【机器学习基础】概率分布之高斯分布
本系列为《模式识别与机器学习》的读书笔记。
一,多元高斯分布
考虑⾼斯分布的⼏何形式,⾼斯对于 x \boldsymbol{x} x 的依赖是通过下⾯形式的⼆次型:
Δ 2 = ( x − μ ) T Σ − 1 ( x − μ ) (2.30) \Delta^{2} = (\boldsymbol{x} - \boldsymbol{\mu})^{T} \boldsymbol{\Sigma}^{-1}(\boldsymbol{x} - \boldsymbol{\mu})\tag{2.30} Δ2=(x−μ)TΣ−1(x−μ)(2.30)
其中, Δ \Delta Δ 被叫做 μ \boldsymbol{\mu} μ 和 x \boldsymbol{x} x 之间的马⽒距离(Mahalanobis distance)。 当 Σ \boldsymbol{\Sigma} Σ 是单位矩阵时,就变成了欧式距离。对于 x \boldsymbol{x} x 空间中这个⼆次型是常数的曲⾯,⾼斯分布也是常数。
现在考虑协⽅差矩阵的特征向量⽅程:
Σ μ i = λ i μ i (2.31) \boldsymbol{\Sigma} \boldsymbol{\mu}_i = \lambda_{i} \boldsymbol{\mu}_{i}\tag{2.31} Σμi=λiμi(2.31)
其中 i = 1 , … , D i = 1,\dots , D i=1,…,D。由于 Σ \boldsymbol{\Sigma} Σ 是实对称矩阵,因此它的特征值也是实数,并且特征向量可以被选成单位正交的,即:
μ i T μ j = I i j (2.32) \boldsymbol{\mu}_{i}^{T} \boldsymbol{\mu}_{j} = I_{ij}\tag{2.32} μiTμj=Iij(2.32)
其中 I i j I_{ij} Iij 是单位矩阵的第 i , j i, j i,j 个元素,满⾜:
I i j = { 1 , 如 果 i = j 0 , 其 他 情 况 (2.33) I_{i j}=\left\{\begin{array}{l}{1,如果 i=j} \\ {0,其他情况}\end{array}\right. \tag{2.33} Iij={1,如果i=j0,其他情况(2.33)
协⽅差矩阵 Σ \boldsymbol{\Sigma} Σ 可以表⽰成特征向量的展开的形式:
Σ = ∑ i = 1 D λ i μ i μ i T (2.34) \boldsymbol{\Sigma} = \sum_{i=1}^{D} \lambda_i \boldsymbol{\mu}_{i}\boldsymbol{\mu}_{i}^{T}\tag{2.34} Σ=i=1∑DλiμiμiT(2.34)
协⽅差矩阵的逆矩阵 Σ − 1 \boldsymbol{\Sigma}^{-1} Σ−1 可以表⽰成特征向量的展开的形式:
Σ − 1 = ∑ i = 1 D 1 λ i μ i μ i T (2.35) \boldsymbol{\Sigma}^{-1} = \sum_{i=1}^{D} \frac{1}{\lambda_i} \boldsymbol{\mu}_{i}\boldsymbol{\mu}_{i}^{T}\tag{2.35} Σ−1=i=1∑Dλi1μiμiT(2.35)
⼆次型公式(2.30)即可表示为:
Δ 2 = ∑ i = 1 D y i 2 λ i (2.36) \Delta^{2} = \sum_{i=1}^{D} \frac{y_{i}^{2}}{\lambda_{i}}\tag{2.36} Δ2=i=1∑Dλiyi2(2.36)
其中, y i 2 = u i T ( x − μ ) y_{i}^{2} = \boldsymbol{u_i^T} (\boldsymbol{x} - \boldsymbol{\mu}) yi2=uiT(x−μ) 。
把 { y i } \{y_i\} {yi} 表⽰成单位正交向量 μ i \boldsymbol{\mu_i} μi 关于原始的 x i x_i xi 坐标经过平移和旋转后形成的新的坐标系。定义向量 y = ( y 1 , … , y D ) T \boldsymbol{y} = (y_1,\dots, y_D)^T y=(y1,…,yD)T ,即有:
y = U ( x − μ ) (2.37) \boldsymbol {y} = \boldsymbol{U} (\boldsymbol{x} - \boldsymbol{\mu})\tag{2.37} y=U(x−μ)(2.37)
其中 U \boldsymbol{U} U 是⼀个矩阵,它的⾏是向量 u i T \boldsymbol{u}_{i}^{T} uiT 。从公式(2.32)可以看出 U \boldsymbol{U} U 是⼀个正交矩阵, 即它满⾜性质 U U T = I \boldsymbol{U}\boldsymbol{U}^T = \boldsymbol{I} UUT=I ,因此也满⾜ U T U = I \boldsymbol{U}^T \boldsymbol{U} = \boldsymbol{I} UTU=I ,其中 I \boldsymbol{I} I 是单位矩阵。
⼀个特征值严格⼤于零的矩阵被称为正定(positive definite)矩阵。偶尔遇到⼀个或者多个特征值为零的⾼斯分布,那种情况下分布是奇异的,被限制在 了⼀个低维的⼦空间中。如果所有的特征值都是⾮负的,那么这个矩阵被称为半正定(positive semidefine)矩阵。
如图2.12,红⾊曲线表⽰⼆维空间 x = ( x 1 , x 2 ) \boldsymbol{x} = (x_1 , x_2) x=(x1,x2) 的⾼斯分布的常数概率密度的椭圆⾯, 它表⽰的概率密度为 exp ( − 1 2 ) \exp(−\frac{1}{2}) exp(−21),值是在 x = μ \boldsymbol{x} = \boldsymbol{\mu} x=μ 处计算的。椭圆的轴由协⽅差矩阵的特征向量 μ i \mu_i μi 定义,对应的特征值为 λ i \lambda_i λi 。

现在考虑在由 y i y_i yi 定义的新坐标系下⾼斯分布的形式。 从 x \boldsymbol{x} x 坐标系到 y \boldsymbol{y} y 坐标系, 我们有⼀ 个 Jacobian矩阵 J \boldsymbol{J} J ,它的元素为:
J i j = ∂ x i ∂ j j = U i j (2.38) \boldsymbol{J}_{ij} = \frac{\partial {x_i}}{\partial {j_j}} = U_{ij}\tag{2.38} Jij=∂jj∂xi=Uij(2.38)
其中 U j i U_{ji} Uji 是矩阵 U T \boldsymbol{U}^T UT 的元素。使⽤矩阵 U \boldsymbol{U} U 的单位正交性质,我们看到 Jacobian矩阵 ⾏列式的平⽅为:
∣ J 2 ∣ = ∣ U T ∣ 2 = ∣ U T ∣ ∣ U ∣ = ∣ U T U ∣ = ∣ I ∣ = 1 (2.39) | \boldsymbol{J}^{2} | = |\boldsymbol{U}^{T}|^{2} = |\boldsymbol{U}^{T}||\boldsymbol{U}| = |\boldsymbol{U}^{T}\boldsymbol{U}| = |\boldsymbol{I}| = 1\tag{2.39} ∣J2∣=∣UT∣2=∣UT∣∣U∣=∣UTU∣=∣I∣=1(2.39)
从而可知, ∣ J ∣ = 1 |\boldsymbol{J}|=1 ∣J∣=1 ,并且,⾏列式 ∣ Σ ∣ |\boldsymbol{\Sigma}| ∣Σ∣ 的协⽅差矩阵可以写成特征值的乘积,因此:
∣ Σ ∣ 1 2 = ∏ j = 1 D λ j 1 2 (2.40) |\boldsymbol{\Sigma}|^{\frac{1}{2}} = \prod_{j=1}^{D} \lambda_{j}^{\frac{1}{2}}\tag{2.40} ∣Σ∣21=j=1∏Dλj21(2.40)
因此在 y \boldsymbol{y} y 坐标系中,⾼斯分布的形式为:
p ( y ) = p ( x ) ∣ J ∣ = ∏ j = 1 D 1 ( 2 π λ j ) 1 2 exp { − y i 2 2 λ j } (2.41) p(\boldsymbol{y}) = p(\boldsymbol{x})|\boldsymbol{J}| = \prod_{j=1}^{D} \frac{1}{(2 \pi \lambda_{j})^{\frac{1}{2}}} \exp \left \{- \frac{y_{i}^2}{2\lambda_j} \right \}\tag{2.41} p(y)=p(x)∣J∣=j=1∏D(2πλj)211exp{−2λjyi2}(2.41)
这是 D D D 个独⽴⼀元⾼斯分布的乘积。
在 y \boldsymbol{y} y 坐标系中,概率分布的积分为:
∫ p ( y ) d y = ∏ j = 1 D ∫ − ∞ ∞ 1 ( 2 π λ j ) 1 2 exp { − y i 2 2 λ j } d y j = 1 (2.42) \int p(\boldsymbol{y}) \mathrm{d} \boldsymbol{y} = \prod_{j=1}^{D} \int_{-\infty}^{\infty} \frac{1}{(2 \pi \lambda_{j})^{\frac{1}{2}}} \exp \left \{- \frac{y_{i}^2}{2\lambda_j} \right \} \mathrm{d} y_j = 1\tag{2.42} ∫p(y)dy=j=1∏D∫−∞∞(2πλj)211exp{−2λjyi2}dyj=1(2.42)
⾼斯分布下 x \boldsymbol{x} x 的期望为:
E [ x ] = 1 ( 2 π ) D 2 1 ∣ Σ ∣ 1 2 ∫ exp { − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) } x d x = 1 ( 2 π ) D 2 1 ∣ Σ ∣ 1 2 ∫ exp { − 1 2 z T Σ − 1 z } ( z + μ ) d z (2.43) \begin{aligned} \mathbb{E}[\boldsymbol{x}] &= \frac{1}{(2 \pi)^{\frac{D}{2}}} \frac{1}{|\boldsymbol{\Sigma}|^{\frac{1}{2}}} \int \exp \left\{-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{T} \boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right\} \boldsymbol{x} \mathrm{d} \boldsymbol{x} \\ &= \frac{1}{(2 \pi)^{\frac{D}{2}}} \frac{1}{|\boldsymbol{\Sigma}|^{\frac{1}{2}}} \int \exp \left\{-\frac{1}{2}\boldsymbol{z}^{T} \boldsymbol{\Sigma}^{-1} \boldsymbol{z}\right\} (\boldsymbol{z+\mu}) \mathrm{d} \boldsymbol{z} \end{aligned}\tag{2.43} E[x]=(2π)2D1∣Σ∣211∫exp{−21(x−μ)TΣ−1(x−μ)}xdx=(2π)2D1∣Σ∣211∫exp{−21zTΣ−1z}(z+μ)dz(2.43)
其中, z = x − μ \boldsymbol{z = x - \mu} z=x−μ 。注意到指数位置是 z \boldsymbol{z} z 的偶函数,并且由于积分区间为 ( − ∞ , ∞ ) (−\infty, \infty) (−∞,∞),因此在因⼦ ( z + μ ) (\boldsymbol{z + \mu}) (z+μ) 中的 z \boldsymbol{z} z 中的项会由于对称性变为零。因此 E [ x ] = μ \mathbb{E}[\boldsymbol{x}] = \boldsymbol{\mu} E[x]=μ 。称 μ \boldsymbol{\mu} μ 为⾼斯分布的均值。
现在考虑⾼斯分布的⼆阶矩。对于多元⾼斯分布,有 D 2 D^2 D2 个由 E [ x i x j ] \mathbb{E}[x_i x_j] E[xixj] 给出的⼆阶矩,可以聚集在⼀起组成矩阵 E [ x x T ] \mathbb{E}[\boldsymbol{x}\boldsymbol{x}^T ] E[xxT]。
E [ x x T ] = 1 ( 2 π ) D 2 1 ∣ Σ ∣ 1 2 ∫ exp { − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) } x x T d x = 1 ( 2 π ) D 2 1 ∣ Σ ∣ 1 2 ∫ exp { − 1 2 z T Σ − 1 z } ( z + μ ) ( z + μ ) T d z (2.44) \begin{aligned} \mathbb{E}[\boldsymbol{x}\boldsymbol{x}^{T}] &= \frac{1}{(2 \pi)^{\frac{D}{2}}} \frac{1}{|\boldsymbol{\Sigma}|^{\frac{1}{2}}} \int \exp \left\{-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{T} \boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right\} \boldsymbol{x} \boldsymbol{x}^{T}\mathrm{d} \boldsymbol{x} \\ &= \frac{1}{(2 \pi)^{\frac{D}{2}}} \frac{1}{|\boldsymbol{\Sigma}|^{\frac{1}{2}}} \int \exp \left\{-\frac{1}{2}\boldsymbol{z}^{T} \boldsymbol{\Sigma}^{-1} \boldsymbol{z}\right\} (\boldsymbol{z+\mu})(\boldsymbol{z+\mu})^{T} \mathrm{d} \boldsymbol{z} \end{aligned}\tag{2.44} E[xxT]=(2π)2D1∣Σ∣211∫exp{−21(x−μ)TΣ−1(x−μ)}xxTdx=(2π)2D1∣Σ∣211∫exp{−21zTΣ−1z}(z+μ)(z+μ)Tdz(2.44)
其中, z = x − μ \boldsymbol{z = x - \mu} z=x−μ , z = ∑ j = 1 D y i u j \boldsymbol{z} = \sum_{j=1}^{D} y_i \boldsymbol{u_j} z=∑j=1Dyiuj , y i = u j T z y_i = \boldsymbol{u_j}^{T}\boldsymbol{z} yi=ujTz 。
由此可以推导出:
E [ x x T ] = μ u T + Σ (2.45) \mathbb{E}[\boldsymbol{x}\boldsymbol{x}^{T}] = \boldsymbol{\mu}\boldsymbol{u}^{T} + \boldsymbol{\Sigma}\tag{2.45} E[xxT]=μuT+Σ(2.45)
随机变量 x \boldsymbol{x} x 的协⽅差(covariance),定义为:
var [ x ] = E [ ( x − E [ x ] ) ( x − E [ x ] ) T ] (2.46) \text{var}[\boldsymbol{x}] = \mathbb{E}[(\boldsymbol{x} - \mathbb{E}[\boldsymbol{x}])(\boldsymbol{x} - \mathbb{E}[\boldsymbol{x}])^{T}]\tag{2.46} var[x]=E[(x−E[x])(x−E[x])T](2.46)
对于⾼斯分布这⼀特例,我们可以使⽤ E [ x ] = μ \mathbb{E}[\boldsymbol{x}] = \boldsymbol{\mu} E[x]=μ 以及公式(2.45)的结果,得到:
var [ x ] = Σ (2.47) \text{var}[\boldsymbol{x}] = \boldsymbol{\Sigma}\tag{2.47} var[x]=Σ(2.47)
由于参数 Σ \boldsymbol{\Sigma} Σ 公式了⾼斯分布下 x \boldsymbol{x} x 的协⽅差,因此它被称为协⽅差矩阵。
二,条件⾼斯分布
多元⾼斯分布的⼀个重要性质:如果两组变量是联合⾼斯分布,那么以⼀组变量为条件, 另⼀组变量同样是⾼斯分布。
假设 x \boldsymbol{x} x 是⼀个服从⾼斯分布 N ( x ∣ μ , Σ ) \mathcal{N}(\boldsymbol{x} | \boldsymbol{\mu}, \mathbf{\Sigma}) N(x∣μ,Σ) 的 D D D 维向量。我们把 x \boldsymbol{x} x 划分成两个不相交的⼦集 x a \boldsymbol{x}_a xa 和 x b \boldsymbol{x}_b xb 。 不失⼀般性, 令 x a \boldsymbol{x}_a xa 为 x \boldsymbol{x} x 的前 M M M 个分量, 令 x b \boldsymbol{x}_b xb 为剩余的 D − M D − M D−M 个分量,因此
x = ( x a x b ) \boldsymbol{x} = \dbinom{\boldsymbol{x}_a}{\boldsymbol{x}_b} x=(xbxa)
同理,对应的对均值向量 μ \boldsymbol{\mu} μ 的划分,即
μ = ( μ a μ b ) \boldsymbol{\mu} = \dbinom{\boldsymbol{\mu}_a}{\boldsymbol{\mu}_b} μ=(μbμa)
协⽅差矩阵 Σ \boldsymbol{\Sigma} Σ 为:
Σ = ( Σ a a Σ a b Σ b a Σ b b ) (2.48) \boldsymbol{\Sigma} = \begin{pmatrix} \boldsymbol{\Sigma}_{aa} & \boldsymbol{\Sigma}_{ab} \\ \boldsymbol{\Sigma}_{ba} & \boldsymbol{\Sigma}_{bb} \end{pmatrix}\tag{2.48} Σ=(ΣaaΣbaΣabΣbb)(2.48)
注意,协⽅差矩阵的对称性 Σ T = Σ \boldsymbol{\Sigma} ^T= \boldsymbol{\Sigma} ΣT=Σ 表明 Σ a a \boldsymbol{\Sigma}_{aa} Σaa 和 Σ b b \boldsymbol{\Sigma}_{bb} Σbb 也是对称的,⽽ Σ b a = Σ a b T \boldsymbol{\Sigma}_{ba} = \boldsymbol{\Sigma}_{ab}^{T} Σba=ΣabT 。
在许多情况下,使⽤协⽅差矩阵的逆矩阵⽐较⽅便,也叫精度矩阵(precision matrix),即:
Λ ≡ Σ − 1 (2.49) \boldsymbol{\Lambda} \equiv \boldsymbol{\Sigma}^{-1}\tag{2.49} Λ≡Σ−1(2.49)
精度矩阵的划分形式
Λ = ( Λ a a Λ a b Λ b a Λ b b ) \boldsymbol{\Lambda} = \begin{pmatrix} \boldsymbol{\Lambda}_{aa} & \boldsymbol{\Lambda}_{ab} \\ \boldsymbol{\Lambda}_{ba} & \boldsymbol{\Lambda}_{bb} \end{pmatrix} Λ=(ΛaaΛbaΛabΛbb)
关于分块矩阵的逆矩阵的恒等式:
( A B C D ) − 1 = ( M − M B D − 1 − D − 1 C M D − 1 + C M B D − 1 ) (2.50) \begin{pmatrix} \boldsymbol{A} & \boldsymbol{B} \\ \boldsymbol{C} & \boldsymbol{D} \end{pmatrix}^{-1} = \begin{pmatrix} \boldsymbol{M} & \boldsymbol{-MBD^{-1}} \\ \boldsymbol{-D^{-1}CM} & \boldsymbol{D^{-1}+CMBD^{-1}} \end{pmatrix}\tag{2.50} (ACBD)−1=(M−D−1CM−MBD−1D−1+CMBD−1)(2.50)
其中, M = ( A − B D − 1 C ) − 1 \boldsymbol{M = (A-BD^{-1}C)^{-1}} M=(A−BD−1C)−1 , M − 1 \boldsymbol{M}^{-1} M−1 被称为公式(2.50)左侧矩阵关于⼦矩阵 D \boldsymbol{D} D 的舒尔补(Schur complement)。
由以上公式和相关结论可以推导出条件概率分布 p ( x a ∣ x b ) p(\boldsymbol{x}_a | \boldsymbol{x}_b) p(xa∣xb) 的均值和协⽅差的表达式:
μ a ∣ b = μ a + Σ a b Σ b b − 1 ( x b − μ b ) (2.51) \boldsymbol{\mu}_{a|b} = \boldsymbol{\mu}_a + \boldsymbol{\Sigma}_{ab}\boldsymbol{\Sigma}_{bb}^{-1}(\boldsymbol{x}_b-\boldsymbol{\mu}_b)\tag{2.51} μa∣b=μa+ΣabΣbb−1(xb−μb)(2.51)
Σ a ∣ b = Σ a a − Σ a b Σ b b − 1 Σ b a (2.52) \boldsymbol{\Sigma}_{a|b} = \boldsymbol{\Sigma}_{aa} - \boldsymbol{\Sigma}_{ab}\boldsymbol{\Sigma}_{bb}^{-1}\boldsymbol{\Sigma}_{ba}\tag{2.52} Σa∣b=Σaa−ΣabΣbb−1Σba(2.52)
三,边缘⾼斯分布
对于边缘高斯分布:
p ( x a ) = ∫ p ( x a , x b ) d x b (2.53) p(\boldsymbol{x}_a) = \int p(\boldsymbol{x}_a, \boldsymbol{x}_b) \mathrm{d} \boldsymbol{x}_b\tag{2.53} p(xa)=∫p(xa,xb)dxb(2.53)
同条件高斯分布一样,可以推导出边缘概率分布 p ( x a ) p(\boldsymbol{x}_a) p(xa) 的均值和协⽅差的表达式:
Σ a = ( Λ a a − Λ a b Λ b b − 1 Λ b a ) − 1 (2.54) \boldsymbol{\Sigma}_{a} = (\boldsymbol{\Lambda}_{aa} - \boldsymbol{\Lambda}{ab}\boldsymbol{\Lambda}_{bb}^{-1}\boldsymbol{\Lambda}_{ba})^{-1}\tag{2.54} Σa=(Λaa−ΛabΛbb−1Λba)−1(2.54)
E [ x a ] = μ a (2.55) \mathbb{E}[\boldsymbol{x}_a] = \boldsymbol{\mu}_a\tag{2.55} E[xa]=μa(2.55)
cov [ x a ] = Σ a a (2.56) \text{cov}[\boldsymbol{x}_a] = \boldsymbol{\Sigma}_{aa}\tag{2.56} cov[xa]=Σaa(2.56)
如图2.13,两个变量上的⾼斯概率分布 p ( x a , x b ) p(x_a , x_b) p(xa,xb) 的轮廓线。
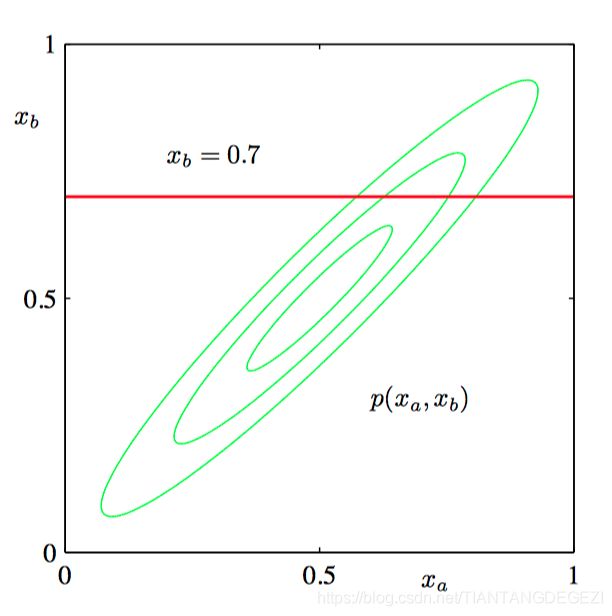
如图2.14,边缘概率分布 p ( x a ) p(x_a) p(xa)(蓝⾊曲线)和 x b = 0.7 x_b = 0.7 xb=0.7 的条件概率分布 p ( x a ∣ x b ) p(x_a | x_b) p(xa∣xb)(红⾊曲线)。

四,⾼斯变量的贝叶斯定理
令边缘概率分布和条件概率分布的形式:
p ( x ) = N ( x ∣ μ , Λ − 1 ) (2.57) p(\boldsymbol{x}) = \mathcal{N}(\boldsymbol{x} |\boldsymbol{\mu}, \boldsymbol{\Lambda}^{-1})\tag{2.57} p(x)=N(x∣μ,Λ−1)(2.57)
p ( y ∣ x ) = N ( y ∣ A x + b , L − 1 ) (2.58) p(\boldsymbol{y} | \boldsymbol{x}) = \mathcal{N}(\boldsymbol{y} |\boldsymbol{Ax+b}, \boldsymbol{L}^{-1})\tag{2.58} p(y∣x)=N(y∣Ax+b,L−1)(2.58)
其中, μ \boldsymbol{\mu} μ , A \boldsymbol{A} A 和 b \boldsymbol{b} b 是控制均值的参数, Λ \boldsymbol{\Lambda} Λ 和 L \boldsymbol{L} L 是精度矩阵。如果 x \boldsymbol{x} x 的维度为 M M M , y \boldsymbol{y} y 的维度为 D D D,那么矩阵 A A A 的⼤⼩为 D × M D \times M D×M 。
⾸先,我们寻找 x \boldsymbol{x} x 和 y \boldsymbol{y} y 的联合分布的表达式。令
z = ( x y ) \boldsymbol{z} = \dbinom{\boldsymbol{x}}{\boldsymbol{y}} z=(yx)
然后考虑联合概率分布的对数:
ln p ( z ) = ln p ( x ) + ln p ( y ∣ x ) = − 1 2 ( x − μ ) T Λ ( x − μ ) − 1 2 ( y − A x − b ) T L ( y − A x − b ) + 常 数 (2.59) \begin{aligned}\ln p(\boldsymbol{z}) &= \ln p(\boldsymbol{x}) + \ln p(\boldsymbol{y} | \boldsymbol{x}) \\ &= -\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{T} \Lambda (\boldsymbol{x} - \boldsymbol{\mu}) \\ &-\frac{1}{2}(\boldsymbol{y} - \boldsymbol{Ax} - \boldsymbol{b})^{T} \boldsymbol{L} (\boldsymbol{y}-\boldsymbol{Ax}-\boldsymbol{b}) + 常数 \end{aligned} \tag{2.59} lnp(z)=lnp(x)+lnp(y∣x)=−21(x−μ)TΛ(x−μ)−21(y−Ax−b)TL(y−Ax−b)+常数(2.59)
可以推导出, z \boldsymbol{z} z 上的⾼斯分布的精度矩阵(协⽅差的逆矩阵)为:
R = ( Λ + A T L A − A T L − L A L ) \boldsymbol{R} = \begin{pmatrix} \boldsymbol{\Lambda + A^{T}LA} & \boldsymbol{-A^{T}L} \\ \boldsymbol{-LA} & \boldsymbol{L} \end{pmatrix} R=(Λ+ATLA−LA−ATLL)
从而, z \boldsymbol{z} z 上的⾼斯分布的均值和协⽅差的表达式:
cov [ z ] = R − 1 = ( Λ − 1 Λ − 1 A T A Λ − 1 L − 1 + A Λ − 1 A T ) (2.60) \text{cov}[\boldsymbol{z}] = \boldsymbol{R}^{-1} = \begin{pmatrix} \boldsymbol{\Lambda^{-1} } & \boldsymbol{\Lambda^{-1}A^{T}} \\ \boldsymbol{A\Lambda^{-1}} & \boldsymbol{L^{-1}+A\Lambda^{-1}A^{T}} \end{pmatrix}\tag{2.60} cov[z]=R−1=(Λ−1AΛ−1Λ−1ATL−1+AΛ−1AT)(2.60)
E [ z ] = R − 1 ( Λ μ − A T L b L b ) (2.61) \mathbb{E}[\boldsymbol{z}] = \boldsymbol{R}^{-1} \dbinom{\boldsymbol{\Lambda \mu - A^{T}Lb}}{\boldsymbol{Lb}}\tag{2.61} E[z]=R−1(LbΛμ−ATLb)(2.61)
E [ z ] = ( μ A μ + b ) (2.62) \mathbb{E}[\boldsymbol{z}] = \dbinom{\boldsymbol{\mu}}{\boldsymbol{A\mu+b}}\tag{2.62} E[z]=(Aμ+bμ)(2.62)
边缘分布 p ( y ) p(\boldsymbol{y}) p(y) 的均值和协⽅差为:
E [ y ] = A μ + b (2.63) \mathbb{E}[\boldsymbol{y}] = \boldsymbol{A\mu+b}\tag{2.63} E[y]=Aμ+b(2.63)
cov [ y ] = L − 1 + A Λ − 1 A T (2.64) \text{cov}[\boldsymbol{y}] = \boldsymbol{L^{-1}+A\Lambda^{-1}A^{T}}\tag{2.64} cov[y]=L−1+AΛ−1AT(2.64)
条件分布 p ( x ∣ y ) p(\boldsymbol{x}|\boldsymbol{y}) p(x∣y) 的均值和协⽅差为:
E [ x ∣ y ] = ( Λ + A T L A ) − 1 { A T L ( y − b ) + Λ μ } (2.65) \mathbb{E}[\boldsymbol{x} | \boldsymbol{y}] = (\boldsymbol{\Lambda + A^{T}LA})^{-1}\{ \boldsymbol{A^{T}L(y-b) + \Lambda \mu} \}\tag{2.65} E[x∣y]=(Λ+ATLA)−1{ATL(y−b)+Λμ}(2.65)
cov [ x ∣ y ] = ( Λ + A T L A ) − 1 (2.66) \text{cov}[\boldsymbol{x|y}] = (\boldsymbol{\Lambda + A^{T}LA})^{-1}\tag{2.66} cov[x∣y]=(Λ+ATLA)−1(2.66)
五,⾼斯分布的最⼤似然估计
给定⼀个数据集 X = ( x 1 , … , x N ) T \boldsymbol{X} = (\boldsymbol{x}_1, \dots, \boldsymbol{x}_N)^T X=(x1,…,xN)T , 其中观测 { x n } \{\boldsymbol{x}_n\} {xn} 假定是独⽴地从多元⾼斯分布中抽取的。我们可以使⽤最⼤似然法估计分布的参数。对数似然函数为:
ln p ( X ∣ μ , Σ ) = − N D 2 ln ( 2 π ) − N 2 ln ∣ Σ ∣ − 1 2 ∑ n = 1 N ( x n − μ ) T Σ − 1 ( x n − μ ) (2.67) \ln p(\boldsymbol{X|\mu, \Sigma}) = -\frac{ND}{2} \ln (2\pi) - \frac{N}{2}\ln \boldsymbol{|\Sigma|} - \frac{1}{2}\sum_{n=1}^{N}\boldsymbol{(x_n -\mu)^{T}\Sigma^{-1}(x_n-\mu)}\tag{2.67} lnp(X∣μ,Σ)=−2NDln(2π)−2Nln∣Σ∣−21n=1∑N(xn−μ)TΣ−1(xn−μ)(2.67)
令对数似然函数关于 μ \mu μ 的导数为零,可以求得均值的最大似然估计:
μ M L = 1 N ∑ n = 1 N x n (2.68) \boldsymbol{\mu}_{ML} = \frac{1}{N}\sum_{n=1}^{N}\boldsymbol{x}_n\tag{2.68} μML=N1n=1∑Nxn(2.68)
方差的最大似然估计:
Σ M L = 1 N ∑ n = 1 N ( x n − μ M L ) ( x n − μ M L ) T (2.69) \boldsymbol{\Sigma}_{ML} = \frac{1}{N}\sum_{n=1}^{N}(\boldsymbol{x}_n-\boldsymbol{\mu}_{ML})(\boldsymbol{x}_n-\boldsymbol{\mu}_{ML})^{T}\tag{2.69} ΣML=N1n=1∑N(xn−μML)(xn−μML)T(2.69)
从而,
E [ μ M L ] = μ (2.70) \mathbb{E}[\boldsymbol{\mu}_{ML}] = \boldsymbol{\mu}\tag{2.70} E[μML]=μ(2.70)
E [ Σ M L ] = N − 1 N Σ (2.71) \mathbb{E}[\boldsymbol{\Sigma}_{ML}] = \frac{N-1}{N}\boldsymbol{\Sigma}\tag{2.71} E[ΣML]=NN−1Σ(2.71)
Σ ~ M L = 1 N ∑ n = 1 N − 1 ( x n − μ M L ) ( x n − μ M L ) T (2.72) \tilde {\boldsymbol{\Sigma}}_{ML} = \frac{1}{N}\sum_{n=1}^{N-1}(\boldsymbol{x}_n-\boldsymbol{\mu}_{ML})(\boldsymbol{x}_n-\boldsymbol{\mu}_{ML})^{T}\tag{2.72} Σ~ML=N1n=1∑N−1(xn−μML)(xn−μML)T(2.72)
六,顺序估计
考虑公式(2.68)给出的均值的最⼤似然估计结果 μ M L \boldsymbol{\mu}_{ML} μML 。 当它依赖于第 N N N 次观察时, 将记作 μ M L ( N ) \boldsymbol{\mu}_{ML}^{(N)} μML(N) 。如果想分析最后⼀个数据点 x N \boldsymbol{x}_N xN 的贡献,即有:
μ M L ( N ) = 1 N ∑ n = 1 N x n = 1 N x N + 1 N ∑ n = 1 N − 1 x n = 1 N x N + N − 1 N μ M L ( N − 1 ) = μ M L ( N − 1 ) + 1 N ( x n − μ M L ( N − 1 ) ) (2.73) \begin{aligned} \boldsymbol{\mu}_{ML}^{(N)} &= \frac{1}{N}\sum_{n=1}^{N}\boldsymbol{x}_n \\ &= \frac{1}{N}\boldsymbol{x}_{N} + \frac{1}{N}\sum_{n=1}^{N-1}\boldsymbol{x}_n \\ &= \frac{1}{N}\boldsymbol{x}_{N} + \frac{N-1}{N} \boldsymbol{\mu}_{ML}^{(N-1)} \\ &= \boldsymbol{\mu}_{ML}^{(N-1)} + \frac{1}{N}(\boldsymbol{x}_{n} -\boldsymbol{\mu}_{ML}^{(N-1)}) \end{aligned}\tag{2.73} μML(N)=N1n=1∑Nxn=N1xN+N1n=1∑N−1xn=N1xN+NN−1μML(N−1)=μML(N−1)+N1(xn−μML(N−1))(2.73)
考虑⼀对随机变量 θ \theta θ 和 z z z , 它们由⼀个联合概率分布 p ( z , θ ) p(z, \theta) p(z,θ) 所控制。已知 θ \theta θ 的条件下, z z z 的条件期望定义了⼀个确定的函数 f ( θ ) f(\theta) f(θ) ,叫回归函数,形式如下:
f ( θ ) ≡ E [ z ∣ θ ] = ∫ z p ( z ∣ θ ) d z (2.74) f(\theta) \equiv \mathbb{E}[z|\theta] = \int zp(z|\theta)\mathrm{d}z\tag{2.74} f(θ)≡E[z∣θ]=∫zp(z∣θ)dz(2.74)
如图2.15,回归函数 f ( θ ) f(\theta) f(θ) 。
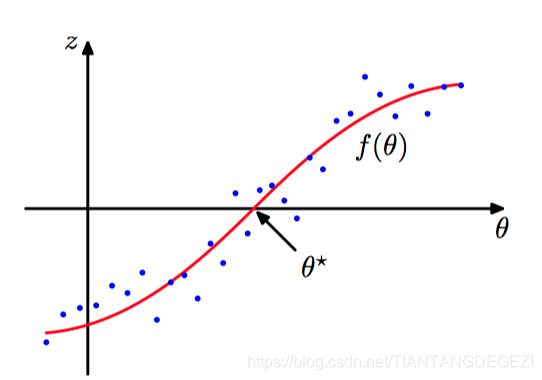
⽬标是寻找根 θ ∗ \theta^{∗} θ∗ 使得 f ( θ ∗ ) = 0 f(\theta^{∗}) = 0 f(θ∗)=0。 如果有观测 z z z 和 θ \theta θ 的⼀个⼤数据集, 那么可以直接对回归函数建模, 得到根的⼀个估计。 但是假设每次观测到⼀个 z z z 的值, 我们想找到⼀个对应的顺序估计⽅法来找到 θ ∗ \theta^{∗} θ∗ 。 下⾯的解决这种问题的通⽤步骤由 Robbins and Monro(1951)给出。假定 z z z 的条件⽅差是有穷的,即:
E [ ( z − f ) 2 ∣ θ ] < ∞ \mathbb{E}[(z-f)^2|\theta] \lt \infty E[(z−f)2∣θ]<∞
并且不失⼀般性, 我们也假设当 θ > θ ∗ \theta \gt \theta^{∗} θ>θ∗ 时 f ( θ ) > 0 f(\theta) \gt 0 f(θ)>0, 当 θ < θ ∗ \theta \lt \theta^{∗} θ<θ∗ 时 f ( θ ) < 0 f(\theta) \lt 0 f(θ)<0,Robbins-Monro 的⽅法定义了⼀个根 θ ∗ \theta^{∗} θ∗ 的顺序估计的序列,由公式(2.75)给出。
θ ( N ) = θ ( N − 1 ) + α N − 1 z ( θ ( N − 1 ) ) (2.75) \theta^{(N)} = \theta^{(N-1)} + \alpha_{N-1}z(\theta^{(N-1)})\tag{2.75} θ(N)=θ(N−1)+αN−1z(θ(N−1))(2.75)
其中 z ( θ ( N ) ) z(\theta^{(N)}) z(θ(N)) 是当 θ \theta θ 的取值为 θ ( N ) \theta (N) θ(N) 时 z z z 的观测值。系数 { α N } \{\alpha_N\} {αN} 表⽰⼀个满⾜下列条件的正数序列:
lim N → ∞ α N = 0 \lim_{N \to \infty}\alpha_{N}=0 N→∞limαN=0
∑ N = 1 ∞ α N = ∞ \sum_{N=1}^{\infty} \alpha_{N} = \infty N=1∑∞αN=∞
∑ N = 1 ∞ α N 2 < ∞ \sum_{N=1}^{\infty} \alpha_{N}^{2} \lt \infty N=1∑∞αN2<∞
根据定义,最⼤似然解 θ M L \theta_{ML} θML 是负对数似然函数的⼀个驻点,因此满⾜:
∂ ∂ θ { 1 N ∑ n = 1 N − ln p ( x N ∣ θ ) } ∣ θ M L = 0 (2.76) \left . \frac{\partial}{\partial \theta} \left\{\frac{1}{N}\sum_{n=1}^{N}- \ln p(x_N|\theta) \right\} \right|_{\theta_{ML}} = 0\tag{2.76} ∂θ∂{N1n=1∑N−lnp(xN∣θ)}∣∣∣∣∣θML=0(2.76)
交换导数与求和,取极限 N → ∞ N \to \infty N→∞ ,可以寻找最⼤似然解对应于寻找回归函数的根。 于是可以应⽤ Robbins-Monro⽅法,此时它的形式为:
θ ( N ) = θ ( N − 1 ) + α N − 1 ∂ ∂ θ ( N − 1 ) [ − ln p ( x N ∣ θ ( N − 1 ) ) ] (2.77) \theta^{(N)} = \theta^{(N-1)} + \alpha_{N-1} \frac{\partial}{\partial\theta^{(N-1)}} \left [-\ln p(x_N |\theta^{(N-1)}) \right ]\tag{2.77} θ(N)=θ(N−1)+αN−1∂θ(N−1)∂[−lnp(xN∣θ(N−1))](2.77)
七,⾼斯分布的贝叶斯推断
考虑⼀个⼀元⾼斯随机变量 x \mathbf{x} x,我们假设⽅差 σ 2 \sigma^2 σ2 是已知的,其任务是从⼀组 N N N 次观测 x = ( x 1 , … , x N ) T \mathbf{x}=(x_1,\dots, x_N)^T x=(x1,…,xN)T 中推断均值 μ \mu μ。 似然函数,即给定 μ \mu μ 的情况下,观测数据集出现的概率。它可以看成 μ \mu μ 的函数,由公式(2.78)给出。
p ( x ∣ μ ) = ∏ n = 1 N p ( x n ∣ μ ) = 1 ( 2 π σ 2 ) N 2 exp { − 1 2 σ 2 ∑ n = 1 N ( x n − μ ) 2 } (2.78) p(\mathbf{x}|\mu) = \prod_{n=1}^{N}p(x_n|\mu) = \frac{1}{\left(2 \pi \sigma^{2}\right)^{\frac{N}{2}}} \exp \left\{-\frac{1}{2 \sigma^{2}}\sum_{n=1}^{N}(x_n-\mu)^{2}\right\}\tag{2.78} p(x∣μ)=n=1∏Np(xn∣μ)=(2πσ2)2N1exp{−2σ21n=1∑N(xn−μ)2}(2.78)
注意:似然函数 p ( x ∣ μ ) p(\mathbf{x}|\mu) p(x∣μ) 不是 μ \mu μ 的概率密度,没有被归⼀化。
如图2.16,在⾼斯分布的情形中,回归函数的形式。

令先验概率分布为:
p ( μ ) = N ( μ ∣ μ 0 , σ 0 2 ) (2.79) p(\mu) = \mathcal{N}\left(\mu | \mu_0, \sigma_{0}^{2}\right)\tag{2.79} p(μ)=N(μ∣μ0,σ02)(2.79)
从⽽后验概率为:
p ( μ ∣ x ) = N ( μ ∣ μ N , σ N 2 ) (2.80) p(\mu | \mathbf{x}) = \mathcal{N}\left(\mu | \mu_N, \sigma_{N}^{2}\right)\tag{2.80} p(μ∣x)=N(μ∣μN,σN2)(2.80)
其中,
μ N = σ 2 N σ 0 2 + σ 2 μ 0 + N σ 0 2 N σ 0 2 + σ 2 μ M L \mu_N = \frac{\sigma^2}{N\sigma_{0}^2 + \sigma^2}\mu_0 + \frac{N\sigma_{0}^2}{N\sigma_{0}^2 + \sigma^2}\mu_{ML} μN=Nσ02+σ2σ2μ0+Nσ02+σ2Nσ02μML
1 σ N 2 = 1 σ 0 2 + N σ 2 \frac{1}{\sigma_{N}^{2}} = \frac{1}{\sigma_{0}^{2}} + \frac{N}{\sigma^{2}} σN21=σ021+σ2N
μ M L = 1 N ∑ n = 1 N x n \mu_{ML} = \frac{1}{N}\sum_{n=1}^{N}x_n μML=N1n=1∑Nxn
图2.17,⾼斯分布均值的贝叶斯推断。

现在假设均值是已知的,我们要推断⽅差。令 λ ≡ 1 σ 2 \lambda \equiv \frac{1}{\sigma^{2}} λ≡σ21 , λ \lambda λ 的似然函数的形式为:
p ( x ∣ λ ) = ∏ n = 1 N N ( x n ∣ μ , λ − 1 ) ∝ λ N 2 exp { − λ 2 ∑ n = 1 N ( x n − μ ) 2 } (2.81) p(\mathbf{x}|\lambda) = \prod_{n=1}^{N}\mathcal{N}(x_n|\mu, \lambda^{-1}) \propto \lambda^{\frac{N}{2}} \exp \left\{-\frac{\lambda}{2}\sum_{n=1}^{N}(x_n-\mu)^{2}\right\}\tag{2.81} p(x∣λ)=n=1∏NN(xn∣μ,λ−1)∝λ2Nexp{−2λn=1∑N(xn−μ)2}(2.81)
对应的共轭先验因此应该正⽐于 λ \lambda λ 的幂指数,也正⽐于 λ \lambda λ 的线性函数的指数。这对应于 Gamma分布,定义为:
Gam ( λ ∣ a , b ) = 1 Γ ( a ) b a λ a − 1 exp ( − b λ ) (2.82) \text{Gam}(\lambda|a,b) = \frac{1}{\Gamma(a)}b^{a}\lambda^{a-1}\exp (-b\lambda)\tag{2.82} Gam(λ∣a,b)=Γ(a)1baλa−1exp(−bλ)(2.82)
均值和协⽅差分别为:
E [ λ ] = a b (2.83) \mathbb{E}[\lambda] = \frac{a}{b}\tag{2.83} E[λ]=ba(2.83)
var [ λ ] = a b 2 (2.84) \text{var}[\lambda] = \frac{a}{b^2}\tag{2.84} var[λ]=b2a(2.84)
如图2.18~2.20,不同的 a a a 和 b b b 的情况下 Gamma分布的图像。



考虑⼀个先验分布 Gam ( λ ∣ a 0 , b 0 ) \text{Gam}(\lambda|a_0,b_0) Gam(λ∣a0,b0)。如果乘以公式(2.81)给出的似然函数,那么即可得到后验分布:
p ( λ ∣ x ) ∝ λ a 0 − 1 λ N 2 exp { − b 0 λ − λ 2 ∑ n = 1 N ( x n − μ ) 2 } (2.85) p(\lambda | \mathbf{x}) \propto \lambda^{a_0-1} \lambda^{\frac{N}{2}} \exp \left\{-b_0 \lambda -\frac{\lambda}{2}\sum_{n=1}^{N}(x_n-\mu)^{2}\right\}\tag{2.85} p(λ∣x)∝λa0−1λ2Nexp{−b0λ−2λn=1∑N(xn−μ)2}(2.85)
我们可以把它看成形式为 Gam ( λ ∣ a N , b N ) \text{Gam}(\lambda|a_N,b_N) Gam(λ∣aN,bN) 的 Gamma分布,其中
a N = a 0 + N 2 a_N = a_0 + \frac{N}{2} aN=a0+2N
b N = b 0 1 2 ∑ n = 1 N ( x n − μ ) 2 = b 0 + N 2 σ M L 2 b_N = b_0 \frac{1}{2}\sum_{n=1}^{N}(x_n-\mu)^2 = b_0 + \frac{N}{2}\sigma_{ML}^{2} bN=b021n=1∑N(xn−μ)2=b0+2NσML2
现在假设均值和精度都是未知的。为了找到共轭先验,考虑似然函数对于 μ \mu μ 和 λ \lambda λ 的依赖关系:
p ( x ∣ μ , λ ) = ∏ n = 1 N ( λ 2 π ) 1 2 exp { − λ 2 ( x n − μ ) 2 } ∝ [ λ 1 2 exp ( − λ μ 2 2 ) ] N exp { λ μ ∑ n = 1 N x n − λ 2 ∑ n = 1 N x n 2 } (2.86) \begin{aligned} p(\mathbf{x}|\mu,\lambda) &= \prod_{n=1}^{N} \left(\frac{\lambda}{2\pi} \right)^{\frac{1}{2}} \exp \left\{-\frac{\lambda}{2}(x_n-\mu)^{2}\right\} \\ &\propto \left[\lambda^{\frac{1}{2}} \exp\left(-\frac{\lambda \mu^{2}}{2}\right) \right]^{N} \exp \left\{\lambda \mu \sum_{n=1}^{N}x_n - \frac{\lambda}{2}\sum_{n=1}^{N}x_{n}^{2}\right\} \end{aligned}\tag{2.86} p(x∣μ,λ)=n=1∏N(2πλ)21exp{−2λ(xn−μ)2}∝[λ21exp(−2λμ2)]Nexp{λμn=1∑Nxn−2λn=1∑Nxn2}(2.86)
假设先验分布的形式为:
p ( μ , λ ) = exp { − β λ 2 ( μ − c β ) 2 } λ β 2 exp { − ( d − c 2 2 β ) λ } ∝ [ λ 1 2 exp ( − λ μ 2 2 ) ] β exp { c λ μ − d λ } (2.87) \begin{aligned} p(\mu,\lambda) &= \exp \left\{-\frac{\beta \lambda}{2}\left(\mu-\frac{c}{\beta}\right)^2 \right\} \lambda^{\frac{\beta}{2}} \exp \left\{-\left(d-\frac{c^2}{2\beta}\right)\lambda \right\} \\ &\propto \left[\lambda^{\frac{1}{2}} \exp\left(-\frac{\lambda \mu^{2}}{2}\right) \right]^{\beta} \exp \left\{c\lambda \mu - d\lambda\right\} \end{aligned}\tag{2.87} p(μ,λ)=exp{−2βλ(μ−βc)2}λ2βexp{−(d−2βc2)λ}∝[λ21exp(−2λμ2)]βexp{cλμ−dλ}(2.87)
其 中 c , d c, d c,d 和 β \beta β 都是常数。
归⼀化的先验概率的形式为:
p ( μ , λ ) = N ( μ ∣ μ 0 , ( β λ ) − 1 ) Gam ( λ ∣ a , b ) (2.88) p(\mu,\lambda) = \mathcal{N}(\mu|\mu_0, (\beta \lambda)^{-1})\text{Gam}(\lambda|a,b)\tag{2.88} p(μ,λ)=N(μ∣μ0,(βλ)−1)Gam(λ∣a,b)(2.88)
这被称为正态-Gamma分布或者⾼斯-Gamma分布。如图2.21:

对于 D D D 维向量 x \boldsymbol{x} x 的多元⾼斯分布 N ( x ∣ μ , Λ − 1 ) \mathcal{N}(\boldsymbol{x|\mu, \Lambda}^{−1}) N(x∣μ,Λ−1),假设精度已知,则均值 μ \boldsymbol{\mu} μ 的共轭先验分布仍然是⾼斯分布。对于已知均值未知精度矩阵 Λ \boldsymbol{\Lambda} Λ 的情形,共轭先验是**Wishart分布**,定义为:
W ( Λ ∣ W , ν ) = B ∣ Λ ∣ ν − D − 1 2 exp ( − 1 2 Tr ( W − 1 Λ ) ) (2.89) \mathcal{W}(\mathbf{\Lambda} | \boldsymbol{W}, \nu)=B|\boldsymbol{\Lambda}|^{\frac{\nu-D-1}{2}} \exp \left(-\frac{1}{2} \operatorname{Tr}\left(\boldsymbol{W}^{-1} \boldsymbol{\Lambda}\right)\right)\tag{2.89} W(Λ∣W,ν)=B∣Λ∣2ν−D−1exp(−21Tr(W−1Λ))(2.89)
其中 ν \nu ν 被称为分布的⾃由度数量(degrees of freedom), W \boldsymbol{W} W 是⼀个 D × D D \times D D×D 的标量矩阵, Tr ( ⋅ ) \operatorname{Tr}(·) Tr(⋅) 表⽰矩阵的迹。归⼀化系数 B B B 为:
B ( W , ν ) = ∣ W ∣ − ν 2 ( 2 ν D 2 π D ( D − 1 ) 4 ∏ i = 1 D Γ ( ν + 1 − i 2 ) ) − 1 (2.90) B(\boldsymbol{W}, \nu)=|\boldsymbol{W}|^{-\frac{\nu}{2}}\left(2^{\frac{\nu D}{2}} \pi^{\frac{D(D-1)}{4}} \prod_{i=1}^{D} \Gamma\left(\frac{\nu+1-i}{2}\right)\right)^{-1}\tag{2.90} B(W,ν)=∣W∣−2ν(22νDπ4D(D−1)i=1∏DΓ(2ν+1−i))−1(2.90)
如果均值和精度都是未知的,那么类似于⼀元变量的推理⽅法,共轭先验为:
p ( μ , Λ ∣ μ 0 , β , W , ν ) = N ( μ ∣ μ 0 , ( β Λ ) − 1 ) W ( Λ ∣ W , ν ) (2.91) p(\boldsymbol{\mu,\Lambda|\mu}_0,\beta,\boldsymbol{W}, \nu) = \mathcal{N}(\boldsymbol{\mu|\mu}_0, (\beta \boldsymbol{\Lambda})^{-1})\mathcal{W}(\mathbf{\Lambda} | \boldsymbol{W}, \nu)\tag{2.91} p(μ,Λ∣μ0,β,W,ν)=N(μ∣μ0,(βΛ)−1)W(Λ∣W,ν)(2.91)
这被称为正态-Wishart分布或者⾼斯-Wishart分布。
八,学生 t \mathbf{t} t 分布
如果有⼀个⼀元⾼斯分布 N ( x ∣ μ , τ − 1 ) \mathcal{N}\left(x | \mu, \tau^{-1}\right) N(x∣μ,τ−1) 和⼀个 Gamma先验分布 Gam ( τ ∣ a , b ) \text{Gam}(\tau|a, b) Gam(τ∣a,b),把精度积分出来,便可以得到 x x x 的边缘分布,形式为:
p ( x ∣ μ , a , b ) = ∫ 0 ∞ N ( x ∣ μ , τ − 1 ) Gam ( τ ∣ a , b ) d τ = ∫ 0 ∞ b a e ( − b r ) τ a − 1 Γ ( a ) ( τ 2 π ) 1 2 exp { − τ 2 ( x − μ ) 2 } d τ = b a Γ ( a ) ( 1 2 π ) 1 2 [ b + ( x − μ ) 2 2 ] − a − 1 2 Γ ( a + 1 2 ) (2.92) \begin{aligned} p(x | \mu, a, b) &=\int_{0}^{\infty} \mathcal{N}\left(x | \mu, \tau^{-1}\right) \operatorname{Gam}(\tau | a, b) \mathrm{d} \tau \\ &=\int_{0}^{\infty} \frac{b^{a} e^{(-b r)} \tau^{a-1}}{\Gamma(a)}\left(\frac{\tau}{2 \pi}\right)^{\frac{1}{2}} \exp \left\{-\frac{\tau}{2}(x-\mu)^{2}\right\} \mathrm{d} \tau \\ &=\frac{b^{a}}{\Gamma(a)}\left(\frac{1}{2 \pi}\right)^{\frac{1}{2}}\left[b+\frac{(x-\mu)^{2}}{2}\right]^{-a-\frac{1}{2}} \Gamma\left(a+\frac{1}{2}\right) \end{aligned}\tag{2.92} p(x∣μ,a,b)=∫0∞N(x∣μ,τ−1)Gam(τ∣a,b)dτ=∫0∞Γ(a)bae(−br)τa−1(2πτ)21exp{−2τ(x−μ)2}dτ=Γ(a)ba(2π1)21[b+2(x−μ)2]−a−21Γ(a+21)(2.92)
形如 p ( x ∣ μ a , b ) p(x|\mu a,b) p(x∣μa,b) 如下:
St ( x ∣ μ , λ , ν ) = Γ ( ν 2 + 1 2 ) Γ ( ν 2 ) ( λ π ν ) 1 2 [ 1 + λ ( x − μ ) 2 ν ] − ν 2 − 1 2 (2.93) \text{St}(x|\mu,\lambda,\nu) = \frac{\Gamma(\frac{\nu}{2}+\frac{1}{2})}{\Gamma(\frac{\nu}{2})}\left(\frac{\lambda}{\pi \nu}\right)^{\frac{1}{2}}\left[1+\frac{\lambda(x-\mu)^2}{\nu}\right]^{-\frac{\nu}{2}-\frac{1}{2}}\tag{2.93} St(x∣μ,λ,ν)=Γ(2ν)Γ(2ν+21)(πνλ)21[1+νλ(x−μ)2]−2ν−21(2.93)
称为学生 t 分布(Student's t-distribution)。 参数 λ \lambda λ 有时被称为 t \mathbf{t} t 分布的精度(precision), 即使它通常不等于⽅差的倒数。参数 ν \nu ν 被称为⾃由度(degrees of freedom)。如图2.22:

学生 t \mathbf{t} t 分布的⼀个重要性质:鲁棒性(robustness),即对于数据集⾥的⼏个离群点outlier的出现,分布不会像⾼斯分布那样敏感。
图 2.23,从⼀个⾼斯分布中抽取的30个数据点的直⽅图,以及得到的最⼤似然拟合。红⾊曲线表⽰使⽤ t \mathbf{t} t 分布进⾏的拟合,绿⾊曲线(⼤部分隐藏在了红⾊曲 线后⾯)表⽰使⽤⾼斯分布进⾏的拟合。由于 t \mathbf{t} t 分布将⾼斯分布作为⼀种特例,因此它给出了与⾼斯分布⼏乎相同的解。

图 2.24,与图2.23同样的数据集,但是多了三个异常数据点。这幅图展⽰了⾼斯分布(绿⾊曲线)是如 何被异常点强烈地⼲扰的,⽽ t \mathbf{t} t 分布(红⾊曲线)相对不受影响。

推⼴到多元⾼斯分布 N ( x ∣ μ , Λ ) \mathcal{N}(\boldsymbol{x|\mu, \Lambda}) N(x∣μ,Λ) 来得到对应的多元学生 t \mathbf{t} t 分布,形式为:
St ( x ∣ μ , Λ , ν ) = ∫ 0 ∞ N ( x ∣ μ , ( η Λ ) − 1 ) Gam ( η ∣ ν 2 , ν 2 ) d ν (2.94) \operatorname{St}(\boldsymbol{x} | \boldsymbol{\mu}, \boldsymbol{\Lambda}, \nu)=\int_{0}^{\infty} \mathcal{N}\left(\boldsymbol{x} | \boldsymbol{\mu},(\eta \boldsymbol{\Lambda})^{-1}\right) \operatorname{Gam}\left(\eta | \frac{\nu}{2}, \frac{\nu}{2}\right) \mathrm{d} \nu \tag{2.94} St(x∣μ,Λ,ν)=∫0∞N(x∣μ,(ηΛ)−1)Gam(η∣2ν,2ν)dν(2.94)
求积分,可得:
St ( x ∣ μ , Λ , , ν ) = Γ ( ν 2 + D 2 ) Γ ( ν 2 ) ( ∣ Λ ∣ ( π ν ) D ) 1 2 [ 1 + Δ 2 ν ] − ν 2 − D 2 (2.95) \text{St}(\boldsymbol{x} | \boldsymbol{\mu}, \boldsymbol{\Lambda},,\nu) = \frac{\Gamma(\frac{\nu}{2}+\frac{D}{2})}{\Gamma(\frac{\nu}{2})}\left(\frac{|\boldsymbol{\Lambda}|}{(\pi \nu)^D}\right)^{\frac{1}{2}}\left[1+\frac{\Delta^{2}}{\nu}\right]^{-\frac{\nu}{2}-\frac{D}{2}}\tag{2.95} St(x∣μ,Λ,,ν)=Γ(2ν)Γ(2ν+2D)((πν)D∣Λ∣)21[1+νΔ2]−2ν−2D(2.95)
其中 D D D 是 x \boldsymbol{x} x 的维度, Δ 2 \Delta^2 Δ2 是平⽅马⽒距离,定义为:
Δ 2 = ( x − μ ) T Λ ( x − μ ) (2.96) \Delta^2 = (\boldsymbol{x-\mu})^T \boldsymbol{\Lambda} (\boldsymbol{x-\mu})\tag{2.96} Δ2=(x−μ)TΛ(x−μ)(2.96)
多元变量形式的学生 t \mathbf{t} t 分布,满⾜下⾯的性质:
1) E [ x ] = μ \mathbb{E}[\boldsymbol{x}] = \boldsymbol{\mu} E[x]=μ 如果 ν > 1 \nu \gt 1 ν>1
2) cov [ x ] = ν ν − 2 Λ − 1 \text{cov}[\boldsymbol{x}] = \frac{\nu}{\nu-2}\boldsymbol{\Lambda}^{-1} cov[x]=ν−2νΛ−1 如果 ν > 2 \nu \gt 2 ν>2
3) mode [ x ] = μ \text{mode}[\boldsymbol{x}] = \boldsymbol{\mu} mode[x]=μ
九,周期变量
考察⼀个⼆维单位向量 x 1 , … , x N \boldsymbol{x}_1,\dots,\boldsymbol{x}_N x1,…,xN , 其中 ∣ ∣ x n ∣ ∣ = 1 ||\boldsymbol{x}_n|| = 1 ∣∣xn∣∣=1 且 n = 1 , … , N n = 1,\dots , N n=1,…,N , 如图2.25所⽰。

可以对向量 { x n } \{\boldsymbol{x}_n\} {xn} 求平均,可得
x ˉ = 1 N ∑ n = 1 N x n \bar{\boldsymbol{x}} = \frac{1}{N}\sum_{n=1}^{N}\boldsymbol{x}_n xˉ=N1n=1∑Nxn
注意, x ˉ \bar{\boldsymbol{x}} xˉ 通常位于单位圆的内部。
x ˉ \bar{\boldsymbol{x}} xˉ 对应的角度 θ ˉ \bar{\theta} θˉ 为:
θ ˉ = tan − 1 { ∑ n sin θ n ∑ n cos θ n } (2.97) \bar{\theta} = \tan^{-1} \left\{\frac{\sum_{n}\sin \theta_n}{\sum_{n}\cos \theta_n} \right\}\tag{2.97} θˉ=tan−1{∑ncosθn∑nsinθn}(2.97)
考虑的周期概率分布 p ( θ ) p(\theta) p(θ) 的周期为 2 π 2\pi 2π 。 θ \theta θ 上的任何概率密度 p ( θ ) p(\theta) p(θ) ⼀定⾮负, 积分等于1,并且⼀定是周期性的。因此, p ( θ ) p(\theta) p(θ) ⼀定满⾜下⾯三个条件:
1) p ( θ ) ≥ 0 p(\theta) \ge 0 p(θ)≥0
2) ∫ 0 2 π p ( θ ) d θ = 1 \int_{0}^{2\pi} p(\theta) \mathrm{d}\theta = 1 ∫02πp(θ)dθ=1
3) p ( θ + 2 π ) = p ( θ ) p(\theta + 2\pi) = p(\theta) p(θ+2π)=p(θ)
考虑两个变量 x = ( x 1 , x 2 ) \boldsymbol{x} = (x_1 , x_2) x=(x1,x2) 的⾼斯分布,均值为 μ = ( μ 1 , μ 2 ) \boldsymbol{\mu} = (\mu_1, \mu_2) μ=(μ1,μ2),协⽅差矩阵为 Σ = σ 2 I \boldsymbol{\Sigma} = \sigma^2 \boldsymbol{I} Σ=σ2I ,其中 I \boldsymbol{I} I 是⼀个 2 × 2 2\times2 2×2 的单位矩阵。因此有:
p ( x 1 , x 2 ) = 1 2 π σ 2 exp { − ( x 1 − μ 1 ) 2 + ( x 2 − μ 2 ) 2 2 σ 2 } (2.98) p(x_1,x_2) = \frac{1}{2\pi \sigma^{2}} \exp \left\{-\frac{(x_1-\mu_1)^2+(x_2-\mu_2)^{2}}{2\sigma^{2}}\right\}\tag{2.98} p(x1,x2)=2πσ21exp{−2σ2(x1−μ1)2+(x2−μ2)2}(2.98)
von Mises分布(环形正态分布(circular normal)):在单位圆 r = 1 r=1 r=1上的概率分布 p ( θ ) p(\theta) p(θ) 的最终表达式:
p ( θ ∣ θ 0 , m ) = 1 2 π I 0 ( m ) exp { m cos ( θ − θ 0 ) } (2.99) p(\theta|\theta_0,m) = \frac{1}{2\pi I_0(m)} \exp \left\{m\cos(\theta-\theta_0)\right\}\tag{2.99} p(θ∣θ0,m)=2πI0(m)1exp{mcos(θ−θ0)}(2.99)
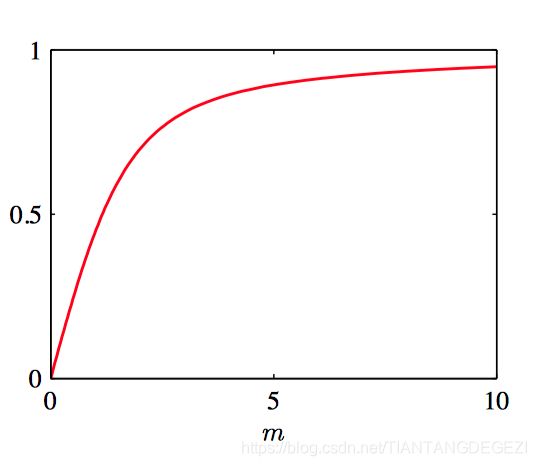
其中,参数 θ 0 \theta_0 θ0 对应于分布的均值, m m m 被称为 concentration参数,类似于⾼斯分布的⽅差的倒数(精度)。归⼀化系数包含项 I 0 ( m ) I_0 (m) I0(m),是零阶修正的第⼀类Bessel函数(Abramowitz and Stegun, 1965), 定义为:
I 0 ( m ) = 1 2 π ∫ 0 2 π exp { m cos θ } d θ (2.100) I_0(m) = \frac{1}{2\pi} \int_{0}^{2\pi}\exp\{m\cos \theta\}\mathrm{d}\theta\tag{2.100} I0(m)=2π1∫02πexp{mcosθ}dθ(2.100)
如图2.26~2.27,von Mises分布的图像。


如图2.28, Bessel函数 I 0 ( m ) I_0 (m) I0(m) 的图像。

现在考虑 von Mises分布 的参数 θ 0 \theta_0 θ0 和参数 m m m 的最⼤似然估计。对数似然函数为:
ln p ( D ∣ θ 0 , m ) = − N ln ( 2 π ) − ln I 0 ( m ) + m ∑ n = 1 N cos ( θ n − θ 0 ) (2.101) \ln p(\mathcal{D} | \theta_0,m)=-N\ln (2\pi)-\ln I_0(m)+m\sum_{n=1}^{N}\cos(\theta_n-\theta_0)\tag{2.101} lnp(D∣θ0,m)=−Nln(2π)−lnI0(m)+mn=1∑Ncos(θn−θ0)(2.101)
令其关于 θ 0 \theta_0 θ0 的导数等于零,从⽽可以得到:
θ 0 M L = tan − 1 { ∑ n sin θ n ∑ n cos θ n } (2.102) \theta_{0}^{ML} = \tan^{-1} \left\{\frac{\sum_{n}\sin \theta_n}{\sum_{n}\cos \theta_n} \right\}\tag{2.102} θ0ML=tan−1{∑ncosθn∑nsinθn}(2.102)
关于 m m m 最⼤化公式(2.101),使⽤ I 0 ′ ( m ) = I 1 ( m ) I_0^{\prime}(m)=I_1(m) I0′(m)=I1(m)(Abramowitz and Stegun, 1965),从⽽可以得到:
A ( m N L ) = 1 N ∑ n = 1 N cos ( θ n − θ 0 M L ) (2.103) A(m_{NL})=\frac{1}{N}\sum_{n=1}^{N}\cos(\theta_{n}-\theta_{0}^{ML})\tag{2.103} A(mNL)=N1n=1∑Ncos(θn−θ0ML)(2.103)
令
A ( m ) = I 1 ( m ) I 0 ( m ) A(m)=\frac{I_1(m)}{I_0(m)} A(m)=I0(m)I1(m)
可以得到:
A ( m M L ) = ( 1 N ∑ n = 1 N cos θ n ) cos θ 0 M L + ( 1 N ∑ n = 1 N sin θ n ) sin θ 0 M L (2.104) A(m_{ML})=\left(\frac{1}{N}\sum_{n=1}^{N}\cos \theta_{n}\right)\cos \theta_{0}^{ML} + \left(\frac{1}{N}\sum_{n=1}^{N}\sin \theta_{n}\right)\sin \theta_{0}^{ML}\tag{2.104} A(mML)=(N1n=1∑Ncosθn)cosθ0ML+(N1n=1∑Nsinθn)sinθ0ML(2.104)
如图2.29, 函数 A ( m ) A (m) A(m) 的图像。
十,混合高斯模型
通过将更基本的概率分布(例如⾼斯分布)进⾏线性组合的这样的叠加⽅法,可以被形式化为概率模型,被称为混合模型(mixture distributions)(McLachlan and Basford, 1988; McLachlan and Peel, 2000)。
考虑 K K K 个⾼斯概率密度的叠加,形式为:
p ( x ) = ∑ k = 1 K π k N ( x ∣ μ k , Σ k ) (2.105) p(\boldsymbol{x}) = \sum_{k=1}^{K} \pi_{k} \mathcal{N}(\boldsymbol{x} |\boldsymbol{\mu_{k}}, \boldsymbol{\Sigma}_{k})\tag{2.105} p(x)=k=1∑KπkN(x∣μk,Σk)(2.105)
这被称为混合⾼斯(mixture of Gaussians)。 每⼀个⾼斯概率密度 N ( x ∣ μ k , Σ k ) \mathcal{N}(\boldsymbol{x} |\boldsymbol{\mu_{k}}, \boldsymbol{\Sigma}_{k}) N(x∣μk,Σk) 被称为混合分布的⼀个成分(component),并且有⾃⼰的均值 μ k \boldsymbol{\mu_{k}} μk 和协⽅差 Σ k \boldsymbol{\Sigma}_{k} Σk。参数 π k \pi_{k} πk 被称为混合系数(mixing coefficients),并且满足以下条件:
1) ∑ k = 1 K π k = 1 \sum_{k=1}^{K} \pi_{k}=1 ∑k=1Kπk=1
2) 0 ≤ π k ≤ 1 0\le \pi_{k} \le 1 0≤πk≤1
如图2.30,每个混合分量的常数概率密度轮廓线,其中三个分量分别被标记为红⾊、蓝⾊和绿⾊, 且混合系数的值在每个分量的下⽅给出。

如图2.31, 混合分布的边缘概率密度 p ( x ) p(\boldsymbol{x}) p(x) 的轮廓线。

如图2.32, 概率分布 p ( x ) p(\boldsymbol{x}) p(x) 的⼀个曲⾯图。
