【数据挖掘】贝叶斯网络理论及Python实现
1.理论知识
1.1贝叶斯网络概述
贝叶斯网络(Bayesian Network,BN)作为一种概率图模型(Probabilistic Graphical Model,PGD),可以通过有向无环图(Directed Acyclic Graph,DAG)来表现。因为概率图模型是用图来表示变量概率依赖关系的模型,结合概率论与图论的知识,利用图来表示与模型有关的变量的联合概率分布。在处理实际问题时,如果我们希望在数据中挖掘隐含的知识,可以通过概率图模型构建一幅图的方式实现,具体实现就是用观测结点表示观测到的数据,用隐含结点表示潜在的知识,用边来描述知识与数据的相互关系,最后基于这样的关系图获得一个概率分布。概率图中的节点分为隐含节点和观测节点,边分为有向边和无向边。从概率论的角度,节点对应于随机变量,边对应于随机变量的依赖或相关关系,其中有向边表示单向的依赖或者说存在因果关系,无向边表示相互依赖关系。
贝叶斯网络是一种模拟人类推理过程中因果关系的不确定性处理模型,它是一个有向无环图,它的节点表示的是一些随机变量,这些随机变量有些可以观测到的,有些无法观测到的。无环表示在信息流动的过程中有一个确定的方向的。当一件事物发生的时候,另一件事情更容易发生,这时候就用概率来表达,而且这种概率通常表达的是因果关系。
贝叶斯网络是一种模拟人类推理过程中因果关系的不确定性处理模型,也是一些变量的联合概率分布的图形表示。通常包含两个部分,一个是贝叶斯网络结构图,它是一个有向无环图(DAG),其中图中的每个节点代表相应的变量,节点之间的连接关系代表了贝叶斯网络的条件独立语义。另一部分,就是节点和节点之间的条件概率表(CPT),也就是一系列的概率值。如果一个贝叶斯网络提供了足够的条件概率值,足以计算任何给定的联合概率,我们就称,它是可计算的,即可推理的。
什么是贝叶斯推断?使用贝叶斯方法处理不确定性,需要利用贝叶斯定理将先验分布更新至后验分布中,这无疑是最流行的方法之一。但还存在其他非贝叶斯方法,例如集中不等式就是非贝叶斯方法,它们允许计算置信区间和不确定性集合。
1.2贝叶斯网络实例
首先从一个具体的实例(医疗诊断的例子)来说明贝叶斯网络的构造。
假设:
随机变量S(smoker):该患者是一个吸烟者
随机变量C(coal Miner):该患者是一个煤矿矿井工人
随机变量L(ung Cancer):他患了肺癌
随机变量E(mphysema):他患了肺气肿
变量S对变量L和变量E有因果影响,而变量C对变量E也有因果影响。
变量之间的关系可以描绘成如下图所示的因果关系网。所以贝叶斯网络有时也叫因果关系网,因为可以将连接节点的弧表示直接的因果关系。

根据上述图可知贝叶斯网络的两个要素:一个是贝叶斯网络的结构,即各节点的继承关系,另一是是条件概率表(CPT)。如果要保证一个贝叶斯网络可计算,则这两个条件缺一不可。
如何用贝叶斯网络对该问题进行建模表示
- 如何定义节点?
- 如何定义节点之间的概率依赖关系?
- 如何表示联合概率分布?
1.3贝叶斯网络定义
贝叶斯网络是一个有向无环图(Directed Acyclic Graph, DAG),由代表变量节点及连接这些节点有向边构成。其中节点代表随机变量,节点间的有向边代表了节点间的互相关系(由父节点指向其子节点),用条件概率表达变量间依赖关系,没有父节点的用先验概率进行信息表达。
令 G 为定义在 { X 1 , X 2 , . . . , X n } \{X_{1},X_{2},...,X_{n}\} {X1,X2,...,Xn}上的一个贝叶斯网络,其联合概率分布可以表示为各个 节点的条件概率分布的乘积 :
p ( X ) = ∏ i p i ( X i ∣ Par G ( X i ) ) p(X)=\prod_{i} p_{i}\left(X_{i} \mid \operatorname{Par}_{G}\left(X_{i}\right)\right) p(X)=i∏pi(Xi∣ParG(Xi))
1.4贝叶斯网络结构
贝叶斯网络随机变量的连接方式主要有顺连、分连、汇连这三种连接形式,具体如下:
1.顺连
如图 a a a所示,当 z z z未知时,变量 x x x的变化会影响z的置信度的变化,从而间接影响 y y y的置信度,所以此时x间接影响 y y y, x x x和 y y y不独立。当变量 z z z的置信度确定时, x x x就不能影响 z z z,从而不能影响 y y y,此时 x x x和 y y y独立,因为此时 x x x和 y y y的通道被阻断了。
2.分连
如图 b b b所示,分连代表一个原因导致多个结果,当变量 z z z已知时,变量 x x x和 y y y之间就不能相互影响,是独立的,而当变量 z z z未知时, z z z可以在变量 x x x和 y y y之间传递信息,从而使变量 x x x和 y y y相互影响从而不独立。
3.汇连
汇连与分连恰好相反,代表多个原因导致一个结果,并且当变量z已知时,变量 x x x的置信度的提高会导致变量 y y y的置信度的降低,从而 x x x和y之间会相互影响所以是不独立的。而当 z z z未知时,变量 x x x和 y y y之间置信度互不影响,他们之间是独立的。

有关概念:
1.条件独立性:在贝叶斯网络中,如果两个节点是直接连接的,它们肯定是非条件独立的,是直接因果关系。
2.局部马尔可夫性质:对一个更一般的贝叶斯网络,其局部马尔可夫性质为:每个随机变量在给定父节点的情况下,条件独立于它的非后代节点。
2贝叶斯网络python实现
案例1:诊断癌症贝叶斯网络

提供如下数据信息:
美国有30%的人吸烟.
每10万人中就就有70人患有肺癌.
每10万人中就就有10人患有肺结核.
每10万人中就就有800人患有支气管炎.
10%人存在呼吸困难症状, 大部分人是哮喘、支气管炎和其他非肺结核、非肺癌性疾病引起.
代码实现如下:
基于python的pgmpy库构建贝叶斯网络,其步骤是先建立网络结构, 然后填入相关参数。
1.针对已知结构及参数,先采用BayesianModel构造贝叶斯网结构
#构建网络
from pgmpy.models import BayesianModel
cancer_model = BayesianModel([('Pollution', 'Cancer'),
('Smoker', 'Cancer'),
('Cancer', 'Xray'),
('Cancer', 'Dyspnoea')])
这个贝叶斯网络中有五个节点: Pollution, Cancer, Smoker, Xray, Dyspnoea.
- (‘Pollution’, ‘Cancer’): 一条有向边, 从 Pollution 指向 Cancer, 表示环境污染有可能导致癌症.
- (‘Smoker’, ‘Cancer’): 吸烟有可能导致癌症.
- (‘Cancer’, ‘Xray’): 得癌症的人可能会去照X射线.
- (‘Cancer’, ‘Dyspnoea’): 得癌症的人可能会呼吸困难.
2.通过TabularCPD构造条件概率分布CPD(condition probability distribution)表格,最后将CPD数据添加到贝叶斯网络结构中,完成贝叶斯网络的构造。
#设置参数
from pgmpy.factors.discrete import TabularCPD
cpd_poll = TabularCPD(variable='Pollution', variable_card=2,
values=[[0.9], [0.1]])
cpd_smoke = TabularCPD(variable='Smoker', variable_card=2,
values=[[0.3], [0.7]])
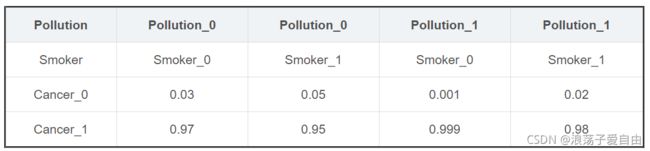
cpd_cancer = TabularCPD(variable='Cancer', variable_card=2,
values=[[0.03, 0.05, 0.001, 0.02],
[0.97, 0.95, 0.999, 0.98]],
evidence=['Smoker', 'Pollution'],
evidence_card=[2, 2])
cpd_xray = TabularCPD(variable='Xray', variable_card=2,
values=[[0.9, 0.2], [0.1, 0.8]],
evidence=['Cancer'], evidence_card=[2])
cpd_dysp = TabularCPD(variable='Dyspnoea', variable_card=2,
values=[[0.65, 0.3], [0.35, 0.7]],
evidence=['Cancer'], evidence_card=[2])
cancer_model.add_cpds(cpd_poll, cpd_smoke, cpd_cancer, cpd_xray, cpd_dysp)
这部分代码主要是建立一些概率表, 然后往表里面填入了一些参数.
- Pollution: 有两种概率, 分别是 0.9 和 0.1.
- Smoker: 有两种概率, 分别是 0.3 和 0.7. (意思是在一个人群里, 有 30% 的人吸烟, 有 70% 的人不吸烟)
- Cancer: envidence 表示有 Smoker 和 Pollution 两个节点指向 Cancer 节点;
3.验证模型数据的正确性
#测试网络结构是否正确
print(cancer_model.check_model())
4.在构建了贝叶斯网之后, 我们使用贝叶斯网来进行推理. 推理算法分精确推理和近似推理. 精确推理有变量消元法和团树传播法; 近似推理算法是基于随机抽样的算法.
#变量消除法是精确推断的一种方法.
from pgmpy.inference import VariableElimination
asia_infer = VariableElimination(cancer_model)
q = asia_infer.query(variables=['Cancer'], evidence={'Smoker': 0})
print(q)
结果:

案例2:学生成绩贝叶斯网络

贝叶斯网络变量说明:

实现代码
from pgmpy.models import BayesianModel
from pgmpy.factors.discrete import TabularCPD
# 通过边来定义贝叶斯网络结构
stu_model = BayesianModel([('D', 'G'), ('I', 'G'), ('G', 'L'), ('I', 'S')])
# 定义条件概率分布
cpd_d = TabularCPD(variable='D', variable_card=2, values=[[0.6], [0.4]])
cpd_i = TabularCPD(variable='I', variable_card=2, values=[[0.7],[0.3]])
# variable:变量
# variable_card:基数
# values:变量值
# evidence:
cpd_g = TabularCPD(variable='G', variable_card=3,
values=[[0.3, 0.05, 0.9, 0.5],
[0.4, 0.25, 0.08, 0.3],
[0.3, 0.7, 0.02, 0.2]],
evidence=['I', 'D'],
evidence_card=[2, 2])
cpd_l = TabularCPD(variable='L', variable_card=2,
values=[[0.1, 0.4, 0.99],
[0.9, 0.6, 0.01]],
evidence=['G'],
evidence_card=[3])
cpd_s = TabularCPD(variable='S', variable_card=2,
values=[[0.95, 0.2],
[0.05, 0.8]],
evidence=['I'],
evidence_card=[2])
# 将有向无环图与条件概率分布表关联
stu_model.add_cpds(cpd_d, cpd_i, cpd_g, cpd_l, cpd_s)
# 验证模型:检查网络结构和CPD,并验证CPD是否正确定义和总和为1
print(stu_model.check_model())
使用极大似然估计:
import numpy as np
import pandas as pd
from pgmpy.models import BayesianModel
from pgmpy.estimators import MaximumLikelihoodEstimator, BayesianEstimator
raw_data = np.random.randint(low=0, high=2, size=(1000, 5))
data = pd.DataFrame(raw_data, columns=['D', 'I', 'G', 'L', 'S'])
model = BayesianModel([('D', 'G'), ('I', 'G'), ('I', 'S'), ('G', 'L')])
model.fit(data, estimator=MaximumLikelihoodEstimator)
for cpd in model.get_cpds():
print("CPD of {variable}:".format(variable=cpd.variable))
print(cpd)
【注意】
- 安装pgmpy的python环境必须要是python3.7.X版本,X必须大于等于1.
- 安装pgmpy必须安装以下模块
networkX
scipy
numpy
pytorch
tqdm
pandas
pyparsing
statsmodels
joblib