YOLOv5训练自己的数据集
YOLOv5训练自己的数据集
文件夹前期大致结构

一、创建VOCdata文件夹
在VOCdata文件夹中创建两个子文件夹,分为训练和测试。

将原始图片放入其中文件夹里的old文件夹中。
二、图片大小重置
将原始图片,统一大小。图片大小重置过后保存到JPEGImages文件夹中。
import cv2
import glob
import os
image_path = "D:/pycharm/yolov5/VOCdata/VOCTrainval/old/*.jpg" # 原始图片路径
output_path = "D:/pycharm/yolov5/VOCdata/VOCTrainval/JPEGImages/" # 修改后的保存路径
count = 0
for jpgfile in glob.glob(image_path):
count += 1
#img = Image.open(jpgfile)
image = cv2.imread(jpgfile )
image = cv2.resize(image,(1280,720),interpolation=cv2.INTER_CUBIC)
cv2.imwrite(os.path.join(output_path,os.path.basename(jpgfile)), image)
print("save%d"%count)
print("resize finished!")三、图片重命名
对于统一大小过后的图片,以统一格式重新命名,以便后续增加新的图片进来,代码如下:
import os
path=input('D:/pycharm/yolov5/VOCdata/VOCTrainval/JPEGImages/')
#获取该目录下所有文件,存入列表中
fileList=os.listdir(path)
n=0
m=0 # 图片编号从m+1开始
for i in fileList:
#设置旧文件名(就是路径+文件名)
oldname=path+ os.sep + fileList[n] # os.sep添加系统分隔符
#设置新文件名
newname=path+os.sep +"train"+str(m+1)+".jpg"
os.rename(oldname,newname) #用os模块中的rename方法对文件改名
print(oldname,'======>',newname)
n+=1
m+=1或是下面代码(第一次做自己的数据用的就是这个代码)
from skimage import data_dir, io, transform, color
import numpy as np
import cv2
# def convert_gray(f):
# rgb = io.imread(f) # 依次读取rgb图片
# dst = transform.resize(rgb, (667, 500))
# return dst
#
# # 将灰度图片大小转换为256*256
data_dir='D:/pycharm/yolov5/VOCdata/VOCTest/old/'
str = data_dir + '/*.jpg'
coll = io.ImageCollection(str)
for i in range(len(coll)):
io.imsave('D:/pycharm/yolov5/VOCdata/VOCTest/JPEGImages/' + 'image_'+np.str(i+0) + '.jpg', coll[i]) # 循环保存图片
四、标记图片
使用Labelimg工具对图片进行标注,标注后会生成XML文件。
使用Labelimg工具标注过后的标签放进Annotations文件夹中
标签内容如下:

全部保存过后,如下所示:

五、创建ImageSets文件夹
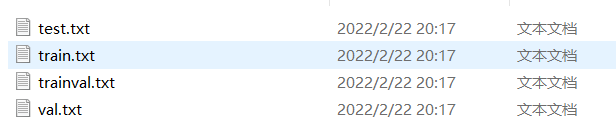
里面建立Main文件夹。存放的是图像物体识别的数据,有train.txt, val.txt ,trainval.txt.这三个文件(VOCTrainval文件夹下)或者test.txt 文件(VOCTest)。这几个文件我们后面会生成
六、划分训练集和测试集
训练时要有测试集和训练集,放在ImageSets\Main文件夹下。代码如下,至于训练验证集和测试集的划分比例,以及训练集和验证集的划分比例,根据自己的数据情况决定。使用下面的代码进行划分:
import os
import random
xmlfilepath = 'D:\pycharm/yolov5/VOCdata/VOCTest/Annotations/' # xml文件的路径
saveBasePath = 'D:\pycharm/yolov5/VOCdata/VOCTest/ImageSets/' # 生成的txt文件的保存路径
trainval_percent = 0.9 # 训练验证集占整个数据集的比重(划分训练集和测试验证集)
train_percent = 0.8 # 训练集占整个训练验证集的比重(划分训练集和验证集)
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
print("train and val size", tv)
print("traub suze", tr)
ftrainval = open(os.path.join(saveBasePath, 'Main/trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath, 'Main/test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath, 'Main/train.txt'), 'w')
fval = open(os.path.join(saveBasePath, 'Main/val.txt'), 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
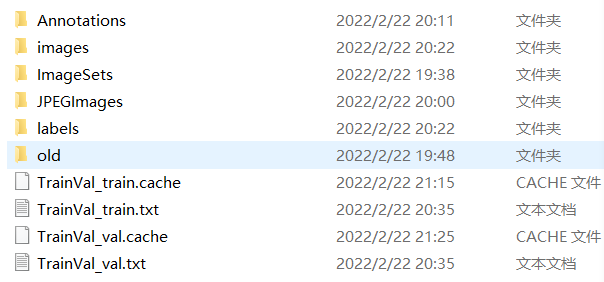
ftest.close()运行后,得到ImageSets\Main\文件下的几个.txt文件。
数据集制作完成。
七、将数据集转换到yolo数据集格式。
在VOCdata中新建一个voc_label.py文件,代码如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import shutil
sets=[('TrainVal', 'train'), ('TrainVal', 'val'), ('Test', 'test')]
classes = ['dog']
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_set, image_id):
in_file = open('VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOC%s/labels/%s_%s/%s.txt'%(year, year, image_set, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
def copy_images(year,image_set, image_id):
in_file = 'VOC%s/JPEGImages/%s.jpg'%(year, image_id)
out_flie = 'VOC%s/images/%s_%s/%s.jpg'%(year, year, image_set, image_id)
shutil.copy(in_file, out_flie)
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOC%s/labels/%s_%s'%(year,year, image_set)):
os.makedirs('VOC%s/labels/%s_%s'%(year,year, image_set))
if not os.path.exists('VOC%s/images/%s_%s'%(year,year, image_set)):
os.makedirs('VOC%s/images/%s_%s'%(year,year, image_set))
image_ids = open('VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('VOC%s/%s_%s.txt'%(year, year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOC%s/images/%s_%s/%s.jpg\n'%(wd, year, year, image_set, image_id))
convert_annotation(year, image_set, image_id)
copy_images(year, image_set, image_id)
list_file.close()转换后可以看到VOCData/VOCTrainval/和VOCData/VOCTest下生成了两个新的文件夹images和labels,以及相应的训练、验证、或测试的txt文件。
VOCTrainval文件夹结构如下:

VOCTest文件夹结构如下:

其中images和label文件夹下又有以相应的txt文件名命名的文件夹,里面存放了对应txt文件内容中的图片和标签信息。
八、修改配置文件
1、修改数据集方面的yaml文件
在data文件夹下创建myvoc.yaml文件
输入以下代码:
# 上面那三个txt文件的位置
train: ./VOCdata/VOCTrainVal/TrainVal_train.txt
val: ./VOCdata/VOCTrainVal/TrainVal_val.txt
test: ./VOCdata/VOCTest/Test_test.txt
# number of classes
nc: 4 # 修改为自己的类别数量
# class names
names: ["类别1", "类别2", "类别3", "类别4"] # 自己来的类别名称2、修改网络参数方面的yaml文件
这个相当于以前版本的.cfg文件,在models/yolov5s.yaml【当然,你想用哪个模型就去修改对应的yaml文件】,就修改一下类别数量:

3、修改train.py中的参数
parser.add_argument('--epochs', type=int, default=200) # 根据需要自行调节训练的epoch
parser.add_argument('--batch-size', type=int, default=8) # 根据自己的显卡调节,显卡不好的话,就调小点
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='*.cfg path') # 根据需要,自行选择模型
parser.add_argument('--data', type=str, default='data/myvoc.yaml', help='*.data path') # data设置为前两步中我们新建的myvoc.yaml
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='train,test sizes') # 可调可不调
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') # 使用CPU还是GPU训练九、训练
训练参数
opt参数解析:
cfg:模型配置文件,网络结构
data:数据集配置文件,数据集路径,类名等
hyp:超参数文件
epochs:训练总轮次
batch-size:批次大小
img-size:输入图片分辨率大小
rect:是否采用矩形训练,默认False
resume:接着打断训练上次的结果接着训练
nosave:不保存模型,默认False
notest:不进行test,默认False
noautoanchor:不自动调整anchor,默认False
evolve:是否进行超参数进化,默认False
bucket:谷歌云盘bucket,一般不会用到
cache-images:是否提前缓存图片到内存,以加快训练速度,默认False
weights:加载的权重文件
name:数据集名字,如果设置:results.txt to results_name.txt,默认无
device:训练的设备,cpu;0(表示一个gpu设备cuda:0);0,1,2,3(多个gpu设备)
multi-scale:是否进行多尺度训练,默认False
single-cls:数据集是否只有一个类别,默认False
adam:是否使用adam优化器
sync-bn:是否使用跨卡同步BN,在DDP模式使用
local_rank:gpu编号
logdir:存放日志的目录
workers:dataloader的最大worker数量