透视表pandas.pivot_table和交叉表pd.crosstab
# 透视表是一种可以对数据动态排布并且分类汇总的表格格式。
# 将指定原有DataFrame的列分别作为行索引和列索引,然后对指定的列应用聚集函数(默认情况下式mean函数)。
# pandas.pivot_table(data, values=None, index=None, columns=None,aggfunc=‘mean’, margins=False)
# data:[必须]需要操作数据 DataFrame
# values:要进行计算操作的列名 一个列名或列名组成的列表,不给代表对所有列操作
# index:[必须]分组后作为行索引的列名 一个列名或列名组成的列表
# columns:分组后作为行索引的列名 一个列名或列名组成的列表
# aggfunc:指定对values参数所给的列做什么计算操作,可以是字典(分别为不同的列指 定不同的计算操作),默认为mean
# margins:是否进行行汇总和列汇总
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
df = DataFrame({'类别':['水果','水果','水果','蔬菜','蔬菜','肉类','肉类'],
'产地':['美国','中国','中国','中国','新西兰','新西兰','美国'],
'水果':['苹果','梨','草莓','番茄','黄瓜','羊肉','牛肉'],
'数量':[5,5,9,3,2,10,8],
'价格':[5,5,10,3,3,13,20]})
df 
# :Index就是层次列,要通过透视表获取什么信息就按照相应的顺序设置列
# 我们没有指定需要计算的列,所以默认是对除了"index设定的列"之外的所有列进行计算,Values可以指定需要计算的列
# 按‘产地’和‘类别’重新索引,然后在‘价格’和‘数量’上执行mean函数
df.pivot_table(index=['产地','类别'])
# Columns类似Index可以设置列层次字段,它不是一个必要参数,作为一种分割数据的可选方式。
df.pivot_table(columns=['产地','类别'])# 行索引为‘产地’,列索引为‘类别’,对‘价格’应用‘max’函数,并提供分项统计,缺失值填充0
df.pivot_table('价格',index='产地',columns='类别',aggfunc='max',margins=True,fill_value=0) 
# 交叉表是用于统计分组频率的特殊透视表,统计词条出现频次
# crosstab本质:按照指定的index和columns统计数据帧中出现(index, columns)的频次。也可以理解为分组。crosstab()总是返回一个数据帧
pd.crosstab(df['类别'],df['产地'],margins=True) # 按类别分组,统计各个分组中产地的频数
pd.crosstab(df['类别'],df['产地'],values=df['价格'],aggfunc=np.max, margins=True).round(0)
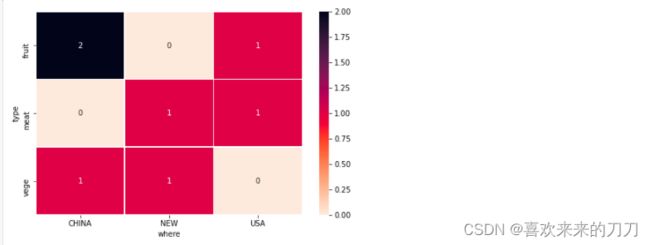
# seaborn可以自动将crosstab()表转换为热图。我将注释设置为True,并用颜色条显示热图。
# seaborn还为列和索引名添加了样式(fmt='g' 将数字显示为整数而不是科学计数)。
import matplotlib.pyplot as plt
import seaborn as sns
df1 = DataFrame({'type':['fruit','fruit','fruit','vege','vege','meat','meat'],
'where':['USA','CHINA','CHINA','CHINA','NEW','NEW','USA'],
'fruit':['apple','pear','atraw','tomato','cucum','mutton','beef'],
'num':[5,5,9,3,2,10,8],
'price':[5,5,10,3,3,13,20]})
cross1 = pd.crosstab(df1['type'],df1['where']).round(0)
sns.heatmap(cross1, cmap='rocket_r', annot=True, fmt='g')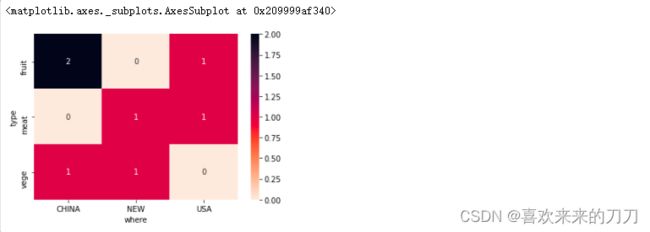
# 热图更容易解释。你不想让你的最终用户看到一张满是数字的表格。因此,我将在需要时将每个crosstab()结果放入热图中。
# 为了避免重复,我创建了一个有用的函数:
def plot_heatmap(cross_table, fmt='g'):
fig, ax = plt.subplots(figsize=(8, 5))
sns.heatmap(cross_table,
annot=True,
fmt=fmt,
cmap='rocket_r',
linewidths=.5,
ax=ax)
plt.show();
plot_heatmap(cross1)