港大&NVIDIA提出SegFormer:简单有效Transformer的语义分割新思路
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
编辑:Amusi 源:知乎
https://zhuanlan.zhihu.com/p/379054782
论文: https://arxiv.org/abs/2105.15203
代码会尽快开源,链接:
https://github.com/NVlabs/SegFormer
PS: SegFormer很快也会在mmsegmentation中支持,欢迎各位看官试用~
太长不看
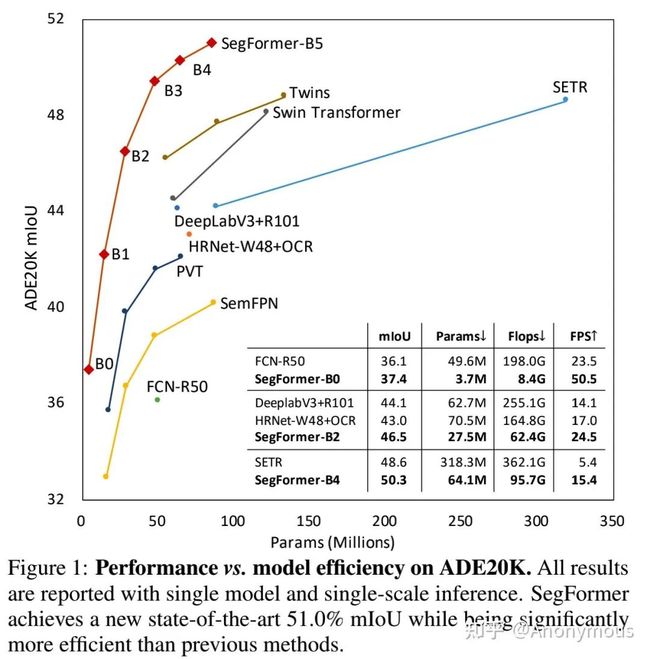
这个工作主要提出了SegFormer, 一种简单、有效且鲁棒性强的语义分割的方法。SegFormer 由两部分组成:(1) 层次化Transformer Encoder (2) 仅由几个FC构成的decoder。SegFormer不仅在经典语义分割数据集(如:ADE20K, Cityscapes, Coco Stuff)上取得了SOTA的精度同时速度也不错(见图1),而且在Cityscapes-C(对测试图像加各种噪声)上大幅度超过之前的方法(如:DeeplabV3+),反映出其良好的鲁棒性。希望这个工作能对语义分割领域有一些启发。
如下是一个video demo,在cityscapes-C上同时跑SegFormer和Deeplabv3+,大家可以对比看下,SegFormer的鲁棒性比DeepLab好很多。
PS:Demo建议点击阅读原文观看
这篇文章主要做了以下几个微小的工作:
1 分析SETR 遗留的问题
众所周知,2020年底,Vision Transformer(ViT) 在图像分类上全面超过CNN, 从此在CV圈掀起Transformer的研究热潮。SETR第一个用Vision Transformer做encoder来尝试做语义分割,并且取得了很好的结果, 具体体现为ADE20K上首次刷到50+ mIoU。这其实迈出了比较重要的一步,说明了Transformer在语义分割上潜力很大,使用Transformer的性能上限可以很高。
另一方面,SETR也存在一些问题需要解决。其中比较主要的问题是SETR采用ViT-large作为encoder, 它有以下几个缺点:
(1) ViT-large 参数和计算量非常大,有300M+参数,这对于移动端模型是无法承受的;
(2) ViT的结构不太适合做语义分割,因为ViT是柱状结构,全程只能输出固定分辨率的feature map, 比如1/16, 这么低的分辨率对于语义分割不太友好,尤其是对轮廓等细节要求比较精细的场景
(3) ViT的柱状结构意味着一旦增大输入图片或者缩小patch大小,计算量都会成平方级提高,对显存的负担非常大,32G的V100也可能hold不住
(4) 位置编码. ViT 用的是固定分辨率的positional embedding, 但是语义分割在测试的时候往往图片的分辨率不是固定的,这时要么对positional embedding做双线性插值,这会损害性能, 要么做固定分辨率的滑动窗口测试,这样效率很低而且很不灵活
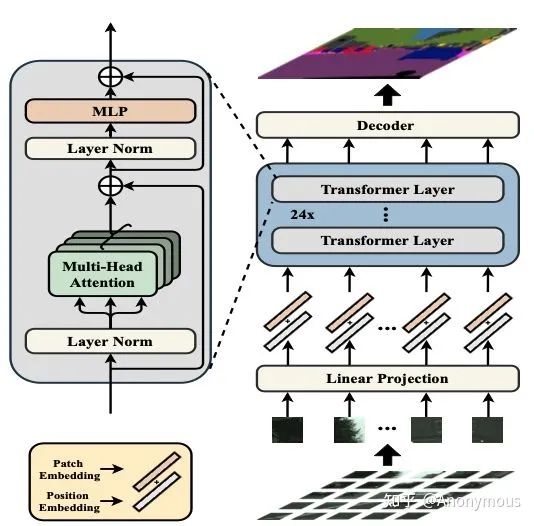 图来自于SETR的论文
图来自于SETR的论文
2 设计更加适合语义分割的Transformer Encoder
首先,回顾经典的语义分割方法, encoder大多会输出*高分辨率的粗粒度特征* 和*低分辨率的细粒度特征*。这样设计的好处在于语义分割可以同时保留这两种特征,从而像素分类更准以及边缘等细节的分割效果更精细。这也是我们期待设计出的Transformer encoder的效果。
首先,最近有一些Transformer encoder可以实现这一目的,比如PVT和Swin Transformer, 这些工作成功的把ViT扩展到分割上,但是他们还有提高空间。比如他们还是采用了Positonal Embedding这一操作,如PVT的Positonal Embedding是和ViT一样固定形状的,如果图片分辨率变了同样需要插值,不够灵活。但是我们发现位置编码实际上在分割中可以完全去掉。
然后,我们重新设计了Transformer encoder, 规避了上述问题,同时也有一些设计受到了之前工作的启发。主要总结为如下几个部分 (1) 之前ViT和PVT做patch embedding时,每个patch是独立的,我们这里对patch设计成有overlap的,这样可以保证局部连续性。(2) 我们彻底去掉了Positional Embedding, 取而代之的是Mix FFN, 即在feed forward network中引入3x3 deepwise conv传递位置信息。
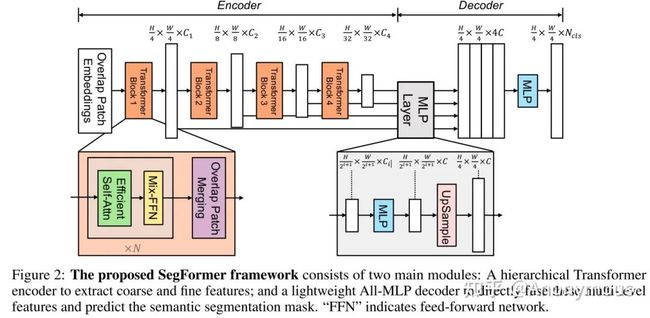 SegFormer的pipeline
SegFormer的pipeline
3 设计简单轻量级的的MLP Decoder
回顾一下过去3年语义分割的文章,不难发现大部分工作其实主要在研究如何设计更好的decoder,比如Deeplab系列, PSPNet, OCNet等工作,但是同时decoder也越来越重,越来越复杂。
不过,在Segformer中, decoder 非常简单,仅有几个MLP 层。首先我们会对不同层的Feature分别过一个linear层确保他们的channel维度一样,其次都上采样到1/4分辨率并concat起来,再用一个linear层融合,最后一个linear层预测结果。整个decoder只有6个linear层,没有引入复杂的操作,比如dilate conv, 甚至也没有3x3 conv. 这样的好处是decoder的计算量和参数量可以非常非常小,从而使得整个方法运行的非常高效。
3.1 讨论
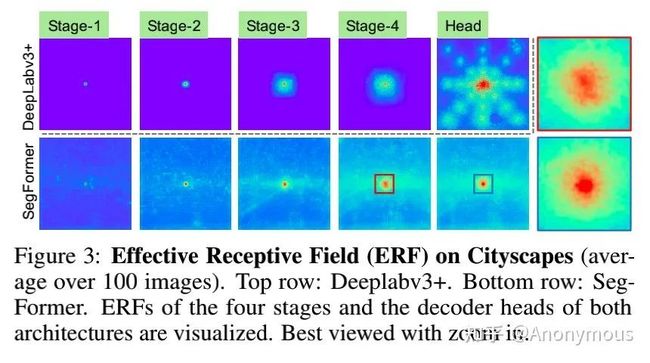
我们分析了一下,之前工作的相对复杂的decoder在CNN encoder上很重要且很有意义,但是在Segformer里,简单的MLP decoder也能work的很好,这是为什么呢?这里需要引出一个概念: 有效感受野(Effective Receptive Field)。关于有效感受野可以看这篇17年的论文:
对于语义分割来说最重要的问题就是如何增大感受野,之前无数的工作也都是在研究这方面。首先对于CNN encoder来说,有效感受野是比较小且局部的,所以需要一些decoder 的设计来增大有效感受野,比如ASPP里利用了不同大小的空洞卷积来实现这一目的。
但是对于Transformer encoder来说,由于 self-attention这一牛逼的操作,有效感受野变得非常大,因此decoder 不需要更多操作来提高感受野(self-attention 永远滴神!)。我们也设计了ablation study具体见论文的Table 1d.
我们可视化了DeepLabv3+和Segformer的有效感受野,如图:
4 实验结果
下表是在ADE20K和cityscapes上的性能,速度,参数以及计算量等指标。可以看到我们的方法随着encoder的增长,性能也在逐步提高。首先我们的最小的模型,SegFormer-B0的参数仅有3.7M 但是效果已经很好了超过很多大模型的方法。其次,我们最大的模型SegFormer-B5在87M参数的情况下取得了最好的结果,相比之下,SETR的参数有318M。同时,从速度层面看,SegFormer相比别的方法优势也比较大。
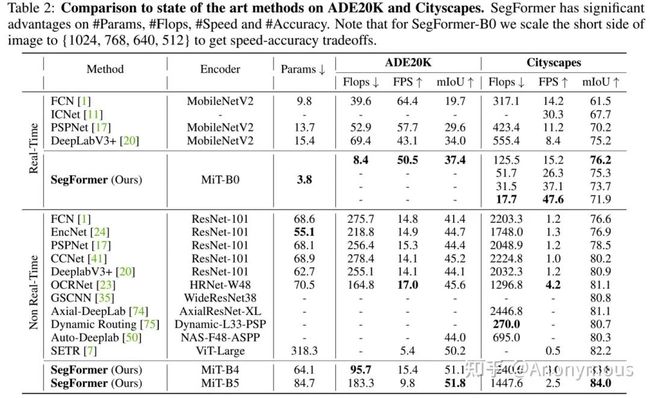
更多关于ADE20K, Cityscape和Coco Stuff的结果可以参考论文的实验部分。关于鲁棒性的结果也可以参考论文的实验部分。
最后的一点总结以及自己的思考,欢迎讨论以及拍砖~
对于语义分割,特征提取非常重要,Transformer已经在分类上证明了比CNN更强大的特征提取能力。但是分类和分割还是有一定的GAP, 因此如何设计对分割友好的更好的Transformer结构,我认为还可以继续研究。
有了很好的特征,decoder该如何设计才能进一步提高性能。我们这里用了一个很简单的MLP decoder取得了不错的效果,而传统的ASPP之类的decoder 在Transformer的基础上帮助不是很大,未来如何针对性的设计更好的decoder也比较值得探索。
最后的最后,SegFormer将会很快在openmmlab的mmsegmentation里开源,mmsegmentation我个人认为是目前最好的语义分割军火库(openmmlab, yyds),推荐大家多多使用。
SegFormer论文PDF下载
后台回复:SegFormer,即可下载论文PDF
CVPR和Transformer资料下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看