ViViT: A Video Vision Transformer 用于视频数据特征提取的ViT详解【码字中。。】

目录
- 前言摘要
- 一、Overview of ViT 回顾视觉 ViT
- 二、Embedding video clips 视频嵌入方法
-
- 2.1 uniform frame sampling 均匀采样
- 2.2 tubelet embedding 时空管采样
- 三、Transformer for Video 网络结构
-
- 3.1 factorised encoder
前言摘要
文章主要transformer在包含时序信息维度的视频格式上的问题展开:
- 一、视频格式数据生成的token序列数量过多,带来繁重的计算冗余。
- 二、训练Transfomer结构模型需要引入大规模的数据集,训练对数据条件十分苛刻。
为了高效处理视频数据中生成的大规模时空tokens,①文章提出并探讨了几种对空间和时间维度进行分解的方法,进而提出了相应的网络结构,从而增加模型对视频数据特征提取的效率和可扩展性。②其次,规范了模型的训练(主要针对模型的训练策略)。目的在小数据集上也能使得Transformer类模型能有很好的效果。
论文名称: ViViT: A Video Vision Transformer
论文地址: ICCV 2021 open access
代码地址: GitHub(Unofficial implementation)–非官方实现
一、Overview of ViT 回顾视觉 ViT
基础的ViT模型主要有三个模块组成:
- Linear Project of Flattened Patches即为Embedding层,对输入的三通道图像数据利用conv卷积层进行分块并完成对应的线性映射,如上式当中的E,而后通过torch.view()进行展平压缩维度。拼接上类别token后采用矩阵相加方式引入位置编码。
- Transformer Encoder模块,对Embedding层输出的token进行多头注意力计算和多层感知机(中间包含Layer Norm)。其中MSA是整个模型的核心部分。
- MLP Head层,堆叠的Transformer Block最终的输出经过Head结构提取出类别token所对应的结果信息,文中通过两个线形层叠加中间插入一个tanh激活函数来实现。
二、Embedding video clips 视频嵌入方法
区别于常规的二维图像数据,视频数据相当于需在三维空间内进行采样(拓展了一个时间维度)。而文章中所提出的两钟视频嵌入方法目的都是将视频数据 V ∈ R T × H × W × C V\in\R^{T×H×W×C} V∈RT×H×W×C 映射到token当中得到 z ~ ∈ R n t × n h × n w × d \widetilde{z}\in\R^{n_t×n_h×n_w×d} z ∈Rnt×nh×nw×d,而后添加位置编码并对token进行reshape得到最终Transformer的输入 z ∈ R N × d z\in\R^{N×d} z∈RN×d。
2.1 uniform frame sampling 均匀采样
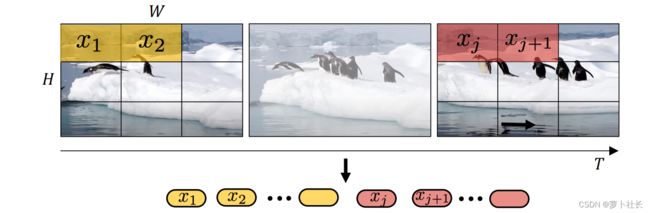
采用相同的采样帧率,从视频数据当中均匀采样 n t n_t nt帧,使用相同的embedding方法独立地处理每一个帧当中的patch,而后将得到的所有token拼接concat在一起。具体而言,从每个采样获得的帧当中划分 n w × n t n_w×n_t nw×nt个不重叠的图像块patch,则共产生 n t × n w × n t n_t×n_w×n_t nt×nw×nt个tokens输入Transformer当中。
然而这种切片方法对于长时间序列的数据来说生成的token长度极大,并且不同帧间首位相连的patch在位置编码上与真实情况不一致。
2.2 tubelet embedding 时空管采样
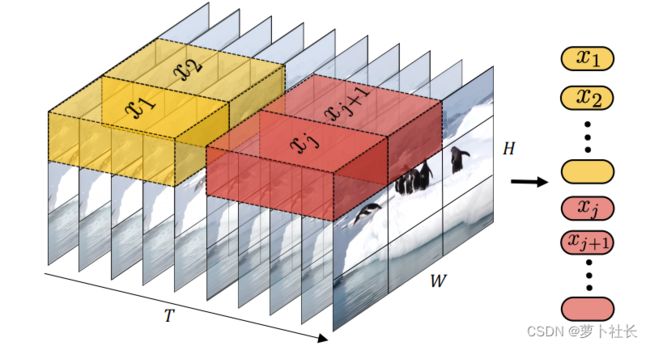
从输入volume(体积)当中提取时空上不重叠的“tubes”,这种方法是将vit嵌入到3D的拓展,embedding层就对应的选取三维卷积。则对于维度为 t × h × w t×h×w t×h×w的tube管来说,有 n t = [ T t ] , n h = [ H h ] , n w = [ W w ] n_t=[\frac{T}{t}],n_ℎ=[\frac{H}{h}],n_w=[\frac{W}{w}] nt=[tT],nh=[hH],nw=[wW]。这种采样方法直接在采样的过程当中就融合了时空信息。
三、Transformer for Video 网络结构
3.1 factorised encoder
Factorised encoder方法:构建两个单独的transformer encoder,分别针对空间和时间处理。首先利用空间编码器(Space Transformer),通过对同一时间索引的token建模。输出cls_token。而后将输出的类别token和帧维度的表征token拼接输入到时间编码器(Time Transformer)中得到最终的结果。(相当于两个Transformer模型的叠加),实现代码如下:
class ViViT(nn.Module):
def __init__(self, image_size, patch_size, num_classes, num_frames, dim = 192, depth = 4, heads = 3, pool = 'cls', in_channels = 3, dim_head = 64, dropout = 0.,
emb_dropout = 0., scale_dim = 4, ):
super().__init__()
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)
assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_size // patch_size) ** 2
patch_dim = in_channels * patch_size ** 2
self.to_patch_embedding = nn.Sequential(
Rearrange('b t c (h p1) (w p2) -> b t (h w) (p1 p2 c)', p1 = patch_size, p2 = patch_size),
nn.Linear(patch_dim, dim),
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_frames, num_patches + 1, dim))
self.space_token = nn.Parameter(torch.randn(1, 1, dim))
self.space_transformer = Transformer(dim, depth, heads, dim_head, dim*scale_dim, dropout)
self.temporal_token = nn.Parameter(torch.randn(1, 1, dim))
self.temporal_transformer = Transformer(dim, depth, heads, dim_head, dim*scale_dim, dropout)
self.dropout = nn.Dropout(emb_dropout)
self.pool = pool
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, x):
x = self.to_patch_embedding(x)
b, t, n, _ = x.shape
cls_space_tokens = repeat(self.space_token, '() n d -> b t n d', b = b, t=t)
x = torch.cat((cls_space_tokens, x), dim=2)
x += self.pos_embedding[:, :, :(n + 1)]
x = self.dropout(x)
x = rearrange(x, 'b t n d -> (b t) n d')
x = self.space_transformer(x)
x = rearrange(x[:, 0], '(b t) ... -> b t ...', b=b)
cls_temporal_tokens = repeat(self.temporal_token, '() n d -> b n d', b=b)
x = torch.cat((cls_temporal_tokens, x), dim=1)
x = self.temporal_transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
return self.mlp_head(x)