深度学习第33讲:CNN图像语义分割和实例分割综述
在前面八讲中,笔者和大家一起研读了关于目标检测算法的将近 10 篇论文,对两阶段的目标检测 R-CNN 系列算法和一步走的 yolo 系列算法有了一个全面的了解和概况。从本节开始,笔者将继续花费几讲的时间来研读关于语义分割和实例分割相关的经典网络和论文,以期对深度学习计算机视觉的第三大任务,也是最难的任务——图像分割有一个宏观的把握和细节的了解。
总的而言,目前的分割任务主要有两种: 语义分割和实例分割。那语义分割和实例分割具体都是什么含义呢?二者又有什么区别和联系呢?语义分割是对图像中的每个像素都划分出对应的类别,即实现像素级别的分类; 而类的具体对象,即为实例,那么实例分割不但要进行像素级别的分类,还需在具体的类别基础上区别开不同的实例。比如说图像有多个人甲、乙、丙,那边他们的语义分割结果都是人,而实例分割结果却是不同的对象,具体如下图第二第三两幅小图所示:

目标检测、语义分割和实例分割
以语义分割和实例分割为代表的图像分割技术在各领域都有广泛的应用,例如在无人驾驶和医学影像分割等方面。应用示例如下图所示:

语义分割在无人驾驶中的应用

语义分割在OCT眼底视网膜图像分层识别中的应用
作为目标检测的更进阶图像处理任务,语义分割和实例分割对卷积网络的架构涉及提出了更高的要求。本节笔者就和大家梳理一下在语义分割和实例分割领域以卷积神经网络为主体的深度学习技术目前所取得的一些研究进展和应用成果。
语义分割(Semantic Segmentation)
1.语义分割的任务描述
不同于此前的图像分类和目标检测,在开始图像分割的学习和尝试之前,我们必须明确语义分割的任务描述,即搞清楚语义分割的输入输出都是什么。我们输入当然是一张原始的RGB图像或者单通道的灰度图,但是输出不再是简单的分类类别或者目标定位,而是带有各个像素类别标签的与输入同分辨率的分割图像。简单来说,我们的输入输出都是图像,而且是同样大小的图像。如下图所示:

从输入到输出语义标签(from https://www.jeremyjordan.me/semantic-segmentation)
类似于处理分类标签数据,对预测分类目标采用像素上的 one-hot 编码,即为每个分类类别创建一个输出的 channel 。如下图所示:

语义标签的 one-hot(from https://www.jeremyjordan.me/semantic-segmentation)
下图是将分割图添加到原始图像上的效果验证。这里有个概念需要明确一下——mask,在图像处理中我们将其译为掩膜,如 mask-rcnn 中的 mask。mask 可以理解为我们将预测结果叠加到单个 channel 时得到的该分类所在区域。

语义标签与输入图像的重叠(from https://www.jeremyjordan.me/semantic-segmentation)
所以总结来说,语义分割的任务就是输入图像经过深度学习算法处理得到带有语义标签的同样尺寸的输出图像。
2.网络结构与编码解码
由于语义分割需要输入输出都是图像,所以与之前经典的图像分类和目标检测网络在分割任务上就不大适用了。在此前的经典网络中,经过多层卷积和池化之后输出的特征图尺寸会逐渐变小,所以对于语义分割任务我们需要将逐渐变小的特征图给还原到输入图像的大小。
为了实现上述目标,现有的语义分割等图像分割模型的一种通用做法就是采用编码和解码的网络结构,此前的多层卷积和池化的过程可以视作是图像编码的过程,也即不断的下采样的过程。那解码的过程就很好理解了,可以将解码理解为编码的逆运算,对编码的输出特征图进行不断的上采样逐渐得到一个与原始输入大小一致的全分辨率的分割图。

图片来自cs231n lecture11课件
编码的过程在之前的学习中我们都很了解了,就是卷积和池化的过程。如下图
所示:
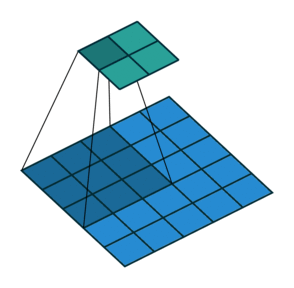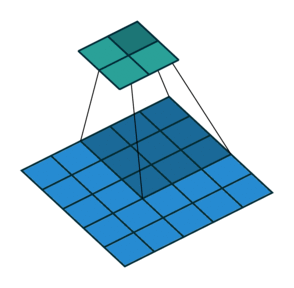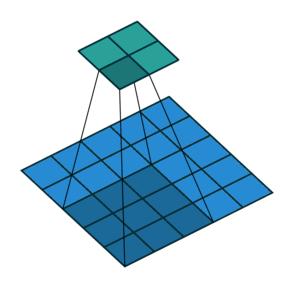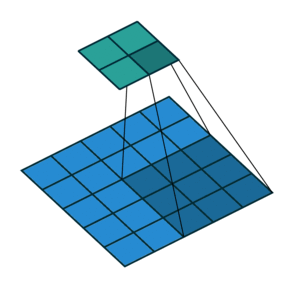
卷积动图(from https://github.com/vdumoulin/conv_arithmetic)
那解码的过程是如何向上采样的呢?上采样的过程也就是反卷积的过程,或者称为转置卷积(transpose convolution), 比如说池化下采样就是取局部最大来采样,那么池化上采样则是通过将单个值分配更高的分辨率来达到扩充的目的。最大池化和最大反池化的示意图如下:

图片来自cs231n lecture11课件
同理反卷积的过程如下图所示:
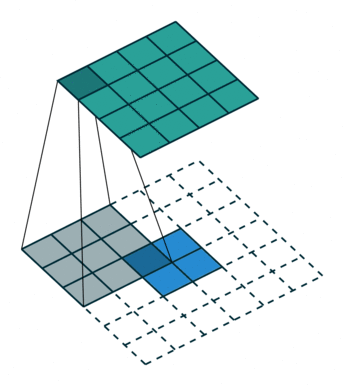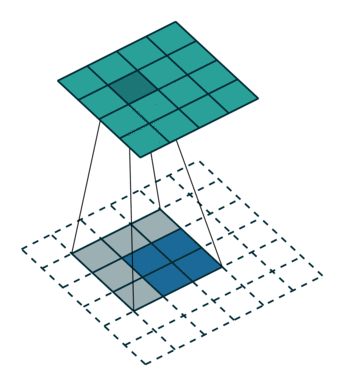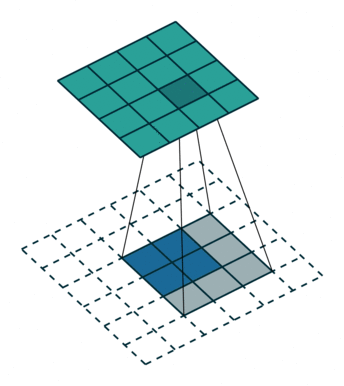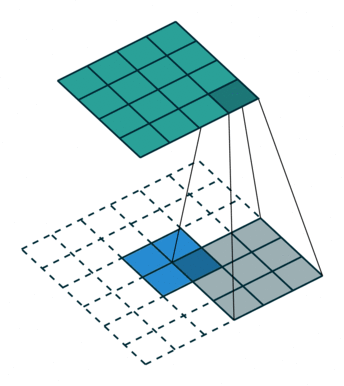
反卷积动图(from https://github.com/vdumoulin/conv_arithmetic)
至于反池化和转置卷积的相关细节,感兴趣的朋友可参考该论文:
A guide to convolution arithmetic for deep learning
地址:https://arxiv.org/abs/1603.07285
3.全卷积网络(FCN)
FCN算是首开对图像进行像素级分类的代表,率先给出了语义级别的图像分割解决方案。总的而言,FCN遵循编码解码的网络结构模式,使用 AlexNet 作为网络的编码器,采用转置卷积对编码器最后一个卷积层输出的特征图进行上采样直到特征图恢复到输入图像的分辨率,因而可以实现像素级别的图像分割。FCN的一个好处是可输入任意尺寸的图像进行语义分割。


FCN 论文:Fully Convolutional Networks for Semantic Segmentation
FCN tensorflow 开源实现参考:https://github.com/MarvinTeichmann/tensorflow-fcn
4.u-net
作为 FCN 的一种改进和发展,Ronneberger 等人通过扩大网络解码器的容量来改进了全卷积网络结构,并给编码和解码模块添加了收缩路径(contracting path)来来实现更精准的像素边界定位。u-net 的结构如下图所示:

u-net 在海拉细胞分割任务上的效果展示:

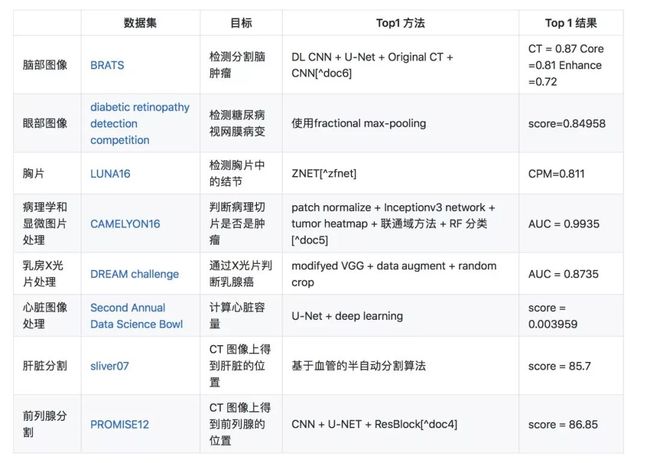
近些年人工智能在医疗领域应用越来越广泛,u-net 似乎就是其中的体现之一,u-net 在大量医学影像分割上的效果使得这种语义分割的网络架构非常流行,近年来在一些视觉比赛的冠军方案中也随处可见 u-net 的身影。
u-net 论文:u-net convolutional networks for biomedical image segmentation
u-net 开源实现参考:https://github.com/jakeret/tf_unet
5.v-net
v-net 可以理解为 3D 版本的 u-net ,适用于三维结构的医学影像分割。v-net 能够实现 3D 图像端到端的图像语义分割,加了一些像残差学习一样的trick来进行网络改进,总体结构上与 u-net 差异不大。
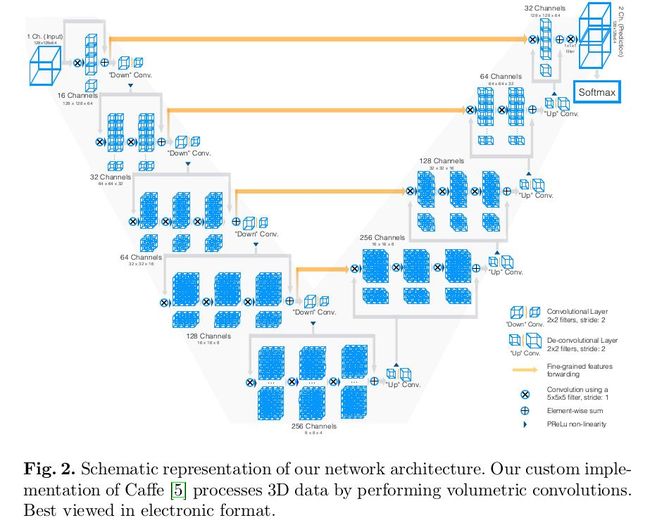
v-net 论文:V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation
v-net 开源实现参考:https://github.com/mattmacy/vnet.pytorch
6.u-net 变体网络
除了以上经典的语义分割网络模型之外,还有一些基于 u-net 的高级变体,比如使用块(block)来代替编码解码模块中堆栈的卷积层。比如 Jegou 等人使用 DenseNet 的密集连接块结合 u-net 的网络架构得到了 u-net 的一种变体网络。结构如下图所示:

应用此网络结构的语义分割效果如下:

以上便是近几年较为经典的基于卷积神经网络的语义分割网络模型。相较于传统的图搜索和图像分割算法,基于CNN的图像语义分割不过数年时间的发展历史,相信深度学习的不断发展我们将来会看到更多性能更优的语义分割网络模型。
实例分割(Instance Segmentation)
相较于语义分割,实例分割不仅要做出像素级别的分类,还要在此基础上将同一类别不同个体分出来,即做到每个实例的分割。这对分割算法提出了更高的要求。好在我们此前积累足够的目标检测算法基础。实例分割的基本思路就是在语义分割的基础上加上目标检测,先用目标检测算法将图像中的实例进行定位,再用语义分割方法对不同定位框中的目标物体进行标记,从而达到实例分割的目的。
实例分割算法也有一定的发展历史但其中影响深远且地位重要的算法不多,这里笔者仅以 mask R-CNN 为例进行介绍。
mask R-CNN 是 2017 年何恺明等大佬基于此前的两阶段目标检测算法推出的顶级网络。Mask R-CNN 的整体架构如图所示:

Mask R-CNN 将 Fast R-CNN 的 ROI Pooling 层升级成了 ROI Align 层,并且在边界框识别的基础上添加了分支FCN层,即mask层,用于语义 Mask 识别,通过 RPN 网络生成目标候选框,然后对每个目标候选框分类判断和边框回归,同时利用全卷积网络对每个目标候选框预测分割。Mask R-CNN 本质上一个实例分割算法(Instance Segmentation),相较于语义分割(Semantic Segmentation),实例分割对同类物体有着更为精细的分割。Mask R-CNN 在 coco 测试集上的图像分割效果如下:

mask R-CNN 论文:mask R-CNN
mask R-CNN 开源实现参考:https://github.com/matterport/Mask_RCNN
关于实例分割的更多内容,感兴趣的小伙伴可以自行谷歌查阅相关的论文和资料,笔者就不在此多说了。下一讲,笔者将和大家一起学习第一个语义分割网络 —— FCN全卷积网络。
参考资料:
Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 39(4):640-651.
Ronneberger O, Fischer P, Brox T. U-Net: Convolutional Networks for Biomedical Image Segmentation[C]// International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2015:234-241.
Milletari F, Navab N, Ahmadi S A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation[C]// International Conference on 3d Vision. IEEE, 2016:565-571.
Jegou S, Drozdzal M, Vazquez D, et al. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation[J]. 2016:1175-1183.
He K, Gkioxari G, Dollar P, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, PP(99):1-1.
https://www.jeremyjordan.me/semantic-segmentation
https://github.com/matterport/Mask_RCNN
cs231n
往期精彩:
一个数据科学从业者的学习历程


长按二维码.关注数据科学家养成记
