RNN和LSTM循环神经网络
为什么为需要循环神经网络?
像DNN这样的神经网络,前一个输入和后一个输入是完全没有关系的,但是某一些任务需要能够更好的处理序列信息(即前面的输入和后面的输入是有关系的)
比如理解一句话的意思时,孤立的理解每个词是不够的,我们需要去处理这些词连接起来的整个序列。
我们一般的做法是用word2vec将词变成向量,再将其传给RNN进行处理。
RNN网络结构
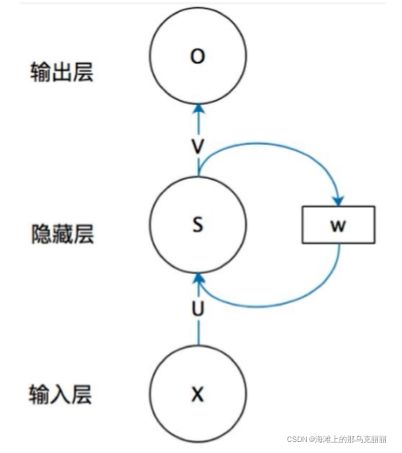
1.RNN有N个时刻的输入,每个输入就相当于每个词的向量。
2.输入经过一个U矩阵全连接,经过隐藏层加和,非线性变换。在经过一个V矩阵全连接,之后直接输出。
RNN在经过隐藏层后会分出来同样的不经过V矩阵,而是经过W矩阵,与下一个时刻的输入加和。
在经过隐藏层非线性变换。以此循环直到输入完毕。
(不管RNN网络有多少个时刻的输入,U,V,W矩阵都是相同的矩阵)
在反向传播的过程中,调整U,V,W矩阵。
例如:I love apple这句话,想要理解这句话的含义,那么每个词都要在前面词的基础上进行理解。
那么RNN输入,把输入的数据打成多个时刻的输入。每个时刻就是输入一个词。经过RNN里面循环后再与下一个词进行加和汇总。
RNN相对于DNN或者CNN,他的网络不会太深。中间的隐藏层可能只有一层或者只有两层。
RNN网络结构展开
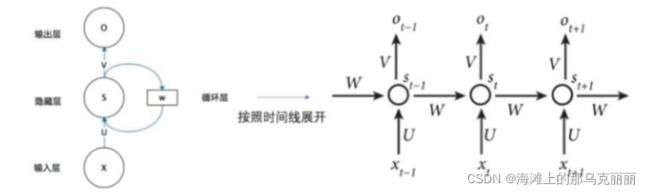
xt-1, xt, xt+1对应三个时刻的输入,ot+1就是结合了前面所有时刻的信息的输出。
RNN计算流程:
我们在每一个时刻输入词的时候,需要先将此转换成词向量(可以用word2vec等方式)词向量维度多长,那么RNN输入层就有多少输入神经元。
经过隐藏层,隐藏层神经元是我们自己设定(假设我们设定n,每个时刻的神经元都是n)
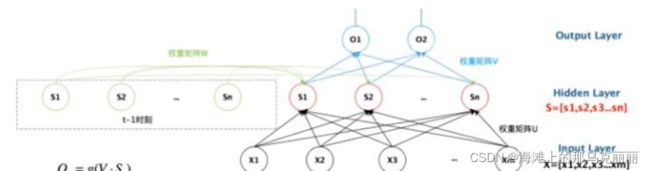
假设我们输入层有n个输入,隐藏层是我们自己设置的神经元n个,那么U矩阵就是m*n
隐藏层有n个神经元,那么就有n个输出。
经过W矩阵后的结果需要和下一时刻经过U矩阵后的向量进行相加,那么W矩阵就是n*n。
因为隐藏层有n个输出,所以V矩阵的形状是n*2(有两个输出)。
RNN计算公式
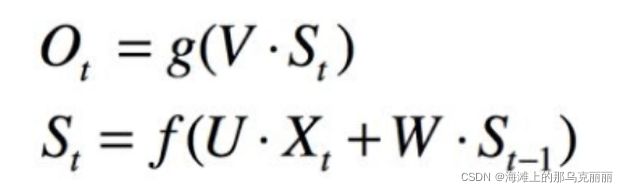
RNN输入往往是按批次batch_size输入,一个时刻的输入是m维度的向量,那么按批次输入一个时刻就是batch_size行m列的矩阵Xt
输入矩阵(batch_size*m)与U(m*n)矩阵相乘得到(batch_size*n)。
那么隐藏层同样的道理一个时刻的隐藏层输出是n维度的输出向量,那么batch_size按批次输出的话就是batch_size行n列的隐藏层输出。
隐藏层(batct_size*n)输出与W(n*n)矩阵相乘得到(batch_size*n)。
两个矩阵汇总相加经过非线性变换,再与V(n*2)矩阵相乘得到输出。
RNN循环网络,第t时刻的输出与前面t-1时刻的输入相关。这就相当于n-gram语言模型把前面n个词都计算上。
LSTM长短时记忆
LSTM是对RNN进行了改进。
RNN缺点:
如果RNN循环的时刻太多,最后时刻会遗忘掉很多信息。
RNN在反向传播时,由于循环时刻太多,导致梯度消失。
LSTM在网络设计上相对于RNN加入了长时记忆。
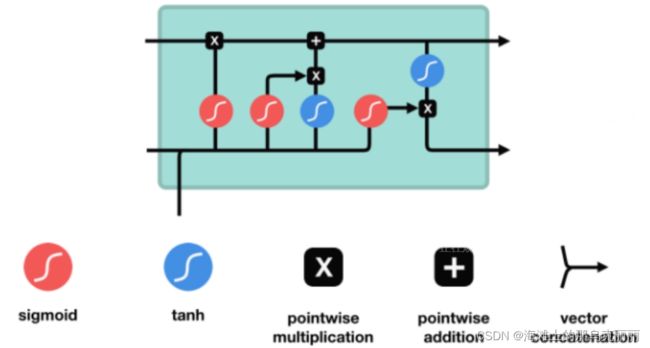
LSTM要训练4个W矩阵。
三个sigmoid函数和一个tanh前面都有一个W矩阵
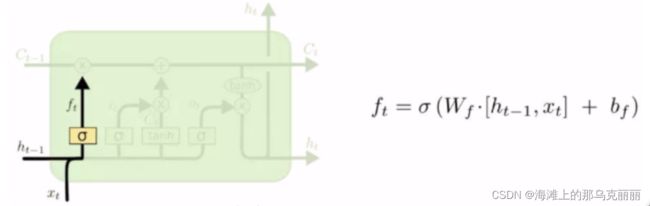
第一个sigmoid遗忘门
x输入与上一时刻ht-1输入相拼接后(batch_size,n)
经过一个W矩阵相乘,再经过sigmoid遗忘门,经过sigmoid会丢弃掉一些短时数据,输出是一个(batch_size,n)矩阵。输出值ft是经过sigmoid后的数据,是0-1之间的数据,输出后与长时记忆相乘
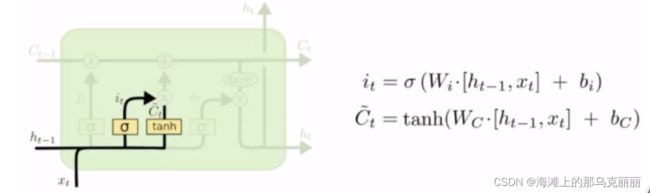
第二个sigmoid+tanh输入门
将短时记忆输入x,再乘上一个sigmoid变换后的x与长时记忆相加。
就是把长时记忆再加上一些东西。
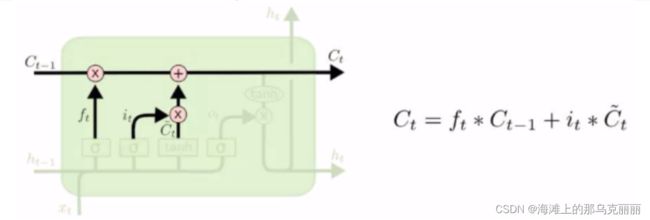
第三个输出门
x输入与上一时刻ht-1输入相拼接后(batch_size,n)
经过sigmoid变换
长时记忆往下经过tanh变换(这里不经过W矩阵)与经过sigmoid变换的输出门相乘再输出得到ht输出。

GRU模型(门控循环单元)
它也是传统RNN的变体,同LSTM一样能够有效捕捉长序列之间的语义关联。能够环境梯度消失或者梯度爆炸的现象,同时它的结构要比LSTM更简单。
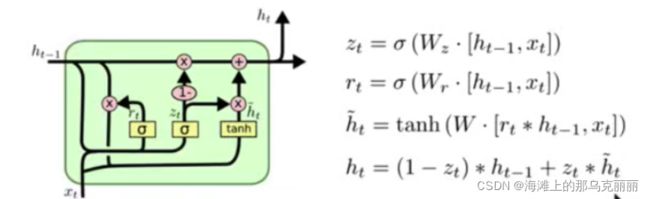
GRU简介_筱筱思的博客-CSDN博客_gru
优点:
GRU作用和LSTM相同,在捕捉长序列语义关联时,能够有效抑制梯度消失和梯度爆炸,效果优于传统RNN且计算复杂度相比LSTM小。
缺点:
GRU仍然不能完全解决梯度消失的问题, 同时起作用RNN的标题,有着RNN本身本身的一大弊端,即不可并行计算。这在数据量和模型体量逐步增大的未来,是RNN发展的关键瓶颈