在C中关于网络字节序和主机字节序困扰了我一段时间,在python中实现字节流的网络传输,必然这个问题也不可避免,但是我觉得在python中解决这个问题和演示起来比较方便一点。
我们上次用struct的pack方法实现了字节流,那么这里就牵涉到一个字节流的字节序问题,当一个16位的int型数据形成01的字节流时,是高位在前,还是低位在前?这里分为网络字节序,和主机字节序。
Little endian:将低序字节存储在起始地址
Big endian:将高序字节存储在起始地址
LE little-endian :
最符合人的思维的字节序,地址低位存储值的低位,地址高位存储值的高位,怎么讲是最符合人的思维的字节序,是因为从人的第一观感来说低位值小,就应该放在内存地址小的地方,也即内存地址低位反之,高位值就应该放在内存地址大的地方,也即内存地址高位
BE big-endian
最直观的字节序,地址低位存储值的高位,地址高位存储值的低位,为什么说直观,不要考虑对应关系
只需要把内存地址从左到右按照由低到高的顺序写出,把值按照通常的高位到低位的顺序写出 两者对照,一个字节一个字节的填充进去
例子:在内存中双字0x01020304(DWORD)的存储方式
内存地址
4000 4001 4002 4003
LE 04 03 02 01
BE 01 02 03 04
例子:如果我们将0x1234abcd写入到以0x0000开始的内存中,则结果为
big-endian little-endian
0x0000 0x12 0xcd
0x0001 0x23 0xab
0x0002 0xab 0x34
0x0003 0xcd 0x12
x86系列CPU都是little-endian的字节序.
我们用python来试验一下:
>>> from struct import *
>>> pack('@h',14)
'\x0e\x00'
>>>
int型的整数14用二进制表示应该为0000000000001110,十六进制的话应该为0x00\ox0e ,但是如果说是低位字节存放低位,那么低位字节0x0e就应该存在低位,然后高位就存放0x00,这就是我们电脑在内存中存放这个数的形式。我们用pack,参数为’@h’,就是把14按照主机字节序,以2字节的int型存放到内存中的。
网络字节顺序是TCP/IP中规定好的一种数据表示格式,它与具体的CPU类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释。网络字节顺序采用big endian排序方式。那么如果我们要把数据流发到网络上,必须把字节顺序改为高字节在前,低字节在后,就是我们发送一个0000000000001110,我们必须先发高字节00000000,然后在发低字节00001110,也就是十六进制的0x00 0x0e
在struct的pack打包中,提供了一个’!’,来实现网络字节序,比如同样是上面的例子:
>>> from struct import *
>>> pack('!h',14)
'\x00\x0e'
>>>
可以看到,确实是高字节在前,低字节在后了。假如我们要把这个14通过UDP协议发送给另外一个主机,那么我们就要用这个字节序。
下面我看一个具体传输的例子吧,基于UDP的。
首先我们在server和client端都用网络字节序来pack和unpack,我们看看结果会是什么样:
Server端:
import socket
import struct
BUFSIZ=1024
ADDR=('localhost',2046)
recvsocket=socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
while True:
print 'waiting for the data'
data,addr=recvsocket.recvfrom(BUFSIZ)
print repr(data)
(data1,)=struct.unpack('h',data)
print repr(data1)
(data2,)=struct.unpack('!h',data)
print data2
recvsocket.close()
下面是client端:
import socket
import struct
BUFSIZ=1024
ADDR=('localhost',2046)
sendsocket=socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
data=struct.pack('!h',14)
print repr(data)
sendsocket.sendto(data,ADDR)
sendsocket.close()
我们还是在client端往server端发一个14,int型数据,我们看看运行结果:
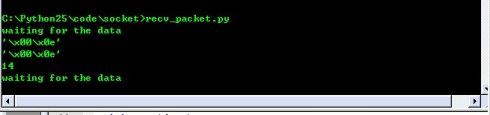
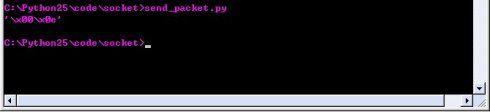
其中红色命令窗口为client端,绿色是server端,可以看到14通过pack传出去的确是高字节在前,低字节在后,属于网络字节序,而server收到的14在内存中也是高字节在前,低字节在后的,这样我们通过unpack就能得到正确的结果。
整个过程是这样的:
14也就是0000000000001110,用pack时候我们用的网络字节序来存,那么在内存中高字节00000000在前,低字节00001110在后(假如不指定用网络字节序的话,它会颠倒)然后我们传输的时候,因为网络传输是默认高字节在前,00000000先传,00001110后传,到接受端接收到的还没有unpack的数据也就是00000000在前,00001110在后了,如果这时候我们unpack不用网络字节序来分的话,那么得到的结果就是错误的,因为那么CPU会以为这个数不是0000000000001110而是0000111000000000.所以就不对了。
附注:
1、网络与主机字节转换函数:htons ntohs htonl ntohl (s 就是short l是long h是host n是network)
2、不同的CPU上运行不同的操作系统,字节序也是不同的,参见下表。
处理器 操作系统 字节排序
Alpha 全部 Little endian
HP-PA NT Little endian
HP-PA UNIX Big endian
Intelx86 全部 Little endian <-----x86系统是小端字节序系统
Motorola680x() 全部 Big endian
MIPS NT Little endian
MIPS UNIX Big endian
PowerPC NT Little endian
PowerPC 非NT Big endian <-----PPC系统是大端字节序系统
RS/6000 UNIX Big endian
SPARC UNIX Big endian
IXP1200 ARM核心 全部