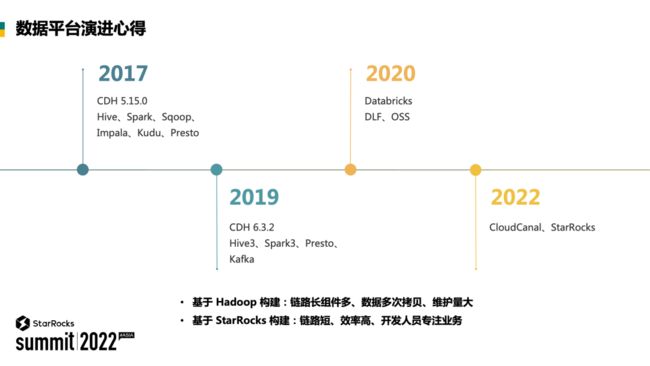
-
2017 年:为了快速产出,基于 CDH 5.15.0 搭建了一套大数据平台,开发了一些基础功能和几百张报表,实时的报表直接使用了 Stream Computer 和 Quick BI,离线报表以 Apache Hive 为主。
-
2019 年:仍然以 CDH 为主,中间经过两次版本迭代,升级为 6.3.2. 实时数据换成了 Apache Spark 和 Apache Kafka,中间封装了一些工具供团队开发。
-
2020 年:被百事收购以后,线下机房由于不符合合规要求,于是选择上云。考虑维护成本,选择了 Databricks,采用 Data Lake Formation(DLF)和对象存储 OSS 的存储架构。
-
2022 年:由于业务对算力的要求,选择了 StarRocks 和 CloudCanal。
根据上面的探索总结出两种大数据开发平台的优劣:
-
基于 Hadoop 构建:链路长,组件多,数据多次拷贝,维护量大
-
基于 StarRocks 构建:链路短,效率高,开发人员专注业务
1、数字化流程
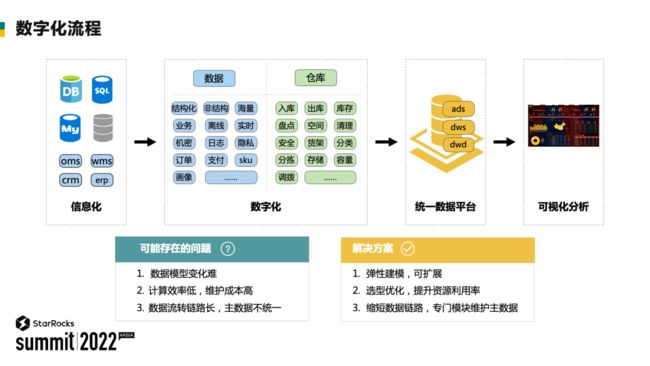
数字化流程大致的进程为信息化,数字化,再延伸到统一数据平台,可视化分析。
数字化何以在企业中广泛引用,离不开前期企业造词造势造概念和政策的支持与约束。40 年前便有数据仓库的概念,慢慢延伸到数据湖和数据中台。目前企业中的实践,一般以数据仓库为底座,再向上层应用延展。流程需要先有信息化的建设,才有数字化的沉淀,然后进行数字化的赋能。
2、早期数据架构
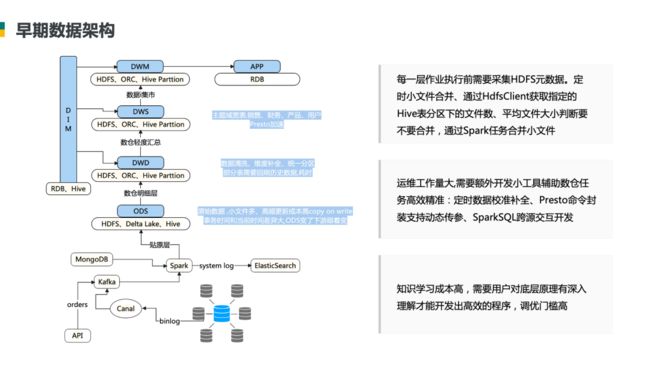
在数仓构建的过程中会遇到各种问题,例如业务侧发生表结构变更,在 ODS 层也需要变更,在 DWD 和 DWS 层只需要做逻辑层变更,做相对弹性的变更,不需要更新物理数据。
这是我们早期的数据架构情况,这是一套比较通用的模型,其优缺点分别为:
-
优点:开源组件比较灵活。
-
缺点:框架比较笨重,运维成本比较高。因为 Apache Hive 没有索引、缓存、组件等功能,业务侧如果发生表结构更新,比较难以操作。
例如,在 ODS 层,新更新的数据有可能是几个月之前的订单,比如订单的状态发生了变更,早期的架构是需要记录更新数据的对应日期,并将对应日期的数据更新一遍,那么 DWS 和 DWD 也要跟着进行变更,这样会带来很大性能问题。
为了应对业务侧的频繁变更问题,使用 Delta Lake,解决了频繁变更和小文件合并问题,但是也会引起 ODS 层的存储过大,需要不断扩展磁盘的问题。
3、新数据架构

传统 Hadoop 体系组件存在以下问题:
-
过于冗余,强耦合
-
数据湖的概念至今没有成熟的产品
-
维护量大,成本高,计算效率低下
基于早期的数据架构,通过简化架构,缩短数据链路,采用 StarRocks 搭建了新的架构。实现三两个组件完成采集、存储计算和可视化。
在数据采集模块,为了保证数据搬运的准确和高效,选择采用 CloudCanal,利用可视化的配置,将 Apache Kafka,MongoDB,Redis 的数据同步到 StarRocks。
CloudCanal+StarRocks 结合使用,带来了很多好处:
-
数据采集方面带来便利
-
使开发人员专注于业务本身,无需关心底层的实现
-
降低了存储成本,因为 DWD 和 DWS 将近一半的表是直接用视图做的,很大程度上减少了数据的拷贝带来的存储压力
4、大数据常用组件
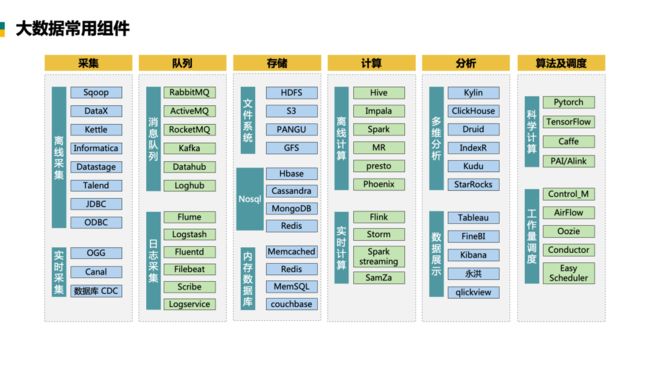
数字化进程中,在初始阶段,没有太多业务流需接入,当各种业务繁杂,需要多种组件参与,涉及到以上多种大数据常用组件。
#02
技术成长源于业务变更
—
1、不断变化的业务需求

以上是快消品行业按照不同场景划分的各种指标。随着业务的庞杂,指标的计算会变得复杂,需要将数据的并入和计算做得高效,才能应对不断变更的业务需求。面对庞大的业务体系,建立数据指标模型时主要有以下问题:
-
数据模型也要快速变化一应对繁杂多变的指标,贴合业务
-
需求在增加,大数据组件也在增加实效性增强,硬件成本高
-
引入新的业务系统满足新的场景对应的数据源也在不断增加
2、业务建模

为实现数据和指标之间的串联,打破部门墙,增强部门之间的协作,启动全链路数字化项目,打造百草味业务全景图。主要流程为:
从全公司部门业务需求的收集,指标文档的整理,确定计算口径和可视化的样式,到数据的采集和模型的搭建,ETL 的计算,报表的呈现,给业务数据赋能。
借助 StarRocks 搭建业务全景图,极大地减少了时间成本,数据采集速率也提高了,效率相比传统方案有 10-100 倍性能提升,真正意义上实现用户只关注业务。
其中由于财务中心的指标有一套固定的计算准则,因此可以较固定的进行指标构建,而相对灵活的变更需求比较大的业务流程和运营中心,则提供比较好用和合理的模型即可。
3、例子:场景→模型→指标

对于快消行业来说,“进销存”三个环节非常重要。数据打通可以很好地解决控价和库存问题。进销存模型以商品流转的链路为主线,记录 SKU 的流转信息。
StarRocks 对企业数字化的赋能,主要针对两大块业务:前端控好价格,后端管好库存。实现了以下优势:
-
一半物理表一半逻辑视图,减少了一半的调度
-
降低了招聘要求和员工交接的技术成本
-
在数字化进程中,打破了概念先行,真正做到了问题驱动
#03
概念先行 OR 问题驱动
—
1、概念→产品→解决问题

概念推动产品落地,产品解决业务问题。随着这种开发逻辑的盛行,慢慢意识到开源与商业之间的问题和差距。因此慢慢地淡化一些概念,聚焦于问题本身,降低试错成本。为了解决问题而产生的问题:
-
一堆概念衍生一堆产品去解决一堆问题
-
产品间兼容性问题,高度耦合,到处拷贝
-
一个概念几年没成熟产品,换个新概念集众多产品优势于一身诞生新产品
我们应该多花时间在问题本身上,加速财务自动对账的效率,探索提效降本的可落地方案,完善会员营销的闭环流程,加速商品流转各种场景的数字化模型建设将是我们未来的研究课题。
优化三部曲:
-
改个 SQL,设置个 Session 参数,提高了一个作业的执行效率
-
改进全局参数,升级到更高的版本,加组件,加机器,提高了部分作业的执行效率
-
换一套产品,提高了整体的作业执行效率
#04
数据架构未来构想
—

StarRocks 可以从以下五个点进行改善和提升,会更有竞争力。
-
统一管理界面:多源增量采集,数据(指标)治理,程序开发调度,运维监控
-
灵活稳定的多表物化视图
-
数据模型可逻辑统一可物理统一,降低数仓模型的深度
-
主键模型(Primary Key Model)持久化索引,完善关系型数据库的 Catalog
-
更好的支持高频写入,加 Buffer 缓冲层,提高采集,计算和极速分析能力
关于 StarRocks
面世两年多来,StarRocks 一直专注打造世界顶级的新一代极速全场景 MPP 数据库,帮助企业建立“极速统一”的数据分析新范式,助力企业全面数字化经营。
当前已经帮助腾讯、携程、顺丰、Airbnb 、滴滴、京东、众安保险等超过 170 家大型用户构建了全新的数据分析能力,生产环境中稳定运行的 StarRocks 服务器数目达数千台。
2021 年 9 月,StarRocks 源代码开放,在 GitHub 上的星数已超过 3400 个。StarRocks 的全球社区飞速成长,至今已有超百位贡献者,社群用户突破 7000 人,吸引几十家国内外行业头部企业参与共建。