yolov5环境配置及训练coco128数据集
本人小白一个,最近在学习yolov5网络,于是跟着网上的教程配置环境训练等,出现了很多错误,可能会比较乱,先说声抱歉。现在总结一下,算是理清下自己的思路,希望对各位也有些帮助。
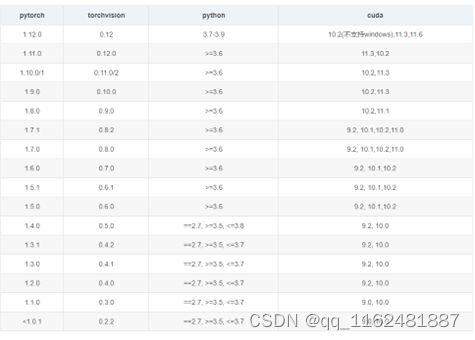
环境配置:推荐安装Cuda10.2+cudnn 7.6.5+toch 1.9.0 +torchvision 0.10.0
先按安装orch在安装torchvision,否则会报错
参考连接史上最详细yolov5环境配置搭建+配置所需文件_python_想到好名再改-DevPress官方社区
这个连接中的代码,建议使用yolov5-3.1,我在使用1.0时在训练coco128数据集时,会出现 P R等值为0的情况,根据网上所说的降低版本仍然不行(之前我用的版本是cuda11.3及其相关匹配版本。)
cuda连接:CUDA Toolkit 10.2 Download | NVIDIA Developer
cudnn连接如下:
cuDNN Archive | NVIDIA Developer
这两个连接是官网下载,或者使用下面的命令也可以(应该是,记不太清了)
如果没有找到自己想安装的版本,可以看看下面的连接:https://download.pytorch.org/whl/torch_stable.html
如其中的
![]()
表示cuda11.3+python3.8+win64
下载完,自己所需要的版本后,在自己的环境中pip install +包名 即可,如:
pip install torch-1.10.0+cu102-cp37-cp37m-win_amd64.whl
建议先安装anaconda,创建一个虚拟环境(比如我的是yolov5test),都安装在自己的虚拟环境中。
在conda虚拟环境中安装cuda,cudnn:
conda install cudatoolkit=10.2 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/win-64/
conda install cudnn=7.6.5 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/win-64/
激活:安装后打开anaconda prompt,输入activate+ 自己的环境名字 即可,如:activate yolov5test,
在安装cuda时,一开始选择第一个,但在安装包下载时一直出错,多次尝试还是不行,于是选择了本地安装:

下载之后安装即可,安装位置默认,自定义安装:
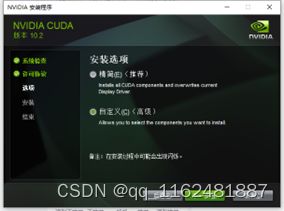
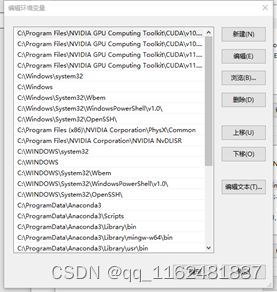
安装完成后配置环境变量:
右击“此电脑”,点击高级系统设置,环境变量:


之后双击系统变量中的path:

如下图,点击新建,将下面的路径一一粘贴,(若有多个cuda版本,将使用的版本上移即可,如下图中10.2版本在前,11.4版本在后):
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\lib\x64
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\extras\CUPTI\lib64
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.2\bin\win64
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.2\common\lib\x64
在cmd命令行输出nvcc -V即可查看是否安装成功:

安装cudnn:
建议下载cudnn7.6.5,选择windows10系统的:

下载之后解压,将里面的内容复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2中,即可。
都安装完之后就可以运行yolov5-3.1中的detect.py代码了,以下是我在运行中的错误总结:
错误1、AttributeError: ‘Upsample‘ object has no attribute ‘recompute_scale_factor‘,解决方法如下:
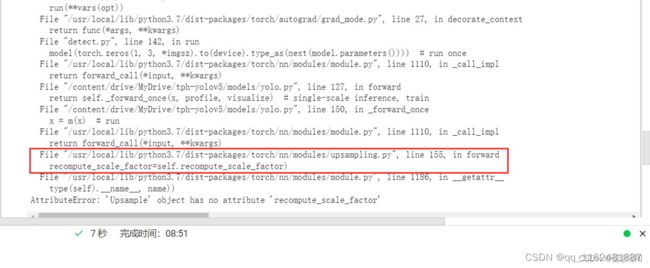
根据上述信息,打开usampling.py文件,在第155行可以看到该报错代码,将第154行以及153行最后的逗号删除,参考:一步真实解决AttributeError: ‘Upsample‘ object has no attribute ‘recompute_scale_factor‘_蓝胖胖▸的博客-CSDN博客
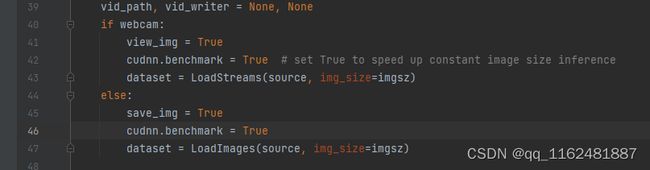
错误2、可能会出现输出结果没有检测框的情况:
打开output文件夹,查看输出图片,发现图中没有检测框,百度之后在第46行加入如下代码cudnn.benchmark = True,如图所示
错误3、可能会出现以下错误:TypeError: can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tenson to host memory firnst.

观察错误提示,发现是pytorch与torchvision版本不匹配。可以在pycharm该项目解释器中查看自己的版本,发现我的分别是1.12.1与0.13.1,又顺便在cmd命令行中输入nvcc --version查看了一下cuda的版本为11.4(使用官网的cuda11.3对应版本即可)
再次运行,应该就可以在输出结果中看到检测框了。
训练coco128过程中,出现的错误:
要将coco128数据集放到与yolov5-3.1同级目录中,运行train.py文件,
错误4、RuntimeError: a view of a leaf Vaniable that nequires grad is being used in an in-place operation.

解决:点击错误提示,
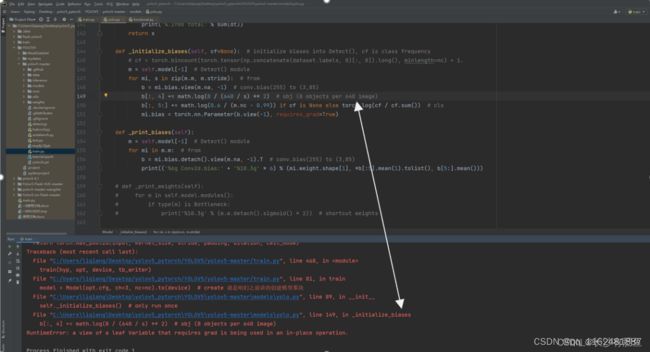
来到如下界面:
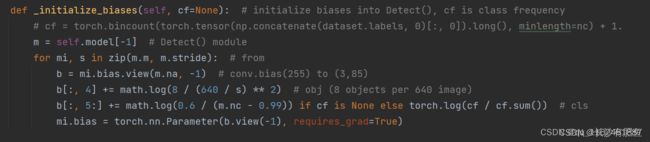
将其修改为:添加with torch.no_grad(),如下

参考:RuntimeError: a view of a leaf Variable that requires grad is being used in an in-place operation._长沙有肥鱼的博客-CSDN博客
错误5、OMP: Hint This means that multipe copies of the OpenMP runtime have linked into the program.

解决:
在开头加上如下代码:
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
参考:Hint: This means that multiple copies of the OpenMP runtime have been linked into the program._LiBiGo的博客-CSDN博客
错误6、RuntimeError: CUDA out of memony.Tried to allocate 20.00 MiB(GPU 0; 4.00 GiB total capacity; 57.24 MiB alr
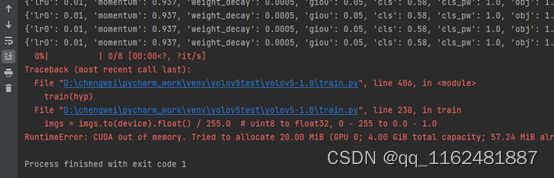
解决:①修改 batch_size大小,之后可能会出现以下错误:TypeError: can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tenson to host memory firnst.

查看错误提示:在将 tensor 格式转换成 numpy 格式时出现报错:
TypeError: can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
错误原因,需要先将 tensor 转换到 CPU ,因为 Numpy 是 CPU-only
解决:使用 .cpu() 先进行转换,例如在643行中加入.cpu():

参考:问题解决之 TypeError: can‘t convert CUDA tensor to numpy. Use Tensor.cpu() to copy the tensor to_star_function的博客-CSDN博客
之后在运行,应该就会成功:

(这里有个错误,P R为0,但我当时不懂,只看到了运行成功,所以在下面的detect.py时,输出结果没有检测框,注意观察训练,若出现为零的情况就不要在训练了,应解决此错误,百度此错误,发现都是降低版本,之前说过,我一开始用的是cuda11.3及相关版本,以及yolov5-1.0代码,所以降低版本之后P R 等还是为0,之后再尝试yolov5-3.1的detect.py以及train.py时成功了,不知道为啥1.0的会不行)
完成之后,可以在train.py统计目录中找到训练结果的图片,权重在weights中,一个best.pt和一个last.pt,打开detect.py程序,将其中的权重目录改为best.pt,如下:

然后运行即可。
错误7、AttributeError: module 'distutils' has no attribute 'version
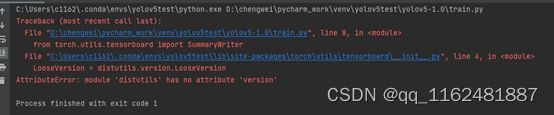
出现该错误的原因是setuptools版本过高,将其降低为58.0.4:
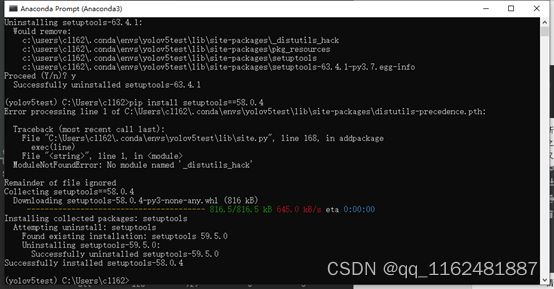
(使用yolov5-3.1的代码,epochs=10,bach_size=8,简单尝试了一下,epochs太大会增加训练时间)训练完成
训练完毕后,整个过程的最好权重best.pt和最后权重last.pt程序会保存在./runs/exp*/weigths/下,修改detect.py中的weeights:
![]()
![]()
运行detect.py:
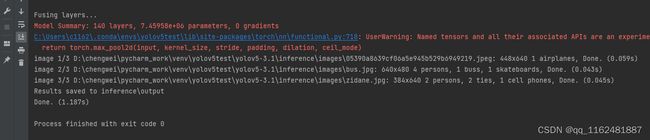
就可以在inferenc/output看到输出结果:
原图(飞机是我另外加的):



结果: