MindSpore框架TBE算子开发全流程
本文为MindSpore框架TBE算子开发全流程的图文案例。
视频案例请移步MindsSpore框架TBE算子开发全流程
MindSpore框架TBE算子开发全流程
一、工具介绍
1.1 MindStudio介绍
1.2 MindSpore介绍
1.3 TBE算子介绍
二、环境依赖与安装指导
2.1 本地环境配置
2.2 远端环境配置
三、算子分析
四、算子实现
4.1 创建工程
4.2 环境配置
4.3 注册算子原语
4.4 定义反向传播函数
4.5 实现算子
4.6 注册算子信息
五、算子测试
5.1 UT测试
5.2 ST测试
六、开发时可能遇到的问题
七、从昇腾论坛获得更多支持
一、工具介绍
1.1 MindStudio介绍
MindStudio提供您在AI开发所需的一站式开发环境,支持模型开发、算子开发以及应用开发三个主流程中的开发任务。依靠模型可视化、算力测试、IDE本地仿真调试等功能,MindStudio能够帮助您在一个工具上就能高效便捷地完成AI应用开发。MindStudio采用了插件化扩展机制,开发者可以通过开发插件来扩展已有功能。
MindStudio具有如下功能:
- 针对安装与部署,MindStudio提供多种部署方式,支持多种主流操作系统,为开发者提供最大便利。
- 针对网络模型的开发,MindStudio支持TensorFlow、Pytorch、MindSpore框架的模型训练,支持多种主流框架的模型转换。集成了训练可视化、脚本转换、模型转换、精度比对等工具,提升了网络模型移植、分析和优化的效率。
- 针对算子开发,MindStudio提供包含UT测试、ST测试、TIK算子调试等的全套算子开发流程。支持TensorFlow、PyTorch、MindSpore等多种主流框架的TBE和AI CPU自定义算子开发。
- 针对应用开发,MindStudio集成了Profiling性能调优、编译器、MindX SDK的应用开发、可视化pipeline业务流编排等工具,为开发者提供了图形化的集成开发环境,通过MindStudio能够进行工程管理、编译、调试、性能分析等全流程开发,能够很大程度提高开发效率。
1.2 MindSpore介绍
MindSpore是一个全场景深度学习框架,旨在实现易开发、高效执行、全场景覆盖三大目标。
其中,易开发表现为API友好、调试难度低;高效执行包括计算效率、数据预处理效率和分布式训练效率;全场景则指框架同时支持云、边缘以及端端场景。
具体到算子方面,mindspore.ops.operations提供了所有的Primitive算子接口,直接封装了底层的Ascend、GPU、CPU等多种算子的具体实现,为用户提供了基础算子能力。即使内置算子不足以满足用户需求,MindSpore也支持用户自定义算子开发。算子开发的具体实现被封装为几个模块,用户只需要根据引导完成算子的定义、实现、注册等,即可实现简单自定义算子的开发。
1.3 TBE算子介绍
TBE(Tensor Boost Engine)是一款华为自主研发的NPU(Neural-network Process Unit)算子开发工具,它在TVM(Tensor Virtual Machine)框架基础上扩展而来,提供了一套Python API来实施开发活动。通过TBE开发的算子即为TBE算子。
在MindStudio上,TBE算子开发有两种方式,分别是DSL方式和TIK方式。其中,DSL方式入门简单,TBE提供了自动优化机制,适用于初级开发者,能开发一些简单的算子;TIK方式需要开发者了解硬件的缓冲区架构及调度等底层逻辑,难度较高,但开发出的算子能完成更复杂的任务。
本文使用的案例为Square算子的开发,应用场景较为简单,故将使用DSL方式进行开发。
二、环境依赖与安装指导
本次案例将Windows主机作为本地环境,Linux服务器作为远端环境进行开发,以下将分别说明本地环境与远端环境的环境配置。
2.1 本地环境配置
本地环境要求用户系统版本为Windows10及以上,使用x86_64的操作系统。主机上必须配置Python3.7~3.9、MinGW、Cmake等依赖。以上依赖的安装及配置方法可参考MindStudio用户手册的“安装依赖”小节。
配置好以上依赖后,即可安装MindStudio,本案例指导以5.0.RC1Windows为例。
步骤一 下载安装包
进入官网下载MindStudio 5.0.RC1Windows版本,下载免安装压缩版,最新版的MindStudio软件包可点击“此处”进行下载。解压后进入bin目录可直接运行,如图2.1所示。
 图2.1 下载安装包
图2.1 下载安装包
步骤二 运行程序启动文件
下载完成后,将文件进行解压,双击解压后文件,并进入bin目录,双击MindStudio64.exe,如图2.2所示。
 图2.2 运行程序
图2.2 运行程序
步骤三 导入配置
选择Do not import settings,如图2.3所示。
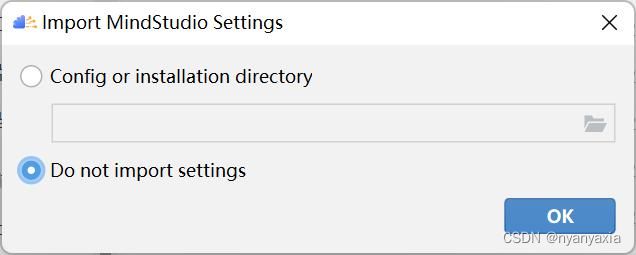 图2.3 配置
图2.3 配置
- Config or installation folder:表示从自定义配置目录导入MindStudio设置。自定义配置目录所在路径:C:\Users\个人用户\AppData\Roaming\MindStudioMS-{version},MindStudio设置包括工程界面的个性化设置(例如背景色等信息)等。
- Do not import settings:不导入设置,若选择该选项,则创建新的配置文件,默认为该选项。
根据需要选择相关选项后,单击“OK”,进入下一步。
如果没有报错信息且能正常进入欢迎界面,则表示MindStudio安装成功,如图2.4所示。
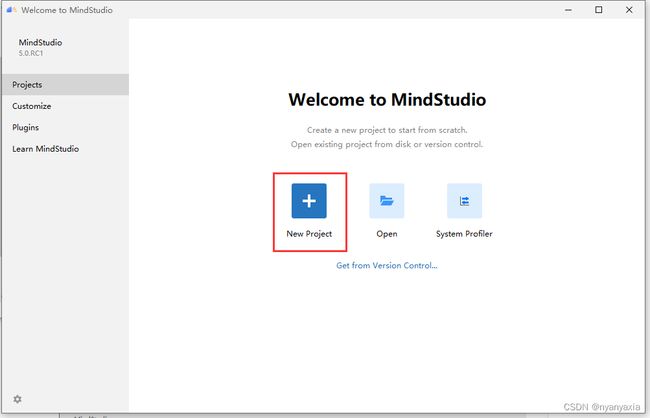 图2.4 首次进入MindStudio界面
图2.4 首次进入MindStudio界面
2.2 远端环境配置
Linux服务器上需安装部署好对应固件与驱动、Ascend-cann-toolkit开发套件包(下载链接请前往CANN社区版,选择5.1.RC2.alpha008版本,以及在固件与驱动链接中获取对应的固件和驱动安装包,安装包的选择与安装方式请参照安装指南)。
在确保系统正确安装了昇腾AI处理器配套软件包后,需要安装好MindSpore(参考MindSpore安装指南,选择适合自己的环境条件后,获取命令并按照指南进行安装)。按照获取命令安装好MindSpore后,需要验证是否安装成功,输入python -c "import mindspore;mindspore.run_check()",输出结果如图2.5所示,表示MindSpore安装成功。
三、算子分析
本案例将以Square TBE算子开发为例,详细讲解算子开发流程。
MindSpore框架下的TBE算子开发的总体流程如图3.1所示。
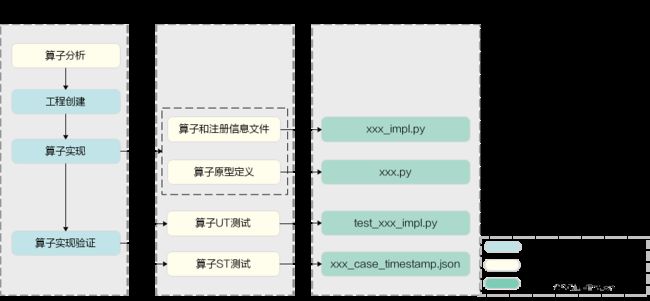 图3.1 MindSpore TBE算子开发流程
图3.1 MindSpore TBE算子开发流程
使用TBE DSL方式开发Square算子前,需要确定算子功能、输入、输出,算子开发方式、算子类型以及算子实现函数名称等。
- 明确算子的功能以及数学表达式。
以Square算子为例,Square算子的数学表达式为:
![]()
计算过程是:将输入参数 与其自身相乘,得到最终结果并将其返回。
与其自身相乘,得到最终结果并将其返回。
- 明确输入与输出。
例如Square算子有一个输入:,输出为 。
。
本样例中算子的输入支持的数据类型为float16、float32,算子输出的数据类型与输入数据类型相同。
算子输入支持所有shape,输出shape与输入shape相同。
算子输入支持的format为:NCHW,NHWC,ND。
- 明确算子实现文件名称以及算子的类型(OpType)。
算子类型需要采用大驼峰的命名方式,即采用大写字符区分不同的语义。
算子文件名称,建议按照如下方式进行转换:
- 首字符的大写字符转换为小写字符。
例如:Abc->abc
- 小写字符后的大写字符转换为下划线+小写字符。
例如:AbcDef->abc_def
因此本例中,算子类型定义为Square,算子的实现文件名称为square。
通过以上分析,得到Square算子的设计规格如下表3-1所示。
| 算子类型 |
Square |
||
| 算子输入 |
name:x |
shape:all |
data type: float16、float32 |
| 算子输出 |
name:y |
shape:all |
data type: float16、float32 |
| 算子实现文件名称 |
square |
||
四、算子实现
本节介绍如何通过MindStudio工具创建算子工程,并通过工具自动生成的文件模板进行算子开发。
4.1 创建工程
- 进入算子工程创建界面
若是首次登录MindStudio,在MindStudio欢迎界面中单击“New Project”,进入创建工程界面,如图4.1所示。
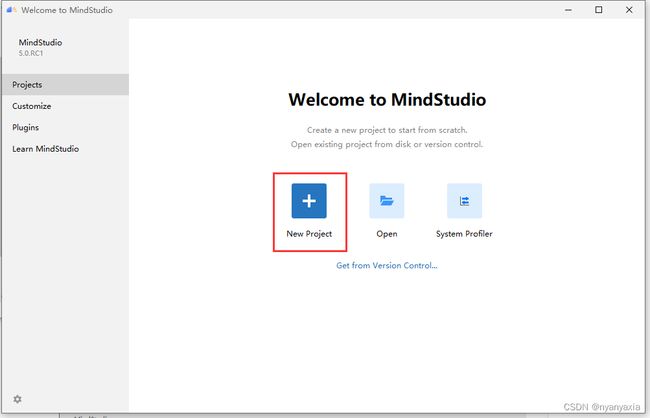 图4.1 首次创建工程
图4.1 首次创建工程
若是非首次登录MindStudio,在顶部菜单栏中选择“File > New > Project”,进入创建工程界面,如图4.2所示。
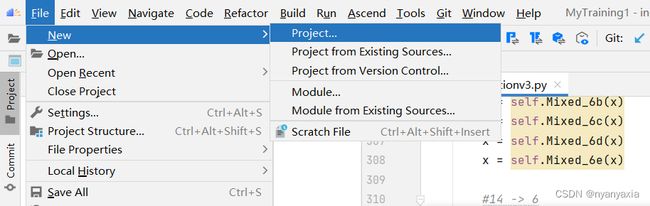 图4.2 非首次创建工程
图4.2 非首次创建工程
- 创建算子工程
在左侧导航栏选择“Ascend Operator”,在右侧配置算子工程信息,具体细节如图4.3所示。
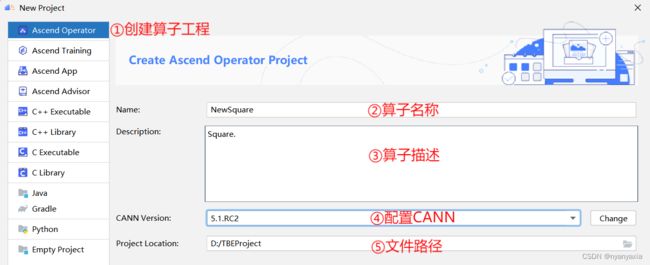 图4.3 创建算子工程
图4.3 创建算子工程
由于本次案例使用了远端环境的CANN进行开发,故需要配置CANN的具体路径。
在第四步配置CANN版本过程中,点击右侧按钮“Change”,出现如图4.4界面。
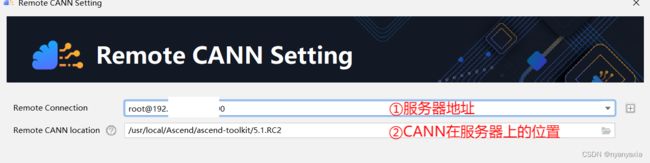 图4.4 CANN配置
图4.4 CANN配置
输入远端服务器地址,并找到CANN所在位置(在本案例中位于“usr/local/Ascend/ascend-toolkit/5.1.RC2”),点击下方按钮“Finish”,完成CANN配置。
点击“Next”按钮,选择对应的模板。
此处一共有四种模板可供选择,分别是Sample Template、Empty Template、IR Template和Tensorflow Template。其中:
Sample Template表示基于样例创建算子工程。用户可以选择使用程序提供的算子样例进行开发,建议初学者使用此方式熟悉算子开发流程。针对本案例,可使用简单快速的DSL开发方式,具体操作如图4.5所示。
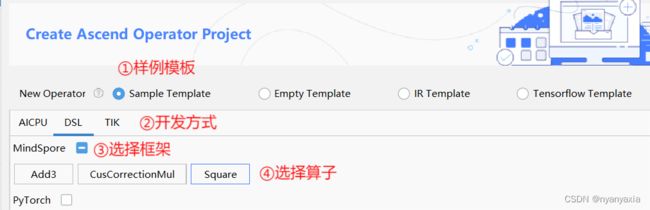 图4.5 样例模板创建算子
图4.5 样例模板创建算子
Empty Template表示创建空的算子工程。为充分讲解TBE算子开发的全流程,本案例将采取此方式创建算子工程,具体细节如图4.6所示。
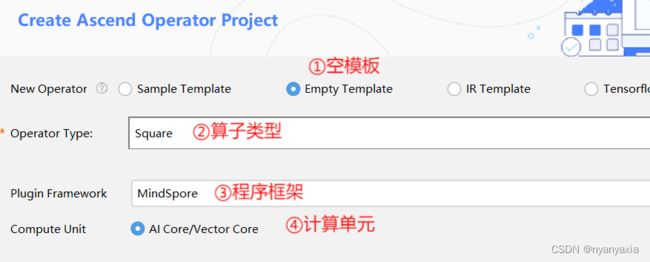 图4.6 空模板创建算子
图4.6 空模板创建算子
由于TBE算子目前只支持运行在AI Core上,因此当程序框架选择“MindSpore”后,仅支持选择“AI Core/Vector Core”。
IR Template表示基于IR定义模板创建算子工程。通过已定义的json或Excel文件,用户可以自定义算子的输入、输出、属性等,缩短了开发的时间。
Tensorflow Template表示基于Tensorflow原型定义创建算子工程。用户需在Mindstudio服务器中下载Tensorflow源码,并配置目录和算子类型。
本案例使用Empty Template方式创建算子工程。待填项填写完毕后,点击下方按钮“Finish”,完成算子工程创建。创建完成时的工程目录结构和主要文件如图4.7所示。
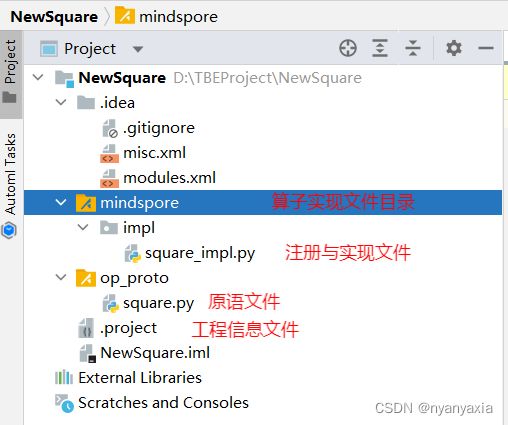 图4.7 初始工程目录结构
图4.7 初始工程目录结构
在实际操作中,主要对square_impl.py以及square.py文件进行编写,以完成算子的开发。
4.2 环境配置
创建工程后,还需要对项目环境进行配置。
- 全局依赖的Python SDK配置
该配置对全部算子工程生效,后续创建算子工程无需重新配置。首次配置方法如下:在工程界面中,点击菜单栏中“File > Project Structure”,进入设置页面。左侧菜单栏点击“SDKs”进行配置,单击上方“+”,点击“Add Python SDK”。具体细节如图4.8所示。
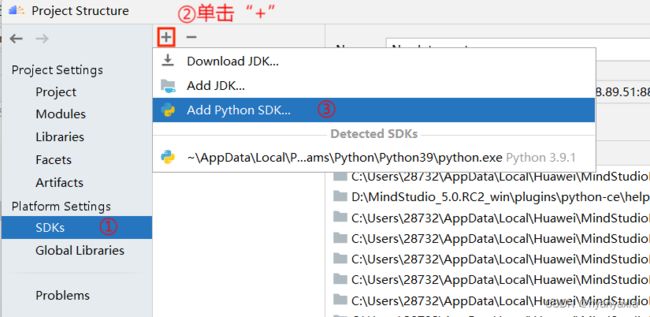 图4.8 添加Python SDK
图4.8 添加Python SDK
此时会出现名为“Add Python Interpret”的页面。
此处有多种方式添加解释器,细节可参考MindStudio用户手册中设置Python库小节。
由于本案例中Python解释器位于远端环境中,故选择最后一项“SSH Interpreter”。此时会出现三个待填项,设置好解释器所在服务器地址后,会自动检索解释器所在路径。最后一项“Name”为解释器名称,用户可以对其进行自定义,本案例中将其命名为“NewInterpreter”,如图4.9所示。
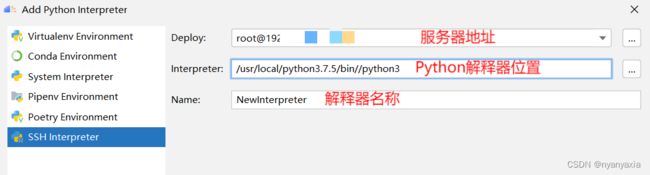 图4.9 设置远程Interpreter
图4.9 设置远程Interpreter
点击右下方按钮“Apply”,再点击按钮“OK”,此时,右下角任务栏将会显示项目正在更新Python解释器,如图4.10所示。
 图4.10 更新Python Interpreter
图4.10 更新Python Interpreter
待更新完成后,可再次回到配置全局SDK的页面,点击已命名的解释器“NewInterpreter”,点击“Packages”,即可查看远端环境上已安装的Python库文件。若库文件能正常显示,则表明远程环境的Interpreter已能正常使用,如图4.11所示。
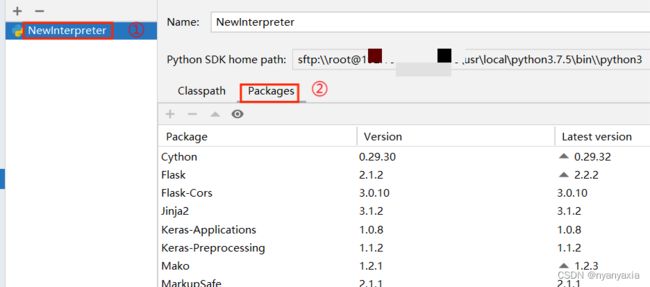 图4.11 查看python库文件
图4.11 查看python库文件
以上工作完成后,项目会在.idea文件夹下生成workspace.xml文件,用于与项目有关的自定义配置。
- 当前算子工程依赖的Python SDK配置
若在算子代码开发过程中引入了其他第三方Python库或自定义Python库,需要在工程中添加相应的Python SDK。
在工程界面中,点击菜单栏中“File > Project Structure”,进入设置页面。
在左侧菜单栏中点击“Project”,在SDK处选择需要配置的Interpreter(此处我们选择之前已配置好的NewInterpreter),如图4.12所示。
 图4.12 配置项目SDK
图4.12 配置项目SDK
点击右下方按钮“Apply”,再点击按钮“OK”,完成项目SDK配置。
以上工作完成后,可以查看相应模块是否完成了自动解析。将光标移至相应包名出,会出现库文件信息,如图4.13所示。
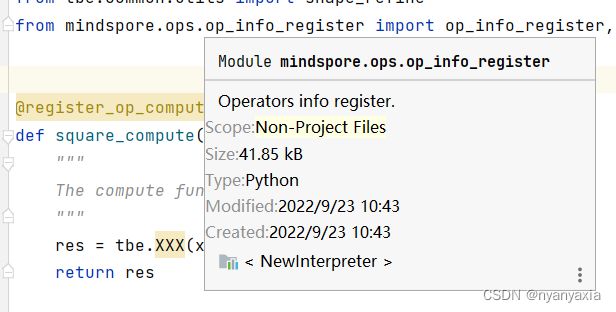 图4.13 代码自动解析
图4.13 代码自动解析
- 项目工程远程同步
对于使用远程环境运行程序的工程,可以通过Deploy功能将项目文件同步到远程环境指定目录,如图4.14所示。
在菜单栏选择“File > Settings”,出现设置页面。
左侧菜单栏选择“Tools > Deployment”,点击“+”,创建新服务器连接。
 图4.14 创建服务器连接
图4.14 创建服务器连接
在弹出的对话框中,为服务器命名,点击“OK”,如图4.15所示。
 图4.15 服务器命名
图4.15 服务器命名
在“Connection”页面下进行连接配置,这里使用的是NewInterpreter所在的服务器NewServer,可以点击“Test Connection”检查服务器连接是否正常,如图4.16所示。
 图4.16 Connection配置
图4.16 Connection配置
在“Mappings”页面配置映射。程序会自动检测本地文件路径,并在远端环境MindStudio工作文件夹下自动创建同步文件夹。用户也可以在远端环境中自定义文件夹,并映射到该文件夹下,如图4.17所示。
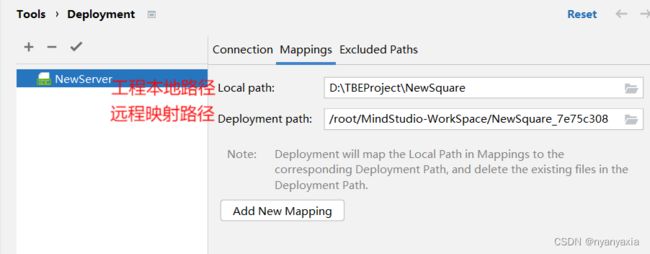 图4.17 Mappings配置
图4.17 Mappings配置
单击“Apply”后,Deploy配置将会生效。在点击run/debug时,会触发Deploy同步功能,本地项目将自动同步到服务器对应文件夹下。
4.3 注册算子原语
算子原语定义了算子在网络中的前端接口原型,也是组成网络模型的基础单元,包括算子的名称、属性、输入输出名称、输入输出dtype推理方法等信息。
空模板为算子原语注册提供了相应的接口,位于square.py文件中,用户只需要按照算子分析的结果补充相关信息即可,如图4.18所示。
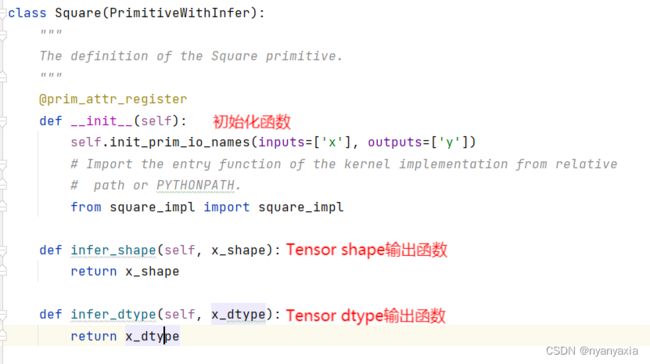 图4.18 注册算子原语
图4.18 注册算子原语
相关参数说明:
- _init_():算子Square类的初始化函数。属性由该构造函数的入参定义,由于Square算子没有属性,因此没有额外入参。
- _init_()中init_prin_io_names():定义了输入与输出的名称。
- infer_shape():定义了输出Tensor的shape推理方法。
- infer_dtype():定义了输出Tensor的dtype推理方法。
4.4 定义反向传播函数
我们希望Square算子支持自动微分,则需要在原语中定义其反向传播函数。该函数应当在square.py文件中、在Square类下进行编写。
Square算子的数学表达式为![]() ,反向传播函数可直接写出,如图4.19所示。
,反向传播函数可直接写出,如图4.19所示。
 图4.19 定义反向传播函数
图4.19 定义反向传播函数
在定义算子反向传播函数时需要注意以下两点:
- bprop()的入参顺序约定为:正向的输入(data)、正向的输出(out)、输出梯度(dout)。
- bprop()的返回值形式约定为:输入梯度组成的元组,元组中元素的顺序与正向输入参数顺序一致。即使只有一个输入梯度,返回值也要求是元组的形式。
4.5 实现算子
实现算子的文件在工程中名叫square_impl.py,模板中已自动生成大部分代码,用户仅需要对少部分代码进行补充与修改即可。
编写一个算子的实现,通常需要编写一个计算函数和一个入口函数。
- 计算函数
计算函数主要用来封装算子的计算逻辑供主函数调用,其内部通过调用TBE的API接口组合实现算子的计算逻辑。
以Square算子为例,square_compute()是算子实现的计算函数,通过调用TBE提供的API描述了![]() 的计算逻辑,如图4.20所示。
的计算逻辑,如图4.20所示。
 图4.20 计算函数
图4.20 计算函数
- 入口函数
算子的入口函数描述了编译算子的内部过程,一般分为以下几步:
- 准备输入的placeholder,该占位符返回一个Tensor对象,表示一组输入数据。
- 调用计算函数。
- 调用Schedle调度模块,默认采用自动调度auto_schedule()。
- 配置编译信息。
- 进行算子编译。
本案例Square算子的入口函数代码,如图4.21所示。
 图4.21 入口函数
图4.21 入口函数
4.6 注册算子信息
算子信息是指导后端选择算子实现的关键信息,同时也指导后端为算子插入合适的类型和格式转换。算子信息中比较重要的设置如下:
- TBERegop:算子注册名称,需要与算子名称一致。
- fusion_type:融合策略,“OPAQUE”表示采取不融合策略。
- kernel_name:生成算子二进制名称,参数需要与算子入口函数名称一致。
- input:算子输入信息,包含输入名称、支持的shape等信息。
- output:算子输出信息,包含输出名称、支持的shape等信息。
- dtype_format:算子支持的数据类型,在前面的算子分析中确定可支持的数据类型为float16与float32。
本案例的算子信息配置如图4.22所示。
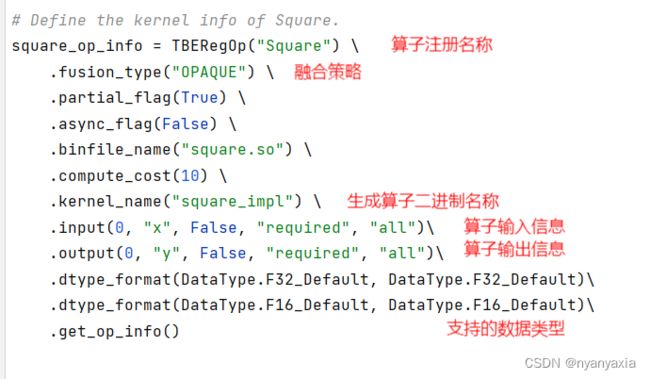 图4.22 算子信息配置
图4.22 算子信息配置
算子信息配置完成后,op_info_register装饰器将算子信息与算子实现入口函数绑定。当算子实现py文件被导入时,op_info_register装饰器会将算子信息注册到后端的算子信息库中。
五、算子测试
5.1 UT测试
UT测试:即单元测试(Unit Test),仿真环境下验证算子实现的功能正确性,包括算子逻辑实现代码及算子原型定义实现代码。
如图5.1所示,右键单击“testcases/ut/ops_test”文件夹,选择Run TBE Operator‘All’UT Impl with coverage,运行整个文件夹下算子实现代码的测试用例。
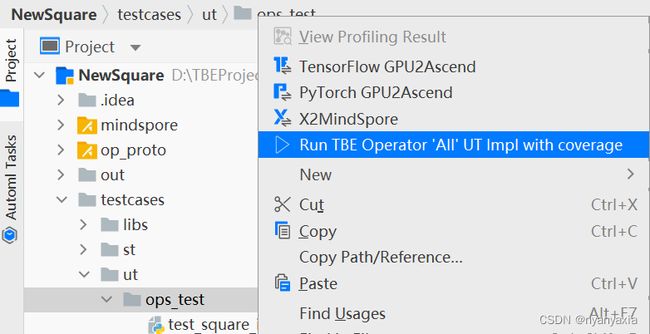 图5.1 UT测试
图5.1 UT测试
第一次运行时会弹出运行配置页面,如图5.2所示,具体配置信息参考配置参数表,如表5-1所示,然后单击Run。
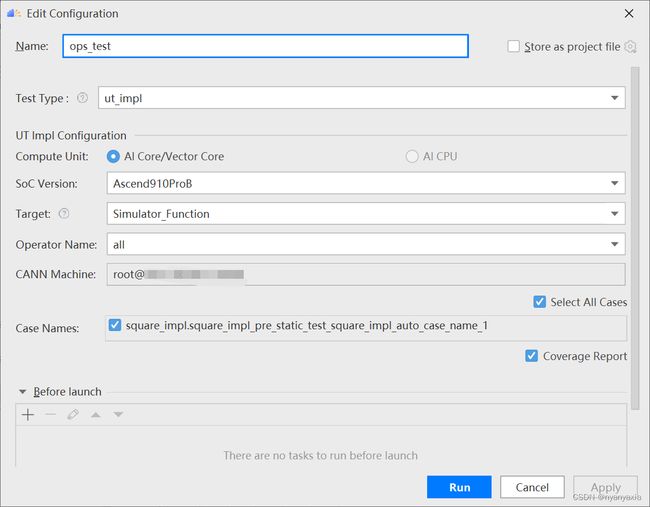 图5.2 运行配置界面
图5.2 运行配置界面
| 参数 |
说明 |
| Name |
运行配置名称,用户可以自定义。 |
| Test Type |
选择ut_inpl。 |
| Compute Unit |
选择计算单元
选择不同的计算单元可以实现AI Core/Vector Core和AI CPU UT测试配置界面的切换。 |
| Soc Version |
下拉选择当前版本的昇腾AI处理器类型。 MindSpore只支持昇腾910处理器。 |
| Target |
运行环境。
当前功能仅支持Ascend 910系列AI处理器。 |
| Operator Name |
选择运行的测试用例。
|
| CANN Machine |
CANN工具所在设备的SSH配置信息。添加SSH配置信息的方法请参见SSH连接管理。 说明:仅支持Windows操作系统。 |
| Case Names |
勾选需要运行的测试用例,即算子实现代码的UT Python测试用例。支持全选和全不选所有测试用例。 |
运行完成后,通过界面下方的“Run”日志打印窗口查看运行结果,如图5.3所示。在“Run”窗口中单击report index.html的URL(URL中的localhost为MindStudio安装服务器的IP,建议直接单击打开),查看UT测试用例的覆盖率结果,如图5.4所示,表示算子的UT用例覆盖率为100%,UT验证通过。
 图5.3 运行结果示意图
图5.3 运行结果示意图
 图5.4 UT测试通过示意图
图5.4 UT测试通过示意图
5.2 ST测试
ST测试:即系统测试(System Test),可以自动生成测试用例,在真实的硬件环境中,验证算子功能的正确性。
如图5.5所示,右键单击ST测试用例定义文件(路径:“testcases > st > square> xxxx.json”),选择 "Run ST Case’xxx.json’"。
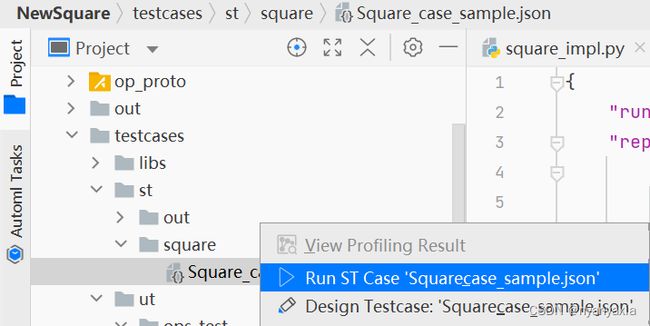 图5.5 ST测试
图5.5 ST测试
第一次运行时会弹出运行配置页面,如图5.6所示,具体配置信息参考配置参数表,如表5-2所示,然后单击Run。
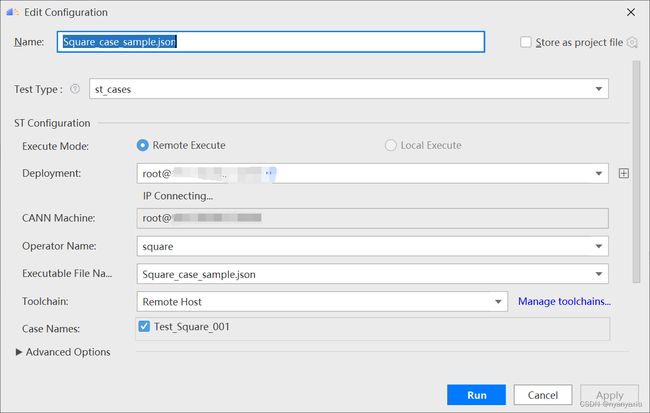 图5.6 运行配置界面
图5.6 运行配置界面
| 参数 |
说明 |
| Name |
运行配置名称,用户可以自定义。 |
| Test Type |
选择st_cases 。 |
| Execute Mode |
说明:Local Execute不支持Windows操作系统。 |
| SSH Connection |
当Execute Mode选择Remote Execute时,下拉选择SSH配置信息,若未添加配置信息,请单击+添加。 |
| CANN Machine |
CANN工具所在设备的SSH配置信息。添加SSH配置信息的方法请参见SSH连接管理。 说明:该参数仅支持Windows操作系统。 |
| Operator Name |
选择需要运行的算子。 |
| Executable File Name |
下拉选择需要执行的测试用例定义文件。 |
| Toolchain |
下拉选项框选择toolchain。 |
| Case Names |
选择运行的Case Name。 说明:默认全选所有用例,可以去除勾选部分不需要运行的用例。 |
ST测试成功后在运行部分的输出和输出的文件st_report.json样例如图5.7所示:
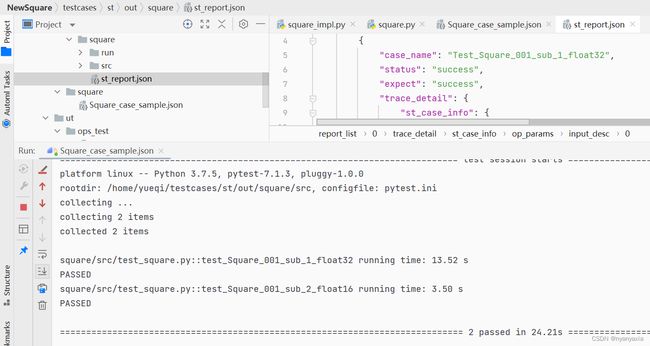 图5.7 ST测试成功示意图
图5.7 ST测试成功示意图
六、开发时可能遇到的问题
- 问题一:验证mindspore安装是否成功时出现错误:
/root/archiconda3/lib/python3.7/site-packages/mindspore/lib/libmindspore_backend.so: undefined symbol。
解答:mindspore版本与CANN版本不配套。
- 问题二:ST测试报错.json文件contains invalid characters。
解答:文件路径含中文。
- 问题三:MindStudio安装成功,但是无法启动,显示如下:
 图6.1 MindStudio启动报错
图6.1 MindStudio启动报错
解答:由于jdk版本过低等各种问题,旧版本的MindStudio在运行过程中可能会出现版本不匹配问题,建议到官网下载最新版MindStudio,以规避此类问题。
- 问题四:创建项目工程后,配置完全局和项目SDK,出现以下问题:
 图6.2 IDE报错
图6.2 IDE报错
解答:以上问题常见于刚配置完SDK或配置SDK过程中。由于Interpreter更新速度较慢,可能会出现库文件为空、定义的Interpreter无法识别库文件等问题,一般在Interpreter加载完成后问题会自动消失。
如果Interpreter还是无法识别库文件,可以尝试进入Project Structure设置界面(点击“File > Project Structure”),点击左侧菜单栏“Modules”,选择项目工程,将模块默认SDK改为已配置好的SDK,如图6-3所示。
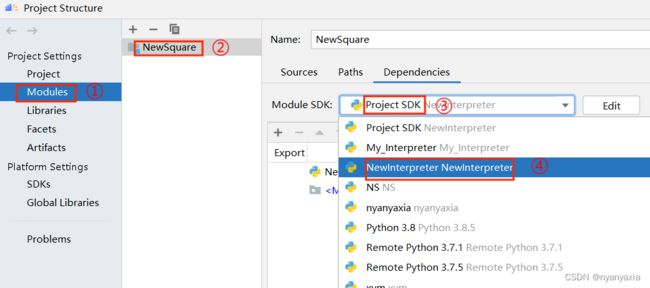 图6.3 配置模块SDK
图6.3 配置模块SDK
如果以上方式还是不能解决问题,则需要重新配置全局SDK和项目SDK,请参考4.2 环境配置小节。
七、从昇腾论坛获得更多支持
如果遇到其他上述步骤中未出现的错误,欢迎大家到昇腾论坛(进入昇腾论坛_开发者论坛-华为云论坛 (huaweicloud.com),选择开发者选项,点击进入昇腾论坛或者昇腾)中提出自己的问题在这里有很多技术大拿可以解决你的问题。或者也可以访问昇腾博客,搜索他人的独到见解。