NLP模型(三)——FastText介绍
文章目录
- 1. FastText 概述
- 2. FastText 分类模型
-
- 2.1 结构
- 2.2 n-gram
- 3. FastText 词嵌入模型
1. FastText 概述
首先,我们得搞清楚,FastText 是什么?有的地方说是分类模型,有的地方又将其用于词向量,那么,FastText究竟指的是什么?我搜集资料时发现很多视频的up主都没弄清楚,其实,FastText 的指向有两个模型,一个就是指向的文本分类模型,首先在论文《Bag of Tricks for Efficient Text Classification》中提出,另一个自然就是词向量模型,首先在文章《Enriching Word Vectors with Subword Information》中提出,接下来我们将会介绍一下两种FastText模型,并将其复现。
2. FastText 分类模型
FastText的分类模型具有速度快、精度高的优点,其分类的准确率甚至不输于大型的深度学习模型,但是由于其模型简单,其训练的速度则要比后者快上好几个数量级。
2.1 结构
FastText在模型结构上采用了 C B O W CBOW CBOW 模型的结构,结构如下:
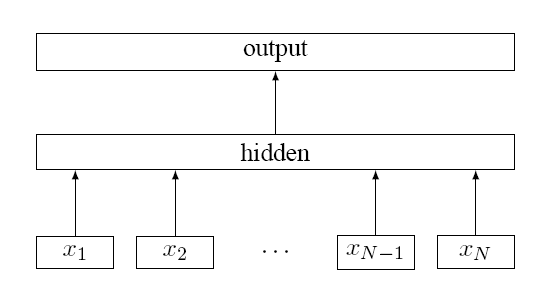
其中这里的 x 1 , x 2 , ⋯ , x N x_1,x_2,\cdots,x_N x1,x2,⋯,xN 是输入的词,整个网络与 C B O W CBOW CBOW 都一样,不同之处主要有以下方面
- C B O W CBOW CBOW 预测的是中心词,FastText最后输出的是各个标签的概率;
- FastText 由于面向的是超多分类以及大量数据的情况,所以FastText 最后的输出采用了层级Softmax,大大优化了模型的运行速度
2.2 n-gram
首先要声明,在原论文中,n-gram并不是FastText必要的步骤,仅仅是一个锦上添花的步骤而已,没有n-gram它还是FastText。
引入n-gram首先是为了解决word2vec中的词序问题,比如两个句子“你礼貌吗”和“礼貌你吗”这两个句子仅仅词序不同,但是意思却天差地别,这种情况word2vec是检测不到词序的不同的,由此提出了n-gram。
注意,词分类模型的n-gram的是word级别的,并不是字符级别的,比如,有如下的句子
I h a v e a n a p p l e I \hspace{0.5em}have\hspace{0.5em} an \hspace{0.5em}apple Ihaveanapple如果n-gram中的 n = 2 n=2 n=2 时,那么输入其中的句子经过n-gram后被分为以下部分 I h a v e , h a v e a n , a n a p p l e I \hspace{0.5em}have,have\hspace{0.5em} an,an \hspace{0.5em}apple Ihave,havean,anapple三个部分,输入也是这三个部分。
尽管如此,还是需要注意一下几个方面:
- 分类模型的n-gram是word级别的,并非字符级别
- n-gram并不是FastText模型中必须的,仅仅是锦上添花
- C B O W CBOW CBOW 和 FastText都是用求和平均值来预测的
- 词向量初始化都是随机的,FastText 并没有在 word2vec 预训练词嵌入的基础上再训练
3. FastText 词嵌入模型
FastText 模型中也引入了n-gram,n-gram的引入其实是为了解决word2vec忽略词型的问题。比如单词 e a t , e a t e n eat,eaten eat,eaten 其实就是一个单词的不同时态,但是,在不同语境下,其词向量可能会相差特别大,而引入n-gram就是为了能够很好的解决词的形态学方面的问题。
例如一个单词 n o r m a l normal normal,如果使用n-gram,当 n = 3 n=3 n=3 时,可以将其分为 n o r , o r m , r m a , m a l nor,orm,rma,mal nor,orm,rma,mal 四个部分,在使用n-gram时一般会用一个尖括号将单词括起来,表示这个单词的开始和结束,如 n o r m a l normal normal 变为 < n o r m a l >
引入了n-gram后,接下来需要做的就是将n-gram后的部分输入模型,这里因为是根据word2vec改进的,所以依旧使用的是 S k i p − g r a m Skip-gram Skip−gram 模型,而这里输入的时候,因为我们有子词以及词,就又会有不同的选择了。
- 词
- 子词
- 词+子词
对于word2vec而言,其训练的有中心词以及周围词矩阵,设 a a a 为中心词矩阵, b b b 为周围词矩阵,那么搭配就有很多种,这里FastText选择的是 a 3 + b 1 a3+b1 a3+b1,即对中心词使用子词+词的输入来预测周围词。
2017 ACL 的 FastText展示提问环节,有人问过为什么不是 a 2 a2 a2,作者的回答是他们试过 a 2 a2 a2,发现效果并不好。
比如一个单词 n o r m a l normal normal,我们将其输入到网络中时,输入的是 < n o , n o r , o r m , r m a , m a l , a l > , n o r m a l
对于未登录词 ( O u t − o f − V o c a b u l a r y ) (Out-of-Vocabulary) (Out−of−Vocabulary),这里采用的方法是将 O O V OOV OOV 词按照n-gram进行拆解,然后将每一部分的词向量进行相加并求平均值,则得到 O O V OOV OOV 词的词向量。
当然,对于进行 n-gram 后没有的部分也是无法进行词向量的计算的,而且,这样做的前提是基于词的拼写、子词在形态学上是有意义的。因此,不同语言,不同效果,作者发现这种方法对阿拉伯语、德语和俄语就比对英语、法语和西班牙语效果好。