【超详细】初学者包会的Vision Transformer(ViT)的PyTorch实现代码学习
本文是博主跟着b站up霹雳吧啦Wz的视频稿件学习的自我记录,图片均为该视频截图。
代码来源timm库(PyTorchImageModels,简称timm)是一个巨大的PyTorch代码集合,已经被官方使用了。
放一些链接:up霹雳吧啦Wz针对ViT写的博客,论文原文链接,timm库作者的GitHub主页,timm库链接,timm库的官方指南,以及一个非官方的timm库的推荐文章。
模型示意图(Base16为例)

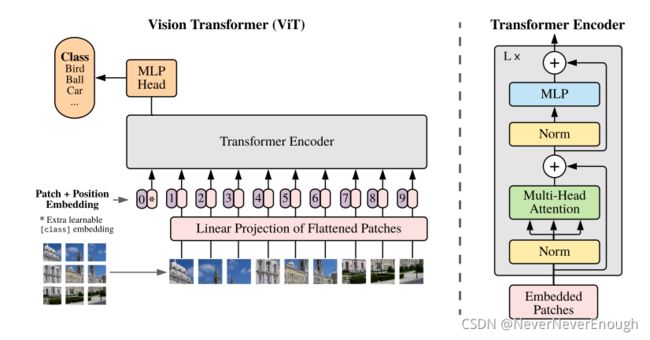
图片来自视频截图和论文截图
PatchEmbed模块
class PatchEmbed(nn.Module):
""" 2D Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, norm_layer=None, flatten=True):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1]) #grid_size=224÷16=14
self.num_patches = self.grid_size[0] * self.grid_size[1]
#num_patches=14*14
self.flatten = flatten
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
#proj使用卷积,embed_dimension这一参数在vision transformer的base16模型用到的是768,所以默认是768。但是如果是large或者huge模型的话embed_dim也会变。
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
#norm_layer默认是None,就是进行nn.Identity()也就是不做任何操作;如果有传入(非None),则会进行初始化一个norm_layer。
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
#assert:进行判断,如果代码模型定义和实际输入尺寸不同则会报错
x = self.proj(x) #用卷积实现序列化
if self.flatten:
x = x.flatten(2).transpose(1, 2) # BCHW -> BNC
#flatten(2)操作实现了[B,C,H,W,]->[B,C,HW],指从维度2开始进行展平
#transpose(1,2)操作实现了[B,C,HW]->[B,HW,C]
x = self.norm(x)
#通过norm层输出
return x
Attention模块
该模块实现多头注意力机制。
class Attention(nn.Module):
def __init__(self,
dim, #输入token的dim
num_heads=8, #多头注意力中head的个数
qkv_bias=False, #在生成qkv时是否使用偏置,默认否
attn_drop=0.,
proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads #计算每一个head需要传入的dim
self.scale = head_dim ** -0.5 #head_dim的-0.5次方,即1/根号d_k,即理论公式里的分母根号d_k
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) #qkv是通过1个全连接层参数为dim和3dim进行初始化的,也可以使用3个全连接层参数为dim和dim进行初始化,二者没有区别,
self.attn_drop = nn.Dropout(attn_drop)#定义dp层 比率attn_drop
self.proj = nn.Linear(dim, dim) #再定义一个全连接层,是 将每一个head的结果进行拼接的时候乘的那个矩阵W^O
self.proj_drop = nn.Dropout(proj_drop)#定义dp层 比率proj_drop
def forward(self, x):#正向传播过程
#输入是[batch_size,
# num_patches+1, (base16模型的这个数是14*14)
# total_embed_dim(base16模型的这个数是768)]
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
#qkv->[batchsize, num_patches+1, 3*total_embed_dim]
#reshape->[batchsize, num_patches+1, 3, num_heads, embed_dim_per_head]
#permute->[3, batchsize, num_heads, num_patches+1, embed_dim_per_head]
q, k, v = qkv[0], qkv[1], qkv[2]
# make torchscript happy (cannot use tensor as tuple)
#q、k、v大小均[batchsize, num_heads, num_patches+1, embed_dim_per_head]
attn = (q @ k.transpose(-2, -1)) * self.scale
#现在的操作都是对每个head进行操作
#transpose是转置最后2个维度,@就是矩阵乘法的意思
#q [batchsize, num_heads, num_patches+1, embed_dim_per_head]
#k^T[batchsize, num_heads, embed_dim_per_head, num_patches+1]
#q*k^T=[batchsize, num_heads, num_patches+1, num_patches+1]
#self.scale=head_dim的-0.5次方
#至此完成了(Q*K^T)/根号d_k的操作
attn = attn.softmax(dim=-1)
#dim=-1表示在得到的结果的每一行上进行softmax处理,-1就是最后1个维度
#至此完成了softmax[(Q*K^T)/根号d_k]的操作
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
#@->[batchsize, num_heads, num_patches+1, embed_dim_per_head]
#这一步矩阵乘积就是加权求和
#transpose->[batchsize, num_patches+1, num_heads, embed_dim_per_head]
#reshape->[batchsize, num_patches+1, num_heads*embed_dim_per_head]即[batchsize, num_patches+1, total_embed_dim]
#reshape实际上就实现了concat拼接
x = self.proj(x)
#将上一步concat的结果通过1个线性映射,通常叫做W,此处用全连接层实现
x = self.proj_drop(x)
#dropout
#至此完成了softmax[(Q*K^T)/根号d_k]*V的操作
#一个head的attention的全部操作就实现了
return x
MLP Block(图中的名字)/FeedForward类(代码中的实现)
class FeedForward(nn.Module):
#全连接层1+GELU+dropout+全连接层2+dropout
#全连接层1的输出节点个数是输入节点个数的4倍,即mlp_ratio=4.
#全连接层2的输入节点个数是输出节点个数的1/4
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
Encoder Block主模块
实现了对EncoderBlock重复堆叠L次的时候的每一次的结构,如下:
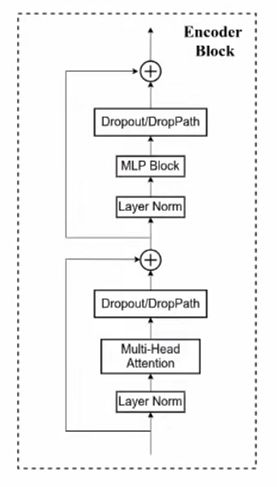
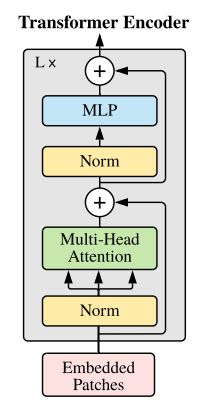
左图为视频截图,右图为原论文截图
class Block(nn.Module):
def __init__(self,
dim,
num_heads,
mlp_ratio=4.,
qkv_bias=False,
drop=0.,
#多头注意力模块中的最后的全连接层之后的dropout层对应的drop比率
attn_drop=0.,
#多头注意力模块中softmax[Q*K^T/根号d_k]之后的dropout层的drop比率
drop_path=0.,
#本代码用到的是DropPath方法(上面右图的DropPath),所以上面右图的两个droppath层有这个比率
act_layer=nn.GELU,
norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
#第一层LN
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)
#第一个多头注意力
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
#如果传入的drop_path大于0,就会实例化一个droppath方法;如果传入的drop_path等于0,则执行Identity()不做任何操作
self.norm2 = norm_layer(dim)
#第二个LN层
mlp_hidden_dim = int(dim * mlp_ratio)
#mlp层的隐层个数是输入的4倍,实例化一个MLP模块的时候需要传入mlp_hidden_dim这个参数,所以在此提前计算
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
#act_layer是激活函数
def forward(self, x):
#前向传播过程:
#第一部分:LN+Mul-Head-Attention+ Dropout之后,加上第一个LN之前的输入
#第二部分:LN+MLP+Dropout之后,加上第二个LN之前的输入
#输出x
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
VisionTransformer类
也就是文章里的模型主体了
class VisionTransformer(nn.Module):
def __init__(self, img_size=224,
patch_size=16,
in_chans=3,
num_classes=1000,
embed_dim=768,
depth=12,
num_heads=12,
mlp_ratio=4.,
qkv_bias=True,
representation_size=None,
#representation_size是最后的MLP Head中的pre-logits中的全连接层的节点个数,默认为None,此时就不会去构建这个pre-logits,也就是此时在MLP Head中只有一个全连接层,而没有pre-logits层。【pre-logits层是什么:就是全连接层+激活函数】
distilled=False,
#distilled后续的DeiT才用到这个参数
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.,
embed_layer=PatchEmbed,
#这个参数是nn.Module类型,即模块PatchEmbed
norm_layer=None,
#这个参数也是nn.Module类型
act_layer=None,
weight_init=''):
super().__init__()
self.num_classes = num_classes #复制参数
self.num_features = self.embed_dim = embed_dim #复制参数
# num_features for consistency with other models
self.num_tokens = 2 if distilled else 1
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
act_layer = act_layer or nn.GELU
#因为ViT模型的distilled=False,所以前面这三句:
#num_tokens=1
#norm_layer=partial(nn.LayerNorm, eps=1e-6)
#act_layer= nn.GELU
self.patch_embed = embed_layer(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim) #对图片进行patch和embed
num_patches = self.patch_embed.num_patches #得到patches的个数
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
#加上class_token,零矩阵初始化,尺寸1*1*embed_dim.
#第一个1是batchsize维度,是为了后面进行拼接所以设置成1。
#第二、三个维度就是1*768
self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else None #这一行可以直接忽略,本文(ViT)模型用不到dist_token
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))
#position embedding,使用零矩阵初始化
#尺寸为1 *(num_patches + self.num_tokens)* embed_dim
#第一个维度1是batchsize维度
#第二个维度:num_tokens=1(见本段代码第29行),num_patches在base16模型中是14*14=196,加一起就是197
#第三个维度:embed_dim
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)]
#根据传入的drop_path_rate参数(默认为0),for i in的语句使得每一层的drop_path层的drop比率是递增的,但是默认为0,则不创建。
# stochastic depth decay rule(随机深度衰减规则)
#下面利用for i in range(depth),即根据模型深度depth(默认=12)堆叠Block
self.blocks = nn.Sequential(*[
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, act_layer=act_layer)
for i in range(depth)])
self.norm = norm_layer(embed_dim)
#不用管下面这一段因为本模型中representation_size=None
#前面提过这个参数的作用(本段代码第12行)
# Representation layer
if representation_size and not distilled:
self.num_features = representation_size
self.pre_logits = nn.Sequential(OrderedDict([
('fc', nn.Linear(embed_dim, representation_size)),
('act', nn.Tanh())
]))#其实就是全连接层+tanh激活函数
else:
self.pre_logits = nn.Identity()
#下面就是最终用于分类的全连接层的实现了
# Classifier head(s)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()#输入向量长度为num_features(定义在本段代码第26行,这个参数值=embed_dim),输出的向量长度为num_classes类别数
#下面的部分和ViT无关可以不看
self.head_dist = None
if distilled:
self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity()
self.init_weights(weight_init)
def forward_features(self, x):
x = self.patch_embed(x)#这个模块第一部分讲了
cls_token = self.cls_token.expand(x.shape[0], -1, -1) #本段第40行附近有解释,原cls_token尺寸1*1*embed_dim,将其在BatchSize维度复制B份,现cls_token尺寸为B*1*embed_dim
if self.dist_token is None:#本模型中这个值就是None
x = torch.cat((cls_token, x), dim=1)
#在维度1上进行拼接,即值为196的维度上拼接。本行之后->[B,14*14+1,embed_dim]
else:#本模型不执行这句
x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)
x = self.pos_drop(x + self.pos_embed)#加上position embedding再通过51行定义的dropout层
x = self.blocks(x)#通过58行定义的transformer encoder堆叠模块
x = self.norm(x)#通过norm
if self.dist_token is None:#本模型该参数为None
return self.pre_logits(x[:, 0])
#x[:, 0]将class_token通过切片取出,因为拼接的时候放在了最前面
#而前面提过pre_logits层在参数representation_size=None的时候返回nn.Identity()即无操作,所以本句输出就是x[:, 0]
else:
return x[:, 0], x[:, 1]
def forward(self, x):
#前向部分
x = self.forward_features(x)#
if self.head_dist is not None:
#本模型head_dist=None(81行)所以不执行此分支 不用看
x, x_dist = self.head(x[0]), self.head_dist(x[1]) # x must be a tuple
if self.training and not torch.jit.is_scripting():
# during inference, return the average of both classifier predictions
return x, x_dist
else:
return (x + x_dist) / 2
else:
x = self.head(x)#直接来到这,head是79行定义的分类头
return x
模型定义
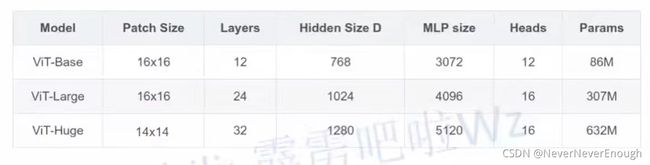
图片来自视频截图
Layers对应代码中的depth
Hidden Size D对应代码中的embed_dim
@register_model
def vit_base_patch16_224(pretrained=False, **kwargs):
""" ViT-Base (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-1k weights fine-tuned from in21k @ 224x224, source https://github.com/google-research/vision_transformer.
"""
model_kwargs = dict(patch_size=16, embed_dim=768, depth=12, num_heads=12, **kwargs)
model = _create_vision_transformer('vit_base_patch16_224', pretrained=pretrained, **model_kwargs)
return model
@register_model
def vit_tiny_patch16_224_in21k(pretrained=False, **kwargs):
#本模型不含(pre-logits) layer
""" ViT-Tiny (Vit-Ti/16).
ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.
NOTE: this model has valid 21k classifier head and no representation (pre-logits) layer
"""
model_kwargs = dict(patch_size=16, embed_dim=192, depth=12, num_heads=3, **kwargs)
model = _create_vision_transformer('vit_tiny_patch16_224_in21k', pretrained=pretrained, **model_kwargs)
return model
@register_model
def vit_huge_patch14_224_in21k(pretrained=False, **kwargs):
#本模型包含pre-logits layer,并使self.num_features = representation_size
""" ViT-Huge model (ViT-H/14) from original paper (https://arxiv.org/abs/2010.11929).
ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.
NOTE: this model has a representation layer but the 21k classifier head is zero'd out in original weights
"""
model_kwargs = dict(
patch_size=14, embed_dim=1280, depth=32, num_heads=16, representation_size=1280, **kwargs)
model = _create_vision_transformer('vit_huge_patch14_224_in21k', pretrained=pretrained, **model_kwargs)
return model
注:Huge模型的预训练权重就1G多,不建议使用;基本从base就行。
要训练哪个模型就下载对应的预训练权重,对于ViT来说预训练十分重要,需要进行迁移学习。
调用
用下面这句就可以调用timm库里的ViT模型啦(记得先在环境里用pip install timm装好环境哈)
from timm.models.vision_transformer import vit_base_patch16_224_in21k as create_model
#从timm库导入模型vit_base_patch16_224_in21k
model = create_model(num_classes=5, has_logits=False).to(device)
# num_classes设置成你所使用的分类数据集的类别数,has_logits就是有没有前面说的pre-logits层,自己选择
train.py
import os
import math
import argparse
import torch
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from my_dataset import MyDataSet
from timm.models.vision_transformer import vit_base_patch16_224_in21k as create_model
from utils import read_split_data, train_one_epoch, evaluate
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
if os.path.exists("./weights") is False:
os.makedirs("./weights")
tb_writer = SummaryWriter()
train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])}
# 实例化训练数据集
train_dataset = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
# 实例化验证数据集
val_dataset = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
batch_size = args.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=nw,
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=val_dataset.collate_fn)
model = create_model(num_classes=5, has_logits=False).to(device)
if args.weights != "":
assert os.path.exists(args.weights), "weights file: '{}' not exist.".format(args.weights)
weights_dict = torch.load(args.weights, map_location=device)
# 删除不需要的权重
del_keys = ['head.weight', 'head.bias'] if model.has_logits \
else ['pre_logits.fc.weight', 'pre_logits.fc.bias', 'head.weight', 'head.bias']
for k in del_keys:
del weights_dict[k]
print(model.load_state_dict(weights_dict, strict=False))
if args.freeze_layers:
for name, para in model.named_parameters():
# 除head, pre_logits外,其他权重全部冻结 只训练MLP模块
if "head" not in name and "pre_logits" not in name:
para.requires_grad_(False)
else:
print("training {}".format(name))
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=5E-5) #传入需要进行SGD的参数组成的dict
# Scheduler https://arxiv.org/pdf/1812.01187.pdf
lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosine learning rate decay
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # cosine learning rate decay
for epoch in range(args.epochs):
# train 返回 平均loss 和 预测正确的样本÷样本总数
train_loss, train_acc = train_one_epoch(model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch)
# validate
val_loss, val_acc = evaluate(model=model,
data_loader=val_loader,
device=device,
epoch=epoch)
scheduler.step()
# 以上循环内三部分写法源于LambdaLR()的torch官方实例
tags = ["train_loss", "train_acc", "val_loss", "val_acc", "learning_rate"]
tb_writer.add_scalar(tags[0], train_loss, epoch)
tb_writer.add_scalar(tags[1], train_acc, epoch)
tb_writer.add_scalar(tags[2], val_loss, epoch)
tb_writer.add_scalar(tags[3], val_acc, epoch)
tb_writer.add_scalar(tags[4], optimizer.param_groups[0]["lr"], epoch)
torch.save(model.state_dict(), "./weights/model-{}.pth".format(epoch))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=5)
parser.add_argument('--epochs', type=int, default=10)
parser.add_argument('--batch-size', type=int, default=8)
parser.add_argument('--lr', type=float, default=0.001)
parser.add_argument('--lrf', type=float, default=0.01)
# 数据集所在根目录
# http://download.tensorflow.org/example_images/flower_photos.tgz
parser.add_argument('--data-path', type=str,
default="/data/xxxx")
parser.add_argument('--model-name', default='', help='create model name')
# 预训练权重路径,如果不想载入就设置为空字符,这里同时进行了重命名
parser.add_argument('--weights', type=str, default='./vit_base_patch16_224_in21k.pth',
help='initial weights path')
# 是否冻结权重
parser.add_argument('--freeze-layers', type=bool, default=True)
parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')
opt = parser.parse_args()
main(opt)
utils.py
import os
import sys
import json
import pickle
import random
import torch
from tqdm import tqdm
import matplotlib.pyplot as plt
def read_split_data(root: str, val_rate: float = 0.2):
random.seed(0) # 保证随机结果可复现
assert os.path.exists(root), "dataset root: {} does not exist.".format(root)
# 遍历文件夹,一个文件夹对应一个类别
flower_class = [cla for cla in os.listdir(root) if os.path.isdir(os.path.join(root, cla))]
# 排序,保证顺序一致
flower_class.sort()
# 生成类别名称以及对应的数字索引
class_indices = dict((k, v) for v, k in enumerate(flower_class))
json_str = json.dumps(dict((val, key) for key, val in class_indices.items()), indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
train_images_path = [] # 存储训练集的所有图片路径
train_images_label = [] # 存储训练集图片对应索引信息
val_images_path = [] # 存储验证集的所有图片路径
val_images_label = [] # 存储验证集图片对应索引信息
every_class_num = [] # 存储每个类别的样本总数
supported = [".jpg", ".JPG", ".png", ".PNG"] # 支持的文件后缀类型
# 遍历每个文件夹下的文件
for cla in flower_class:
cla_path = os.path.join(root, cla)
# 遍历获取supported支持的所有文件路径
images = [os.path.join(root, cla, i) for i in os.listdir(cla_path)
if os.path.splitext(i)[-1] in supported]
# 获取该类别对应的索引
image_class = class_indices[cla]
# 记录该类别的样本数量
every_class_num.append(len(images))
# 按比例随机采样验证样本
val_path = random.sample(images, k=int(len(images) * val_rate))
for img_path in images:
if img_path in val_path: # 如果该路径在采样的验证集样本中则存入验证集
val_images_path.append(img_path)
val_images_label.append(image_class)
else: # 否则存入训练集
train_images_path.append(img_path)
train_images_label.append(image_class)
print("{} images were found in the dataset.".format(sum(every_class_num)))
print("{} images for training.".format(len(train_images_path)))
print("{} images for validation.".format(len(val_images_path)))
plot_image = False
if plot_image:
# 绘制每种类别个数柱状图
plt.bar(range(len(flower_class)), every_class_num, align='center')
# 将横坐标0,1,2,3,4替换为相应的类别名称
plt.xticks(range(len(flower_class)), flower_class)
# 在柱状图上添加数值标签
for i, v in enumerate(every_class_num):
plt.text(x=i, y=v + 5, s=str(v), ha='center')
# 设置x坐标
plt.xlabel('image class')
# 设置y坐标
plt.ylabel('number of images')
# 设置柱状图的标题
plt.title('flower class distribution')
plt.show()
return train_images_path, train_images_label, val_images_path, val_images_label
def plot_data_loader_image(data_loader):
batch_size = data_loader.batch_size
plot_num = min(batch_size, 4)
json_path = './class_indices.json'
assert os.path.exists(json_path), json_path + " does not exist."
json_file = open(json_path, 'r')
class_indices = json.load(json_file)
for data in data_loader:
images, labels = data
for i in range(plot_num):
# [C, H, W] -> [H, W, C]
img = images[i].numpy().transpose(1, 2, 0)
# 反Normalize操作
img = (img * [0.229, 0.224, 0.225] + [0.485, 0.456, 0.406]) * 255
label = labels[i].item()
plt.subplot(1, plot_num, i+1)
plt.xlabel(class_indices[str(label)])
plt.xticks([]) # 去掉x轴的刻度
plt.yticks([]) # 去掉y轴的刻度
plt.imshow(img.astype('uint8'))
plt.show()
def write_pickle(list_info: list, file_name: str):
with open(file_name, 'wb') as f:
pickle.dump(list_info, f)
def read_pickle(file_name: str) -> list:
with open(file_name, 'rb') as f:
info_list = pickle.load(f)
return info_list
def train_one_epoch(model, optimizer, data_loader, device, epoch):
model.train()
loss_function = torch.nn.CrossEntropyLoss()
accu_loss = torch.zeros(1).to(device) # 用于累计损失
accu_num = torch.zeros(1).to(device) # 用于累计预测正确的样本数
optimizer.zero_grad()
sample_num = 0
data_loader = tqdm(data_loader)
for step, data in enumerate(data_loader): # step对应索引 data对应所传入的dataloader参数中的每个元素
images, labels = data
sample_num += images.shape[0] # batchsize维度的值求和,即样本数量
#前向
pred = model(images.to(device)) # 预测结果
pred_classes = torch.max(pred, dim=1)[1]
# 在dim=1维度找到预测值最大的值,即为预测类;
# torch.max()得到{max, max_indices},使用torch[1]取出该张量的dim=1维度的向量,即max_indices向量(size=batchsize*类别数),为预测最大值对应的类别索引
accu_num += torch.eq(pred_classes, labels.to(device)).sum()
# 判断max_indices与label(label是batchsize*类别数的向量)是否相等,相等返回True;并累计预测正确的样本数
loss = loss_function(pred, labels.to(device)) # loss函数的输入参数是[pre,label]
loss.backward()
accu_loss += loss.detach()
data_loader.desc = "[train epoch {}] loss: {:.3f}, acc: {:.3f}".format(epoch,
accu_loss.item() / (step + 1),
accu_num.item() / sample_num)
if not torch.isfinite(loss): # loss = inf or -inf or nan 的时候结束训练
print('WARNING: non-finite loss, ending training ', loss)
sys.exit(1)
optimizer.step()
optimizer.zero_grad()
return accu_loss.item() / (step + 1), accu_num.item() / sample_num
@torch.no_grad()
# @torch.no_grad()中的数据不需要计算梯度,也不会进行反向传播
def evaluate(model, data_loader, device, epoch):
loss_function = torch.nn.CrossEntropyLoss()
model.eval()
accu_num = torch.zeros(1).to(device) # 累计预测正确的样本数
accu_loss = torch.zeros(1).to(device) # 累计损失
sample_num = 0
data_loader = tqdm(data_loader)
for step, data in enumerate(data_loader):
images, labels = data
sample_num += images.shape[0]
pred = model(images.to(device))
pred_classes = torch.max(pred, dim=1)[1]
accu_num += torch.eq(pred_classes, labels.to(device)).sum()
loss = loss_function(pred, labels.to(device))
accu_loss += loss
data_loader.desc = "[valid epoch {}] loss: {:.3f}, acc: {:.3f}".format(epoch,
accu_loss.item() / (step + 1),
accu_num.item() / sample_num)
return accu_loss.item() / (step + 1), accu_num.item() / sample_num