PyTorch之MLP
一 、关于Graphviz 的问题
首先手动下载对应的包并安装,添加环境变量,如果仍然不行,考虑如下方法
graphviz.backend.execute.ExecutableNotFound: failed to execute WindowsPath(‘dot’), make sure the Graphviz executables are on your systems’ PATH
解决方案
在代码文件中导入路径
import os
os.environ["PATH"] += os.pathsep + 'D:/IProgramming/python/Iintsall/Graphviz/bin'
二、运行出现警告信息
UserWarning: This figure includes Axes that are not compatible with tight_layout, so results might be incorrect.
self.figure.tight_layout()
解决方案
File > Settings > Tools > Python Scientific > show plots in tool window 取消勾选的show plots in tool window 点击Apply再点击OK
也就是将绘画的图不显示在pycharm的小窗口,直接外部显示
示例代码,实现邮件的垃圾分类
import numpy as np
import pandas as pd
import seaborn as sns
# read data and show the first lines
import torch
import torch.nn as nn
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler,MinMaxScaler
import matplotlib.pyplot as plt
from torchviz import make_dot
import os
os.environ["PATH"] += os.pathsep + 'D:/IProgramming/python/Iintsall/Graphviz/bin'
spam = pd.read_csv("./data/spambase.csv")
'''显示基本数据显示'''
# spam.head()
# pd.value_counts(spam.label)
''' 训练集和测试集划分'''
X= spam.iloc[:,0:57].values
y = spam.label.values
X_train,X_test,y_trains,y_test = train_test_split(X,y,test_size=0.25,random_state=123)
scales = MinMaxScaler(feature_range= (0,1))
X_train_s = scales.fit_transform(X_train)
X_test_s = scales.transform(X_test)
'''绘画箱线图'''
# plt.figure(figsize = (20,14))
# colname = spam.columns.values[:-1]
# for ii in range(len(colname)):
# plt.subplot(7,9,ii+1)
# sns.boxplot(x = y_trains,y = X_train_s[:,ii])
# plt.title(colname[ii])
# plt.subplots_adjust(hspace= 0.4)
# plt.show()
'''搭建网络'''
class MLPclassifica(nn.Module):
def __init__(self):
super(MLPclassifica, self).__init__()
self.hidden1 = nn.Sequential(
nn.Linear(
in_features=57,
out_features=30,
bias= True
),
nn.ReLU()
)
self.hidden2 = nn.Sequential(
nn.Linear(30,10),
nn.ReLU()
)
self.classifica = nn.Sequential(
nn.Linear(10,2),
nn.Sigmoid()
)
def forward(self,x):
fc1 = self.hidden1(x)
fc2 = self.hidden2(fc1)
output = self.classifica(fc2)
return fc1,fc2,output
'''网络可视化'''
mplc = MLPclassifica()
x = torch.randn(1,57).requires_grad_(True)
y = mplc(x)
Mymplcvis = make_dot(y,params=dict(list(mplc.named_parameters())+[('x',x)]))
Mymplcvis
Mymplcvis.view('model_structure.pdf',"./data") #第一个参数是文件名 第二个是保存路径
Out[9]: ‘data\model_structure.pdf.pdf’
三,邮件分类之一
未初始化数据的训练结果如下:
代码:
import numpy as np
import pandas as pd
import seaborn as sns
# read data and show the first lines
import torch
import torch.nn as nn
import hiddenlayer as hl
from sklearn.metrics import accuracy_score,confusion_matrix,classification_report
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler
import torch.utils.data as Data
import matplotlib.pyplot as plt
from torchviz import make_dot
from sklearn.manifold import TSNE
import os
os.environ["PATH"] += os.pathsep + 'D:/IProgramming/python/Iintsall/Graphviz/bin'
spam = pd.read_csv("./data/spambase.csv")
'''显示基本数据显示'''
# spam.head()
# pd.value_counts(spam.label)
''' 训练集和测试集划分'''
X = spam.iloc[:, 0:57].values
y = spam.label.values
X_train, X_test, y_trains, y_test = train_test_split(X, y, test_size=0.25, random_state=123)
# 数据归一化
scales = MinMaxScaler(feature_range=(0, 1))
X_train_s = scales.fit_transform(X_train)
X_test_s = scales.transform(X_test)
'''绘画箱线图'''
# plt.figure(figsize = (20,14))
# colname = spam.columns.values[:-1]
# for ii in range(len(colname)):
# plt.subplot(7,9,ii+1)
# sns.boxplot(x = y_trains,y = X_train_s[:,ii])
# plt.title(colname[ii])
# plt.subplots_adjust(hspace= 0.4)
# plt.show()
'''搭建网络'''
class MLPclassifica(nn.Module):
def __init__(self):
super(MLPclassifica, self).__init__()
self.hidden1 = nn.Sequential(
nn.Linear(
in_features=57,
out_features=30,
bias=True
),
nn.ReLU()
)
self.hidden2 = nn.Sequential(
nn.Linear(30, 10),
nn.ReLU()
)
self.classifica = nn.Sequential(
nn.Linear(10, 2),
nn.Sigmoid()
)
def forward(self, x):
fc1 = self.hidden1(x)
fc2 = self.hidden2(fc1)
output = self.classifica(fc2)
return fc1, fc2, output
# '''网络可视化'''
mlpc = MLPclassifica()
# x = torch.randn(1,57).requires_grad_(True)
# y = mlpc(x)
# Mymlpcvis = make_dot(y,params=dict(list(mlpc.named_parameters())+[('x',x)]))
# Mymlpcvis
# 使用未归一化的数据进行训练
X_train_nots = torch.from_numpy(X_train.astype(np.float32))
y_train_t = torch.from_numpy(y_trains.astype(np.int64))
X_test_nots = torch.from_numpy(X_test.astype(np.float32))
y_test_t = torch.from_numpy(y_test.astype(np.int64))
train_data_nots = Data.TensorDataset(X_train_nots,y_train_t)
train_data_loader = Data.DataLoader(
dataset=train_data_nots,
batch_size=64,
shuffle=True,
# RuntimeError: DataLoader worker (pid(s) 8704) exited unexpectedly
# 上述错误,必须使用单线程
num_workers=0
)
'''定义优化器'''
optimizer = torch.optim.Adam(mlpc.parameters(),lr = 0.01)
loss_func = nn.CrossEntropyLoss()
history1 = hl.History()
canvas1 = hl.Canvas()
print_step = 25
for epoch in range(15):
for step,(b_x,b_y) in enumerate(train_data_loader):
_,_,output = mlpc(b_x)
train_loss = loss_func(output,b_y)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
niter = epoch*len(train_data_loader)+step+1
if niter%print_step == 0:
_,_,output = mlpc(X_test_nots)
_,pre_lab = torch.max(output,1)
test_accuracy = accuracy_score(y_test_t,pre_lab)
history1.log(niter,train_loss = train_loss,test_accuracy = test_accuracy)
with canvas1:
canvas1.draw_plot(history1['train_loss'])
canvas1.draw_plot(history1['test_accuracy'])
输出结果如下:
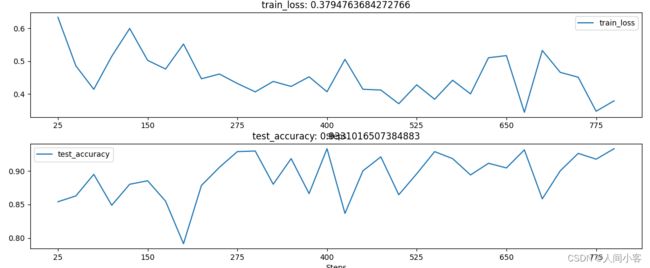
结果分析:
准确率88%,损失函数一直在波动,MLP数据并未收敛
分析原因如下:
- 数据没有标准化处理
- 训练的数据样本过少
- 网络的神经元太少,或者太多
四、邮件分类正确分类之二
对其进行归一化处理
归一后代码如下:
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import hiddenlayer as hl
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import torch.utils.data as Data
import os
os.environ["PATH"] += os.pathsep + 'D:/IProgramming/python/Iintsall/Graphviz/bin'
spam = pd.read_csv("./data/spambase.csv")
''' 训练集和测试集划分 1:3'''
X = spam.iloc[:, 0:57].values
y = spam.label.values
X_train, X_test, y_trains, y_test = train_test_split(X, y, test_size=0.25, random_state=123)
# 数据归一化
scales = MinMaxScaler(feature_range=(0, 1))
X_train_s = scales.fit_transform(X_train)
X_test_s = scales.transform(X_test)
'''搭建网络'''
class MLPclassifica(nn.Module):
def __init__(self):
super(MLPclassifica, self).__init__()
self.hidden1 = nn.Sequential(
nn.Linear(
in_features=57,
out_features=30,
bias=True
),
nn.ReLU()
)
self.hidden2 = nn.Sequential(
nn.Linear(30, 10),
nn.ReLU()
)
self.classifica = nn.Sequential(
nn.Linear(10, 2),
nn.Sigmoid()
)
def forward(self, x):
fc1 = self.hidden1(x)
fc2 = self.hidden2(fc1)
output = self.classifica(fc2)
return fc1, fc2, output
mlpc = MLPclassifica()
# 使用未归一化的数据进行训练
X_train_t = torch.from_numpy(X_train_s.astype(np.float32))
y_train_t = torch.from_numpy(y_trains.astype(np.int64))
X_test_t = torch.from_numpy(X_test_s.astype(np.float32))
y_test_t = torch.from_numpy(y_test.astype(np.int64))
train_data_nots = Data.TensorDataset(X_train_t,y_train_t)
train_data_loader = Data.DataLoader(
dataset=train_data_nots,
batch_size=64,
shuffle=True,
# RuntimeError: DataLoader worker (pid(s) 8704) exited unexpectedly
# 上述错误,必须使用单线程
num_workers=0
)
'''定义优化器'''
optimizer = torch.optim.Adam(mlpc.parameters(),lr = 0.01)
loss_func = nn.CrossEntropyLoss()
history1 = hl.History()
canvas1 = hl.Canvas()
print_step = 25
for epoch in range(15):
for step,(b_x,b_y) in enumerate(train_data_loader):
_,_,output = mlpc(b_x)
train_loss = loss_func(output,b_y)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
niter = epoch*len(train_data_loader)+step+1
if niter%print_step == 0:
_,_,output = mlpc(X_test_t)
_,pre_lab = torch.max(output,1)
test_accuracy = accuracy_score(y_test_t,pre_lab)
history1.log(niter,train_loss = train_loss,test_accuracy = test_accuracy)
with canvas1:
canvas1.draw_plot(history1['train_loss'])
canvas1.draw_plot(history1['test_accuracy'])
# 在测试集合上进行测试
_,_,output = mlpc(X_test_t)
_,pre_lab = torch.max(output,1)
test_accuracy = accuracy_score(y_test_t,pre_lab)
print("test_accuracy :",test_accuracy)
结果如下图所示
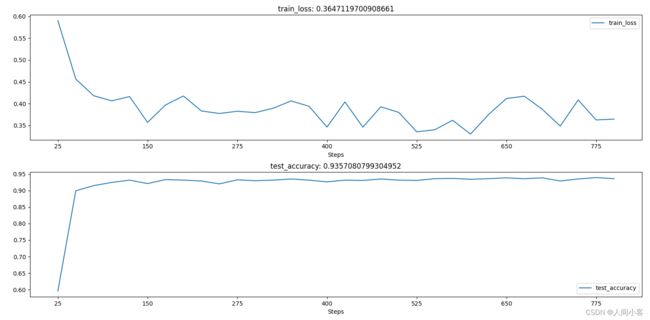
结果分析,可以看到准确率达到93%,损失函数也在不断下降。
对训练的模型进行预测,结果如下,认为94.52%
Backend TkAgg is interactive backend. Turning interactive mode on.
test_accuracy : 0.945264986967854
五、获取中间层的可视化工作
''中间层输出可视化'''
_, test_fc2, _ = mlpc(X_test_t)
# print('test_fc2.shape:', test_fc2.shape)
# 对输出进行降维并可视化
# test_fc2_tsne = TSNE(n_components = 2).fit_transform(test_fc2.data.numpy())
# # 特征可视化
# plt.figure(figsize=(8, 6))
# # 可视化前设置坐标系的取值范围
# plt.xlim([min(test_fc2_tsne[:, 0] - 1), max(test_fc2_tsne[:, 0] + 1)])
# plt.ylim([min(test_fc2_tsne[:, 1] - 1), max(test_fc2_tsne[:, 1] + 1)])
# plt.plot(test_fc2_tsne[y_test == 0, 0], test_fc2_tsne[y_test == 0, 1],
# 'bo', label = '0')
# plt.plot(test_fc2_tsne[y_test == 1, 0], test_fc2_tsne[y_test == 1, 1],
# 'rd', label = '1')
# plt.legend()
# plt.title('test_fc2_tsne')
# plt.show()
对应结果如下
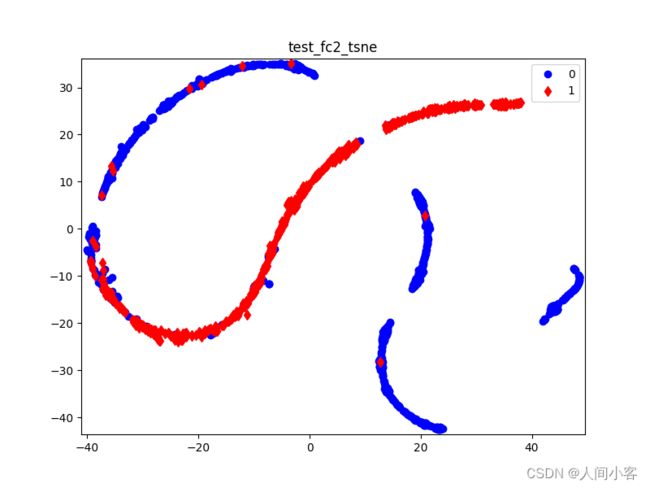
结果分析
略
使用hook输出的
'''使用钩子获取信息'''
# 定义一个辅助函数,获取指定层名称的特征
activation = {} # 保存不同层的输出
def get_activaion(name):
def hook(model, input, output):
activation[name] = output.detach()
return hook
# 获取分类层输出
mlpc.classifica.register_forward_hook(get_activaion('classify'))
_, _, _ = mlpc(X_test_t)
classifica = activation['classify'].data.numpy()
print('classification.shape:', classifica.shape)
# 特征可视化
plt.figure(figsize=(8, 6))
plt.plot(classifica[y_test == 0, 0], classifica[y_test == 0, 1],
'bo', label = '0')
plt.plot(classifica[y_test == 1, 0], classifica[y_test == 1, 1],
'rd', label = '1')
plt.legend()
plt.title('classification')
plt.show()
结果如下:
classification.shape: (1151, 2)
对应的输出图
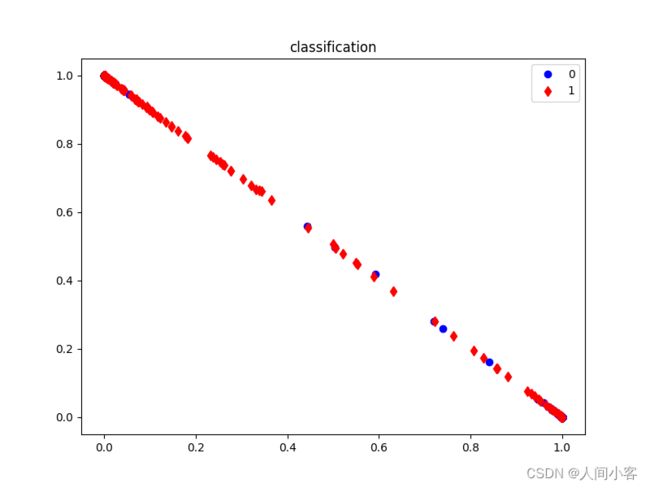
分析如下:
六、参数调整:
lr学习率
迭代次数
bachsize的设定,epoch的设定等参数的理解何调参数对结果的影响