pytorch 训练过程acc_PyTorch练习(一)循环神经网络(RNN)
准备更一个pytorch的系列,通过一个个案例来熟悉一下pytorch以及工具库的使用方法。如果您对深度学习不甚了解,对深度学习框架也没有使用过,不建议直接阅读此文,如果您对pytorch完全没接触过,可以观看这个教程:
https://www.bilibili.com/video/BV1uJ41117t6www.bilibili.com这是一个超级棒的、面向pytorch萌新的课程。如果你的英语水平不错的话,这门课程将看得非常舒适。
而下面的这些代码和组织逻辑,很大一部分是来自孙玉林、余本国的《PyTorch深度学习入门与实战》(好吧,我承认校图书馆的新书阅览室太香了(╯▽╰))。感觉这本书的质量还挺不错的。
练习(一)我想写写使用RNN实现CV界的hello world:手写数据集识别(MNIST)。NLP学习者都知道RNN是用来处理序列信息(时序信息)的一种网络结构。
所谓序列信息就是一串位置不能交换的序列,比如文字序列、音频序列、视频流序列。将文字序列中的几个字互换位置,整句话的意思可能会天翻地覆;将一首歌分帧后交换几帧的位置,整首歌就会非常不协调
其实手写数字集MNIST也可以看作序列信息,一张28*28的图片的第
接下来,尝试使用RNN来识别MNIST数据集。
首先导入需要的第三方库:
import numpy as np
import matplotlib.pyplot as plt
import copy
import torch
from torch import nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torch.utils.data as Data
from torchvision import transforms
import hiddenlayer as hl
from sklearn.metrics import classification_report, accuracy_score
%matplotlib inline接下来通过torchvision.datasets模块下的MNIST方法来导入数据:
train_data = torchvision.datasets.MNIST(
root="../数据集/pytorch专用/MNIST",
train=True, transform=transforms.ToTensor(),
download=False
)
train_loader = Data.DataLoader(
dataset=train_data,
batch_size=64, # 每次读取一个batch中样本的数量
shuffle=True, # 重新使用loader时打乱数据
num_workers=0 # 工作线程数
)
test_data = torchvision.datasets.MNIST(
root="../数据集/pytorch专用/MNIST",
train=False, transform=transforms.ToTensor(),
download=False
)
test_loader = Data.DataLoader(
dataset=test_data,
batch_size=64,
shuffle=True,
num_workers=0
)其中torchvision.datasets.MNIST有这么几个参数:
- root:指定本地MNIST数据集的路径,如果指定路径没有数据且download参数为True,则在该路径下自动下载MNIST数据集。
- train:如果参数为True,返回训练集,反之,返回测试集。
- transform:填入transforms模块下方法,用来指定对载入数据的操作。比如此处的transforms.ToTensor()作用是将numpy.ndarray对象或者PIL.Image对象表示的图片转化成tensor张量,并对每个通道的每个像素点做除以255的归一化操作。
- download:如果填入参数为True,就在root指定的路径下下载数据集,反之,读取root指定的路径下的数据集。
我们可以看看一个batch中的数据:
for batch in train_loader:
x, y = batch
print(x.shape)
print(y.shape)
break输出:
torch.Size([64, 1, 28, 28])
torch.Size([64])接下来搭建RNN网络:
class RNNimc(nn.Module):
def __init__(self, input_dim, hidden_dim, layer_dim, output_dim):
"""
input_dim: 每个输入xi的维度
hidden_dim: 词向量嵌入变换的维度,也就是W的行数
layer_dim: RNN神经元的层数
output_dim: 最后线性变换后词向量的维度
"""
super(RNNimc, self).__init__()
self.rnn = nn.RNN(
input_dim, hidden_dim, layer_dim,
batch_first = True,
nonlinearity = "relu"
)
self.fc1 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
"""
维度说明:
time_step = sum(像素数) / input_dim
x : [batch, time_step, input_dim]
"""
out, h_n = self.rnn(x, None) # None表示h0会以全0初始化,及初始记忆量为0
"""
out : [batch, time_step, hidden_dim]
"""
out = self.fc1(out[: , -1, :]) # 此处的-1说明我们只取RNN最后输出的那个h。
return out 此处结合RNN的结构稍作解释:
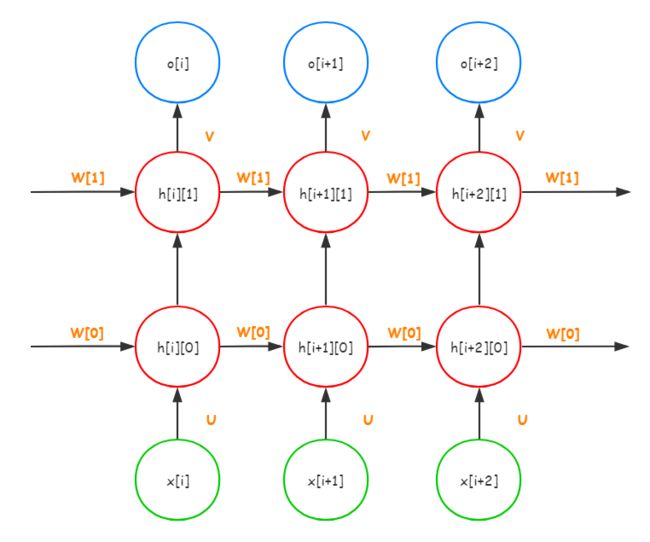
图中橘黄色标出的大写字母都是参数矩阵。
第一个参数input_dim是代表输入的x的维度,其中x是列向量。input_dim将决定网络中矩阵U的列数
第二个参数hidden_dim代表了词向量嵌入的维度,也就是x[i]经过U的变换后,会从input_dim维(input_dim个神经元)变到hidden_dim维(hidden_dim个神经元)。因此hidden_dim决定了U的行数。
第三个参数layer_dim代表了RNN神经元的层数。如图所示,在x[i]->o[i]这个方向上经过了h[i][0]和h[i][1]这两个状态(h[i][0]和h[i][1]都是形如[hidden_dim, 1]的列向量;h[i][0]变换到h[i][1]的矩阵没有在图中标出),于是,上图中RNN神经元的层数便是2。所以x[i]到o[i]这个方向上红色神经元的数量代表了RNN神经元的层数。
上述程序中的这句话
out, h_n = self.rnn(x, None) # None表示h0会以全0初始化,及初始记忆量为0 因为RNN的本质就是一个迭代次数与序列长度相同的迭代,所以需要给与起始的h0一个迭代初值,填入None就代表h0的迭代初值为0。self.rnn的输出值有两个。out代表由o[0],o[2],o[3],...o[n-1]组成的序列,长度与输入序列长度相同,hn代表最后RNN的一个隐藏状态。
后面的操作out[:, -1, :]代表我们对batch中的每个数据都只取o[n-1],因为o[n-1]中体现了网络对一整个序列的认识(提取的特征),故取o[n-1]。
取到o[n-1]后,我们再通过一个全连接层将o[n-1]映射到一个维度为output_dim的向量,向量的每一维就是网络对每一类别的预测置信度。
然后我们在全局定义网络的参数,再实例化网络,得到一个网络对象:
input_dim = 28 # 输入维度
hidden_dim = 128 # RNN神经元个数
layer_dim = 1 # RNN的层数
output_dim = 10 # 输出维度
MyRNNimc = RNNimc(input_dim, hidden_dim, layer_dim, output_dim)
print(MyRNNimc)out:
RNNimc(
(rnn): RNN(28, 128, batch_first=True)
(fc1): Linear(in_features=128, out_features=10, bias=True)
)数据和网络都准备好了,接下来就是训练了。有一点点小准备:
- 获取优化器
- 获取损失函数
- 准备几个迭代器在训练时记录数据,用来训练后可视化
当然,第三条也可以不要,你可以借助一些可视化库来更加方便地展示数据,具体可以看一下笔者曾经的拙笔:
锦恢:PyTorch下的可视化工具zhuanlan.zhihu.com
获取优化器、损失函数:
optimizer = optim.RMSprop(MyRNNimc.parameters(), lr=3e-4)
criterion = nn.CrossEntropyLoss()
train_loss_all = []
train_acc_all = []
test_loss_all = []
test_acc_all = []
num_epoch = 30 # 训练的轮数接下里开始训练,记住先遍历训练轮数epoch,再遍历数据生成器train_loader/test_loader,别忘了保存模型:
optimizer = optim.RMSprop(MyRNNimc.parameters(), lr=3e-4)
criterion = nn.CrossEntropyLoss()
train_loss_all = []
train_acc_all = []
test_loss_all = []
test_acc_all = []
num_epoch = 30
for epoch in range(num_epoch):
print("Epoch {}/{}".format(epoch, num_epoch - 1))
MyRNNimc.train() # 模式设为训练模式
train_loss = 0
corrects = 0
train_num = 0
for step, (b_x, b_y) in enumerate(train_loader):
# input_size=[batch, time_step, input_dim]
output = MyRNNimc(b_x.view(-1, 28, 28))
pre_lab = torch.argmax(output, 1)
loss = criterion(output, b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item() * b_x.size(0)
corrects += torch.sum(pre_lab == b_y.data)
train_num += b_x.size(0)
# 每个epoch后再测试集上测试损失和精度
train_loss_all.append(train_loss / train_num)
train_acc_all.append(corrects.double().item() / train_num)
print("{}, Train Loss: {:.4f} Train Acc: {:.4f}".format(epoch, train_loss_all[-1], train_acc_all[-1]))
# 设置模式为验证模式
MyRNNimc.eval()
corrects, test_num, test_loss = 0, 0, 0
for step, (b_x, b_y) in enumerate(test_loader):
output = MyRNNimc(b_x.view(-1, 28, 28))
pre_lab = torch.argmax(output, 1)
loss = criterion(output, b_y)
test_loss += loss.item() * b_x.size(0)
corrects += torch.sum(pre_lab == b_y)
test_num += b_x.size(0)
# 计算经过一个epoch的训练后再测试集上的损失和精度
test_loss_all.append(test_loss / test_num)
test_acc_all.append(corrects.double().item() / test_num)
print("{} Test Loss: {:.4f} Test Acc: {:.4f}".format(epoch, test_loss_all[-1], test_acc_all[-1]))
torch.save(MyRNNimc, "./data/chap7/RNNimc.pkl")out:
Epoch 0/29
0, Train Loss: 0.9896 Train Acc: 0.6620
0 Test Loss: 0.6311 Test Acc: 0.7913
Epoch 1/29
1, Train Loss: 0.4929 Train Acc: 0.8469
1 Test Loss: 0.4277 Test Acc: 0.8722
Epoch 2/29
2, Train Loss: 0.3441 Train Acc: 0.8950
2 Test Loss: 0.2843 Test Acc: 0.9122
Epoch 3/29
3, Train Loss: 0.2612 Train Acc: 0.9206
3 Test Loss: 0.3294 Test Acc: 0.8997
Epoch 4/29
4, Train Loss: 0.2110 Train Acc: 0.9364
4 Test Loss: 0.4589 Test Acc: 0.8643
Epoch 5/29
5, Train Loss: 0.1803 Train Acc: 0.9460
5 Test Loss: 0.1780 Test Acc: 0.9468
Epoch 6/29
6, Train Loss: 0.1593 Train Acc: 0.9532
6 Test Loss: 0.1573 Test Acc: 0.9526
Epoch 7/29
7, Train Loss: 0.1421 Train Acc: 0.9579
7 Test Loss: 0.1305 Test Acc: 0.9626
Epoch 8/29
8, Train Loss: 0.1299 Train Acc: 0.9616
8 Test Loss: 0.1620 Test Acc: 0.9505
Epoch 9/29
9, Train Loss: 0.1189 Train Acc: 0.9635
9 Test Loss: 0.1217 Test Acc: 0.9650
Epoch 10/29
10, Train Loss: 0.1106 Train Acc: 0.9671
10 Test Loss: 0.1110 Test Acc: 0.9674
Epoch 11/29
11, Train Loss: 0.1017 Train Acc: 0.9699
11 Test Loss: 0.1272 Test Acc: 0.9625
Epoch 12/29
12, Train Loss: 0.0955 Train Acc: 0.9714
12 Test Loss: 0.1134 Test Acc: 0.9661
Epoch 13/29
13, Train Loss: 0.0910 Train Acc: 0.9731
13 Test Loss: 0.0925 Test Acc: 0.9733
Epoch 14/29
14, Train Loss: 0.0839 Train Acc: 0.9750
14 Test Loss: 0.1095 Test Acc: 0.9691
Epoch 15/29
15, Train Loss: 0.0806 Train Acc: 0.9759
15 Test Loss: 0.0849 Test Acc: 0.9752
Epoch 16/29
16, Train Loss: 0.0761 Train Acc: 0.9768
16 Test Loss: 0.1017 Test Acc: 0.9716
Epoch 17/29
17, Train Loss: 0.0730 Train Acc: 0.9780
17 Test Loss: 0.1418 Test Acc: 0.9601
Epoch 18/29
18, Train Loss: 0.0689 Train Acc: 0.9790
18 Test Loss: 0.2600 Test Acc: 0.9204
Epoch 19/29
19, Train Loss: 0.0665 Train Acc: 0.9805
19 Test Loss: 0.0913 Test Acc: 0.9743
Epoch 20/29
20, Train Loss: 0.0637 Train Acc: 0.9808
20 Test Loss: 0.0851 Test Acc: 0.9742
Epoch 21/29
21, Train Loss: 0.0613 Train Acc: 0.9814
21 Test Loss: 0.0795 Test Acc: 0.9791
Epoch 22/29
22, Train Loss: 0.0586 Train Acc: 0.9826
22 Test Loss: 0.0684 Test Acc: 0.9807
Epoch 23/29
23, Train Loss: 0.0565 Train Acc: 0.9826
23 Test Loss: 0.1019 Test Acc: 0.9698
Epoch 24/29
24, Train Loss: 0.0557 Train Acc: 0.9833
24 Test Loss: 0.0710 Test Acc: 0.9804
Epoch 25/29
25, Train Loss: 0.0524 Train Acc: 0.9845
25 Test Loss: 0.0676 Test Acc: 0.9800
Epoch 26/29
26, Train Loss: 0.0519 Train Acc: 0.9841
26 Test Loss: 0.0733 Test Acc: 0.9807
Epoch 27/29
27, Train Loss: 0.0488 Train Acc: 0.9855
27 Test Loss: 0.0662 Test Acc: 0.9826
Epoch 28/29
28, Train Loss: 0.0477 Train Acc: 0.9858
28 Test Loss: 0.1600 Test Acc: 0.9562
Epoch 29/29
29, Train Loss: 0.0462 Train Acc: 0.9865
29 Test Loss: 0.0694 Test Acc: 0.9825数据看着是正常收敛,我们可以可视化看看:
plt.figure(figsize=[14, 5])
plt.subplot(1, 2, 1)
plt.plot(train_loss_all, "ro-", label="Train Loss")
plt.plot(test_loss_all, "bs-", label="Val Loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(train_acc_all, "ro-", label="Train Acc")
plt.plot(test_acc_all, "bs-", label="Test Acc")
plt.xlabel("epoch")
plt.ylabel("Acc")
plt.legend()
plt.show()out:

看着效果还不错。
最后看一下模型在测试集上的准确率:
predict_labels = []
true_labels = []
for step, batch in enumerate(test_loader):
x, y = batch
output = MyRNNimc(x.squeeze()) # 只是为了塑造成[batch, time_step, input_dim]的形状
pre_lab = torch.argmax(output, 1)
predict_labels += pre_lab.flatten().tolist()
true_labels += y.flatten().tolist()
print(classification_report(predict_labels, true_labels))
print("n模型精度为:", accuracy_score(predict_labels, true_labels))out:
precision recall f1-score support
0 0.99 0.98 0.99 987
1 1.00 0.97 0.99 1161
2 0.97 0.98 0.98 1022
3 0.97 0.99 0.98 990
4 0.98 0.98 0.98 983
5 0.97 0.98 0.97 887
6 0.98 0.98 0.98 952
7 0.97 0.98 0.97 1024
8 0.98 0.96 0.97 989
9 0.97 0.97 0.97 1005
micro avg 0.98 0.98 0.98 10000
macro avg 0.98 0.98 0.98 10000
weighted avg 0.98 0.98 0.98 10000
模型精度为: 0.9778因此,RNN在MNIST数据集上的效果很不错。