【研究生工作周报】(GAN最新论文调研)
GAN系列最新论文调研
文章目录
- GAN系列最新论文调研
- 前言
- 一、EditGAN:High-Precision Semantic Image Editing
- 二、TransductGAN: a Transductive Adversarial Model for Novelty Detection
- 三、Driving Anomaly Detection Using Conditional Generative Adversarial Network
- 四、SphericGAN: Semi-supervised Hyper-spherical Generative Adversarial Networks for Fine-grained Image Synthesis
- 五、WarpingGAN: Warping Multiple Uniform Priors for Adversarial 3D Point Cloud Generation
- 六、SemanticStyleGAN: Learning Compositional Generative Priors for Controllable Image Synthesis and Editing
- 七、Closed-Form Factorization of Latent Semantics in GANs
- 八、HumanGAN: A Generative Model of Human Images
- 九、Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation
- 十、PD-GAN: Probabilistic Diverse GAN for Image Inpainting
- 总结
-
- 1. 图像生成
- 2. 图像转换(翻译)
- 3. 图像合成
-
- 场景合成
- 人脸合成
- 文本到图像的合成
- 4. 图像超分辨率
- 5. 图像域的转换
- 6. 图像修复
前言
本次主要探究GAN应用层面的最新进展 ,包括但不限于风格迁移,图像翻译,特征解耦,语言概念解耦等。
一、EditGAN:High-Precision Semantic Image Editing
NeurIPS 2021 · 基于GAN的高精度语义图像编辑
生成对抗网络(GANs)最近在图像编辑中得到了应用。 然而,大多数基于GAN的图像编辑方法往往需要大规模的带语义分割注释的数据集进行训练,只能提供高层控制,或者仅仅在不同图像之间进行插值。
本文提出了一种新的高质量、高精度的语义图像编辑方法EditGAN,它允许用户通过修改其高度细节的部分分割掩模来编辑图像,例如为汽车前灯绘制一个新的掩模。 EditGAN建立在一个GAN框架上,该框架可以联合建模图像及其语义分割[1,2],只需要少量的标记示例–使其成为一个可伸缩的编辑工具。 具体来说,我们将图像嵌入到GAN的潜在空间中,并根据分割编辑进行条件潜在代码优化,从而有效地修改图像。 为了延缓优化,我们在潜在空间中寻找“编辑向量”来实现编辑。 该框架允许我们学习任意数量的编辑向量,然后这些向量可以以交互速率直接应用于其他图像。 实验表明,EditGAN能够以前所未有的细节和自由度处理图像,同时保持完整的图像质量。我们还可以轻松地组合多个编辑,并在EditGAN的训练数据之外执行似是而非的编辑。

项目地址传送门
二、TransductGAN: a Transductive Adversarial Model for Novelty Detection
CVPR 2022一种用于新颖性检测的转导对抗模型
新颖性检测是机器学习中一个被广泛研究的问题,它是检测以前没有观察到的一类新数据的问题。 新颖性检测的一个常见设置是归纳的,由此在训练时间内只有否定类的示例可用。 而转导新颖性检测只是最近才出现的,它不仅在训练过程中利用否定类,而且还结合了(未标记的)测试集来检测新颖性样本。 在转导设置伞下出现了几项研究,证明了它比感应设置伞有优势。 根据对数据的假设,这些方法有不同的名称(例如,转导新颖性检测,半监督新颖性检测,正-未标记学习,非分布检测)。 随着生成对抗网络(GAN)的使用,这些研究中的一部分采用了一种换能器设置,以学习如何生成新类的示例。 在本研究中,我们提出了一个转换生成对抗网络TransductGAN,它试图通过在潜在空间中使用两个高斯的混合来学习如何从新类和负类中生成图像示例。 通过将对抗性自动编码器与GAN网络相结合,生成新颖数据点示例的能力不仅提供了新颖的可视化表示,而且克服了许多归纳方法所面临的如何调整模型超对等的障碍。
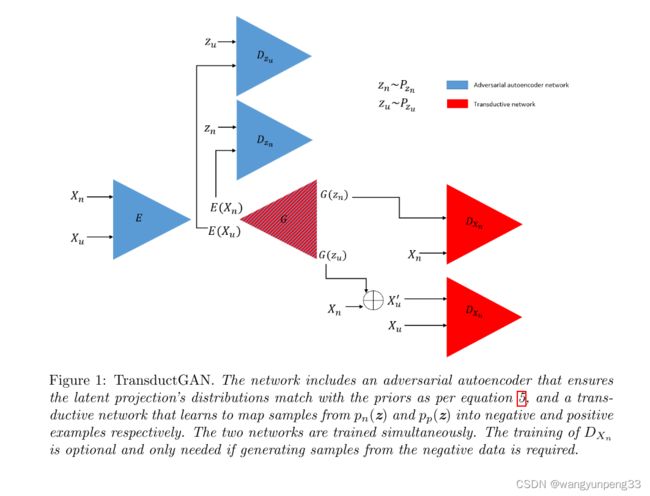
三、Driving Anomaly Detection Using Conditional Generative Adversarial Network
CVPR-2022 用CGAN做驾驶异常检测
异常驾驶检测是高级驾驶辅助系统(ADAS)中的一个重要问题。 尽早识别潜在的危险情景以避免潜在的事故是很重要的。 本研究提出一种无监督的方法来量化驾驶异常使用条件生成对抗网络(GAN)。 该方法通过对先前观察到的信号进行调整来预测即将到来的驾驶场景。 该系统使用来自鉴别器的输出在预测信号和实际信号之间的差值作为度量来量化驱动段的异常程度。 我们采用以驾驶员为中心的方法,考虑来自驾驶员的生理信号和来自车辆的控制器局域网总线(CANBUS)信号。 该方法采用卷积神经网络(CNNs)提取鉴别特征表示,并用长短时记忆(LSTM)单元捕捉时间信息。 该研究是通过驾驶异常数据集(DAD)来实现和评估的,该数据集包括250小时人工标注驾驶事件的自然主义记录。 实验结果表明,标注有可能异常事件的记录,如避免路上行人、违反交通规则等,比未标注事件的记录具有更高的异常分数。 结果通过感知评估来验证,其中注释者被要求评估异常得分高的视频的风险和熟悉度。 结果表明,异常得分较高的驾驶段比其他驾驶段更有风险,在道路上更不常见,验证了所提出的无监督方法。 索引项驱动异常检测,条件生成对抗网络,卷积神经网络,长短时记忆细胞。

四、SphericGAN: Semi-supervised Hyper-spherical Generative Adversarial Networks for Fine-grained Image Synthesis
CVPR-2022 用于精细图像合成的半监督超球生成对抗网络SphericGAN
基于生成对抗网络(GAN)的模型极大地促进了图像合成。 然而,由于训练样本有限和类别之间的细微差别,当应用于细粒度数据时,模型的性能可能会下降。 与一般的GANS不同,我们从一个新的角度来解决这个问题,即发现和利用真实数据的底层结构来显式地规则化潜在空间的空间组织。
- 为了减少生成模型对标记数据的依赖,我们提出了一种用于类条件细粒度图像生成的半监督超球形GAN,我们的模型称为SphericGAN。 通过将从先验分布中提取的随机向量投影到超球面上,我们可以对更复杂的分布进行建模,同时得到的潜在向量之间的相似性只依赖于角度,而不依赖于它们的大小。 另一方面,我们还引入映射网络将真实图像映射到超球面上,并通过真假聚类对齐将潜在向量与真实数据的底层结构进行匹配。 因此,我们得到了一个空间组织的潜在空间,这对于捕捉类无关的变化因子是有用的。 实验结果表明,我们的SphericGAN在合成具有精确类语义的高保真图像方面达到了最先进的性能。

五、WarpingGAN: Warping Multiple Uniform Priors for Adversarial 3D Point Cloud Generation
CVPR-2022 三维点云生成网络
我们提出了一个有效的三维点云生成网络WarpingGAN。 与现有的通过直接学习潜在代码和三维形状之间的映射函数生成点云的方法不同,WarpingGan学习了一个统一的局部翘曲函数,将多个相同的预定义先验信息(即均匀分布在规则三维网格上的点集)翘曲成由局部结构感知语义驱动的三维形状。 另外,我们还巧妙地利用了鉴别器的原理,通过裁剪一个拼接损失来消除对应于不同先验信息的生成形状的不同分区之间的间隙,以提高质量。 WarpingGAN是一个经过一次训练的轻量级网络,由于其新颖的生成机制,能够高效地生成均匀分布的各种分辨率的三维点云。

六、SemanticStyleGAN: Learning Compositional Generative Priors for Controllable Image Synthesis and Editing
CVPR-2022 SemanticStyleGAN:面向可控图像合成和编辑的合成生成先验学习
与属性cgan相比,本文所提出模型不是为任何特定任务设计的,可以像StyleGAN一样作为通用先验。因此,它可以与为StyleGAN设计的潜操作方法相结合,以编辑输出图像,同时提供更精确的局部控制。本文工作的贡献可以总结如下:
-
一个组合式生成器架构,将潜在空间分解为不同的语义区域,以控制局部部分的结构和纹理。
-
一个GAN训练框架,用于学习图像和语义分割掩码的联合建模。
-
实验表明,所提出的生成器可以与现有的潜在操纵方法相结合进行编辑,以一种更可控的方式显示图像。
-
实验表明,所提出生成器可以适应于只有有限图像的其他领域,同时保留空间解缠。
七、Closed-Form Factorization of Latent Semantics in GANs
CVPR-2021 GANS中潜在语义的闭式分解
在这项工作中,我们提出了一种新的算法来发现由GANS学习的潜在语义方向,该算法不依赖于任何类型的训练或采样。 我们称它为语义分解的简称SEFA。 SEFA不依赖于合成样本作为中间步骤,而是深入研究GANS的产生机制,研究图像变化与内部表征之间的关系。 事实上,GANS一步一步(或者说一层一层)地将潜在代码投射到照片真实感图像上,其中每一步都学习从一个空间到另一个空间的投影。 许多解释因素源于这一过程。 因此,我们研究直接作用于我们想要研究的潜在空间的第一个投影步骤。 我们提出了一种封闭形式的方法,它只需使用生成器的预训练权值就可以从潜在空间中识别出多种语义。 更重要的是,这些变化因素,由SEFA在不受监督的情况下发现,是准确的,在一个更大的范围内,与最先进的监督方法。 我们使用在图中发现的语义演示了一些有趣的操作结果 1. 例如,我们可以旋转图像中的对象,而不知道其底层的3D模型或姿势标签。 大量的实验表明,我们的方法是有效的,并适用于大多数流行的GAN模型(如PGGAN[16]、StyleGAN[17]、BigGAN[4]和StyleGAN2[18])。

八、HumanGAN: A Generative Model of Human Images
CVPR-2021 人类图像的生成模型
本文提出了HumanGAN,即一个新的服装人体全身图像生成模型,该模型能够控制人体姿态,并能独立地控制和采样人体部分的外观和服装风格。 我们的方法在条件变分自动编码器的框架中结合了两个世界的优点,即基于潜在空间的GANS和可控翻译网络[17]。 我们将隐变量的真实后验概率从一个独立的外观空间中进行编码,并利用编码后的隐向量用一个高保真生成器重建出一幅真实感的人体图像。 为了从局部图像中分离出一个姿态,我们提出了一种新的策略,在进行重建之前,我们对身体部位的潜在向量进行调整,并将它们扭曲到不同的姿态。 这允许在持续的外观和服装风格下进行姿势控制,并在局部的身体部位水平上进行外观采样,而不影响姿势,参见图 1.
概括地说,我们的贡献如下:
- Humangan,即一个新的用于人类图像生成的通用模型,可以进行全局外观采样、姿态转换、部件和服装转换以及部件采样。 第一次,单个方法可以支持所有这些任务(第3节)。
- 一种新颖的基于部分的编码策略,并在一个不同的框架中对特定的部分进行空间扭曲,从而将身体各部分的姿势和外观分离开来。

九、Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation
CVPR-2021 一种用于图像翻译的StyleGan编码器
我们提出了一个通用的图像到图像的翻译框架,Pixel2Style2Pixel(PSP)。 我们的PSP框架是基于一个新的编码器网络,它直接产生一系列风格向量,这些向量被输入到一个预先训练的风格angenerator,形成扩展W+潜在空间。 我们首先展示了我们的编码器可以直接将真实图像嵌入到W+中,无需额外的优化。 接下来,我们提出利用我们的编码器直接解决图像到图像的翻译任务,将它们定义为从某个输入域到潜在域的编码问题。 与以前Stylegan编码器使用的标准“先反转,后编辑”方法不同,即使输入图像不在Stylegan域中表示,我们的方法也可以处理各种任务。
本文的主要贡献是:
- 一种新颖的Stylegan编码器,能够将真实图像直接编码到W+潜在域;
- 一种利用预先训练的样式生成器来解决图像到图像翻译任务的新方法。

十、PD-GAN: Probabilistic Diverse GAN for Image Inpainting
CVPR-2021 用于图像修复的概率多样性GAN
我们提出了PD-GAN,一种用于图像修复的概率多样性GAN。 给定一个具有任意孔洞区域的输入图像,PD-GAN可以产生多个具有不同视觉真实感内容的修复结果。 我们的PD-GaN是建立在一个香草GaN上,它根据随机噪声生成图像。 在图像生成过程中,我们通过在多个尺度上注入初始恢复的图像和空洞区域,对输入随机噪声的深度特征进行从粗到细的调制。我们认为,在孔洞填充过程中,孔洞边界附近的像素应该具有更高的确定性(即更高的概率信任背景和初始恢复图像来创建自然的修复边界),而位于孔洞中心的像素应该享有更多的自由度(即更有可能去除了关于增强分集的随机噪声)。 为此,我们在调制中提出了空间概率分集归一化(spdnorm)模型,根据上下文信息对像素的生成概率进行建模。 SPDNorm动态地平衡了孔洞区域内部的真实感和多样性,使得生成的内容朝着孔洞中心方向更加多样化,朝着孔洞边界方向更像邻近图像内容。 同时,我们提出了一个感知分集损失来进一步增强PD-GAN的多样性内容生成能力。 在Celeba-HQ、Places2和Paris Street View等基准数据集上的实验表明,PD-GAN能够有效地恢复图像的多样性和逼真性。
我们的贡献如下:
- 基于一个Vanilla GaN,提出的PD-GaN通过提出的SPDNorm调制随机噪声向量的深度特征,以引入上下文约束。
- 我们提出了一个感知分集损失来增强网络的分集能力。
- 在基准数据集上进行的实验表明,我们的PD-GAN能够有效地为图像修复生成多样化和视觉逼真的内容。
总结
简单对GAN的应用领域归下类:
1. 图像生成
GAN作为一个生成模型,可以用来生成图像、音频等等,生成质量逐年增加,看下图:
ProGAN算是开了高清图像生成的先河,后续的StyleGAN,StyleGANv2也是基于ProGAN实现对生成的高清图像样式控制。
2. 图像转换(翻译)
所谓图像翻译,指从一副图像到另一副图像的转换。可以类比机器翻译,一种语言转换为另一种语言。下图就是一些典型的图像翻译任务:比如语义分割图转换为真实街景图,灰色图转换为彩色图,白天转换为黑夜…
比较典型的有监督图像翻译模型pix2pix (后续版本pix2pixHD,vid2vid)

另一类就是无监督的图像翻译模型CycleGAN,实现了Domain transfer任务。

3. 图像合成
图像合成这个任务是通过 某种形式的图像描述 \color{red}{某种形式的图像描述} 某种形式的图像描述 创建新图像的过程。pix2pix和cycleGAN 都属于图像合成领域的一部分。
图像合成又可以细分出以下子领域
场景合成
如何给定部分显示场景的信息还原出真实的场景信息,比如根据分割图像还原出原始场景信息,刚好是图像分割的逆过程,只要GAN还原的场景足够真实,完全可以模拟无人驾驶的路况场景,从而在实验室阶段就可以完成无人驾驶汽车的上路测试工作,但是面对的问题就是如何生成高分辨率的和足够真实的图像,(pix2pixHD)

人脸合成
人脸合成主要是根据一张人脸的图像,合成出不同角度的人脸图像,可以用做人脸对齐,姿态转换等辅助手段提高人脸识别的精度,例如比较典型的TP-GAN,可以根据半边人脸生成整张人脸的前向图,对人脸识别任务有很大的辅助效果。

文本到图像的合成
这个算是NLP和CV的交叉点了,任务描述为:从给定的一段文字描述,生成一张和图像文字匹配的图像。比如:根据文字:一只黑色冠冕和黄色喙的白色的鸟,生成下面的这张图像:

4. 图像超分辨率
图像超分辨率的英文名称是 Image Super Resolution。图像超分辨率是指由一幅低分辨率图像或图像序列恢复出高分辨率图像。图像超分辨率技术分为超分辨率复原和超分辨率重建。
图像超分辨率研究可分为 3个主要范畴: 基于插值、 基于重建和基于学习的方法.
典型的SRGAN(ESRGAN),以及StyleGAN
5. 图像域的转换
GAN很适合学习数据的分布(只要是数据是连续的,对于离散的文本数据效果不是很好),同时也能完成domain转换的任务,比如使用GAN完成domain的迁移,此部分有比较典型的工作,CVPR的oral论文StarGAN是其中一个。pix2pix和CycleGAN解决的是一对一的Domain Adaption。StarGAN是在多个domain之间进行转换的方法。可以做多个图像翻译任务,比如更换头发颜色,表情变化,年龄变换等等。

6. 图像修复
修复指的是恢复图像损失的部分并且基于背景信息将它们重建的技术。它指的是在视觉输入的指定区域中填充缺失数据的过程。在数字世界中,它指的是应用复杂算法以替代图像数据中缺失或者损坏部分。
在数字效果图像复原,图像编码和传输的应用中,图像修复已经被广泛地研究。
Generative Image Inpainting with Contextual Attention是其中一个。
