深度学习:训练、验证,保存模型,加载模型,测试,代码-案例写法总结
目录
- 案例一:猫狗分类
-
- 定义训练+验证函数
- 调用函数
- 保存模型
- 测试模型
-
- 测试数据预处理
- 加载模型
- 可视化模型
- 案例二:交通指示牌4分类
-
- 定义训练函数
- 定义验证函数
- 训练函数
- 测试集评估
案例一:猫狗分类
参考:猫狗分类迁移学习案例详解
代码位置:E:\项目例程\猫狗分类\迁移学习\猫狗_resnet18_2 \猫狗分类_迁移学习可视化
定义训练+验证函数
#----训练模型-----
import copy
def train_model(model, criterion, optimizer, scheduler, num_epochs=10):
t1 = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
history = defaultdict(list) # 构建一个默认value为list的字典
for epoch in range(num_epochs):
lr = optimizer.param_groups[0]['lr']
print(
f'EPOCH: {epoch+1:0>{len(str(num_epochs))}}/{num_epochs}',
f'LR: {lr:.4f}',
end=' '
)
# 每轮都需要训练和评估
for phase in ['train', 'val']:
if phase == 'train':
model.train() # 将模型设置为训练模式
else:
model.eval() # 将模型设置为评估模式
running_loss = 0.0
running_corrects = 0
# 遍历数据
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# 梯度归零
optimizer.zero_grad()
# 前向传播
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
preds = outputs.argmax(1)
loss = criterion(outputs, labels)
# 反向传播+参数更新
if phase == 'train':
loss.backward()
optimizer.step()
# 统计
running_loss += loss.item() * inputs.size(0)
running_corrects += (preds == labels.data).sum()
if phase == 'train':
# 调整学习率
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
# 打印训练过程
if phase == 'train':
history['train_acc'].append(epoch_loss)
history['train_loss'].append(epoch_acc)
print(
f'LOSS: {epoch_loss:.4f}',
f'ACC: {epoch_acc:.4f} ',
end=' '
)
else:
history['val_acc'].append(epoch_loss)
history['val_loss'].append(epoch_acc)
print(
f'VAL-LOSS: {epoch_loss:.4f}',
f'VAL-ACC: {epoch_acc:.4f} ',
end='\n'
)
# 深度拷贝模型参数
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
t2 = time.time()
total_time = t2-t1
print('-'*10)
print(
f'TOTAL-TIME: {total_time//60:.0f}m{total_time%60:.0f}s',
f'BEST-VAL-ACC: {best_acc:.4f}'
)
# 加载最佳的模型权重
model.load_state_dict(best_model_wts)
return model, history
调用函数
# 调用训练函数训练
model_conv, history = train_model(
model_conv,
criterion,
optimizer_conv,
exp_lr_scheduler,
num_epochs=30
)
print("训练验证完毕")
保存模型
torch.save(model_conv.state_dict(), 'model.pt')
测试模型
百度或必应图片中随便找几张张蚂蚁和蜜蜂的图片,或者用手机拍几张照片也行。用上一步加载的模型测试一下分类的效果。
测试数据预处理
# 图片预处理
test_transforms = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor()
])
# 制作数据集
test_dataset = datasets.ImageFolder(
root='./test',
transform=test_transforms
)
# 数据加载器
test_loader = DataLoader(
dataset=test_dataset,
batch_size=4,
shuffle=False,
num_workers=0
)
加载模型
device = torch.device('cpu')
model = models.resnet18(pretrained=False)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, len(class_names))
model.load_state_dict(torch.load('model.pt', map_location=device))
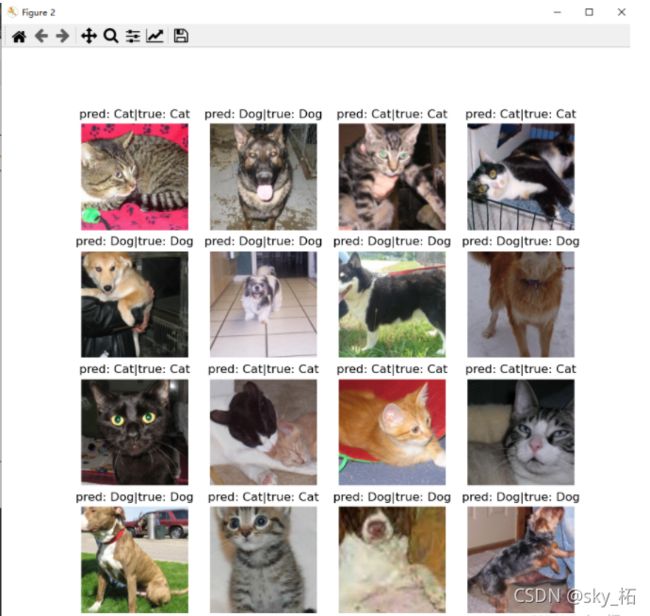
可视化模型
# 可视化函数
def visualize_model(model):
model.eval()
with torch.no_grad():
inputs, labels = next(iter(test_loader))
outputs = model(inputs)
preds = outputs.argmax(1)
plt.figure(figsize=(9, 9))
for i in range(inputs.size(0)):
plt.subplot(2, 2, i+1)
plt.axis('off')
plt.title(f'pred: {class_names[preds[i]]}|true: {class_names[labels[i]]}')
im = inputs[i].permute(1, 2, 0)
plt.imshow(im)
plt.savefig('old.jpg')
plt.show()
# 可视化结果
visualize_model(model)
案例二:交通指示牌4分类
参考:b站交通指示牌4分类迁移学习
代码位置:E:\项目例程\交通指示灯\迁移学习_交通道路识别\交通指示牌识别4分类_迁移学习
定义训练函数
# ----函数:训练 写法固定------
def train(model, data_loader, criterion, optimizer, device, scheduler, n_examples):
model.train()
train_loss = []
correct_pred = 0
for inputs, labels in data_loader: #一批批读取数据
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad() # 梯度置零
outputs = model(inputs) # 输出
loss = criterion(outputs, labels) # 计算损失
_, preds = torch.max(outputs, dim=1) # 获取到概率最大值的索引
correct_pred += torch.sum(preds == labels) # 累计正确数
train_loss.append(loss.item()) # 累计损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
scheduler.step() # 更新学习率
# 返回平均损失,平均准确率
return np.mean(train_loss), correct_pred.double()/n_examples
定义验证函数
# 函数:验证
def evaluation(model, data_loader, criterion, device, n_examples):
model.eval()
eval_loss = []
correct_pred = 0
with torch.no_grad():
for inputs, labels in data_loader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs) #输出
loss = criterion(outputs, labels) # 损失
_, preds = torch.max(outputs, dim=1) # 获取到概率最大值的索引
correct_pred += torch.sum(preds == labels) # 累计正确数
eval_loss.append(loss.item()) # 累计损失
return np.mean(eval_loss), correct_pred.double() / n_examples
训练函数
在这个函数里调用前两个函数
# 函数:开始训练
def train_model(model, data_loader, dataset_size, device, n_epochs=10):
# 优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 动态学习率
scheduler = lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
# 损失函数
criterion = nn.CrossEntropyLoss().to(device)
# 假设最好的accuracy, history
best_accuracy = 0.0
history = defaultdict(list) # 构建一个默认value为list的字典
for epoch in range(n_epochs):
print(f'Epoch : {epoch + 1} / {n_epochs}')
print('-' * 20)
train_loss, train_accuracy = train(model, data_loader['train'], criterion, optimizer, device,
scheduler, dataset_size['train'])
print(f'Train Loss : {train_loss}, Train accuracy : {train_accuracy}')
val_loss, val_accuracy = evaluation(model, data_loader['val'], criterion, device, dataset_size['val'])
print(f'Val loss : {val_loss}, val accuracy : {val_accuracy}')
# 保存所有结果
history['train_acc'].append(train_accuracy)
history['train_loss'].append(train_loss)
history['val_acc'].append(val_accuracy)
history['val_loss'].append(val_loss)
if val_accuracy > best_accuracy:
# 保存最佳模型
torch.save(model.state_dict(), 'best_model_state_2.pkl')
# 最好得分
best_accuracy = val_accuracy
print(f'Best Accuracy : {best_accuracy}')
# 加载模型
model.load_state_dict(torch.load("best_model_state_2.pkl"))
return model, history
best_model, history = train_model(clf_model, data_loaders, dataset_size, device)
测试集评估
不如案例一的写法
# 在test集上评估
def show_predictions(model, class_names, n_imgs=6):
model.eval()
images_handled = 0
plt.figure()
with torch.no_grad():
my_font = FontProperties(fname='SimHei.ttf', size=12)
for i, (inputs, labels) in enumerate(data_loaders['test']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, dim=1)
for j in range(inputs.shape[0]):
images_handled += 1
ax = plt.subplot(2, n_imgs // 2, images_handled)
ax.set_title(f'predicted : {class_names[preds[j]]}', fontproperties=my_font)
imshow(inputs.cpu().data[j])
ax.axis('off')
if images_handled == n_imgs:
return
show_predictions(best_model, class_names, n_imgs=8)