OpenCV基础(15)OpenCV DNN模块的深度学习:权威指南
计算机视觉领域自20世纪60年代末就存在了。图像分类和目标检测是计算机视觉领域的一些最古老的问题,研究人员几十年来一直试图解决这些问题。利用神经网络和深度学习,我们已经达到了一个阶段,计算机可以开始真正理解和识别一个物体,准确率很高,在很多情况下甚至超过了人类。要了解神经网络和计算机视觉深度学习,OpenCV的DNN模块是一个很好的起点。其高度优化的CPU性能,初学者也可以轻松入门,即使他们没有一个非常强大的GPU。
不仅是理论部分,我们还涵盖了OpenCV DNN的实践经验。我们将详细讨论图像和实时视频中的分类和目标检测。
1.什么是OpenCV DNN模块?
我们都知道OpenCV是最好的计算机视觉库之一。此外,它还具有运行深度学习推理的功能。最好的部分是支持加载来自不同框架的不同模型,使用它我们可以执行几个深度学习功能。从3.3版开始,OpenCV就支持来自不同框架的模型。然而,许多新进入该领域的人并不知道OpenCV的这个伟大特性。因此,他们往往会错过许多乐趣和良好的学习机会。
2.为什么选择OpenCV DNN模块?
OpenCV DNN模块只支持图像和视频的深度学习推理。它不支持微调和训练。不过,OpenCV DNN模块可以作为任何初学者进入基于深度学习的计算机视觉领域的一个完美起点。
OpenCV DNN模块最好的地方之一是它是为英特尔处理器高度优化的。在实时视频中对目标检测和图像分割应用进行推理时,可以获得良好的帧率。当我们使用特定框架预先训练的模型时,使用DNN模块通常会获得更高的FPS。例如,让我们看看不同框架下的图像分类推理速度。
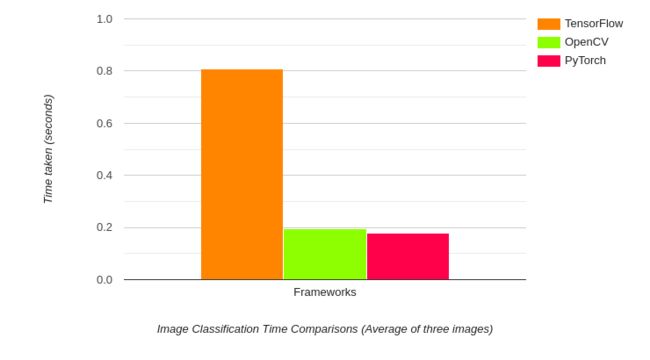
以上结果为DenseNet121模型的推理时间。令人惊讶的是,OpenCV比TensorFlow的原始实现要快得多,同时还稍微落后于PyTorch。事实上,TensorFlow的推断时间接近1秒,而OpenCV只需要不到200毫秒。
即使在对象检测的情况下也是如此。
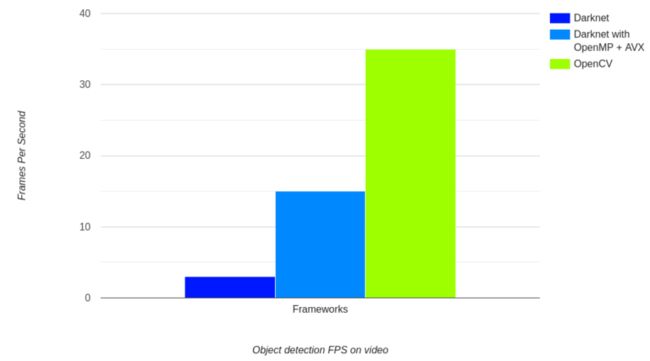
上图显示了在原始Darknet框架和OpenCV上使用Tiny YOLOv4进行视频FPS的结果。基准测试是在Intel i7 8代笔记本电脑CPU上进行的,时钟速度为2.6Ghz。在同一个视频中,我们可以看到OpenCV的DNN模块运行在35帧每秒,而使用OpenMP和AVX编译的Darknet运行在15帧每秒。而Darkne(没有OpenMP或AVX)的Tiny YOLOv4是最慢的,只有3帧每秒。这是一个巨大的区别,因为我们在这两种情况下都使用了最初的Darknet Tiny YOLOv4模型。
上面的图表显示了OpenCV DNN模块在与cpu一起工作时的实际用处和能力。由于它的快速推断时间,即使在cpu上,它也可以在计算能力有限的边缘设备上作为出色的部署工具。基于ARM处理器的边缘设备就是最好的例子。下面的图表很好地证明了这一点。
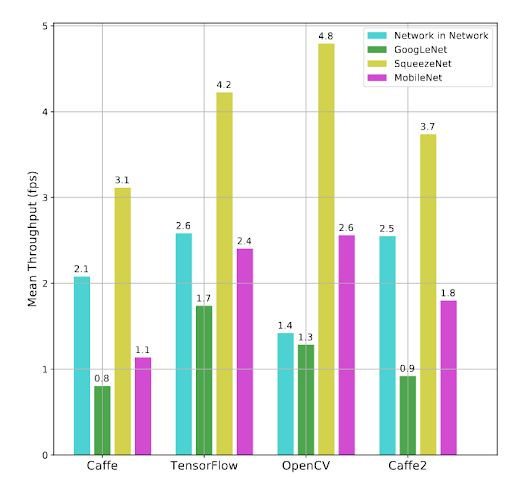
上图显示了运行在Raspberry Pi 3B上的不同框架和模型的FPS。结果令人印象深刻。对于SqueezeNet和MobileNet模型,OpenCV在FPS方面超过了所有其他框架。对于googleNet来说,OpenCV排在第二,TensorFlow是最快的。对于Network in Network,OpenCV树莓派FPS是最慢的。
上面的几个图展示了优化后的OpenCV,以及它用于神经网络推理的速度。这些数据是选择详细了解OpenCV DNN模块的完美理由。
3.OpenCV DNN模块支持的不同深度学习功能
我们建立了利用OpenCV DNN模块,可以对图像和视频进行基于深度学习的计算机视觉推理。让我们看看它支持的所有功能。有趣的是,我们能想到的大多数深度学习和计算机视觉任务都得到了支持。下面的列表将让我们对这些特性有一个很好的了解。
- 图像分类。
- 对象检测。
- 图像分割。
- 文本检测与识别。
- 姿态估计。
- 深度估计。
- 行人与人脸验证与检测。
- 行人重识别
这个列表非常广泛,并提供了许多实际的深度学习用例。通过访问OpenCV存储库的Wiki页面,可以了解更多细节。
我们将详细讨论目标检测和人体姿态估计,以给出使用OpenCV DNN选择不同模型的工作思路。
4.OpenCV DNN模块支持的不同模型
为了支持我们上面讨论的所有应用程序,我们需要许多预先训练过的模型。此外,还有许多最先进的算法可供选择。下表根据不同的深度学习应用列出了一些模型。
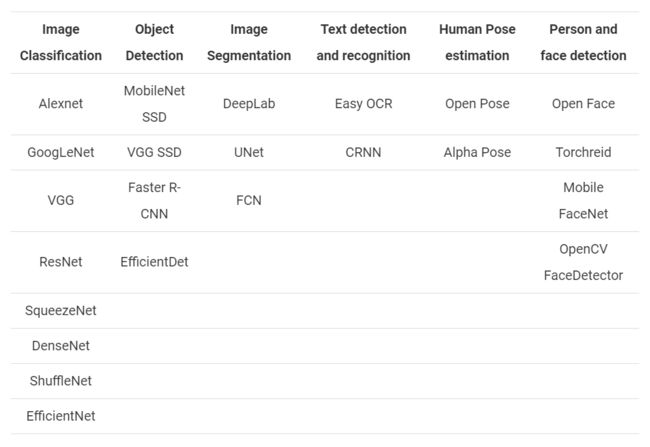
上述模型并非详尽无遗。还有更多的模式。正如前面提到的,在一个博客中完整地列出或详细讨论每一项内容几乎是不可能的。上面的列表让我们很好地了解了DNN模块在探索计算机视觉中的深度学习方面的实用性。
5.OpenCV DNN模块支持的不同框架
看看上面所有的模型,一个问题浮现在脑海中,“所有这些模型都是由一个单一框架支持的吗?”事实上,没有。
OpenCV DNN模块支持许多流行的深度学习框架。以下是OpenCV DNN模块支持的深度学习框架。
Caffe:为了使用OpenCV DNN预先训练过的Caffe模型,我们需要两件事。一个是model.caffemodel文件包含预先训练权重。另一个是模型架构文件,扩展名为.prototxt。它就像一个带有JSON结构的纯文本文件,包含所有神经网络层的定义。TensorFlow:为了加载预先训练好的TensorFlow模型,我们还需要两个文件。模型权重文件和包含模型配置的protobuf文本文件。权重文件有一个.pb扩展名,它是一个protobuf文件,包含所有预先训练的权重。如果您以前使用过TensorFlow,您就会知道。pb文件是我们保存模型并冻结权重后得到的模型检查点(checkpoint)。模型配置保存在protobuf文本文件中,该文件的扩展名是.pbtxt。
注意:在TensorFlow的新版本中,模型权重文件可能不是.pb格式。如果你试图使用你自己保存的.ckpt或.h5格式的模型,这也是正确的。在这种情况下,在模型可以与OpenCV DNN模块一起使用之前,需要执行一些中间步骤。在这种情况下,将模型转换为ONNX格式,然后转换为.pb格式,这是确保一切按照预期工作的最好方法。Torch和PyTorch:为了加载Torch模型文件,我们需要包含预先训练的权重的文件。通常,这个文件有.t7或.net扩展名。但是由于最新的PyTorch模型具有.pth扩展名,所以最好先转换为ONNX。在转换到ONNX之后,你可以直接加载它们,因为OpenCV DNN支持ONNX模型。Darknet:OpenCV DNN模块也支持著名的Darknet框架。如果他们在Darknet框架中使用了官方的YOLO模型,人们可能会意识到这一点。
通常,要加载Darknet模型,我们需要一个具有.weights扩展名的模型权重文件。对于Darknet模型,网络配置文件总是一个.cfg文件。使用从不同框架(如Keras和PyTorch)转换为ONNX格式的模型:通常,在PyTorch或TensorFlow等框架中训练的模型可能无法直接用于OpenCV DNN模块。在这些情况下,通常我们将模型转换为ONNX格式(Open Neural Network Exchange),然后可以直接使用它,甚至转换为TensorFlow或PyTorch等其他框架支持的格式。
为了加载ONNX模型,我们只需要OpenCV DNN模块的.ONNX权重文件。
最可能的情况是,上述列表涵盖了所有著名的深度学习框架。要了解OpenCV DNN模块支持的所有框架和模型的完整信息,请访问官方Wiki页面。
我们已经学了足够多的理论。让我们深入学习本教程的编码部分。首先,我们将使用OpenCV DNN模块对图像分类进行完整的演练。然后我们将使用DNN模块进行目标检测。所有代码
链接链接:https://pan.baidu.com/s/1E5Ki0uscfSSLblO_H9e-8w
提取码:123a
6.使用OpenCV DNN模块进行图像分类的完整指南
在本节中,我们将使用OpenCV DNN模块对图像进行分类。
我们将使用Caffe框架在非常著名的ImageNet数据集上训练的神经网络模型。具体来说,我们将使用DensNet121深度神经网络模型进行分类任务。其优点是它预先训练了来自ImageNet数据集的1000个类。我们可以预期,我们想要分类的任何图像都已经被模型看到了。这使得我们可以从广泛的图像中进行选择。
我们将使用下面的老虎图像进行图像分类任务。

简单地说,下面是我们在对图像进行分类时要遵循的步骤。
- 从磁盘加载类名文本文件并提取所需的标签。
- 从磁盘加载预训练的神经网络模型。
- 从磁盘加载图像,并将图像准备为深度学习模型的正确输入格式。
- 通过模型前向传播输入图像并获得输出。
(1)Python
import cv2
import numpy as np
# 读取ImageNet类名
with open('../../input/classification_classes_ILSVRC2012.txt', 'r') as f:
image_net_names = f.read().split('\n')
# 最终类名(这只是一个图像的多个ImageNet名称中的第一个单词)
class_names = [name.split(',')[0] for name in image_net_names]
# 加载神经网络模型
model = cv2.dnn.readNet(model='../../input/DenseNet_121.caffemodel',
config='../../input/DenseNet_121.prototxt',
framework='Caffe')
# 从磁盘加载图像
image = cv2.imread('../../input/image_1.jpg')
# 从图像创建blob
blob = cv2.dnn.blobFromImage(image=image, scalefactor=0.01, size=(224, 224),
mean=(104, 117, 123))
# blob输入神经网络
model.setInput(blob)
# 图像blob前向传播
outputs = model.forward()
final_outputs = outputs[0]
# 使所有输出为1D
final_outputs = final_outputs.reshape(1000, 1)
# 获取类标签
label_id = np.argmax(final_outputs)
# 将输出经过softmax转换为概率
probs = np.exp(final_outputs) / np.sum(np.exp(final_outputs))
# 最后得到最高概率
final_prob = np.max(probs) * 100.
# 将最高概率映射到类标签名称
out_name = class_names[label_id]
out_text = f"{out_name}, {final_prob:.3f}"
# 将类名文本放在图像的顶部
cv2.putText(image, out_text, (25, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0),
2)
cv2.imshow('Image', image)
cv2.waitKey(0)
cv2.imwrite('../../outputs/result_image.jpg', image)
(2)C++
#include 7.OpenCV DNN图像分类代码解析
如前所述,我们将使用预先训练过的DenseNet121模型,该模型使用Caffe深度学习框架进行训练。
我们将需要模型权重文件(.caffemodel)和模型配置文件(.prototxt)。
readNet(model[, config[, framework]]) -> retval可以看到,我们正在使用OpenCV DNN模块的一个名为readNet()的函数,它接受三个输入参数。
model:这是预训练权重文件的路径。在我们的例子中,它是预先训练的Caffe模型。config:这是模型配置文件的路径,在本例中是Caffe模型的.prototxt文件。framework:最后,我们需要提供从其中加载模型的框架名称。对我们来说,它是Caffe框架。
该函数自动检测训练模型的框架,并调用适当的函数,如readNetFromCaffe,ref readNetFromTensorflow, readNetFromTorch或readNetFromDarknet。
除了readNet()函数,OpenCV DNN模块还提供了从特定框架加载模型的函数,在这些框架中我们不需要提供框架参数。下面是这些函数。
readNetFromCaffe():它用于加载预先训练的Caffe模型,并接受两个参数。它们是prototxt文件的路径和Caffe模型文件的路径。readNetFromTensorflow():我们可以使用这个函数直接加载TensorFlow预先训练的模型。这也接受两个参数。一个是冻结模型的路径,另一个是模型架构protobuf文本文件的路径。readNetFromTorch():我们可以使用它来加载使用Torch .save()函数保存的Torch和PyTorch模型。我们需要提供模型路径作为参数。readNetFromDarknet():这用于加载使用DarkNet框架训练的模型。我们还需要提供两个参数。一条路径指向模型权重,另一条路径指向模型配置文件。readNetFromONNX():我们可以使用它来加载ONNX模型,我们只需要提供到ONNX模型文件的路径。readNetFromModelOptimizer():从英特尔的模型优化器中间表示(openvino)加载一个网络。网络后端使用英特尔的推理引擎,需要提供xml文件和bin文件。
这篇博文将继续使用readNet()函数来加载预先训练过的模型。我们也将在对象检测部分使用相同的函数。
我们将像往常一样使用OpenCV的imread()函数从磁盘读取图像。注意,我们还需要注意其他一些细节。我们使用OpenCV DNN模块加载的预训练模型并没有直接将读取的图像作为输入。在那之前我们需要做一些预处理。
在读取图像时,我们假设它位于当前目录之前的两个目录中,并且位于输入文件夹中。接下来的几个步骤是必不可少的。我们有一个blobFromImage()函数blobFromImage(image, scalefactor=None, size=None, mean=None, swapRB=None, crop=None, ddepth=None),它将图像以正确的格式输入模型,blobFromImage()函数输出一个NCHW维度顺序的四维矩阵。让我们回顾一下所有的参数,并详细了解它们。
image:这是我们刚刚使用imread()函数读取的输入图像。scalefactor:这个值根据提供的值缩放图像。它的默认值是1,这意味着不执行缩放。size:这是图像将被调整为的大小。我们提供了224×224的大小,这是大多数在ImageNet数据集上训练的分类模型所期望的大小。mean:这一参数非常重要。这些实际上是从图像的RGB颜色通道中减去的平均值。这将输入归一化并使最终输入对不同的照明尺度具有不变性。swapRB:表示在3通道图像中是否交换第一个和最后一个通道。crop:图像在调整大小后是否被裁剪,如果crop为真,调整输入图像大小,调整大小后的一边等于相应的尺寸,另一面等于相应的尺寸或比相应的尺寸更大。然后,从中心进行裁剪。ddepth:输出blob的深度。选择CV_32F或CV_8U。
这里还有一件事要注意。所有的深度学习模型都期望批量输入。然而,我们这里只有一张图片。然而,我们在这里得到的blob输出实际上有一个[1,3,224,224]的形状。观察blobFromImage()函数添加了一个额外的批处理维度。这将是神经网络模型的最终和正确的输入格式。
现在,我们的输入已经准备好了,我们就可以进行预测了。
进行预测有两个步骤。
- 首先,我们必须将输入
blob设置到我们从磁盘加载的神经网络模型里面。 - 第二步是使用
forward()函数在模型中对blob前向传播,这将为我们提供所有输出。
输出是一个包含所有预测的数组。但是在我们能够正确地看到输出和类标签之前,我们需要完成一些预处理步骤。
目前,输出的形状为(1,1000,1,1),很难提取类标签。因此,reshape输出,在此之后,我们可以轻松地获得正确的类标签并将标签ID映射到类名。
在我们reshape输出之后,它有一个形状(1000,1),表示它有1000行用于所有1000个标签,每行保存与类标签相对应的分数。
我们从中提取分数最高的标签索引,并将其存储在label_id中。然而,这些分数实际上不是概率分数。我们需要得到softmax概率,以知道模型预测最高得分标签的概率。
在上面的Python代码中,我们使用 n p . e x p ( f i n a l _ o u t p u t s ) / n p . s u m ( n p . e x p ( f i n a l _ o u t p u t s ) ) np.exp(final\_outputs) / np.sum(np.exp(final\_outputs)) np.exp(final_outputs)/np.sum(np.exp(final_outputs))将分数转换为softmax概率。然后我们将概率最高的分数与100相乘,得到预测分数的百分比。
最后一步是在图像顶部标注类名和百分比。然后我们将图像可视化并将结果保存到磁盘中。
执行代码后,我们将得到以下输出。
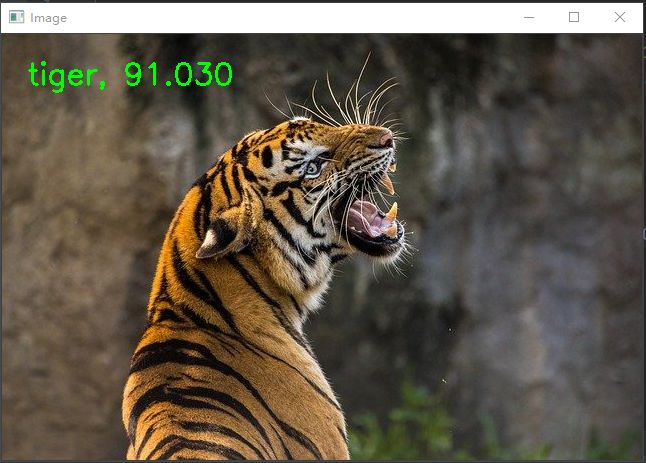
DenseNet121模型正确地预测了老虎的图像,并且有91%的可信度。结果相当好。
在上面的小节中,我们看到了如何使用OpenCV DNN模块使用DenseNet121神经网络模型进行图像分类。我们还详细介绍了每个步骤,以便更好地理解OpenCV DNN模块的工作。
在接下来的章节中,我们将使用OpenCV DNN对图像和视频进行目标检测。
8.使用OpenCV DNN进行对象检测
使用OpenCV DNN模块,我们可以轻松开始深度学习和计算机视觉中的目标检测。像分类一样,我们将加载图像、选择适当的模型并对blob进行前向传播。在目标检测中,适当可视化的预处理步骤将有所不同。在接下来的博文中,我们将逐一了解这些内容。
(1)Python
# 图片检测
import cv2
import numpy as np
# 加载COCO类名
with open('../../input/object_detection_classes_coco.txt', 'r') as f:
class_names = f.read().split('\n')
# 为每个类获取不同的颜色数组
COLORS = np.random.uniform(0, 255, size=(len(class_names), 3))
# 加载DNN模型
model = cv2.dnn.readNet(model='../../input/frozen_inference_graph.pb',
config='../../input/ssd_mobilenet_v2_coco_2018_03_29.pbtxt.txt',
framework='TensorFlow')
# 从磁盘读取图像
image = cv2.imread('../../input/image_2.jpg')
image_height, image_width, _ = image.shape
# 从图像创建blob
blob = cv2.dnn.blobFromImage(image=image, size=(300, 300), mean=(104, 117, 123),
swapRB=True)
# 将blob导入模型中
model.setInput(blob)
# 前向传播模型进行检测
output = model.forward() # (1, 1, 100, 7)
# 循环遍历每个检测结果
for detection in output[0, 0, :, :]:
# 提取检测的置信度
confidence = detection[2]
# 只有当检测置信度高于某个阈值时才绘制边界框,否则跳过
if confidence > .4:
# 获取类id
class_id = detection[1]
# 将类id映射到类
class_name = class_names[int(class_id)-1]
color = COLORS[int(class_id)]
# 获取边界框坐标
box_x = detection[3] * image_width
box_y = detection[4] * image_height
# 获取边框的宽度和高度
box_width = detection[5] * image_width
box_height = detection[6] * image_height
# 在每个检测到的对象周围画一个矩形
cv2.rectangle(image, (int(box_x), int(box_y)), (int(box_width), int(box_height)), color, thickness=2)
# 将FPS文本放在帧的顶部
cv2.putText(image, class_name, (int(box_x), int(box_y - 5)), cv2.FONT_HERSHEY_SIMPLEX, 1, color, 2)
cv2.imshow('image', image)
cv2.imwrite('../../outputs/image_result.jpg', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 视频检测
import cv2
import time
import numpy as np
# 加载COCO类名
with open('../../input/object_detection_classes_coco.txt', 'r') as f:
class_names = f.read().split('\n')
# 为每个类获取不同的颜色数组
COLORS = np.random.uniform(0, 255, size=(len(class_names), 3))
# 加载DNN模型
model = cv2.dnn.readNet(model='../../input/frozen_inference_graph.pb',
config='../../input/ssd_mobilenet_v2_coco_2018_03_29.pbtxt.txt',
framework='TensorFlow')
# 加载视频
cap = cv2.VideoCapture('../../input/video_1.mp4')
# 获取视频帧的宽度和高度,以便适当地保存视频
frame_width = int(cap.get(3))
frame_height = int(cap.get(4))
# 创建 `VideoWriter()` 对象
out = cv2.VideoWriter('../../outputs/video_result.mp4', cv2.VideoWriter_fourcc(*'mp4v'), 30,
(frame_width, frame_height))
# 检测视频的每一帧中的对象
while cap.isOpened():
ret, frame = cap.read()
if ret:
image = frame
image_height, image_width, _ = image.shape
# 从图像创建blob
blob = cv2.dnn.blobFromImage(image=image, size=(300, 300), mean=(104, 117, 123),
swapRB=True)
# 开始时间以计算FPS
start = time.time()
model.setInput(blob)
output = model.forward()
# 检测结束时间
end = time.time()
# 计算当前帧检测的FPS
fps = 1 / (end-start)
# 循环遍历每个检测
for detection in output[0, 0, :, :]:
# 提取检测的置信度
confidence = detection[2]
# 只有当检测置信度高于某个阈值时才绘制边界框,否则跳过
if confidence > .4:
# 获取类id
class_id = detection[1]
# 将类id映射到类
class_name = class_names[int(class_id)-1]
color = COLORS[int(class_id)]
# 获取边界框坐标
box_x = detection[3] * image_width
box_y = detection[4] * image_height
# 获取边框的宽度和高度
box_width = detection[5] * image_width
box_height = detection[6] * image_height
# 在每个检测到的对象周围画一个矩形
cv2.rectangle(image, (int(box_x), int(box_y)), (int(box_width), int(box_height)), color, thickness=2)
# 将类名文本放在检测到的对象上
cv2.putText(image, class_name, (int(box_x), int(box_y - 5)), cv2.FONT_HERSHEY_SIMPLEX, 1, color, 2)
# 将FPS文本放在帧的顶部
cv2.putText(image, f"{fps:.2f} FPS", (20, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow('image', image)
out.write(image)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
else:
break
cap.release()
cv2.destroyAllWindows()
(2)C++
//检测图像
#include //视频检测
#include 9.OpenCV DNN图像检测代码解析
就像分类一样,在这里,我们将利用预先训练的模型。这些模型在MS COCO数据集上进行了训练,MS COCO数据集是当前基于深度学习的目标检测模型的基准数据集。
MS COCO有近80种类别,从人到汽车,再到牙刷。数据集包含80个日常对象的类。我们还将使用一个文本文件来加载MS COCO数据集中的所有标签,以进行对象检测。
对于目标检测,我们将使用下面的图像。

我们将使用MobileNet SSD (Single Shot Detector),它已经使用TensorFlow深度学习框架在MS COCO数据集上训练过。SSD模型通常比其他目标检测模型更快。此外,MobileNet主干网也降低了它们的计算密集型。因此,使用OpenCV DNN开始学习目标检测是一个很好的模型。
在Python代码中,我们首先导入cv2和numpy模块。对于C++,我们需要包含OpenCV和OpenCV DNN库。
接下来,我们读取object_detection_classes_coco.txt文件,其中包含所有用换行分隔符分隔的类名。我们将每个类名存储在class_names列表中。
class_names列表如下所示:['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', … 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush', '']
除此之外,我们还有一个COLORS数组,它包含三个整数值的元组。这些是我们在为每个类绘制边界框时可以应用的随机颜色。最好的部分是,我们将为每个类有一个不同颜色的边界框,这将是相当容易的,我们在最终的结果中区分类。
我们将使用readNet()函数加载MobileNet SSD模型,我们在前面也使用过这个函数。
接下来,我们将从磁盘读取图像并准备输入blob文件。
对于对象检测,我们在blobFromImage()函数中使用了一些不同的参数值。
- 我们将大小指定为
300×300,因为这是SSD模型在几乎所有框架中通常期望的输入大小。对于TensorFlow也是一样的。 - 这次我们还使用了
swapRB参数。OpenCV一般以BGR格式读取图像,而对于目标检测,模型一般希望输入为RGB格式。因此,swapRB参数将交换图像的R和B通道,使其为RGB格式。
然后我们将blob设置到MobileNet SSD模型,并使用forward()函数进行前向传播。
我们的输出结构如下:[[[[0.00000000e+00 1.00000000e+00 9.72869813e-01 2.06566155e-02 1.11088693e-01 2.40461200e-01 7.53399074e-01]]]]
- 在这里,索引位置1包含类标签,它可以从1到80。
- 索引位置2包含置信度得分。这不是一个概率分数,而是模型对它所检测到的类的对象的置信度。
- 在最后四个值中,前两个值是x、y边界框坐标,最后一个值是边界框的宽度和高度。
我们对检测输出结果进行遍历,并在每个检测对象周围绘制边界框。
这是我们使用OpenCV DNN在图像中进行目标检测所需要的所有代码。执行代码会得到以下结果。
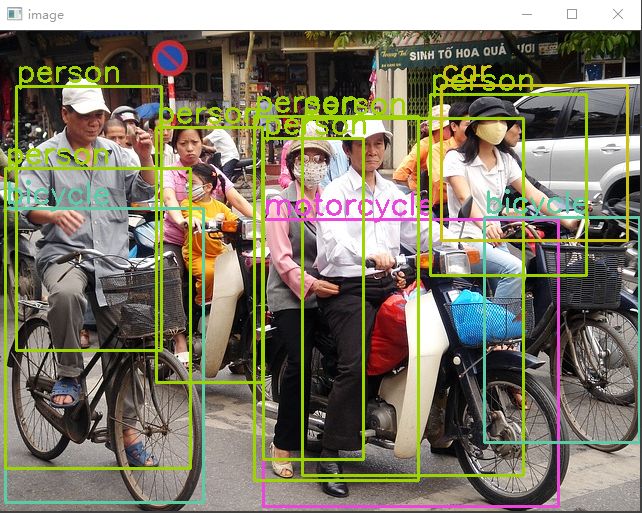
在上面的图像中,我们可以看到结果似乎很好。该模型几乎可以探测到所有可见的物体。然而,也有一些错误的预测。例如,MobileNet SSD模型在左侧多检测出了行人。MobileNet ssd往往会犯这样的错误,因为它们在实时应用程序中会犯这样的错误,并以准确性换取速度。
使用OpenCV DNN进行视频中的目标检测。
10.OpenCV DNN视频检测代码解析
视频中的目标检测代码将与图像的检测代码非常相似。这将有一些变化,因为我们将对视频帧而不是图像进行预测。
我们不是使用图像,而是使用VideoCapture()对象捕获视频。我们还创建了一个VideoWriter()对象,用于正确保存生成的视频帧。
当我们准备好我们的视频和MobileNet SSD模型,下一步是循环遍历每一帧视频,并在每一帧中进行目标检测。通过这种方式,我们将把每一帧都看作是一幅图像。
模型检测每一帧中的对象,直到视频中没有要循环的帧为止。需要注意一些重要的事情:
- 我们将检测前的开始时间存储在
start变量中,检测结束时间存储在end变量中。 - 以上时间变量帮助我们计算
FPS(每秒帧数)。我们计算FPS并将其存储在FPS中。 - 在代码的最后一部分,我们还在当前帧的基础上编写了计算出的
FPS,以了解在使用OpenCV DNN模块运行MobileNet SSD模型时,我们可以期望的速度。 - 最后,我们在屏幕上可视化每一帧,并将它们保存到磁盘上。
我们在Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz CPU上达到了23 FPS左右。考虑到检测的数量,还算不错。该模型可以检测到几乎所有的人,移动的车辆,甚至交通灯。不过,当它试图探测手提包和背包等小物体时,还是有点困难。CPU上的23帧每秒是我们在精度和更小物体检测更少的代价中得到的。
11.在GPU上推理
我们也可以在GPU上运行所有的分类和检测推理。为此,我们需要从源代码编译OpenCV DNN模块。
- 如果是在Ubuntu上,请访问这篇文章来编译带有
GPU的OpenCV。 - 如果在windows上,请访问此链接以使用
GPU编译OpenCV。
为了在GPU上运行推理,我们需要对C++和Python代码做一个简单的更改。
Python:
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
C++:
net.setPreferableBackend(DNN_BACKEND_CUDA);
net.setPreferableTarget(DNN_TARGET_CUDA);
我们应该在从磁盘加载神经网络模型之后添加上述两行代码。第一行代码确保如果DNN模块支持CUDA GPU模型,神经网络将使用CUDA后端。
第二行代码告诉我们,所有的神经网络计算都将在GPU上进行,而不是在CPU上。使用CUDA支持的GPU,目标检测视频推理的帧数要比CPU高。即使使用图像,推断时间也应该比使用CPU的情况低得多。
总结
我们介绍了OpenCV的DNN模块,并讨论了我们选择DNN模块的原因。我们已经看到了比较性能的条形图。我们还研究了OpenCV DNN支持的不同深度学习功能、模型和框架。
我们讨论了使用OpenCV的DNN模块的图像分类和目标检测任务,以获得实际操作经验。我们还看到了使用OpenCV DNN进行视频中的对象检测。
关键词
- 神经网络和深度学习已经达到了计算机能够以高精确度理解和识别物体的阶段。有时,他们甚至在某些用例中超过了人类。
- OpenCV DNN模块
- 是模型推理的首选,特别是在
Intel CPU上。 - 易于安装
- 附带了现成的,准备使用的模型和算法,适合大多数用例。
- 虽然DNN模块不具备训练能力,但仍然对边缘设备有很大的部署支持。
- 是模型推理的首选,特别是在
参考目录
https://learnopencv.com/deep-learning-with-opencvs-dnn-module-a-definitive-guide/