峰会回顾 | 阿里云与StarRocks合作、开放、共赢
作者:阿里云计算平台事业部产品解决方案总经理 陈立(本文为作者在 StarRocks Summit Asia 2022 上的分享)
天下武功唯快不破。互联网公共云、金融和企业的各类型客户目前在风控、营销、推荐等行业对于数据分析的时效性提出了更多的要求。实现高时效数据查询分析对技术的管理运维成本,尤其给开发团队的技能提出了更高的挑战。
在数字经济时代,客户的业务发展也更依赖于数据分析和数据决策。高度的数据决策提升业务正向增长的概率是普遍的客户诉求。从战略蓝图规划,到月度/季度的管理决策,再到实时根据业务的进展和阶段性结果做出快速的反馈和调整,是数字企业重要的标志和价值。
不同类型的客户有他们自己的业务优先级和重点,客户正利用数字化转型和 IT 建设将每一个传统的项目以产品化的方式去推动。阿里云的数据湖演进也是基于市场和客户的普遍诉求来一步步进阶的。
#01
阿里云数据湖演进之路
—
2019 年以前,是阿里云数据湖 1.0 时代。
存储上:存算分离,冷热数据分层,以 Apache Hadoop 的生态为主;
管理上:无官方管理服务,需要用户自行处理扩缩容和磁盘运维等管理工作;
计算上:初步实现计算云原生化,缺乏计算弹性及多样性。
2019 年到 2021 年,是阿里云数据湖 2.0 时代。
存储上:以对象存储为中心,统一存储承载生产业务,大规模、高性能;
管理上:提供面向 OSS/EMR 等垂直湖管理系统,缺乏产品之间的联动;
计算上:计算弹性化,根据客户的业务负载进行计算的快速伸缩。
2021 年开始,已经到了阿里云数据湖的 3.0 时代。
存储上:以对象存储为中心,构建企业级数据、全兼容、多协议统一元数据管理;
管理上:面向湖存储+计算的一站式湖构建和管理,做到智能“建湖”和“治湖”;
计算上:实现云原生、弹性化,同时实现实时化、AI 化和生态化。StarRocks 是阿里云在数据湖 3.0 云原生化、弹性化、实时化的重要产品之一。
#02
阿里云&StarRocks:共建数据湖 3.0
—
2021 年 9 月,阿里云EMR 和 StarRocks 开始正式合作。2022 年 3 月,阿里云EMR StarRocks 正式发布。2022 年 5 月,伴随着 StarRocks 2.2.0 版本的发布,阿里云EMR StarRocks 2.2.0 也同步发布,支持数据湖分析功能。在 2022 年 7 月,阿里云EMR StarRocks 2.3.0 和 StarRocks 2.3.0 同时发布,支持实时计算入湖的能力。2022 年 8 月,阿里云北京数据湖 Workshop 和 StarRocks 进行了联合分享。
阿里云作为中国第一家云托管 StarRocks 的服务厂商,拥有国内当前最成熟的云上 StarRocks 解决方案,已为数以百计的阿里云用户提供了服务。从技术合作共建的角度来看,阿里云深度参与了 StarRocks 社区共建,从 Committer 到 Champion 到 Contributor,已贡献代码数万行。
同时阿里云开源大数据团队深度参与社区共建的产出有以下几个:第一个是降低了客户使用门槛,提升了产品易用性及产品体验感觉,第二个是实现了集群的高效管理。在开放的 Lakehouse 和湖仓一体上,我们也以技术合作的方式贡献了自己的能力,与 StarRocks 一起去完善了部分功能。我们在实时数据导入及分析、多表物化视图、ETL Load 和 Transformation 等方面都做了相关技术工作。
#03
阿里云EMR StarRocks:多场景的高效数据分析
—
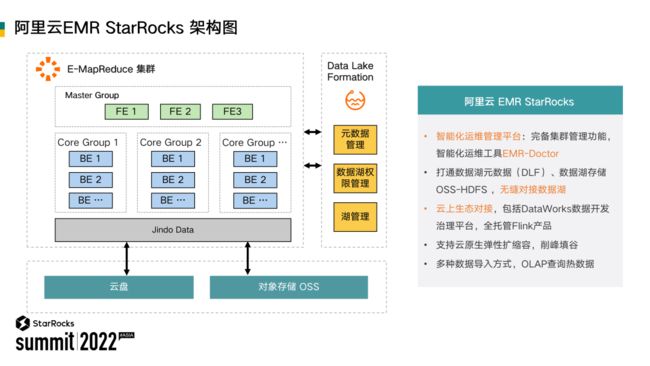
阿里云EMR StarRocks 有以下几个特点:
1. 与阿里已有的存算分离产品进行了高度的技术融合,例如数据湖构建 DLF、Jindo FS、Jindo Data 和 OSS 等。实现智能化的运维管理平台,完备集群管理功能,利用智能化的运维工具及时诊断数据湖和 StarRocks 的一些运维和使用问题。
2. 实现云上生态对接,包括 DataWorks 数据治理平台,全托管 Flink 实时计算做到了无缝集成。
3. 支持云原生弹性扩缩容,削峰填谷,帮助客户更好的节约计算成本。
4. 支持多种数据的导入方式,支持 OLAP 查询热数据等场景。
阿里云的云原生数据湖整体架构今年主要有“四个一体化”:大数据和 AI 一体化、湖仓一体化、实时离线一体化和流批一体化。“四个一体化”的引擎之上,是大数据开发建模治理平台 DataWorks。在 4+1 的产品形态之下,我们与 StarRocks 在统一的存储与服务、高效的存算分离数据分析能力和多种多样的数据格式等三个方面进行了深度的融合与合作。
1、高效的数据分析能力
在高效的数据分析能力层面,我们在 Lakehouse 分析场景下,通过 StarRocks 全面的向量化执行引擎优势,更智能的优化器来显著提升 TPC-H 100G 的性能。和业界开源的 Trino 相比,StarRocks 2.1 的 Hive external 查询速度都有 1.7-2.2 倍的提升。

在 SSB 的性能测试方面,我们也构建了三个阿里云EMR 集群来做性能对比,测试结果如下:
1. 在标准测试数据集查询上,ClickHouse 的整体查询时间是 StarRocks 的 1.7 倍,Apache Druid 的整体查询时间是 StarRocks 的 2.2 倍;
2. 在 StarRocks 启用 bitmap index 和 cache 的情况下,性能更胜一筹,尤其在 Q2.2、Q2.3 和 Q3.3 上有显著提升,整体性能是 ClickHouse 的 2.2 倍、Apache Druid 的 2.9 倍。
2、重点客户实践案例
针对在线教育客户,每天可能存在几十亿条数据量,涉及订单变更、特征人权筛选和机器学习训练等各个方面的业务需求。实时数据湖架构做到了以下功能:
1. 支持 Upsert 场景;
2. 热数据导入 StarRocks,订单实时分析,实时大屏;
3. StarRocks 物化视图提供 BI 系统实时查询能力;
4. StarRocks 直接查询外表湖数据,保持技术栈统一的同时提升了效率。
针对社交领域的客户,其每天可能存在 5TB 的数据规模,还有数据画像大宽表、业务系统点查、业务人员随机查询等需求。我们的实时数据分析方案通过 StarRocks 做到了统一架构,方便运维,自动平衡数据。在用户画像场景,大宽表可以局部更新,避免多流 Join,提高效率和性能。
针对电商领域的客户,我们利用 StarRocks 统一 OLAP 引擎,满足其 GMV 订单、物流、客户分析、推荐系统、用户画像等各个业务场景需求。我们支持数据离线导入,实时导入。同时运维简单,MySQL 协议对接各类 BI 工具,实现了技术上的进一步创新和业务洞察。
阿里云今年主要是 Back to Basic,做好基础技术工作,提升客户体验感。对于阿里云和 StarRocks 在大数据领域的合作,我们希望做到 High scale-Low touch,主要有以下几个方面:第一个是云原生存算分离,增强云原生集成能力;第二个是增量物化视图,增强湖仓分析实时性;第三个是通过 Serverless 实现更轻量级的云原生方案。
#04
总结与展望
—
阿里云是云计算的基础设施。我们的大数据和人工智能团队、计算平台事业部,作为在大数据和人工智能领域的产品承载方,希望和更多的开源社区一起吸引更多的用户,同时希望能够与更高性能、更高弹性和更低运维投入的客户一起实现合作共赢,从而为行业和企业客户提供更好的支持。
关于 StarRocks
面世两年多来,StarRocks 一直专注打造世界顶级的新一代极速全场景 MPP 数据库,帮助企业建立“极速统一”的数据分析新范式,助力企业全面数字化经营。
当前已经帮助腾讯、携程、顺丰、Airbnb 、滴滴、京东、众安保险等超过 170 家大型用户构建了全新的数据分析能力,生产环境中稳定运行的 StarRocks 服务器数目达数千台。
2021 年 9 月,StarRocks 源代码开放,在 GitHub 上的星数已超过 3400 个。StarRocks 的全球社区飞速成长,至今已有超百位贡献者,社群用户突破 7000 人,吸引几十家国内外行业头部企业参与共建。