Hive3入门至精通(基础、部署、理论、SQL、函数、运算以及性能优化)1-14章
Hive3入门至精通(基础、部署、理论、SQL、函数、运算以及性能优化)1-14章
Hive3入门至精通(基础、部署、理论、SQL、函数、运算以及性能优化)15-28章
第1章:数据仓库基础理论
1-1.数据仓库概念
数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。
数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持(Decision Support)。
- 数据仓库本身并不“生产”任何数据,其数据来源于不同外部系统
- 同时数据仓库自身也不需要“消费”任何的数据,其结果开放给各个外部应用使用
- 这也是为什么叫“数据仓库”,而不叫“数据工厂”的原因

1-2.场景案例:数据仓库由来
数据仓库为了分析数据而来,分析结果给企业决策提供支撑。
企业中,信息数据总是用作两个目的:
(1)操作型记录的保存
(2)分析型决策的制定
操作型记录的保存
- 中国人寿保险(集团)公司下辖多条业务线,包括:人寿险、财险、车险,养老险等。各业务线的业务正常运营需要记录维护包括客户、保单、收付费、核保、理赔等信息。
- 联机事务处理系统(OLTP)正好可以满足上述业务需求开展, 其主要任务是执行联机事务处理。其基本特征是前台接收的用户数据可以立即传送到后台进行处理,并在很短的时间内给出处理结果。
- 关系型数据库(RDBMS)是OLTP典型应用,比如:Oracle、MySQL、SQL Server等
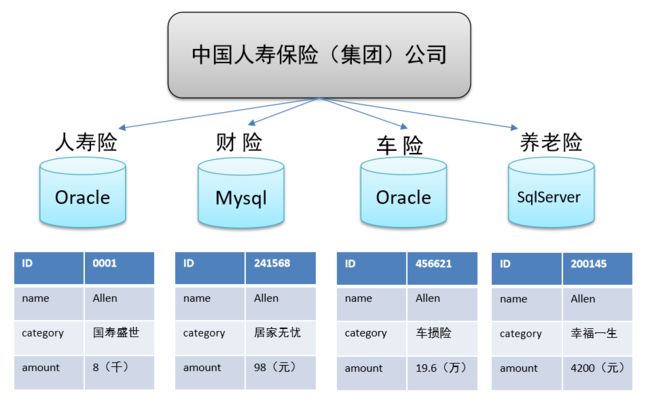
分析型决策的制定
随着集团业务的持续运营,业务数据将会越来越多。由此也产生出许多运营相关的困惑:
能够确定哪些险种正在恶化或已成为不良险种?
能够用有效的方式制定新增和续保的政策吗?
理赔过程有欺诈的可能吗?
现在得到的报表是否只是某条业务线的?集团整体层面数据如何?
…
为了能够正确认识这些问题,最稳妥办法就是:基于业务数据开展数据分析,基于分析的结果给决策提供支撑。也就是所谓的数据驱动决策的制定
OLTP环境开展数据分析可行性
-
OLTP系统的核心是面向业务,支持业务,支持事务。所有的业务操作可以分为读、写两种操作,一般来说读的压力明显大于写的压力。如果在OLTP环境直接开展各种分析,有以下问题需要考虑:
- 数据分析也是对数据进行读取操作,会让读取压力倍增;
- OLTP仅存储数周或数月的数据;
- 数据分散在不同系统不同表中,字段类型属性不统一;
-
当分析所涉及数据规模较小的时候,在业务低峰期时可以在OLTP系统上开展直接分析。但是为了更好的进行各种规模的数据分析,同时也不影响OLTP系统运行,此时需要构建一个集成统一的数据分析平台。
-
该平台的目的很简单:面向分析,支持分析,并且和OLTP系统解耦合。
-
基于这种需求,数据仓库的雏形开始在企业中出现了
数据仓库的构建
- 如数仓定义所说,数仓是一个用于存储、分析、报告的数据系统,目的是构建面向分析的集成化数据环境。我们把这种面向分析、支持分析的系统称之为OLAP(联机分析处理)系统,数据仓库是OLAP一种。
- 中国人寿保险公司就可以基于分析决策需求,构建数仓平台。
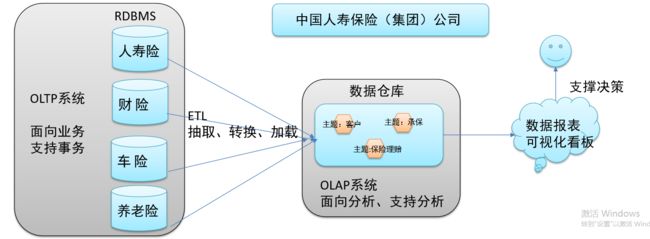
1-3.数据仓库主要特征
- 数据仓库目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持(Decision Support)。
- 数据仓库本身并不“生产”任何数据,其数据来源于不同外部系统;
- 数据仓库自身也不需要“消费”任何的数据,其结果开放给各个外部应用使用;
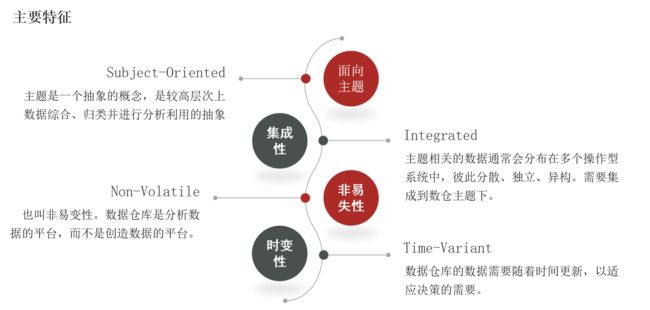
面向主题
- 数据库中,最大的特点是面向应用进行数据的组织,各个业务系统可能是相互分离的。
- 而数据仓库则是面向主题的。主题是一个抽象的概念,是较高层次上企业信息系统中的数据综合、归类并进行分析利用的抽象。在逻辑意义上,它是对应企业中某一宏观分析领域所涉及的分析对象。
- 操作型处理(传统数据)对数据的划分并不适用于决策分析。而基于主题组织的数据则不同,它们被划分为各自独立的领域,每个领域有各自的逻辑内涵但互不交叉,在抽象层次上对数据进行完整、一致和准确的描述。
集成性
- 确定主题之后,就需要获取和主题相关的数据。当下企业中主题相关的数据通常会分布在多个操作型系统中,彼此分散、独立、异构。
- 在数据进入数据仓库之前,必然要经过统一与综合,对数据进行抽取、清理、转换和汇总,这一步是数据仓库建设中最关键、最复杂的一步,所要完成的工作有:
- 要统一源数据中所有矛盾之处,如字段的同名异义、异名同义、单位不统一、字长不一致,等等。
- 进行数据综合和计算。数据仓库中的数据综合工作可以在从原有数据库抽取数据时生成,但许多是在数据仓库内部生成的,即进入数据仓库以后进行综合生成的。
下图说明了保险公司综合数据的简单处理过程,其中数据仓库中与“承保”主题有关的数据来自于多个不同的操作型系统。这些系统内部数据的命名可能不同,数据格式也可能不同。把不同来源的数据存储到数据仓库之前,需要去除这些不一致
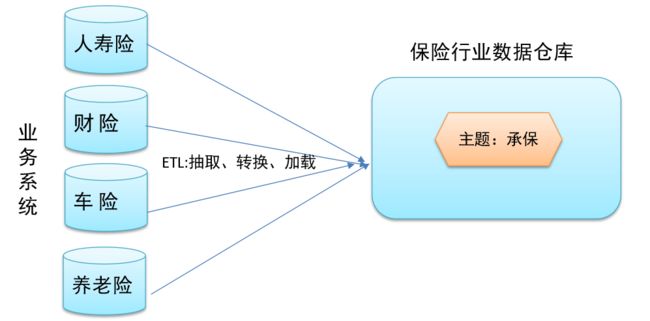
非易失性
- 数据仓库是分析数据的平台,而不是创造数据的平台。我们是通过数仓去分析数据中的规律,而不是去创造修改其中的规律。因此数据进入数据仓库后,它便稳定且不会改变。
- 操作型数据库主要服务于日常的业务操作,使得数据库需要不断地对数据实时更新,以便迅速获得当前最新数据,不至于影响正常的业务运作。在数据仓库中只要保存过去的业务数据,不需要每一笔业务都实时更新数据仓库,而是根据商业需要每隔一段时间把一批较新的数据导入数据仓库。
- 数据仓库的数据反映的是一段相当长的时间内历史数据的内容,是不同时点的数据库快照的集合,以及基于这些快照进行统计、综合和重组的导出数据。
- 数据仓库的用户对数据的操作大多是数据查询或比较复杂的挖掘,一旦数据进入数据仓库以后,一般情况下被较长时间保留。数据仓库中一般有大量的查询操作,但修改和删除操作很少。
时变性
- 数据仓库包含各种粒度的历史数据,数据可能与某个特定日期、星期、月份、季度或者年份有关。
- 数据仓库的用户不能修改数据,但并不是说数据仓库的数据是永远不变的。分析的结果只能反映过去的情况,当业务变化后,挖掘出的模式会失去时效性。因此数据仓库的数据需要随着时间更新,以适应决策的需要。从这个角度讲,数据仓库建设是一个项目,更是一个过程 。
- 数据仓库的数据随时间的变化表现在以下几个方面。
- 数据仓库的数据时限一般要远远长于操作型数据的数据时限。
- 操作型系统存储的是当前数据,而数据仓库中的数据是历史数据。
- 数据仓库中的数据是按照时间顺序追加的,它们都带有时间属性。
1-4.数据仓库、数据库、数据集市
OLTP、OLAP
联机事务处理 OLTP(On-Line Transaction Processing)。
联机分析处理 OLAP(On-Line Analytical Processing)。
OLTP
- 操作型处理,叫联机事务处理OLTP(On-Line Transaction Processing),主要目标是做数据处理,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。
- 用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。
- 传统的关系型数据库系统(RDBMS)作为数据管理的主要手段,主要用于操作型处理。
OLAP
- 分析型处理,叫联机分析处理OLAP(On-Line Analytical Processing),主要目标是做数据分析。
- 一般针对某些主题的历史数据进行复杂的多维分析,支持管理决策。
- 数据仓库是OLAP系统的一个典型示例,主要用于数据分析。
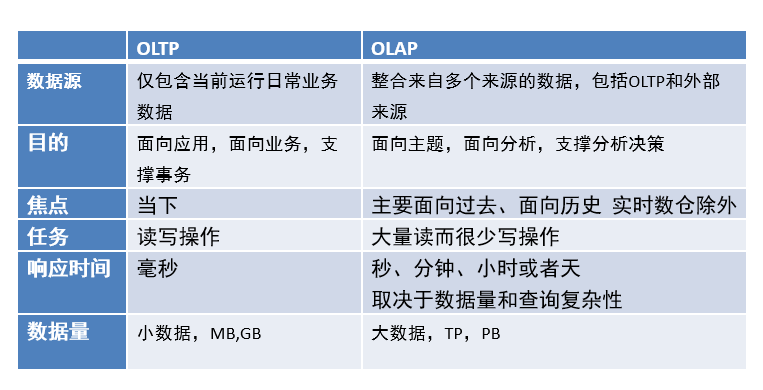
数据仓库、数据库区别
- 数据库与数据仓库的区别实际讲的是OLTP与OLAP的区别。
- OLTP系统的典型应用就是RDBMS,也就是我们俗称的数据库,当然这里要特别强调此数据库表示的是关系型数据库,Nosql数据库并不在讨论范围内。
- OLAP系统的典型应用就是DW,也就是我们俗称的数据仓库。
- 数据仓库不是大型的数据库,虽然数据仓库存储数据规模大。
- 数据仓库的出现,并不是要取代数据库。
- 数据库是面向事务的设计,数据仓库是面向主题设计的。
- 数据库一般存储业务数据,数据仓库存储的一般是历史数据。
- 数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
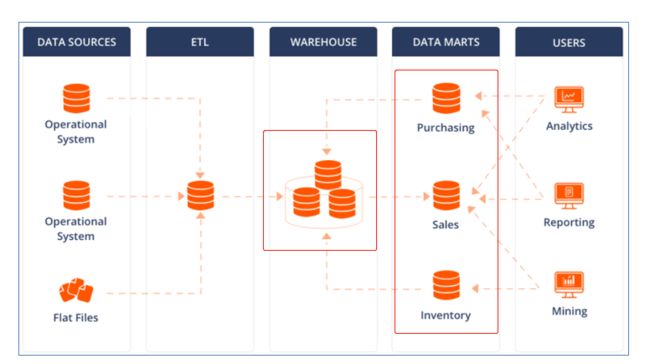
数据仓库、数据集市区别
- 数据仓库(Data Warehouse)是面向整个集团组织的数据,数据集市( Data Mart ) 是面向单个部门使用的。
- 可以认为数据集市是数据仓库的子集,也有把数据集市叫做小型数据仓库。数据集市通常只涉及一个主题领域,例如市场营销或销售。因为它们较小且更具体,所以它们通常更易于管理和维护,并具有更灵活的结构。
- 下图中,各种操作型系统数据和包括文件在内的等其他数据作为数据源,经过ETL(抽取转换加载)填充到数据仓库中;数据仓库中有不同主题数据,数据集市则根据部门特点面向指定主题,比如Purchasing(采购)、Sales(销售)、Inventory(库存);
- 用户可以基于主题数据开展各种应用:数据分析、数据报表、数据挖掘。
1-5.数据仓库分层架构
分层思想和标准
- 数据仓库的特点是本身不生产数据,也不最终消费数据。按照数据流入流出数仓的过程进行分层就显得水到渠成。
- 每个企业根据自己的业务需求可以分成不同的层次。但是最基础的分层思想,理论上分为三个层:操作型数据层(ODS)、数据仓库层(DW)和数据应用层(DA)。
- 企业在实际运用中可以基于这个基础分层之上添加新的层次,来满足不同的业务需求

阿里巴巴数仓3层架构介绍
为了更好的理解数据仓库分层的思想以及每层的功能意义,下面结合阿里巴巴提供出的数仓分层架构图进行分析。
阿里数仓是非常经典的3层架构,从下往上依次是:ODS、DW、DA。
通过元数据管理和数据质量监控来把控整个数仓中数据的流转过程、血缘依赖关系和生命周期。
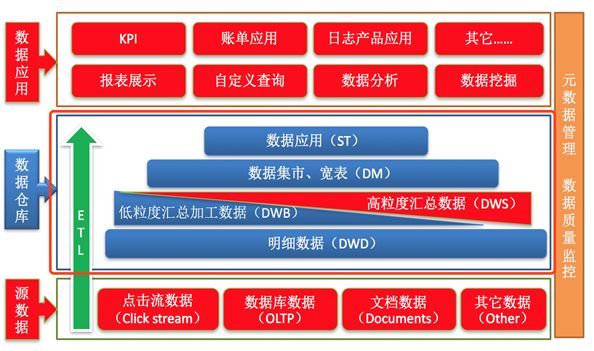
ODS层(Operation Data Store)
- 操作型数据层,也称之为源数据层、数据引入层、数据暂存层、临时缓存层。
- 此层存放未经过处理的原始数据至数据仓库系统,结构上与源系统保持一致,是数据仓库的数据准备区。
- 主要完成基础数据引入到数仓的职责,和数据源系统进行解耦合,同时记录基础数据的历史变化。
DW层(Data Warehouse)
- 数据仓库层,由ODS层数据加工而成。主要完成数据加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标。内部具体划分如下:
- 公共维度层(DIM):基于维度建模理念思想,建立整个企业一致性维度。
- 公共汇总粒度事实层(DWS、DWB):以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表,以宽表化手段物理化模型
- 明细粒度事实层(DWD): 将明细事实表的某些重要维度属性字段做适当冗余,即宽表化处理。
DA层(或ADS层)
数据应用层,面向最终用户,面向业务定制提供给产品和数据分析使用的数据。
包括前端报表、分析图表、KPI、仪表盘、OLAP专题、数据挖掘等分析。
数据仓库分层优点
- 清晰数据结构
- 每一个数据分层都有它的作用域,在使用表的时候能更方便地定位和理解。
- 数据血缘追踪
- 简单来说,我们最终给业务呈现的是一个能直接使用业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
- 减少重复开发
- 规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
- 把复杂问题简单化
- 将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
- 屏蔽原始数据的异常
- 屏蔽业务的影响,不必改一次业务就需要重新接入数据
ETL、ELT区别
数据仓库从各数据源获取数据及在数据仓库内的数据转换和流动都可以认为是ETL(抽取Extra, 转化Transfer, 装载Load)的过程。
但是在实际操作中将数据加载到仓库却产生了两种不同做法:ETL和ELT。
ETL
Extract,Transform,Load ETL
首先从数据源池中提取数据,这些数据源通常是事务性数据库。数据保存在临时暂存数据库中(ODS)。然后执行转换操作,将数据结构化并转换为适合目标数据仓库系统的形式。然后将结构化数据加载到仓库中,以备分析。
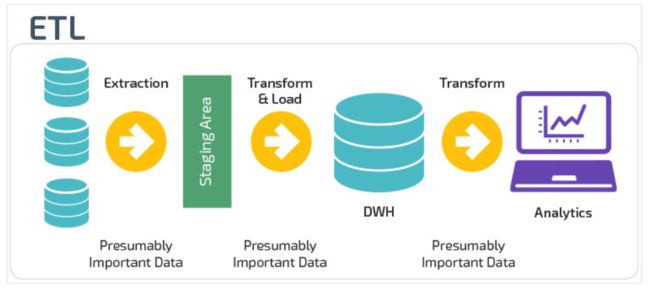
ELT
Extract,Load,Transform ELT
使用ELT,数据在从源数据池中提取后立即加载。没有专门的临时数据库(ODS),这意味着数据会立即加载到单一的集中存储库中。数据在数据仓库系统中进行转换,以便与商业智能工具(BI工具)一起使用。大数据时代的数仓这个特点很明显。

第2章:Apache Hive入门
2-1.Apache Hive概述
什么是Hive
- Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
- Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行。
- Hive由Facebook实现并开源。
为什么使用Hive
- 使用Hadoop MapReduce直接处理数据所面临的问题
- 人员学习成本太高,需要掌握java语言
- MapReduce实现复杂查询逻辑开发难度太大
- 使用Hive处理数据的好处
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
- 避免直接写MapReduce,减少开发人员的学习成本
- 支持自定义函数,功能扩展很方便
- 背靠Hadoop,擅长存储分析海量数据集
Hive和Hadoop关系
- 从功能来说,数据仓库软件,至少需要具备下述两种能力:
- 存储数据的能力
- 分析数据的能力
- Apache Hive作为一款大数据时代的数据仓库软件,当然也具备上述两种能力。只不过Hive并不是自己实现了上述两种能力,而是借助Hadoop。
- Hive利用Hadoop的HDFS存储数据,利用Hadoop的MapReduce查询分析数据。
- 这样突然发现Hive没啥用,不过是套壳Hadoop罢了。其实不然,Hive的最大的魅力在于用户专注于编写HQL,Hive帮您转换成为MapReduce程序完成对数据的分析。
2-2.Apache Hive架构、组件
Hive架构图
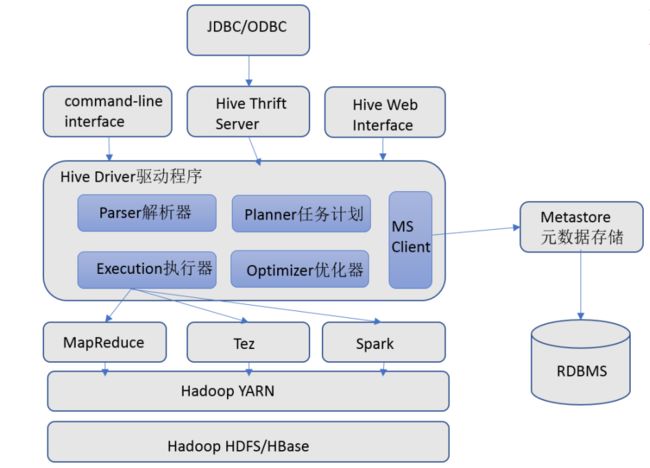
Hive组件
用户接口
包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive
元数据存储
通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
Driver驱动程序
包括语法解析器、计划编译器、优化器、执行器
完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有执行引擎调用执行
执行引擎
Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark3种执行引擎
2-3.Apache Hive数据模型
Data Model概念
- 数据模型:用来描述数据、组织数据和对数据进行操作,是对现实世界数据特征的描述。、
- Hive的数据模型类似于RDBMS库表结构,此外还有自己特有模型。
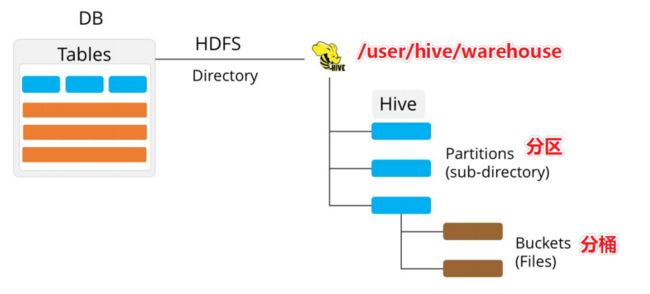
- Hive中的数据可以在粒度级别上分为三类:
- Table 表
- Partition 分区
- Bucket 分桶
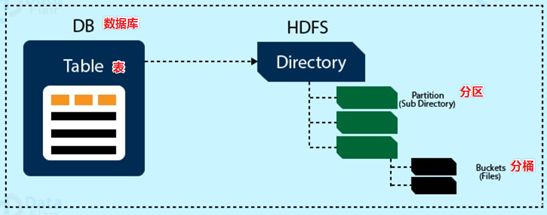
Databases 数据库
- Hive作为一个数据仓库,在结构上积极向传统数据库看齐,也分数据库(Schema),每个数据库下面有各自的表组成。默认数据库default。
- Hive的数据都是存储在HDFS上的,默认有一个根目录,在hive-site.xml中,由参数hive.metastore.warehouse.dir指定。默认值为/user/hive/warehouse。
- 因此,如果没有设置特定路径,那么Hive中的数据库在HDFS上的存储路径为:/user/hive/warehouse/databasename.db
Tables 表
- Hive表与关系数据库中的表相同。Hive中的表所对应的数据通常是存储在HDFS中,而表相关的元数据是存储在RDBMS中。
- Hive中的表的数据在HDFS上的存储路径为:/user/hive/warehouse/databasename.db/tablename
Partitions 分区
- Partition分区是hive的一种优化手段表。分区是指根据分区列(例如“日期day”)的值将表划分为不同分区。这样可以更快地对指定分区数据进行查询。
- 分区在存储层面上的表现是:table表目录下以子文件夹形式存在。
- 一个文件夹表示一个分区。子文件命名标准:分区列=分区值
- Hive还支持分区下继续创建分区,所谓的多重分区。关于分区表的使用和详细介绍,后面模块会单独展开。
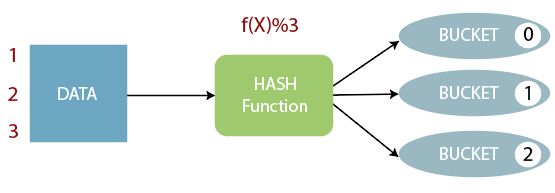
Buckets 分桶
- Bucket分桶表是hive的一种优化手段表。分桶是指根据表中字段(例如“编号ID”)的值,经过hash计算规则将数据文件划分成指定的若干个小文件。
- 分桶规则:hashfunc(字段) % 桶个数,余数相同的分到同一个文件。
- 分桶的好处是可以优化join查询和方便抽样查询。
- Bucket分桶表在HDFS中表现为同一个表目录下数据根据hash散列之后变成多个文件。
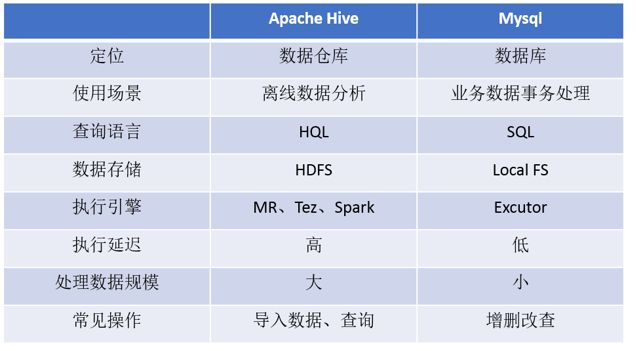
2-4.Apache Hive能否取代MySQL
- Hive虽然具有RDBMS数据库的外表,包括数据模型、SQL语法都十分相似,但hive应用场景和MySQL却完全不同。
- Hive只适合用来做海量数据的离线分析。Hive的定位是数据仓库,面向分析的OLAP系统。
- Hive不是大型数据库,也无法取代MySQL承担业务数据处理。
第3章:Apache Hive安装部署
3-1.Apache Hive 元数据
什么是元数据
元数据(Metadata),又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
Hive Metadata
- Hive Metadata即Hive的元数据。
- 包含用Hive创建的database、table、表的位置、类型、属性,字段顺序类型等元信息。
- 元数据存储在关系型数据库中。如hive内置的Derby、或者第三方如MySQL等。
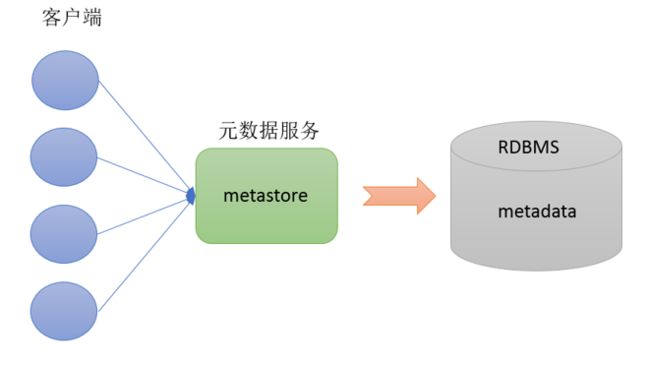
Hive Metastore
- Metastore即元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据。
- 有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。某种程度上也保证了hive元数据的安全。
3-2.metastore三种配置方式
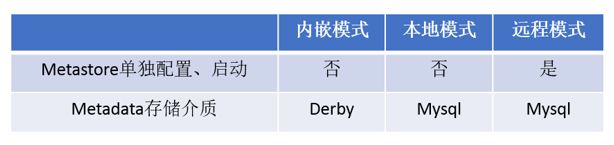
metastore服务配置有3种模式:内嵌模式、本地模式、远程模式。
区分3种配置方式的关键是弄清楚两个问题:
Metastore服务是否需要单独配置、单独启动?
Metadata是存储在内置的derby中,还是第三方RDBMS,比如MySQL。
内嵌模式
- 内嵌模式(Embedded Metastore)是metastore默认部署模式。
- 内嵌模式模式下,元数据存储在内置的Derby数据库,并且Derby数据库和metastore服务都嵌入在主HiveServer进程中,当启动HiveServer进程时,Derby和metastore都会启动。不需要额外起Metastore服务。
- 但是一次只能支持一个活动用户,仅仅适用于调试和测试体验,不适用于生产环境。
本地模式
- 本地模式(Local Metastore)下,Metastore服务与主HiveServer进程在同一进程中运行,但是存储元数据的数据库在单独的进程中运行,并且可以在单独的主机上。metastore服务将通过JDBC与metastore数据库进行通信。
- 本地模式采用外部数据库来存储元数据,推荐使用MySQL。
- hive根据hive.metastore.uris参数值来判断,如果为空,则为本地模式。
- 本地模式缺点是:每启动一次hive服务,都内置启动了一个metastore。
远程模式
- 远程模式(Remote Metastore)下,Metastore服务在其自己的单独JVM上运行,而不在HiveServer的JVM中运行。如果其他进程希望与Metastore服务器通信,则可以使用Thrift Network API进行通信。
- 远程模式下,需要配置hive.metastore.uris 参数来指定metastore服务运行的机器ip和端口,并且需要单独手动启动metastore服务。元数据也采用外部数据库来存储元数据,推荐使用MySQL。
- 在生产环境中,建议用远程模式来配置Hive Metastore。在这种情况下,其他依赖hive的软件都可以通过Metastore访问hive。由于还可以完全屏蔽数据库层,因此这也带来了更好的可管理性/安全性。
3-3.Apache Hive部署实战
安装前环境准备
- 由于Apache Hive是一款基于Hadoop的数据仓库软件,通常部署运行在Linux系统之上。因此不管使用何种方式配置Hive Metastore,必须要先保证服务器的基础环境正常,Hadoop集群健康可用。
- 服务器基础环境
集群时间同步、防火墙关闭、主机Host映射、免密登录、JDK安装 - Hadoop集群健康可用
启动Hive之前必须先启动Hadoop集群。特别要注意,需等待HDFS安全模式关闭之后再启动运行Hive。
Hive不是分布式安装运行的软件,其分布式的特性主要借由Hadoop完成。包括分布式存储、分布式计算。
如果还没有hadoop集群可以参考另一篇hadoop文章进行准备:
hadoop集群准备
搭建部署hadoop集群
https://blog.csdn.net/wt334502157/article/details/114916871
已有hadoop集群则可以直接进行hive的安装部署
hive3安装部署
hive安装部署
https://blog.csdn.net/wt334502157/article/details/115419462
由于篇幅原因,hive3.1.2的详细安装部署步骤可以参考hive安装部署文章
本篇幅会讲重要点标注
[注意] hive安装详解文档中附带了安装包的网盘分享:
Hive部署所有依赖包和安装包网盘链接
链接:https://pan.baidu.com/s/1kPr0uTEXqslxZ3v_r-uLQQ
提取码:bi8x
按照部署文档中步骤:
- 上传安装包
- MySQL安装
- MySQL配置
- hive安装
- 配置Metastore到MySql
- 修改hadoop环境变量
- 解决jar包冲突
- 启动hive(启动前处理guava的jar包冲突)
3-4.Apache Hive客户端使用
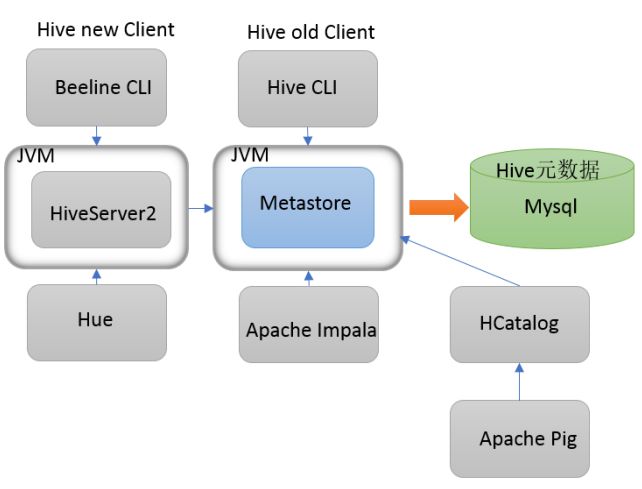
bin/hive和bin/beeline
Hive发展至今,总共历经了两代客户端工具。
- 第一代客户端(deprecated不推荐使用):$HIVE_HOME/bin/hive, 是一个 shellUtil。主要功能:一是可用于以交互或批处理模式运行Hive查询;二是用于Hive相关服务的启动,比如metastore服务。
- 第二代客户端(recommended 推荐使用):$HIVE_HOME/bin/beeline,是一个JDBC客户端,是官方强烈推荐使用的Hive命令行工具,和第一代客户端相比,性能加强安全性提高。
远程模式下beeline通过 Thrift 连接到单独的 HiveServer2服务上,这也是官方推荐在生产环境中使用的模式
bin/hive客户端
- 在hive安装包的bin目录下,有hive提供的第一代客户端 bin/hive。该客户端可以访问hive的metastore服务,从而达到操作hive的目的。
- 需要启动运行metastore服务。
- 可以直接在启动Hive metastore服务的机器上使用bin/hive客户端操作,此时不需要进行任何配置。
bin/beeline客户端
- hive经过发展,推出了第二代客户端beeline,但是beeline客户端不是直接访问metastore服务的,而是需要单独启动hiveserver2服务
- 在hive安装的服务器上,首先启动metastore服务,然后启动hiveserver2服务
- Beeline是JDBC的客户端,通过JDBC协议和Hiveserver2服务进行通信,协议的地址是:jdbc:hive2://ip:port
wangting@ops02:/home/wangting >beeline -u jdbc:hive2://ops01:10000 -n wangting
Connecting to jdbc:hive2://ops01:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
0: jdbc:hive2://ops01:10000> show databases;
+--------------------+
| database_name |
+--------------------+
| db_hive |
| default |
| hvprd_ads |
| hvprd_base |
| hvprd_basedb |
| hvprd_cdm |
| hvprd_cln |
| hvprd_ods |
| hvprd_stg |
| hvprd_tmp |
| hvprd_udl |
| test |
+--------------------+
13 rows selected (0.166 seconds)
0: jdbc:hive2://ops01:10000>
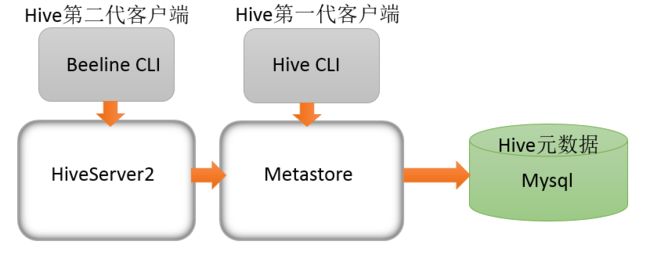
HiveServer和HiveServer2服务
- HiveServer、HiveServer2都是Hive自带的两种服务,允许客户端在不启动CLI(命令行)的情况下对Hive中的数据进行操作,且两个都允许远程客户端使用多种编程语言如java,python等向hive提交请求,取回结果。
- HiveServer不能处理多于一个客户端的并发请求。因此在Hive-0.11.0版本中重写了HiveServer代码得到了HiveServer2,进而解决了该问题。HiveServer已经被废弃。
- HiveServer2支持多客户端的并发和身份认证,旨在为开放API客户端如JDBC、ODBC提供更好的支持。
Hive服务和客户端
- HiveServer2通过Metastore服务读写元数据。所以在远程模式下,启动HiveServer2之前必须先首先启动metastore服务
- 远程模式下,Beeline客户端只能通过HiveServer2服务访问Hive。而bin/hive是通过Metastore服务访问
第4章:场景案例:Apache Hive初体验
4-1.体验1:Hive使用和MySQL对比
按照MySQL的思维,在hive中创建、切换数据库,创建表并执行插入数据操作,最后查询是否插入成功
通过beeline登录hive
# 通过beeline登录hive
wangting@ops02:/home/wangting >beeline -u jdbc:hive2://ops01:10000 -n wangting
Connecting to jdbc:hive2://ops01:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
创建一个库
# 创建hv_2022_10_13库
0: jdbc:hive2://ops01:10000> create database hv_2022_10_13;
INFO : Compiling command(queryId=wangting_20221013160018_4a1ad7d6-b66b-4e9d-b7e9-e6f602e24e5e): create database hv_2022_10_13
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=wangting_20221013160018_4a1ad7d6-b66b-4e9d-b7e9-e6f602e24e5e); Time taken: 0.043 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20221013160018_4a1ad7d6-b66b-4e9d-b7e9-e6f602e24e5e): create database hv_2022_10_13
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=wangting_20221013160018_4a1ad7d6-b66b-4e9d-b7e9-e6f602e24e5e); Time taken: 0.034 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.133 seconds)
查看数据库
# 查看数据库
0: jdbc:hive2://ops01:10000> show databases like '*2022*';
INFO : Compiling command(queryId=wangting_20221013160105_5dfea58b-e0df-4354-b7c1-33115306e2ea): show databases like '*2022*'
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=wangting_20221013160105_5dfea58b-e0df-4354-b7c1-33115306e2ea); Time taken: 0.014 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20221013160105_5dfea58b-e0df-4354-b7c1-33115306e2ea): show databases like '*2022*'
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=wangting_20221013160105_5dfea58b-e0df-4354-b7c1-33115306e2ea); Time taken: 0.005 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+----------------+
| database_name |
+----------------+
| hv_2022_10_13 |
+----------------+
1 row selected (0.031 seconds)
进入数据库
# 进入数据库
0: jdbc:hive2://ops01:10000> use hv_2022_10_13;
INFO : Compiling command(queryId=wangting_20221013160126_1e501f53-09ee-4baf-8ef5-8e63079ea4eb): use hv_2022_10_13
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=wangting_20221013160126_1e501f53-09ee-4baf-8ef5-8e63079ea4eb); Time taken: 0.016 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20221013160126_1e501f53-09ee-4baf-8ef5-8e63079ea4eb): use hv_2022_10_13
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=wangting_20221013160126_1e501f53-09ee-4baf-8ef5-8e63079ea4eb); Time taken: 0.004 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.031 seconds)
建表
# 建表
0: jdbc:hive2://ops01:10000> create table t_student(id int,name varchar(255));
INFO : Compiling command(queryId=wangting_20221013160614_888f8325-7559-4a1a-ae0b-a58f81d42b78): create table t_student(id int,name varchar(255))
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=wangting_20221013160614_888f8325-7559-4a1a-ae0b-a58f81d42b78); Time taken: 0.017 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20221013160614_888f8325-7559-4a1a-ae0b-a58f81d42b78): create table t_student(id int,name varchar(255))
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=wangting_20221013160614_888f8325-7559-4a1a-ae0b-a58f81d42b78); Time taken: 0.073 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.098 seconds)
表中插入一条数据
# 插入一条数据
0: jdbc:hive2://ops01:10000> insert into table t_student values(1,"allen");
INFO : Compiling command(queryId=wangting_20221013160708_4f681b20-e521-4c4e-8fce-c1b7a68a8c9b): insert into table t_student values(1,"allen")
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_col0, type:int, comment:null), FieldSchema(name:_col1, type:varchar(255), comment:null)], properties:null)
INFO : Completed compiling command(queryId=wangting_20221013160708_4f681b20-e521-4c4e-8fce-c1b7a68a8c9b); Time taken: 0.233 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20221013160708_4f681b20-e521-4c4e-8fce-c1b7a68a8c9b): insert into table t_student values(1,"allen")
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
INFO : Query ID = wangting_20221013160708_4f681b20-e521-4c4e-8fce-c1b7a68a8c9b
INFO : Total jobs = 3
INFO : Launching Job 1 out of 3
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1615531413182_10785
INFO : Executing with tokens: []
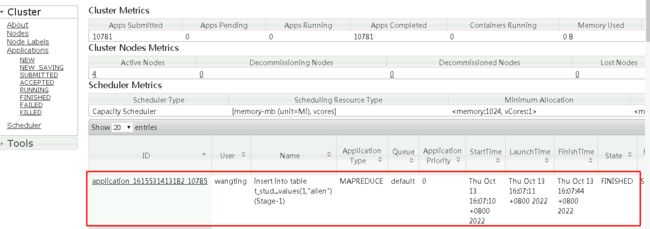
INFO : The url to track the job: http://ops02:8088/proxy/application_1615531413182_10785/
INFO : Starting Job = job_1615531413182_10785, Tracking URL = http://ops02:8088/proxy/application_1615531413182_10785/
INFO : Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1615531413182_10785
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2022-10-13 16:07:20,125 Stage-1 map = 0%, reduce = 0%
INFO : 2022-10-13 16:07:28,336 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.46 sec
INFO : 2022-10-13 16:07:44,683 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 7.37 sec
INFO : MapReduce Total cumulative CPU time: 7 seconds 370 msec
INFO : Ended Job = job_1615531413182_10785
INFO : Starting task [Stage-7:CONDITIONAL] in serial mode
INFO : Stage-4 is selected by condition resolver.
INFO : Stage-3 is filtered out by condition resolver.
INFO : Stage-5 is filtered out by condition resolver.
INFO : Starting task [Stage-4:MOVE] in serial mode
INFO : Moving data to directory hdfs://ops01:8020/user/hive/warehouse/hv_2022_10_13.db/t_student/.hive-staging_hive_2022-10-13_16-07-08_795_1543917524199913194-6/-ext-10000 from hdfs://ops01:8020/user/hive/warehouse/hv_2022_10_13.db/t_student/.hive-staging_hive_2022-10-13_16-07-08_795_1543917524199913194-6/-ext-10002
INFO : Starting task [Stage-0:MOVE] in serial mode
INFO : Loading data to table hv_2022_10_13.t_student from hdfs://ops01:8020/user/hive/warehouse/hv_2022_10_13.db/t_student/.hive-staging_hive_2022-10-13_16-07-08_795_1543917524199913194-6/-ext-10000
INFO : Starting task [Stage-2:STATS] in serial mode
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 7.37 sec HDFS Read: 15979 HDFS Write: 250 SUCCESS
INFO : Total MapReduce CPU Time Spent: 7 seconds 370 msec
INFO : Completed executing command(queryId=wangting_20221013160708_4f681b20-e521-4c4e-8fce-c1b7a68a8c9b); Time taken: 37.022 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (37.266 seconds)
0: jdbc:hive2://ops01:10000>
在执行插入数据的时候,发现插入速度极慢,sql执行时间很长
最终插入一条数据,历史37.266秒的时间。查询表数据,显示数据插入成功
查询表数据
# 查询表数据
0: jdbc:hive2://ops01:10000> select * from t_student;
INFO : Compiling command(queryId=wangting_20221013162317_8bdee041-dcb8-421f-b122-c0eaf65b7994): select * from t_student
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_student.id, type:int, comment:null), FieldSchema(name:t_student.name,type:varchar(255), comment:null)], properties:null)
INFO : Completed compiling command(queryId=wangting_20221013162317_8bdee041-dcb8-421f-b122-c0eaf65b7994); Time taken: 0.123 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20221013162317_8bdee041-dcb8-421f-b122-c0eaf65b7994): select * from t_student
INFO : Completed executing command(queryId=wangting_20221013162317_8bdee041-dcb8-421f-b122-c0eaf65b7994); Time taken: 0.001 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+---------------+-----------------+
| t_student.id | t_student.name |
+---------------+-----------------+
| 1 | allen |
+---------------+-----------------+
1 row selected (0.228 seconds)
登陆Hadoop HDFS浏览文件系统,根据Hive的数据模型,表的数据最终是存储在HDFS和表对应的文件夹下的
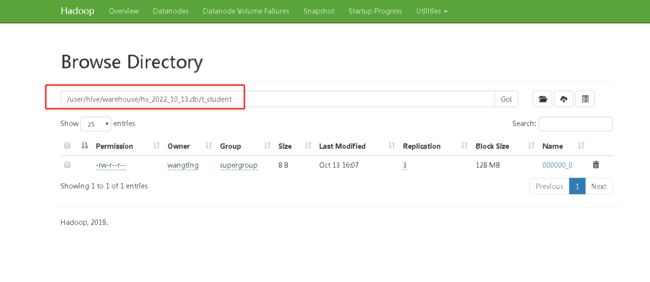
总结
- Hive SQL语法和标准SQL很类似
- Hive底层是通过MapReduce执行的数据插入动作,所以速度慢。
- 如果大数据集这么一条一条插入的话是非常不现实的,时间成本极高。
- Hive应该具有自己特有的数据插入表方式,结构化文件映射成为表。
4-2.体验2:将结构化数据映射成为表初次体验
HDFS上传映射文件
在HDFS根目录下创建一个结构化数据文件user.txt,里面内容如下:
wangting@ops01:/home/wangting >mkdir 20221013
wangting@ops01:/home/wangting >cd 20221013
wangting@ops01:/home/wangting/20221013 >vim user.txt
1,zhangsan,18,beijing
2,lisi,25,shanghai
3,allen,30,shanghai
4,woon,15,nanjing
5,james,45,hangzhou
6,tony,26,beijing
wangting@ops01:/home/wangting/20221013 >hdfs dfs -put user.txt /
2022-10-13 17:17:48,256 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
wangting@ops01:/home/wangting/20221013 >hdfs dfs -ls /user.txt
-rw-r--r-- 3 wangting supergroup 117 2022-10-13 17:17 /user.txt
wangting@ops01:/home/wangting/20221013 >hdfs dfs -cat /user.txt
2022-10-13 17:18:28,421 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
1,zhangsan,18,beijing
2,lisi,25,shanghai
3,allen,30,shanghai
4,woon,15,nanjing
5,james,45,hangzhou
6,tony,26,beijing
创建表t_user
在hive中创建一张表t_user。注意:字段的类型顺序要和文件中字段保持一致。
0: jdbc:hive2://ops01:10000> create table t_user(id int,name varchar(255),age int,city varchar(255));
INFO : Compiling command(queryId=wangting_20221013172003_f3c0cd33-b145-4768-9c78-d2f5d177c43d): create table t_user(id int,name varchar(255),age int,city varchar(255))
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=wangting_20221013172003_f3c0cd33-b145-4768-9c78-d2f5d177c43d); Time taken: 0.015 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20221013172003_f3c0cd33-b145-4768-9c78-d2f5d177c43d): create table t_user(id int,name varchar(255),age int,city varchar(255))
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=wangting_20221013172003_f3c0cd33-b145-4768-9c78-d2f5d177c43d); Time taken: 0.054 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.077 seconds)
0: jdbc:hive2://ops01:10000> select * from t_user;
INFO : Compiling command(queryId=wangting_20221013172211_e9eb3b6b-5ea6-4d5f-92d5-41c60c4e3d15): select * from t_user
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_user.id, type:int, comment:null), FieldSchema(name:t_user.name, type:varchar(255),comment:null), FieldSchema(name:t_user.age, type:int, comment:null), FieldSchema(name:t_user.city, type:varchar(255), comment:null)], properties:null)
INFO : Completed compiling command(queryId=wangting_20221013172211_e9eb3b6b-5ea6-4d5f-92d5-41c60c4e3d15); Time taken: 0.108 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20221013172211_e9eb3b6b-5ea6-4d5f-92d5-41c60c4e3d15): select * from t_user
INFO : Completed executing command(queryId=wangting_20221013172211_e9eb3b6b-5ea6-4d5f-92d5-41c60c4e3d15); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+------------+--------------+-------------+--------------+
| t_user.id | t_user.name | t_user.age | t_user.city |
+------------+--------------+-------------+--------------+
+------------+--------------+-------------+--------------+
No rows selected (0.12 seconds)
验证表t_user
执行数据查询操作,发现表中并没有数据,说明创建的t_user表和user.txt并没有形成映射关系
使用HDFS命令将数据移动到表对应的路径下
wangting@ops01:/home/wangting/20221013 >hdfs dfs -mv /user.txt /user/hive/warehouse/hv_2022_10_13.db/t_user
wangting@ops01:/home/wangting/20221013 >hdfs dfs -ls /user/hive/warehouse/hv_2022_10_13.db/t_user
Found 1 items
-rw-r--r-- 3 wangting supergroup 117 2022-10-13 17:17 /user/hive/warehouse/hv_2022_10_13.db/t_user/user.txt
再次查看表中内容
0: jdbc:hive2://ops01:10000> select * from t_user;
INFO : Compiling command(queryId=wangting_20221013172615_aff07cff-130a-4698-82e6-7e847f479d18): select * from t_user
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_user.id, type:int, comment:null), FieldSchema(name:t_user.name, type:varchar(255),comment:null), FieldSchema(name:t_user.age, type:int, comment:null), FieldSchema(name:t_user.city, type:varchar(255), comment:null)], properties:null)
INFO : Completed compiling command(queryId=wangting_20221013172615_aff07cff-130a-4698-82e6-7e847f479d18); Time taken: 0.111 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20221013172615_aff07cff-130a-4698-82e6-7e847f479d18): select * from t_user
INFO : Completed executing command(queryId=wangting_20221013172615_aff07cff-130a-4698-82e6-7e847f479d18); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+------------+--------------+-------------+--------------+
| t_user.id | t_user.name | t_user.age | t_user.city |
+------------+--------------+-------------+--------------+
| NULL | NULL | NULL | NULL |
| NULL | NULL | NULL | NULL |
| NULL | NULL | NULL | NULL |
| NULL | NULL | NULL | NULL |
| NULL | NULL | NULL | NULL |
| NULL | NULL | NULL | NULL |
+------------+--------------+-------------+--------------+
6 rows selected (0.127 seconds)
再次执行查询操作,值都是null,说明感知到文件,但是并没有把内容一一对应起来
建新表t_user_1指定分隔符
0: jdbc:hive2://ops01:10000> create table t_user_1(id int,name varchar(255),age int,city varchar(255)) row format delimited fields terminated by ',';
INFO : Compiling command(queryId=wangting_20221013173054_8ddcc8a6-d690-4eda-adb7-0788629ba15c): create table t_user_1(id int,name varchar(255),age int,city varchar(255)) row format delimited fields terminated by ','
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=wangting_20221013173054_8ddcc8a6-d690-4eda-adb7-0788629ba15c); Time taken: 0.015 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20221013173054_8ddcc8a6-d690-4eda-adb7-0788629ba15c): create table t_user_1(id int,name varchar(255),age int,city varchar(255)) row format delimited fields terminated by ','
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=wangting_20221013173054_8ddcc8a6-d690-4eda-adb7-0788629ba15c); Time taken: 0.071 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.094 seconds)
上传映射文件到对应路径
wangting@ops01:/home/wangting/20221013 >hdfs dfs -put user.txt /user/hive/warehouse/hv_2022_10_13.db/t_user_1/
2022-10-13 17:32:18,236 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
wangting@ops01:/home/wangting/20221013 >hdfs dfs -cat /user/hive/warehouse/hv_2022_10_13.db/t_user_1/user.txt
2022-10-13 17:32:43,877 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
1,zhangsan,18,beijing
2,lisi,25,shanghai
3,allen,30,shanghai
4,woon,15,nanjing
5,james,45,hangzhou
6,tony,26,beijing
查询新表t_user_1内容
0: jdbc:hive2://ops01:10000> select * from t_user_1;
INFO : Compiling command(queryId=wangting_20221013173328_ee6745df-ca06-4433-9960-632250ccc5a6): select * from t_user_1
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_user_1.id, type:int, comment:null), FieldSchema(name:t_user_1.name, type:varchar(255), comment:null), FieldSchema(name:t_user_1.age, type:int, comment:null), FieldSchema(name:t_user_1.city, type:varchar(255), comment:null)], properties:null)
INFO : Completed compiling command(queryId=wangting_20221013173328_ee6745df-ca06-4433-9960-632250ccc5a6); Time taken: 0.108 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20221013173328_ee6745df-ca06-4433-9960-632250ccc5a6): select * from t_user_1
INFO : Completed executing command(queryId=wangting_20221013173328_ee6745df-ca06-4433-9960-632250ccc5a6); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+--------------+----------------+---------------+----------------+
| t_user_1.id | t_user_1.name | t_user_1.age | t_user_1.city |
+--------------+----------------+---------------+----------------+
| 1 | zhangsan | 18 | beijing |
| 2 | lisi | 25 | shanghai |
| 3 | allen | 30 | shanghai |
| 4 | woon | 15 | nanjing |
| 5 | james | 45 | hangzhou |
| 6 | tony | 26 | beijing |
+--------------+----------------+---------------+----------------+
6 rows selected (0.125 seconds)
创建表t_user_2
此时再创建一张表t_user_2,保存分隔符语法,但是故意使得字段类型和文件中不一致,测试一下字段约束类型不符会如何
0: jdbc:hive2://ops01:10000> create table t_user_2(id int,name int,age varchar(255),city varchar(255)) row format delimited fields terminated by ',';
INFO : Compiling command(queryId=wangting_20221013173540_c4d0759d-5120-4e77-bd1f-9cae820d5cad): create table t_user_2(id int,name int,age varchar(255),city varchar(255)) row format delimited fields terminated by ','
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=wangting_20221013173540_c4d0759d-5120-4e77-bd1f-9cae820d5cad); Time taken: 0.016 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20221013173540_c4d0759d-5120-4e77-bd1f-9cae820d5cad): create table t_user_2(id int,name int,age varchar(255),city varchar(255)) row format delimited fields terminated by ','
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=wangting_20221013173540_c4d0759d-5120-4e77-bd1f-9cae820d5cad); Time taken: 0.055 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (0.077 seconds)
上传映射文件
wangting@ops01:/home/wangting/20221013 >hdfs dfs -put user.txt /user/hive/warehouse/hv_2022_10_13.db/t_user_2/
查询新表t_user_2内容
0: jdbc:hive2://ops01:10000> select * from t_user_2;
INFO : Compiling command(queryId=wangting_20221013173648_048fa03f-beb9-4387-bc09-e6062d79170f): select * from t_user_2
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_user_2.id, type:int, comment:null), FieldSchema(name:t_user_2.name, type:int, comment:null), FieldSchema(name:t_user_2.age, type:varchar(255), comment:null), FieldSchema(name:t_user_2.city, type:varchar(255), comment:null)], properties:null)
INFO : Completed compiling command(queryId=wangting_20221013173648_048fa03f-beb9-4387-bc09-e6062d79170f); Time taken: 0.106 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20221013173648_048fa03f-beb9-4387-bc09-e6062d79170f): select * from t_user_2
INFO : Completed executing command(queryId=wangting_20221013173648_048fa03f-beb9-4387-bc09-e6062d79170f); Time taken: 0.001 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+--------------+----------------+---------------+----------------+
| t_user_2.id | t_user_2.name | t_user_2.age | t_user_2.city |
+--------------+----------------+---------------+----------------+
| 1 | NULL | 18 | beijing |
| 2 | NULL | 25 | shanghai |
| 3 | NULL | 30 | shanghai |
| 4 | NULL | 15 | nanjing |
| 5 | NULL | 45 | hangzhou |
| 6 | NULL | 26 | beijing |
+--------------+----------------+---------------+----------------+
6 rows selected (0.121 seconds)
此时发现,有的列name显示null,有的列显示正常
name字段本身是字符串,但是建表的时候指定int,类型转换不成功;age是数值类型,建表指定字符串类型,可以转换成功。说明hive中具有自带的类型转换功能,但是不一定保证转换成功
结论
要想在hive中创建表跟结构化文件映射成功,需要注意以下几个方面问题:
- 创建表时,字段顺序、字段类型要和文件中保持一致。
- 如果类型不一致,hive会尝试转换,但是不保证转换成功。不成功显示null。
4-3.体验3:使用Hive进行小数据分析体验
在体验2中的t_user_1中进行数据查询
之前创建好了一张表t_user_1,现在通过Hive SQL找出当中年龄大于20岁的有几个
0: jdbc:hive2://ops01:10000> select count(*) from t_user_1 where age > 20;
INFO : Compiling command(queryId=wangting_20221013174512_2ec3e4c9-bafe-40fd-9a4c-367dbf1d899e): select count(*) from t_user_1 where age > 20
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_c0, type:bigint, comment:null)], properties:null)
INFO : Completed compiling command(queryId=wangting_20221013174512_2ec3e4c9-bafe-40fd-9a4c-367dbf1d899e); Time taken: 0.268 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20221013174512_2ec3e4c9-bafe-40fd-9a4c-367dbf1d899e): select count(*) from t_user_1 where age > 20
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez)or using Hive 1.X releases.
INFO : Query ID = wangting_20221013174512_2ec3e4c9-bafe-40fd-9a4c-367dbf1d899e
INFO : Total jobs = 1
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1615531413182_10786
INFO : Executing with tokens: []
INFO : The url to track the job: http://ops02:8088/proxy/application_1615531413182_10786/
INFO : Starting Job = job_1615531413182_10786, Tracking URL = http://ops02:8088/proxy/application_1615531413182_10786/
INFO : Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1615531413182_10786
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2022-10-13 17:45:20,779 Stage-1 map = 0%, reduce = 0%
INFO : 2022-10-13 17:45:35,109 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.06 sec
INFO : 2022-10-13 17:45:49,405 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 7.25 sec
INFO : MapReduce Total cumulative CPU time: 7 seconds 250 msec
INFO : Ended Job = job_1615531413182_10786
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 7.25 sec HDFS Read: 14444 HDFS Write: 101 SUCCESS
INFO : Total MapReduce CPU Time Spent: 7 seconds 250 msec
INFO : Completed executing command(queryId=wangting_20221013174512_2ec3e4c9-bafe-40fd-9a4c-367dbf1d899e); Time taken: 38.032 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+------+
| _c0 |
+------+
| 4 |
+------+
1 row selected (38.322 seconds)
从控制台输出可以发现又是通过MapReduce程序执行的数据查询功能
结论
- Hive底层的确是通过MapReduce执行引擎来处理数据的
- 执行完一个MapReduce程序需要的时间较长
- 如果是小数据集,使用hive进行分析将得不偿失,延迟很高
- 如果是大数据集,使用hive进行分析,底层MapReduce分布式计算
+后续章前准备工作+
准备工作可以根据情况选择是否准备,大部分语句可以通过命令行客户端去执行,推荐使用开发环境去熟悉。
IntelliJ IDEA开发工具安装,java开发人员必备工具
IntelliJ IDEA是JetBrains公司的产品,是java编程语言开发的集成环境。
在业界被公认为最好的java开发工具,尤其在智能代码助手、代码自动提示、重构、代码分析、 创新的GUI设计等方面的功能可以说是超常的。
IntelliJ IDEA 还有丰富的插件,其中就内置集成了Database插件,支持操作各种主流的数据库、数据仓库
创建一个maven项目
Name: hive_test
GroupId: cn.wangting
在IDEA中的任意工程中,选择Database标签配置Hive Driver驱动
配置Hive数据源,连接HS2
驱动文件包可以关联本地对应版本jar包
链接:https://pan.baidu.com/s/14Pl4KnqjGj0nf05d7JSrxw?pwd=kfud
提取码:kfud
在线下载速度非常慢,有代理可以尝试在线下载依赖包

配置完成后,点击测试连接
test包下创建一个hive.sql,来测试功能:输入语句 show databases;
可以看到成功查询到结果输出
第5章:数据定义语言(DDL)概述
5-1.SQL中DDL语法的作用
- 数据定义语言 (Data Definition Language, DDL),是SQL语言集中对数据库内部的对象结构进行创建,删除,修改等的操作语言,这些数据库对象包括database(schema)、table、view、index等。
- DDL核心语法由CREATE、ALTER与DROP三个所组成。DDL并不涉及表内部数据的操作。
- 在某些上下文中,该术语也称为数据描述语言,因为它描述了数据库表中的字段和记录。
5-2.Hive中DDL语法的使用
- Hive SQL(HQL)与标准SQL的语法大同小异,基本相通,注意差异即可;
- 基于Hive的设计、使用特点,HQL中create语法(尤其create table)将是学习掌握Hive DDL语法的重中之重。
建表是否成功直接影响数据文件是否映射成功,进而影响后续是否可以基于SQL分析数据。
第6章:Hive SQL DDL建表基础语法
6-1.Hive建表完整语法树
完整语法树
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [COMMENT col_comment], ... ]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT DELIMITED|SERDE serde_name WITH SERDEPROPERTIES (property_name=property_value,...)]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)];
注意事项
[ ] 中括号的语法表示可选。
| 表示使用的时候,左右语法二选一。
建表语句中的语法顺序要和语法树中顺序保持一致。
6-2.Hive数据类型详解
Hive数据类型指的是表中列的字段类型;
整体分为两类:
- 原生数据类型(primitive data type)
- 数值类型
- 时间日期类型
- 字符串类型
- 杂项数据类型
- 复杂数据类型(complex data type)
- array数组
- map映射
- struct结构
- union联合体
primitive data type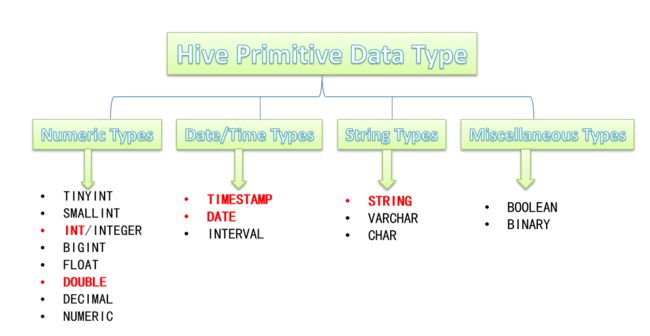
complex data type
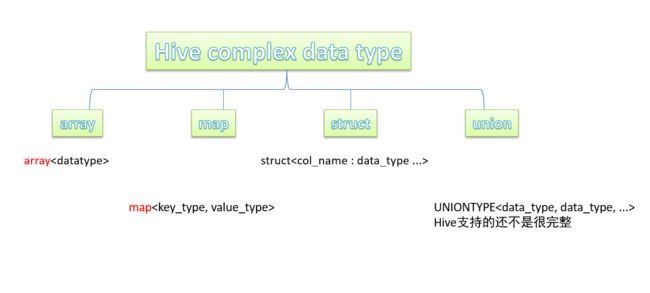
- Hive SQL中,数据类型英文字母大小写不敏感;
- 除SQL数据类型外,还支持Java数据类型,比如字符串string;
- 复杂数据类型的使用通常需要和分隔符指定语法配合使用;
- 如果定义的数据类型和文件不一致,Hive会尝试隐式转换,但是不保证成功。
隐式转换:
- 与标准SQL类似,HQL支持隐式和显式类型转换。
- 原生类型从窄类型到宽类型的转换称为隐式转换,反之,则不允许
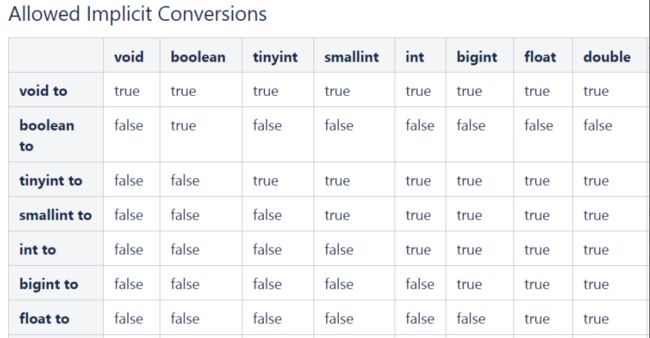
显示转换
显式类型转换使用CAST函数
例如,CAST('100’as INT)会将100字符串转换为100整数值
如果强制转换失败,例如CAST(‘Allen’as INT),该函数返回NULL
0: jdbc:hive2://ops01:10000> select cast ('100' as INT);
+------+
| _c0 |
+------+
| 100 |
+------+
1 row selected (0.146 seconds)
0: jdbc:hive2://ops01:10000> select cast ('wang' as INT);
+-------+
| _c0 |
+-------+
| NULL |
+-------+
1 row selected (0.132 seconds)
6-3.Hive读写文件机制
SerDe是什么:
- SerDe是Serializer、Deserializer的简称,目的是用于序列化和反序列化。
- 序列化是对象转化为字节码的过程;而反序列化是字节码转换为对象的过程。
- Hive使用SerDe(包括FileFormat)读取和写入表行对象。需要注意的是,“key”部分在读取时会被忽略,而在写入时key始终是常数。基本上行对象存储在“value”中。
Read:
HDFS files --> InputFileFormat -->
Write:
Row object --> Serializer(序列化) -->
可以通过desc formatted tablename查看表的相关SerDe信息
0: jdbc:hive2://ops01:10000> desc formatted t_user_1;
+-------------------------------+----------------------------------------------------+---------------------+
| col_name | data_type | comment |
+-------------------------------+----------------------------------------------------+---------------------+
| # Storage Information | NULL | NULL
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL
| OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL
Hive读写文件流程:
-
Hive读取文件机制:首先调用InputFormat(默认TextInputFormat),返回一条一条kv键值对记录(默认是一行对应一条键值对)。然后调用SerDe(默认LazySimpleSerDe)的Deserializer,将一条记录中的value根据分隔符切分为各个字段。
-
Hive写文件机制:将Row写入文件时,首先调用SerDe(默认LazySimpleSerDe)的Serializer将对象转换成字节序列,然后调用OutputFormat将数据写入HDFS文件中
SerDe相关语法:
ROW FORMAT这一行所代表的是跟读写文件、序列化SerDe相关的语法,功能有二
- 使用哪个SerDe类进行序列化
- 如何指定分隔符
其中ROW FORMAT是语法关键字,DELIMITED和SERDE二选其一。
如果使用delimited表示使用默认的LazySimpleSerDe类来处理数据。
如果数据文件格式比较特殊可以使用ROW FORMAT SERDE serde_name指定其他的Serde类来处理数据,甚至支持用户自定义SerDe类。
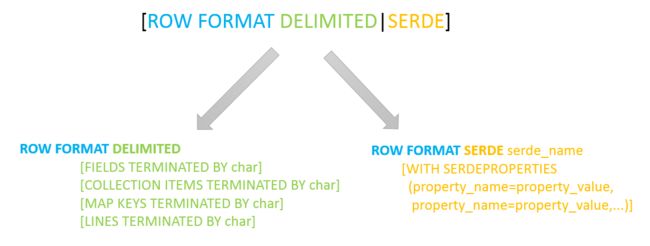
LazySimpleSerDe分隔符指定:
LazySimpleSerDe是Hive默认的序列化类,包含4种子语法,分别用于指定字段之间、集合元素之间、map映射 kv之间、换行的分隔符号
在建表的时候可以根据数据的特点灵活搭配使用
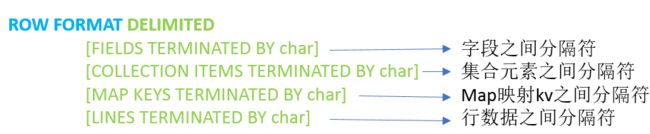
Hive默认分隔符:
Hive建表时如果没有row format语法指定分隔符,则采用默认分隔符;
默认的分割符是’\001’,是一种特殊的字符,使用的是ASCII编码的值,键盘是打不出来的
在vim编辑器中,连续按下Ctrl+v/Ctrl+a即可输入’\001’ ,显示^A,但是在正常的展示文本时则不可见
# 举例 下载一个hdfs映射文件
wangting@ops01:/home/wangting/20221013 >hdfs dfs -get /water_bill/output_ept_10W_export_0817/part-m-00000
wangting@ops01:/home/wangting/20221013 >ll
total 50284
-rw-r--r-- 1 wangting wangting 51483241 Oct 14 10:06 part-m-00000
-rw-rw-r-- 1 wangting wangting 117 Oct 13 17:16 user.txt
# 简单查看内容,并没有发现类似^开头的特殊字符
wangting@ops01:/home/wangting/20221013 >head part-m-00000 20
==> part-m-00000 <==
SEQ1org.apache.hadoop.hbase.io.ImmutableBytesWritable%org.apache.hadoop.hbase.client.Result8+u
0000132
R
0000132C1ADDRESS .(21山西省忻州市偏关县新关镇7单元124室
/
0000132C1
LATEST_DATE .(2
2020-08-02
'
0000132C1NAME .(2 蔡徐坤
-
0000132C1
NUM_CURRENT .(@p33333
# 使用vim编辑器打开文本,发现有很多^开头的特殊字符
wangting@ops01:/home/wangting/20221013 >vim part-m-00000
SEQ^F1org.apache.hadoop.hbase.io.ImmutableBytesWritable%org.apache.hadoop.hbase.client.Result^@^@^@^@^@^@8+u^V<8d>^BÕݬ<9a> ^S<81>ðN^@^@^Aû^@^@^@^K^@^@^@^G0000132î^C
R
^G0000132^R^BC1^Z^GADDRESS ÿ<8d><80><94><9f>.(^D21山西ç<9c><81>å¿»å·<9e>å¸<82>å<81><8f>å<85>³å<8e>¿æ<96>°å<85>³é<95><87>7å<8d><95>å<85><83>124室
^G0000132^R^BC1^Z^KLATEST_DATE ÿ<8d><80><94><9f>.(^D2
2020-08-02
^G0000132^R^BC1^Z^DNAME ÿ<8d><80><94><9f>.(^D2 æ<96>¹æµ©è½©
^G0000132^R^BC1^Z^KNUM_CURRENT ÿ<8d><80><94><9f>.(^D2^H@pó33333
^G0000132^R^BC1^Z^LNUM_PREVIOUS ÿ<8d><80><94><9f>.(^D2^H@}Û33333
6-4.Hive数据存储路径
默认存储路径:
Hive表默认存储路径是由${HIVE_HOME}/conf/hive-site.xml配置文件的hive.metastore.warehouse.dir属性指定,默认值是:/user/hive/warehouse
在该路径下,文件将根据所属的库、表,有规律的存储在对应的文件夹下
指定存储路径:
在Hive建表的时候,可以通过location语法来更改数据在HDFS上的存储路径,使得建表加载数据更加灵活方便
语法:LOCATION ‘
对于已经生成好的数据文件,使用location指定路径将会很方便
6-5.案例–王者荣耀数据Hive建表映射
案例相关数据素材文件均在:
https://osswangting.oss-cn-shanghai.aliyuncs.com/hive/honor_of_kings.zip
案例1
背景:
文件archer.txt中记录了手游《王者荣耀》射手的相关信息,包括生命、物防、物攻等属性信息,其中字段之间分隔符为制表符\t,要求在Hive中建表映射成功该文件
archer.txt
honor_of_kings.zip下载解压后上传即可
1 后羿 5986 1784 396 336 remotely archer
2 马可波罗 5584 200 362 344 remotely archer
3 鲁班七号 5989 1756 400 323 remotely archer
4 李元芳 5725 1770 396 340 remotely archer
5 孙尚香 6014 1756 411 346 remotely archer
6 黄忠 5898 1784 403 319 remotely archer
7 狄仁杰 5710 1770 376 338 remotely archer
8 虞姬 5669 1770 407 329 remotely archer
9 成吉思汗 5799 1742 394 329 remotely archer
10 百里守约 5611 1784 410 329 remotely archer assassin
- 字段含义:id、name(英雄名称)、hp_max(最大生命)、mp_max(最大法力)、attack_max(最高物攻)、defense_max(最大物防)、attack_range(攻击范围)、role_main(主要定位)、role_assist(次要定位)。
- 字段都是基本类型,字段的顺序需要注意。
- 字段之间的分隔符是制表符,需要使用row format语法进行指定
执行建表语句:
use hv_2022_10_13;
create table t_archer(
id int comment "ID",
name string comment "英雄名称",
hp_max int comment "最大生命",
mp_max int comment "最大法力",
attack_max int comment "最高物攻",
defense_max int comment "最大物防",
attack_range string comment "攻击范围",
role_main string comment "主要定位",
role_assist string comment "次要定位"
) comment "王者荣耀射手信息"
row format delimited
fields terminated by "\t";
建表成功之后,在Hive的默认存储路径下就生成了表对应的文件夹;
把archer.txt文件上传到对应的表文件夹下
wangting@ops01:/home/wangting/20221013 >ls
archer.txt part-m-00000 user.txt
wangting@ops01:/home/wangting/20221013 >hdfs dfs -put archer.txt /user/hive/warehouse/hv_2022_10_13.db/t_archer
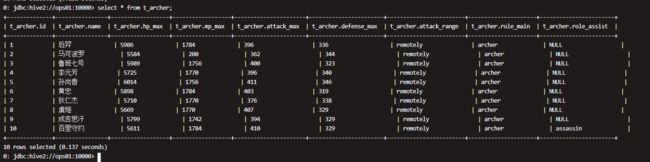
查数验证:
执行查询操作,可以看出数据已经映射成功。
核心语法:row format delimited fields terminated by 指定字段之间的分隔符。
案例2
背景:
文件hot_hero_skin_price.txt中记录了手游《王者荣耀》热门英雄的相关皮肤价格信息,要求在Hive中建表映射成功该文件
hot_hero_skin_price.txt
1,孙悟空,53,西部大镖客:288-大圣娶亲:888-全息碎片:0-至尊宝:888-地狱火:1688
2,鲁班七号,54,木偶奇遇记:288-福禄兄弟:288-黑桃队长:60-电玩小子:2288-星空梦想:0
3,后裔,53,精灵王:288-阿尔法小队:588-辉光之辰:888-黄金射手座:1688-如梦令:1314
4,铠,52,龙域领主:288-曙光守护者:1776
5,韩信,52,飞衡:1788-逐梦之影:888-白龙吟:1188-教廷特使:0-街头霸王:888
- 字段:id、name(英雄名称)、win_rate(胜率)、skin_price(皮肤及价格);
- 前3个字段原生数据类型、最后一个字段复杂类型map。
- 需要指定字段之间分隔符、集合元素之间分隔符、map kv之间分隔符
执行建表语句:
use hv_2022_10_13;
create table t_hot_hero_skin_price(
id int,
name string,
win_rate int,
skin_price map<string,int>
)
row format delimited
fields terminated by ',' --字段之间分隔符
collection items terminated by '-' --集合元素之间分隔符
map keys terminated by ':'; --集合元素kv之间分隔符;
建表成功之后,在Hive的默认存储路径下就生成了表对应的文件夹;
把hot_hero_skin_price.txt文件上传到对应的表文件夹下
wangting@ops01:/home/wangting/20221013 >ls
archer.txt hot_hero_skin_price.txt part-m-00000 user.txt
wangting@ops01:/home/wangting/20221013 >hdfs dfs -put hot_hero_skin_price.txt /user/hive/warehouse/hv_2022_10_13.db/t_hot_hero_skin_price
查数验证:
执行查询操作,可以看出数据已经映射成功

案例3
背景:
文件team_ace_player.txt中记录了手游《王者荣耀》主要战队内最受欢迎的王牌选手信息,字段之间使用的是\001作为分隔符,要求在Hive中建表映射成功该文件
team_ace_player.txt
有不可见字符,自行下载:https://osswangting.oss-cn-shanghai.aliyuncs.com/hive/honor_of_kings.zip
- 字段:id、team_name(战队名称)、ace_player_name(王牌选手名字)
- 数据都是原生数据类型,且字段之间分隔符是\001,因此在建表的时候可以省去row format语句,因为hive默认的分隔符就是\001
执行建表语句:
use hv_2022_10_13;
create table t_team_ace_player(
id int,
team_name string,
ace_player_name string
);
建表成功后,把team_ace_player.txt文件上传到对应的表文件夹下
wangting@ops01:/home/wangting/20221013 >ls
archer.txt hot_hero_skin_price.txt part-m-00000 team_ace_player.txt user.txt
wangting@ops01:/home/wangting/20221013 >hdfs dfs -put team_ace_player.txt /user/hive/warehouse/hv_2022_10_13.db/t_team_ace_player
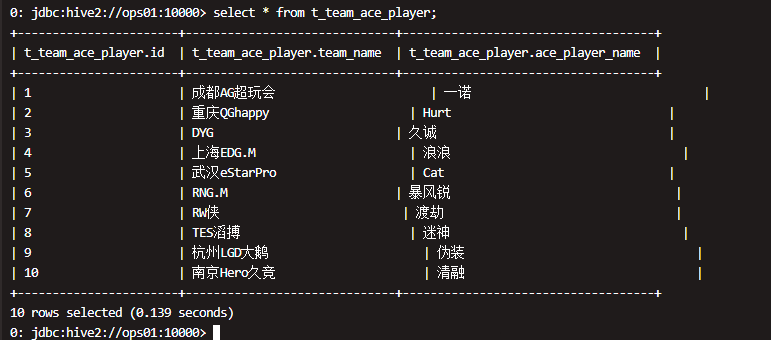
查数验证:
执行查询操作,可以看出数据已经映射成功。
案例4
背景:
文件team_ace_player.txt中记录了手游《王者荣耀》主要战队内最受欢迎的王牌选手信息,字段之间使用的是\001作为分隔符。
要求把文件上传到HDFS任意路径下,不能移动复制,并在Hive中建表映射成功该文件相当于指定数据存储路径
执行建表语句:
create table t_team_ace_player_location(
id int,
team_name string,
ace_player_name string)
location '/20221014';
上传数据文件:
wangting@ops01:/home/wangting/20221013 >hdfs dfs -mkdir /20221014
wangting@ops01:/home/wangting/20221013 >hdfs dfs -put team_ace_player.txt /20221014/
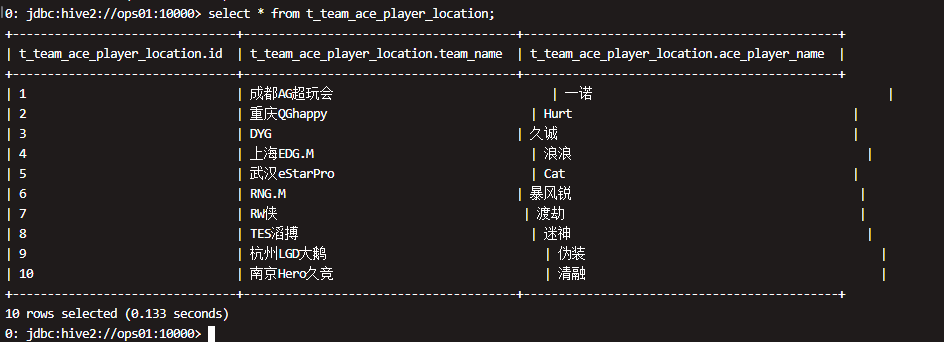
查数验证:
执行查询操作,可以看出数据已经映射成功。
第7章:Hive SQL DDL建表高阶语法
7-1.Hive 内部表、外部表
什么是内部表
- 内部表(Internal table)也称为被Hive拥有和管理的托管表(Managed table)。
- 默认情况下创建的表就是内部表,Hive拥有该表的结构和文件。换句话说,Hive完全管理表(元数据和数据)的生命周期,类似于RDBMS中的表。
- 当删除内部表时,会删除数据以及表的元数据
可以使用DESCRIBE FORMATTED tablename,来获取表的元数据描述信息,从中可以看出表的类型
Table Type: MANAGED_TABLE
什么是外部表
- 外部表(External table)中的数据不是Hive拥有或管理的,只管理表元数据的生命周期。
- 要创建一个外部表,需要使用EXTERNAL语法关键字。
- 删除外部表只会删除元数据,而不会删除实际数据。在Hive外部仍然可以访问实际数据。
- 实际场景中,外部表搭配location语法指定数据的路径,可以让数据更安全
可以使用DESCRIBE FORMATTED tablename,来获取表的元数据描述信息,从中可以看出表的类型
Table Type: EXTERNAL_TABLE
内、外部表差异
- 无论内部表还是外部表,Hive都在Hive Metastore中管理表定义、字段类型等元数据信息。
- 删除内部表时,除了会从Metastore中删除表元数据,还会从HDFS中删除其所有数据文件。
- 删除外部表时,只会从Metastore中删除表的元数据,并保持HDFS位置中的实际数据不变。

如何选择内、外部表
- 当需要通过Hive完全管理控制表的整个生命周期时,请使用内部表。
- 当数据来之不易,防止误删,请使用外部表,因为即使删除表,文件也会被保留。
案例验证内部表、外部表区别
wangting@ops01:/home/wangting/20221013 >ls
archer.txt hot_hero_skin_price.txt part-m-00000 team_ace_player.txt user.txt
wangting@ops01:/home/wangting/20221013 >cat user.txt
1,zhangsan,18,beijing
2,lisi,25,shanghai
3,allen,30,shanghai
4,woon,15,nanjing
5,james,45,hangzhou
6,tony,26,beijing
wangting@ops01:/home/wangting/20221013 >hdfs dfs -mkdir /20221014/in
wangting@ops01:/home/wangting/20221013 >hdfs dfs -mkdir /20221014/out
建内外表
0: jdbc:hive2://ops01:10000> create table t_user_in(id int,name varchar(255),age int,city varchar(255)) row format delimited fields terminated by ',' location '/20221014/in';
No rows affected (0.083 seconds)
0: jdbc:hive2://ops01:10000> create external table t_user_out(id int,name varchar(255),age int,city varchar(255)) row format delimited fields terminated by ',' location '/20221014/out';
No rows affected (0.077 seconds)
上传映射文件
wangting@ops01:/home/wangting/20221013 >hdfs dfs -put user.txt /20221014/in/t_user_in
wangting@ops01:/home/wangting/20221013 >hdfs dfs -put user.txt /20221014/out/t_user_out
查询数据验证结果
0: jdbc:hive2://ops01:10000> select * from t_user_in;
+---------------+-----------------+----------------+-----------------+
| t_user_in.id | t_user_in.name | t_user_in.age | t_user_in.city |
+---------------+-----------------+----------------+-----------------+
| 1 | zhangsan | 18 | beijing |
| 2 | lisi | 25 | shanghai |
| 3 | allen | 30 | shanghai |
| 4 | woon | 15 | nanjing |
| 5 | james | 45 | hangzhou |
| 6 | tony | 26 | beijing |
+---------------+-----------------+----------------+-----------------+
6 rows selected (0.143 seconds)
0: jdbc:hive2://ops01:10000> select * from t_user_out;
+----------------+------------------+-----------------+------------------+
| t_user_out.id | t_user_out.name | t_user_out.age | t_user_out.city |
+----------------+------------------+-----------------+------------------+
| 1 | zhangsan | 18 | beijing |
| 2 | lisi | 25 | shanghai |
| 3 | allen | 30 | shanghai |
| 4 | woon | 15 | nanjing |
| 5 | james | 45 | hangzhou |
| 6 | tony | 26 | beijing |
+----------------+------------------+-----------------+------------------+
6 rows selected (0.138 seconds)
此时,内外表都可以成功映射
t_user_in 对应hdfs文件路径 /20221014/in/t_user_in
t_user_out 对应hdfs文件路径 /20221014/out/t_user_out
wangting@ops01:/home/wangting/20221013 >hdfs dfs -ls /20221014
Found 2 items
drwxr-xr-x - wangting supergroup 0 2022-10-14 13:53 /20221014/in
drwxr-xr-x - wangting supergroup 0 2022-10-14 13:54 /20221014/out
wangting@ops01:/home/wangting/20221013 >hdfs dfs -ls /20221014/in
Found 1 items
-rw-r--r-- 3 wangting supergroup 117 2022-10-14 13:53 /20221014/in/t_user_in
wangting@ops01:/home/wangting/20221013 >hdfs dfs -ls /20221014/out
Found 1 items
-rw-r--r-- 3 wangting supergroup 117 2022-10-14 13:54 /20221014/out/t_user_out
将内外表删除drop
0: jdbc:hive2://ops01:10000> drop table t_user_in;
No rows affected (0.114 seconds)
0: jdbc:hive2://ops01:10000> drop table t_user_out;
No rows affected (0.093 seconds)
删除表后验证hdfs映射文件情况
wangting@ops01:/home/wangting/20221013 >hdfs dfs -ls /20221014/in
ls: `/20221014/in': No such file or directory
wangting@ops01:/home/wangting/20221013 >hdfs dfs -ls /20221014/out
Found 1 items
-rw-r--r-- 3 wangting supergroup 117 2022-10-14 13:54 /20221014/out/t_user_out
内部表drop删除后,hdfs上的/20221014/in/t_user_in文件已经同步被删除
外部表drop删除后,hdfs上的/20221014/out/t_user_out文件依旧还在hdfs上
如果需要外部表重建表即可再次使用数据文件
7-2.Hive Partitioned Tables 分区表
分区表概念
- 当Hive表对应的数据量大、文件个数多时,为了避免查询时全表扫描数据,Hive支持根据指定的字段对表进行分区,分区的字段可以是日期、地域、种类等具有标识意义的字段。
- 例如把一整年的数据根据月份划分12个月(12个分区),后续就可以查询指定月份分区的数据,尽可能避免了全表扫描查询
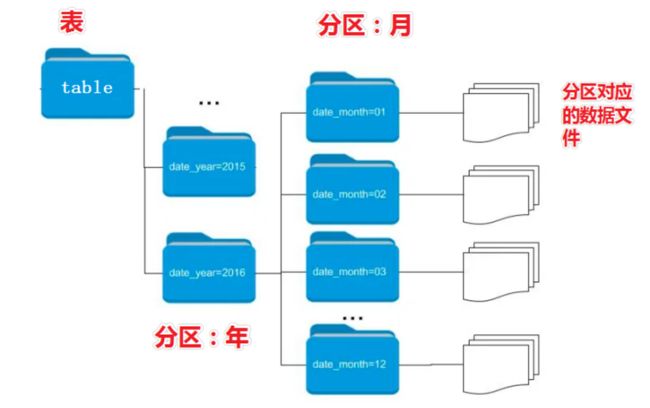
创建分区表语法
分区字段不能是表中已经存在的字段,因为分区字段最终也会以虚拟字段的形式显示在表结构上
关键词:PARTITIONED BY
示例:
CREATE TABLE table_name (
column1 data_type,
column2 data_type,
....)
PARTITIONED BY (partition1 data_type, partition2 data_type,…);
案例验证实验分区表
背景:
针对《王者荣耀》英雄数据,创建一张分区表t_all_hero_part,以role角色作为分区字段
执行建表语句:
create table t_all_hero_part(
id int,
name string,
hp_max int,
mp_max int,
attack_max int,
defense_max int,
attack_range string,
role_main string,
role_assist string
) partitioned by (role string)
row format delimited
fields terminated by "\t";
0: jdbc:hive2://ops01:10000> desc t_all_hero_part;
+--------------------------+------------+----------+
| col_name | data_type | comment |
+--------------------------+------------+----------+
| id | int | |
| name | string | |
| hp_max | int | |
| mp_max | int | |
| attack_max | int | |
| defense_max | int | |
| attack_range | string | |
| role_main | string | |
| role_assist | string | |
| role | string | |
| | NULL | NULL |
| # Partition Information | NULL | NULL |
| # col_name | data_type | comment |
| role | string | |
+--------------------------+------------+----------+
14 rows selected (0.114 seconds)
上传数据文件:
wangting@ops01:/home/wangting/20221013/hero >ls
archer.txt assassin.txt mage.txt support.txt tank.txt warrior.txt
wangting@ops01:/home/wangting/20221013/hero >beeline -u jdbc:hive2://ops01:10000 -n wangting
Connecting to jdbc:hive2://ops01:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
0: jdbc:hive2://ops01:10000>
0: jdbc:hive2://ops01:10000> use hv_2022_10_13;
0: jdbc:hive2://ops01:10000> load data local inpath '/home/wangting/20221013/hero/archer.txt' into table t_all_hero_part partition(role='sheshou');
0: jdbc:hive2://ops01:10000> load data local inpath '/home/wangting/20221013/hero/assassin.txt' into table t_all_hero_part partition(role='cike');
0: jdbc:hive2://ops01:10000> load data local inpath '/home/wangting/20221013/hero/mage.txt' into table t_all_hero_part partition(role='fashi');
0: jdbc:hive2://ops01:10000> load data local inpath '/home/wangting/20221013/hero/support.txt' into table t_all_hero_part partition(role='fuzhu');
0: jdbc:hive2://ops01:10000> load data local inpath '/home/wangting/20221013/hero/tank.txt' into table t_all_hero_part partition(role='tanke');
0: jdbc:hive2://ops01:10000> load data local inpath '/home/wangting/20221013/hero/warrior.txt' into table t_all_hero_part partition(role='zhanshi');
查询数据验证:
分区本质
外表上看起来分区表好像没多大变化,只不过多了一个分区字段。实际上分区表在底层管理数据的方式发生了改变。这里直接去HDFS查看区别
wangting@ops01:/home/wangting/20221013/hero >hdfs dfs -ls /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part
Found 6 items
drwxr-xr-x - wangting supergroup 0 2022-10-14 14:29 /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part/role=cike
drwxr-xr-x - wangting supergroup 0 2022-10-14 14:30 /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part/role=fashi
drwxr-xr-x - wangting supergroup 0 2022-10-14 14:30 /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part/role=fuzhu
drwxr-xr-x - wangting supergroup 0 2022-10-14 14:29 /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part/role=sheshou
drwxr-xr-x - wangting supergroup 0 2022-10-14 14:30 /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part/role=tanke
drwxr-xr-x - wangting supergroup 0 2022-10-14 14:30 /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part/role=zhanshi
- 分区的概念提供了一种将Hive表数据分离为多个文件/目录的方法。
- 不同分区对应着不同的文件夹,同一分区的数据存储在同一个文件夹下。
- 查询过滤的时候只需要根据分区值找到对应的文件夹,扫描本文件夹下本分区下的文件即可,避免全表数据扫描。
- 这种指定分区查询的方式叫做分区裁剪。
分区表的使用
分区表的使用重点在于:
- 建表时根据业务场景设置合适的分区字段。比如日期、地域、类别等;
- 查询的时候尽量先使用where进行分区过滤,查询指定分区的数据,避免全表扫描。
比如:查询英雄主要定位是射手并且最大生命大于6000的个数。使用分区表查询和使用非分区表进行查询
英雄为射手 + 生命值大于6000
0: jdbc:hive2://ops01:10000> select count(*) from t_all_hero_part where role="sheshou" and hp_max >6000;
+------+
| _c0 |
+------+
| 1 |
+------+
1 row selected (26.307 seconds)
多重分区表
-
通过建表语句中关于分区的相关语法可以发现,Hive支持多个分区字段
- PARTITIONED BY (partition1 data_type, partition2 data_type,….)
-
多重分区下,分区之间是一种递进关系,可以理解为在前一个分区的基础上继续分区
-
从HDFS的角度来看就是文件夹下继续划分子文件夹。比如:把全国人口数据首先根据省进行分区,然后根据市进行划分,如果你需要甚至可以继续根据区县再划分,此时就是3分区表
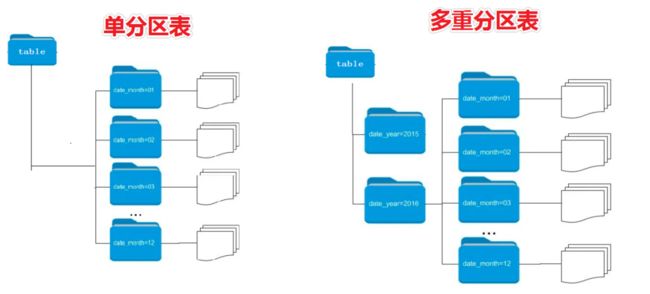
创建多重分区表示例:
--单分区表,按省份分区
create table t_user_province (id int, name string,age int) partitioned by (province string);
--双分区表,按省份和市分区
--分区字段之间是一种递进的关系 因此要注意分区字段的顺序 谁在前在后
create table t_user_province_city (id int, name string,age int) partitioned by (province string, city string);
--双分区表的数据加载 静态分区加载数据
load data local inpath '/root/hivedata/user.txt' into table t_user_province_city
partition(province='zhejiang',city='hangzhou');
load data local inpath '/root/hivedata/user.txt' into table t_user_province_city
partition(province='zhejiang',city='ningbo');
load data local inpath '/root/hivedata/user.txt' into table t_user_province_city
partition(province='shanghai',city='pudong');
--双分区表的使用 使用分区进行过滤 减少全表扫描 提高查询效率
select * from t_user_province_city where province= "zhejiang" and city ="hangzhou";
分区表数据加载–动态分区
-
所谓动态分区指的是分区的字段值是基于查询结果(参数位置)自动推断出来的。核心语法就是insert+select
-
启用hive动态分区,需要在hive会话中设置两个参数
- set hive.exec.dynamic.partition=true;
- 是否开启动态分区功能
- set hive.exec.dynamic.partition.mode=nonstrict;
- 指定动态分区模式,分为nonstick非严格模式和strict严格模式。
- strict严格模式要求至少有一个分区为静态分区。
- set hive.exec.dynamic.partition=true;
-
创建一张新的分区表,执行动态分区插入。
-
动态分区插入时,分区值是根据查询返回字段位置自动推断的
创建动态分区示例:
-- 创建原始表,无分区
create table t_all_hero(
id int,
name string,
hp_max int,
mp_max int,
attack_max int,
defense_max int,
attack_range string,
role_main string,
role_assist string
)
row format delimited
fields terminated by "\t";
上传映射文件:
wangting@ops01:/home/wangting/20221013/hero >ls
archer.txt assassin.txt mage.txt support.txt tank.txt warrior.txt
wangting@ops01:/home/wangting/20221013/hero >hdfs dfs -put * /user/hive/warehouse/hv_2022_10_13.db/t_all_hero
2022-10-14 15:47:40,286 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-10-14 15:47:40,426 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-10-14 15:47:40,447 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-10-14 15:47:40,466 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-10-14 15:47:40,485 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-10-14 15:47:40,503 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
开启动态分区:
--动态分区
0: jdbc:hive2://ops01:10000> set hive.exec.dynamic.partition=true;
No rows affected (0.005 seconds)
0: jdbc:hive2://ops01:10000> set hive.exec.dynamic.partition.mode=nonstrict;
No rows affected (0.012 seconds)
创建一个动态分区表:
--创建一张新的分区表 t_all_hero_part_dynamic
create table t_all_hero_part_dynamic(
id int,
name string,
hp_max int,
mp_max int,
attack_max int,
defense_max int,
attack_range string,
role_main string,
role_assist string
) partitioned by (role string)
row format delimited
fields terminated by "\t";
向动态分区表中插入数据:
0: jdbc:hive2://ops01:10000> insert into table t_all_hero_part_dynamic partition(role) select tmp.*,tmp.role_main from t_all_hero tmp;
No rows affected (29.625 seconds)
查询分区状态情况:
0: jdbc:hive2://ops01:10000> select distinct(role) from t_all_hero_part_dynamic ;
+-----------+
| role |
+-----------+
| archer |
| assassin |
| mage |
| support |
| tank |
| warrior |
+-----------+
6 rows selected (24.049 seconds)
分区表总结与注意事项
- 分区表不是建表的必要语法规则,是一种优化手段表,可选;
- 分区字段不能是表中已有的字段,不能重复;
- 分区字段是虚拟字段,其数据并不存储在底层的文件中;
- 分区字段值的确定来自于用户价值数据手动指定(静态分区)或者根据查询结果位置自动推断(动态分区)
- Hive支持多重分区,也就是说在分区的基础上继续分区,划分更加细粒度
7-3.Hive Bucketed Tables 分桶表
分桶表概念
- 分桶表也叫做桶表,叫法源自建表语法中bucket单词,是一种用于优化查询而设计的表类型。
- 分桶表对应的数据文件在底层会被分解为若干个部分,通俗来说就是被拆分成若干个独立的小文件。
- 在分桶时,要指定根据哪个字段将数据分为几桶(几个部分)。
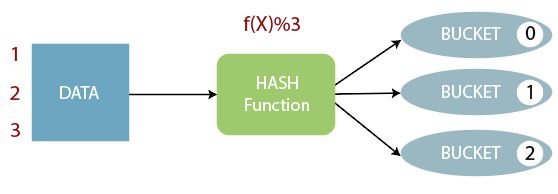
分桶规则
分桶规则如下:桶编号相同的数据会被分到同一个桶当中
Bucket number = hash_function(bucketing_column) mod num_buckets
分桶编号 = 哈希方法(分桶字段) 取模 分桶个数
hash_function取决于分桶字段bucketing_column的类型:
- 如果是int类型,hash_function(int) == int;
- 如果是其他比如bigint,string或者复杂数据类型,hash_function比较棘手,将是从该类型派生的某个数字,比如hashcode值。
分桶表语法
语法关键词:CLUSTERED BY (col_name)
--分桶表建表语句
CREATE [EXTERNAL] TABLE [db_name.]table_name
[(col_name data_type, ...)]
CLUSTERED BY (col_name)
INTO N BUCKETS;
- CLUSTERED BY (col_name)表示根据哪个字段进行分
- INTO N BUCKETS表示分为几桶(也就是几个部分)
- 需要注意的是,分桶的字段必须是表中已经存在的字段
分桶表的创建
数据集文件连接:
链接:https://pan.baidu.com/s/1cWq6wd0pfqaCRuBijt1WKg?pwd=cc6v
提取码:cc6v
下载解压文件包:
wangting@ops01:/home/wangting/20221013/usa >unzip us-civid19.zip
wangting@ops01:/home/wangting/20221013/usa >ll
total 46864
-rw-rw-r-- 1 wangting wangting 4318157 Jan 29 2021 COVID-19-Cases-USA-By-County.csv
-rw-rw-r-- 1 wangting wangting 116254 Jan 29 2021 COVID-19-Cases-USA-By-State.csv
-rw-rw-r-- 1 wangting wangting 2988679 Jan 29 2021 COVID-19-Deaths-USA-By-County.csv
-rw-rw-r-- 1 wangting wangting 86590 Jan 29 2021 COVID-19-Deaths-USA-By-State.csv
-rw-rw-r-- 1 wangting wangting 39693686 Jan 29 2021 us-counties.csv
-rw-rw-r-- 1 wangting wangting 136795 Sep 16 23:23 us-covid19-counties.dat
-rw-rw-r-- 1 wangting wangting 9135 Jan 29 2021 us.csv
-rw-rw-r-- 1 wangting wangting 620291 Jan 29 2021 us-states.csv
示例:
背景:
现有美国2021-1-28号,各个县county的新冠疫情累计案例信息,包括确诊病例和死亡病例,数据格式如下所示;
字段含义:count_date(统计日期),county(县),state(州),fips(县编码code),cases(累计确诊病例),deaths(累计死亡病例)样例数据:
2021-01-28,Autauga,Alabama,01001,5554,69 2021-01-28,Baldwin,Alabama,01003,17779,225 2021-01-28,Barbour,Alabama,01005,1920,40 2021-01-28,Bibb,Alabama,01007,2271,51 2021-01-28,Blount,Alabama,01009,5612,98 2021-01-28,Bullock,Alabama,01011,1079,29 2021-01-28,Butler,Alabama,01013,1788,60 2021-01-28,Calhoun,Alabama,01015,11833,231 2021-01-28,Chambers,Alabama,01017,3159,76 2021-01-28,Cherokee,Alabama,01019,1682,35
根据state州把数据分为5桶,建表语句如下
CREATE TABLE t_usa_covid19_bucket(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int)
CLUSTERED BY(state) INTO 5 BUCKETS;
在创建分桶表时,还可以指定分桶内的数据排序规则
CREATE TABLE t_usa_covid19_bucket_sort(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int)
CLUSTERED BY(state)
sorted by (cases desc) INTO 5 BUCKETS;
把源数据加载到普通hive表中,创建普通表t_usa_covid19 :
CREATE TABLE t_usa_covid19(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int)
row format delimited fields terminated by ",";
将映射文件上传hdfs对应普通表t_usa_covid19
# 将源数据上传到HDFS,t_usa_covid19表对应的路径下
wangting@ops01:/home/wangting/20221013/usa >hdfs dfs -put us-covid19-counties.dat /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19
0: jdbc:hive2://ops01:10000> select * from t_usa_covid19 limit 5;
+---------------------------+-----------------------+----------------------+---------------------+----------------------+-----------------------+
| t_usa_covid19.count_date | t_usa_covid19.county | t_usa_covid19.state | t_usa_covid19.fips | t_usa_covid19.cases | t_usa_covid19.deaths |
+---------------------------+-----------------------+----------------------+---------------------+----------------------+-----------------------+
| 2021-01-28 | Autauga | Alabama | 1001 | 5554 | 69 |
| 2021-01-28 | Baldwin | Alabama | 1003 | 17779 | 225 |
| 2021-01-28 | Barbour | Alabama | 1005 | 1920 | 40 |
| 2021-01-28 | Bibb | Alabama | 1007 | 2271 | 51 |
| 2021-01-28 | Blount | Alabama | 1009 | 5612 | 98 |
+---------------------------+-----------------------+----------------------+---------------------+----------------------+-----------------------+
5 rows selected (0.139 seconds)
使用insert+select语法将数据加载到分桶表t_usa_covid19_bucket中:
0: jdbc:hive2://ops01:10000> insert into t_usa_covid19_bucket select * from t_usa_covid19;
No rows affected (55.215 seconds)
- 到HDFS上查看t_usa_covid19_bucket底层数据结构可以发现,数据被分为了5个部分。
- 并且从结果可以发现,分桶字段一样的数据就一定被分到同一个桶中。
wangting@ops01:/home/wangting/20221013/usa >hdfs dfs -ls /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19
Found 1 items
-rw-r--r-- 3 wangting supergroup 136795 2022-10-14 16:33 /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19/us-covid19-counties.dat
wangting@ops01:/home/wangting/20221013/usa >hdfs dfs -ls /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19_bucket
Found 5 items
-rw-r--r-- 3 wangting supergroup 20013 2022-10-14 16:35 /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19_bucket/000000_0
-rw-r--r-- 3 wangting supergroup 33705 2022-10-14 16:34 /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19_bucket/000001_0
-rw-r--r-- 3 wangting supergroup 46572 2022-10-14 16:34 /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19_bucket/000002_0
-rw-r--r-- 3 wangting supergroup 11636 2022-10-14 16:34 /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19_bucket/000003_0
-rw-r--r-- 3 wangting supergroup 24766 2022-10-14 16:35 /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19_bucket/000004_0
# 简单查看一下文件情况
wangting@ops01:/home/wangting/20221013/usa >hdfs dfs -cat /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19_bucket/000000_0 | head -3
2021-01-28 RensselaerNew York 360837720116
2021-01-28 PutnamNew York 36079717179
2021-01-28 OtsegoNew York 36077194029
wangting@ops01:/home/wangting/20221013/usa >hdfs dfs -cat /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19_bucket/000001_0 | head -3
2021-01-28 SampsonNorth Carolina 37163604279
2021-01-28 RutherfordNorth Carolina 371616116166
2021-01-28 RowanNorth Carolina 3715912709241
使用粪桶表优点
- 基于分桶字段查询时,减少全表扫描
--基于分桶字段state查询来自于New York州的数据
--不再需要进行全表扫描过滤
--根据分桶的规则hash_function(New York) mod 5计算出分桶编号
--查询指定分桶里面的数据 就可以找出结果 此时是分桶扫描而不是全表扫描
select * from t_usa_covid19_bucket where state="New York";
- JOIN时可以提高MR程序效率,减少笛卡尔积数量
根据join的字段对表进行分桶操作(比如下图中id是join的字段)
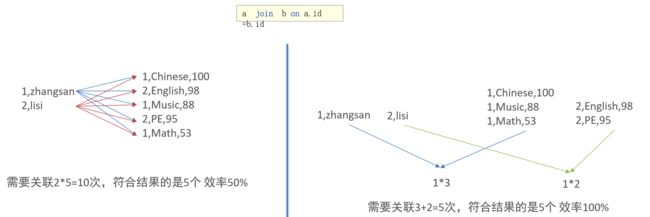
- 分桶表数据进行高效抽样
当数据量特别大时,对全体数据进行处理存在困难时,抽样就显得尤其重要了。抽样可以从被抽取的数据中估计和推断出整体的特性,是科学实验、质量检验、社会调查普遍采用的一种经济有效的工作和研究方法
7-4.Hive Transactional Tables事务表
Hive事务背景知识
-
Hive本身从设计之初时,就是不支持事务的,因为Hive的核心目标是将已经存在的结构化数据文件映射成为表,然后提供基于表的SQL分析处理,是一款面向分析的工具。且映射的数据通常存储于HDFS上,而HDFS是不支持随机修改文件数据的。
-
这个定位就意味着在早期的Hive的SQL语法中是没有update,delete操作的,也就没有所谓的事务支持了,因为都是select查询分析操作
-
从Hive0.14版本开始,具有ACID语义的事务已添加到Hive中,以解决以下场景下遇到的问题:
-
流式传输数据
- 使用如Apache Flume、Apache Kafka之类的工具将数据流式传输到Hadoop集群中。虽然这些工具可以每秒数百行或更多行的速度写入数据,但是Hive只能每隔15分钟到一个小时添加一次分区。如果每分甚至每秒频繁添加分区会很快导致表中大量的分区,并将许多小文件留在目录中,这将给NameNode带来压力。
- 因此通常使用这些工具将数据流式传输到已有分区中,但这有可能会造成脏读(数据传输一半失败,回滚了)。
需要通过事务功能,允许用户获得一致的数据视图并避免过多的小文件产生
-
尺寸变化缓慢
- 星型模式数据仓库中,维度表随时间缓慢变化。例如,零售商将开设新商店,需要将其添加到商店表中,或者现有商店可能会更改其平方英尺或某些其他跟踪的特征。这些更改导致需要插入单个记录或更新单条记录(取决于所选策略)
-
数据重述
- 有时发现收集的数据不正确,需要更正
-
Hive事务局限性
虽然Hive支持了具有ACID语义的事务,但是在使用起来,并没有像在MySQL中使用那样方便,有很多局限性。原因很简单,毕竟Hive的设计目标不是为了支持事务操作,而是支持分析操作,且最终基于HDFS的底层存储机制使得文件的增加删除修改操作需要动一些小心思。
- 尚不支持BEGIN,COMMIT和ROLLBACK。所有语言操作都是自动提交的。
- 仅支持ORC文件格式(STORED AS ORC)。
- 默认情况下事务配置为关闭。需要配置参数开启使用。
- 表必须是分桶表(Bucketed)才可以使用事务功能。
- 表参数transactional必须为true;
- 外部表不能成为ACID表,不允许从非ACID会话读取/写入ACID表。
创建使用Hive表尝试修改数据
背景:
在Hive中创建一张具备事务功能的表,并尝试进行增删改操作。
体验一下Hive的增删改操作和MySQL比较起来,性能如何
- 如果不做任何配置修改,直接针对Hive中已有的表进行Update、Delete、Insert操作,可以发现,只有insert语句可以执行,Update和Delete操作会报错。
- Insert插入操作能够成功的原因在于,底层是直接把数据写在一个新的文件中的
先创建一张普通的表:
create table student(
num int,
name string,
sex string,
age int,
dept string)
row format delimited
fields terminated by ',';
加载数据文件:
students.txt文件内容
95001,李勇,男,20,CS
95002,刘晨,女,19,IS
95003,王敏,女,22,MA
95004,张立,男,19,IS
95005,刘刚,男,18,MA
95006,孙庆,男,23,CS
95007,易思玲,女,19,MA
95008,李娜,女,18,CS
95009,梦圆圆,女,18,MA
95010,孔小涛,男,19,CS
95011,包小柏,男,18,MA
95012,孙花,女,20,CS
95013,冯伟,男,21,CS
95014,王小丽,女,19,CS
95015,王君,男,18,MA
95016,钱国,男,21,MA
95017,王风娟,女,18,IS
95018,王一,女,19,IS
95019,邢小丽,女,19,IS
95020,赵钱,男,21,IS
95021,周二,男,17,MA
95022,郑明,男,20,MA
wangting@ops01:/home/wangting/20221013 >hdfs dfs -put students.txt /user/hive/warehouse/hv_2022_10_13.db/student
执行数据修改操作:
0: jdbc:hive2://ops01:10000> select * from student limit 3;
+--------------+---------------+--------------+--------------+---------------+
| student.num | student.name | student.sex | student.age | student.dept |
+--------------+---------------+--------------+--------------+---------------+
| 95001 | 李勇 | 男 | 20 | CS |
| 95002 | 刘晨 | 女 | 19 | IS |
| 95003 | 王敏 | 女 | 22 | MA |
+--------------+---------------+--------------+--------------+---------------+
3 rows selected (0.12 seconds)
0: jdbc:hive2://ops01:10000> update student set age = 100 where num = 95001;
Error: Error while compiling statement: FAILED: SemanticException [Error 10294]: Attempt to do update or delete using transaction manager that does not support these operations. (state=42000,code=10294)
注意此时出现了报错
FAILED: SemanticException [Error 10294]: Attempt to do update or delete using transaction manager that does not support these operations. (state=42000,code=10294)
这是因为没有开启事务导致的抛错
配置开启事务、创建事务表
创建表
--1、开启事务配置(可以使用set设置当前session生效 也可以配置在hive-site.xml中)
-- set hive.support.concurrency = true; --Hive是否支持并发
-- set hive.enforce.bucketing = true; --从Hive2.0开始不再需要 是否开启分桶功能
-- set hive.exec.dynamic.partition.mode = nonstrict; --动态分区模式 非严格
-- set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; --
-- set hive.compactor.initiator.on = true; --是否在Metastore实例上运行启动线程和清理线程
-- set hive.compactor.worker.threads = 1; --在此metastore实例上运行多少个压缩程序工作线程。
0: jdbc:hive2://ops01:10000> set hive.support.concurrency = true;
No rows affected (0.004 seconds)
0: jdbc:hive2://ops01:10000> set hive.enforce.bucketing = true;
No rows affected (0.003 seconds)
0: jdbc:hive2://ops01:10000> set hive.exec.dynamic.partition.mode = nonstrict;
No rows affected (0.003 seconds)
0: jdbc:hive2://ops01:10000> set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
No rows affected (0.003 seconds)
0: jdbc:hive2://ops01:10000> set hive.compactor.initiator.on = true;
No rows affected (0.003 seconds)
0: jdbc:hive2://ops01:10000> set hive.compactor.worker.threads = 1;
No rows affected (0.004 seconds)
--2、创建Hive事务表
create table trans_student(
id int,
name String,
age int
)clustered by (id) into 2 buckets stored as orc TBLPROPERTIES('transactional'='true');
--注意 事务表创建几个要素:开启参数、分桶表、存储格式orc、表属性
针对事务表进行增删改查操作验证:
0: jdbc:hive2://ops01:10000> insert into trans_student values(1,"wangting",666);
No rows affected (53.575 seconds)
0: jdbc:hive2://ops01:10000> select * from trans_student;
+-------------------+---------------------+--------------------+
| trans_student.id | trans_student.name | trans_student.age |
+-------------------+---------------------+--------------------+
| 1 | wangting | 666 |
+-------------------+---------------------+--------------------+
1 row selected (0.36 seconds)
0: jdbc:hive2://ops01:10000> update trans_student set age = 18 where id = 1;
No rows affected (26.142 seconds)
0: jdbc:hive2://ops01:10000> select * from trans_student;
+-------------------+---------------------+--------------------+
| trans_student.id | trans_student.name | trans_student.age |
+-------------------+---------------------+--------------------+
| 1 | wangting | 18 |
+-------------------+---------------------+--------------------+
1 row selected (0.199 seconds)
0: jdbc:hive2://ops01:10000> delete from trans_student where id =1;
No rows affected (26.221 seconds)
0: jdbc:hive2://ops01:10000> select * from trans_student;
+-------------------+---------------------+--------------------+
| trans_student.id | trans_student.name | trans_student.age |
+-------------------+---------------------+--------------------+
+-------------------+---------------------+--------------------+
No rows selected (0.203 seconds)
7-5.Hive Views 视图
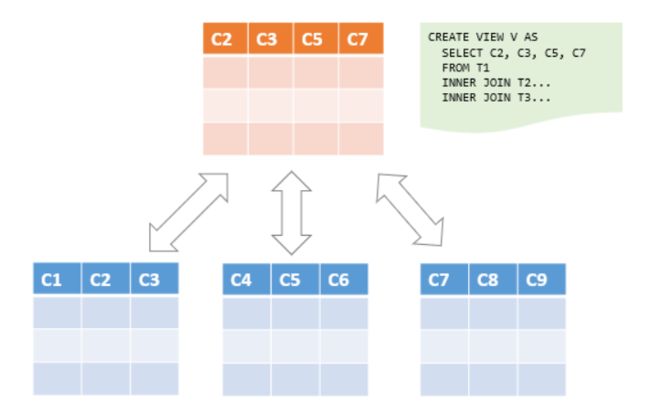
视图概念
- Hive中的视图(view)是一种虚拟表,只保存定义,不实际存储数据。
- 通常从真实的物理表查询中创建生成视图,也可以从已经存在的视图上创建新视图。
- 创建视图时,将冻结视图的架构,如果删除或更改基础表,则视图将失败。
- 视图是用来简化操作的,不缓冲记录,也没有提高查询性能。
相关语法示例:
--hive中有一张真实的基础表t_usa_covid19,
-- 表名:t_usa_covid19
--1、创建视图
0: jdbc:hive2://ops01:10000> select count_date, county,state,deaths from t_usa_covid19 limit 5;
+-------------+----------+----------+---------+
| count_date | county | state | deaths |
+-------------+----------+----------+---------+
| 2021-01-28 | Autauga | Alabama | 69 |
| 2021-01-28 | Baldwin | Alabama | 225 |
| 2021-01-28 | Barbour | Alabama | 40 |
| 2021-01-28 | Bibb | Alabama | 51 |
| 2021-01-28 | Blount | Alabama | 98 |
+-------------+----------+----------+---------+
5 rows selected (0.156 seconds)
0: jdbc:hive2://ops01:10000> create view v_usa_covid19 as select count_date, county,state,deaths from t_usa_covid19 limit 5;
No rows affected (0.193 seconds)
-- 查看视图表
0: jdbc:hive2://ops01:10000> select * from v_usa_covid19;
+---------------------------+-----------------------+----------------------+-----------------------+
| v_usa_covid19.count_date | v_usa_covid19.county | v_usa_covid19.state | v_usa_covid19.deaths |
+---------------------------+-----------------------+----------------------+-----------------------+
| 2021-01-28 | Autauga | Alabama | 69 |
| 2021-01-28 | Baldwin | Alabama | 225 |
| 2021-01-28 | Barbour | Alabama | 40 |
| 2021-01-28 | Bibb | Alabama | 51 |
| 2021-01-28 | Blount | Alabama | 98 |
+---------------------------+-----------------------+----------------------+-----------------------+
5 rows selected (0.181 seconds)
-- 验证能否从已有的视图中创建视图
0: jdbc:hive2://ops01:10000> create view v_usa_covid19_from_view as select * from v_usa_covid19 limit 2;
No rows affected (0.205 seconds)
0: jdbc:hive2://ops01:10000> select * from v_usa_covid19_from_view;
+-------------------------------------+---------------------------------+--------------------------------+---------------------------------+
| v_usa_covid19_from_view.count_date | v_usa_covid19_from_view.county | v_usa_covid19_from_view.state | v_usa_covid19_from_view.deaths |
+-------------------------------------+---------------------------------+--------------------------------+---------------------------------+
| 2021-01-28 | Autauga | Alabama | 69 |
| 2021-01-28 | Baldwin | Alabama | 225 |
+-------------------------------------+---------------------------------+--------------------------------+---------------------------------+
2 rows selected (0.188 seconds)
--2、显示当前已有的视图
0: jdbc:hive2://ops01:10000> show views;
+--------------------------+
| tab_name |
+--------------------------+
| v_usa_covid19 |
| v_usa_covid19_from_view |
+--------------------------+
2 rows selected (0.03 seconds)
-- 验证能否插入数据到视图中
--不行 报错 SemanticException:A view cannot be used as target table for LOAD or INSERT
0: jdbc:hive2://ops01:10000> insert into v_usa_covid19 select count_date,county,state,deaths from t_usa_covid19;
Error: Error while compiling statement: FAILED: SemanticException [Error 10090]: A view cannot be used as target table for LOAD or INSERT (state=42000,code=10090)
--4、查看视图定义
0: jdbc:hive2://ops01:10000> show create table v_usa_covid19;
+----------------------------------------------------+
| createtab_stmt |
+----------------------------------------------------+
| CREATE VIEW `v_usa_covid19` AS select `t_usa_covid19`.`count_date`, `t_usa_covid19`.`county`,`t_usa_covid19`.`state`,`t_usa_covid19`.`deaths` from `hv_2022_10_13`.`t_usa_covid19` limit 5 |
+----------------------------------------------------+
1 row selected (0.075 seconds)
--5、删除视图
0: jdbc:hive2://ops01:10000> drop view v_usa_covid19_from_view;
No rows affected (0.111 seconds)
--6、更改视图属性
0: jdbc:hive2://ops01:10000> alter view v_usa_covid19 set TBLPROPERTIES ('comment' = 'This is a view');
No rows affected (0.087 seconds)
--7、更改视图定义
0: jdbc:hive2://ops01:10000> alter view v_usa_covid19 as select county,deaths from t_usa_covid19 limit 2;
No rows affected (0.118 seconds)
0: jdbc:hive2://ops01:10000> select * from v_usa_covid19;
+-----------------------+-----------------------+
| v_usa_covid19.county | v_usa_covid19.deaths |
+-----------------------+-----------------------+
| Autauga | 69 |
| Baldwin | 225 |
+-----------------------+-----------------------+
2 rows selected (0.166 seconds)
使用视图优点
- 将真实表中特定的列数据提供给用户,保护数据隐式
- 降低查询的复杂度,优化查询语句
7-6.Hive3.0新特性物化视图
物化视图概念
- 物化视图(Materialized View)是一个包括查询结果的数据库对像,可以用于预先计算并保存表连接或聚集等耗时较多的操作的结果。在执行查询时,就可以避免进行这些耗时的操作,而从快速的得到结果
- 使用物化视图的目的就是通过预计算,提高查询性能,当然需要占用一定的存储空间
- Hive3.0开始尝试引入物化视图,并提供对于物化视图的查询自动重写机制(基于Apache Calcite实现)
- Hive的物化视图还提供了物化视图存储选择机制,可以本地存储在Hive,也可以通过用户自定义storage handlers存储在其他系统(如Druid)
- Hive引入物化视图的目的就是为了优化数据查询访问的效率,相当于从数据预处理的角度优化数据访问
- Hive从3.0丢弃了index索引的语法支持,推荐使用物化视图和列式存储文件格式来加快查询的速度
物化视图与视图区别
- 视图是虚拟的,逻辑存在的,只有定义没有存储数据
- 物化视图是真实的,物理存在的,里面存储着预计算的数据
- 视图的目的是简化降低查询的复杂度,而物化视图的目的是提高查询性能
物化视图能够缓存数据,在创建物化视图的时候就把数据缓存起来了,Hive把物化视图当成一张“表”,将数据缓存。而视图只是创建一个虚表,只有表结构,没有数据,实际查询的时候再去改写SQL去访问实际的数据表
物化视图语法
--物化视图的创建语法
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db_name.]materialized_view_name
[DISABLE REWRITE]
[COMMENT materialized_view_comment]
[PARTITIONED ON (col_name, ...)]
[CLUSTERED ON (col_name, ...) | DISTRIBUTED ON (col_name, ...) SORTED ON (col_name, ...)]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)]
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
AS SELECT ...;
-
物化视图创建后,select查询执行数据自动落地,“自动”也即在query的执行期间,任何用户对该物化视图是不可见的,执行完毕之后物化视图可用;
-
默认情况下,创建好的物化视图可被用于查询优化器optimizer查询重写,在物化视图创建期间可以通过DISABLE REWRITE参数设置禁止使用
-
默认SerDe和storage format为hive.materializedview.serde、 hive.materializedview.fileformat
-
物化视图支持将数据存储在外部系统(如druid),如下述语法所示:
CREATE MATERIALIZED VIEW druid_wiki_mv STORED AS 'org.apache.hadoop.hive.druid.DruidStorageHandler' AS SELECT __time, page, user, c_added, c_removed FROM src; -
目前支持物化视图的drop和show操作
DROP MATERIALIZED VIEW [db_name.]materialized_view_name;
SHOW MATERIALIZED VIEWS [IN database_name];
DESCRIBE [EXTENDED | FORMATTED] [db_name.]materialized_view_name;
6. 当数据源变更(新数据插入inserted、数据修改modified),物化视图也需要更新以保持数据一致性,目前需要用户主动触发rebuild重构
```sql
ALTER MATERIALIZED VIEW [db_name.]materialized_view_name REBUILD;
基于物化视图的查询重写
-
物化视图创建后即可用于相关查询的加速,即:用户提交查询query,若该query经过重写后可以命中已经存在的物化视图,则直接通过物化视图查询数据返回结果,以实现查询加速
-
是否重写查询使用物化视图可以通过全局参数控制,默认为true: hive.materializedview.rewriting=true;
-
用户可选择性的控制指定的物化视图查询重写机制,语法如下:
-
ALTER MATERIALIZED VIEW [db_name.]materialized_view_name ENABLE|DISABLE REWRITE;
-
物化视图案例
背景:基于物化视图的查询重写
- 用户提交查询query
- 若该query经过重写后可以命中已经存在的物化视图
- 则直接通过物化视图查询数据返回结果,以实现查询加速
-- 表student数据内容:
0: jdbc:hive2://ops01:10000> select * from student;
+--------------+---------------+--------------+--------------+---------------+
| student.num | student.name | student.sex | student.age | student.dept |
+--------------+---------------+--------------+--------------+---------------+
| 95001 | 李勇 | 男 | 20 | CS |
| 95002 | 刘晨 | 女 | 19 | IS |
| 95003 | 王敏 | 女 | 22 | MA |
| 95004 | 张立 | 男 | 19 | IS |
| 95005 | 刘刚 | 男 | 18 | MA |
| 95006 | 孙庆 | 男 | 23 | CS |
| 95007 | 易思玲 | 女 | 19 | MA |
| 95008 | 李娜 | 女 | 18 | CS |
| 95009 | 梦圆圆 | 女 | 18 | MA |
| 95010 | 孔小涛 | 男 | 19 | CS |
| 95011 | 包小柏 | 男 | 18 | MA |
| 95012 | 孙花 | 女 | 20 | CS |
| 95013 | 冯伟 | 男 | 21 | CS |
| 95014 | 王小丽 | 女 | 19 | CS |
| 95015 | 王君 | 男 | 18 | MA |
| 95016 | 钱国 | 男 | 21 | MA |
| 95017 | 王风娟 | 女 | 18 | IS |
| 95018 | 王一 | 女 | 19 | IS |
| 95019 | 邢小丽 | 女 | 19 | IS |
| 95020 | 赵钱 | 男 | 21 | IS |
| 95021 | 周二 | 男 | 17 | MA |
| 95022 | 郑明 | 男 | 20 | MA |
+--------------+---------------+--------------+--------------+---------------+
22 rows selected (0.156 seconds)
-- 新建一张事务表 student_trans,先开启事务相关配置项
0: jdbc:hive2://ops01:10000> set hive.support.concurrency = true;
0: jdbc:hive2://ops01:10000> set hive.enforce.bucketing = true;
0: jdbc:hive2://ops01:10000> set hive.exec.dynamic.partition.mode = nonstrict;
0: jdbc:hive2://ops01:10000> set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
0: jdbc:hive2://ops01:10000> set hive.compactor.initiator.on = true;
0: jdbc:hive2://ops01:10000> set hive.compactor.worker.threads = 1;
-- 创建事务表student_trans
CREATE TABLE student_trans (
sno int,
sname string,
sdept string)
clustered by (sno) into 2 buckets stored as orc TBLPROPERTIES('transactional'='true');
-- 从原student表导入数据到student_trans中
0: jdbc:hive2://ops01:10000> insert overwrite table student_trans select num,name,dept from student;
No rows affected (54.344 seconds)
0: jdbc:hive2://ops01:10000> select * from student_trans;
+--------------------+----------------------+----------------------+
| student_trans.sno | student_trans.sname | student_trans.sdept |
+--------------------+----------------------+----------------------+
| 95022 | 郑明 | MA |
| 95010 | 孔小涛 | CS |
| 95016 | 钱国 | MA |
| 95008 | 李娜 | CS |
| 95018 | 王一 | IS |
| 95006 | 孙庆 | CS |
| 95014 | 王小丽 | CS |
| 95004 | 张立 | IS |
| 95020 | 赵钱 | IS |
| 95002 | 刘晨 | IS |
| 95012 | 孙花 | CS |
| 95011 | 包小柏 | MA |
| 95021 | 周二 | MA |
| 95019 | 邢小丽 | IS |
| 95017 | 王风娟 | IS |
| 95015 | 王君 | MA |
| 95013 | 冯伟 | CS |
| 95009 | 梦圆圆 | MA |
| 95007 | 易思玲 | MA |
| 95005 | 刘刚 | MA |
| 95003 | 王敏 | MA |
| 95001 | 李勇 | CS |
+--------------------+----------------------+----------------------+
22 rows selected (0.188 seconds)
-- 对student_trans建立聚合物化视图
0: jdbc:hive2://ops01:10000> CREATE MATERIALIZED VIEW student_trans_agg AS SELECT sdept, count(*) as sdept_cnt from student_trans group by sdept;
No rows affected (25.603 seconds)
-- 通过show materialized查看物化视图清单
0: jdbc:hive2://ops01:10000> show materialized views;
+--------------------+
| tab_name |
+--------------------+
| student_trans_agg |
+--------------------+
1 row selected (0.064 seconds)
-- SELECT sdept, count(*) as sdept_cnt from student_trans -> 走物化视图student_trans_agg
-- 对原始表student_trans查询
-- 由于会命中物化视图,重写query查询物化视图,查询速度会加快(没有启动MR,只是普通的table scan)
0: jdbc:hive2://ops01:10000> SELECT sdept, count(*) as sdept_cnt from student_trans group by sdept;
+--------+------------+
| sdept | sdept_cnt |
+--------+------------+
| CS | 7 |
| IS | 6 |
| MA | 9 |
+--------+------------+
3 rows selected (0.378 seconds)
-- 通过explain来查询SELECT执行情况,可以看到查询走了alias: hv_2022_10_13.student_trans_agg
0: jdbc:hive2://ops01:10000> explain SELECT sdept, count(*) as sdept_cnt from student_trans group by sdept;
+----------------------------------------------------+
| Explain |
+----------------------------------------------------+
| STAGE DEPENDENCIES: |
| Stage-0 is a root stage |
| STAGE PLANS: |
| Stage: Stage-0 |
| Fetch Operator |
| limit: -1 |
| Processor Tree: |
| TableScan |
| alias: hv_2022_10_13.student_trans_agg |
| Statistics: Num rows: 3 Data size: 282 Basic stats: COMPLETE Column stats: NONE |
| Select Operator |
| expressions: sdept (type: string), sdept_cnt (type: bigint) |
| outputColumnNames: _col0, _col1 |
| Statistics: Num rows: 3 Data size: 282 Basic stats: COMPLETE Column stats: NONE |
| ListSink |
+----------------------------------------------------+
17 rows selected (0.207 seconds)
第8章:Hive SQL DDL其他语法
8-1.Database|Schema(数据库)DDL操作
- 在Hive中,DATABASE的概念和RDBMS中类似,我们称之为数据库,DATABASE和SCHEMA是可互换的,都可以使用
- 默认的数据库叫做default,存储数据位置位于/user/hive/warehouse下
- 用户自己创建的数据库存储位置是/user/hive/warehouse/database_name.db下
create database
- create database用于创建新的数据库
- COMMENT:数据库的注释说明语句
- LOCATION:指定数据库在HDFS存储位置,默认/user/hive/warehouse/dbname.db
- WITH DBPROPERTIES:用于指定一些数据库的属性配置
--创建数据库
create database if not exists hv_2022_10_13
comment "this is my first db"
with dbproperties ('createdBy'='Allen');
如果需要使用location指定路径的时候,最好指向的是一个新创建的空文件夹
describe database
- 显示Hive中数据库的名称,注释(如果已设置)及其在文件系统上的位置等信息
- EXTENDED关键字用于显示更多信息。可以将关键字describe简写成desc使用
-- DESCRIBE DATABASE/SCHEMA [EXTENDED] db_name;
0: jdbc:hive2://ops01:10000> describe database hv_2022_10_13;
0: jdbc:hive2://ops01:10000> desc database hv_2022_10_13;
0: jdbc:hive2://ops01:10000> describe schema hv_2022_10_13;
use database
- 选择指定的数据库
drop database
- 删除数据库
- 默认行为是RESTRICT,这意味着仅在数据库为空时才删除它
- 要删除带有表的数据库(不为空的数据库),我们可以使用CASCADE
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
alter database
- 更改与Hive中的数据库关联的元数据
--更改数据库属性
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...);
--更改数据库所有者
ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role;
--更改数据库位置
ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path;
8-2.Table(表)DDL操作
- Hive中针对表的DDL操作可以说是DDL中的核心操作,包括建表、修改表、删除表、描述表元数据信息。
- 其中以建表语句为核心中的核心,详见Hive DDL建表语句。
- 可以说表的定义是否成功直接影响着数据能够成功映射,进而影响是否可以顺利的使用Hive开展数据分析。
- 由于Hive建表之后加载映射数据很快,实际中如果建表有问题,可以不用修改,直接删除重建。
describe table
- 显示Hive中表的元数据信息
- 如果指定了EXTENDED关键字,则它将以Thrift序列化形式显示表的所有元数据。
- 如果指定了FORMATTED关键字,则它将以表格格式显示元数据
describe formatted student;
drop table
- 删除该表的元数据和数据
- 如果已配置垃圾桶且未指定PURGE,则该表对应的数据实际上将移动到HDFS垃圾桶,而元数据完全丢失
- 删除EXTERNAL表时,该表中的数据不会从文件系统中删除,只删除元数据
- 如果指定了PURGE,则表数据跳过HDFS垃圾桶直接被删除。因此如果DROP失败,则无法挽回该表数据
DROP TABLE [IF EXISTS] table_name [PURGE];
truncate table
- 从表中删除所有行
可以简单理解为清空表的所有数据但是保留表的元数据结构
如果HDFS启用了垃圾桶,数据将被丢进垃圾桶,否则将被删除
TRUNCATE [TABLE] table_name;
alter table
- 修改表的元数据信息,数据约束变动
--1、更改表名
ALTER TABLE table_name RENAME TO new_table_name;
--2、更改表属性
ALTER TABLE table_name SET TBLPROPERTIES (property_name = property_value, ... );
--更改表注释
ALTER TABLE table_name SET TBLPROPERTIES ('comment' = "comment info");
--3、更改SerDe属性
ALTER TABLE table_name SET SERDE serde_class_name [WITH SERDEPROPERTIES (property_name = property_value, ... )];
ALTER TABLE table_name [PARTITION partition_spec] SET SERDEPROPERTIES serde_properties;
ALTER TABLE table_name SET SERDEPROPERTIES ('field.delim' = ',');
--移除SerDe属性
ALTER TABLE table_name [PARTITION partition_spec] UNSET SERDEPROPERTIES (property_name, ... );
--4、更改表的文件存储格式 该操作仅更改表元数据。现有数据的任何转换都必须在Hive之外进行。
ALTER TABLE table_name SET FILEFORMAT file_format;
--5、更改表的存储位置路径
ALTER TABLE table_name SET LOCATION "new location";
--6、更改列名称/类型/位置/注释
0: jdbc:hive2://ops01:10000> CREATE TABLE test_change (a int, b int, c int);
No rows affected (0.243 seconds)
0: jdbc:hive2://ops01:10000> desc test_change;
+-----------+------------+----------+
| col_name | data_type | comment |
+-----------+------------+----------+
| a | int | |
| b | int | |
| c | int | |
+-----------+------------+----------+
3 rows selected (0.086 seconds)
0: jdbc:hive2://ops01:10000> ALTER TABLE test_change CHANGE a a1 INT;
No rows affected (0.145 seconds)
0: jdbc:hive2://ops01:10000> desc test_change;
+-----------+------------+----------+
| col_name | data_type | comment |
+-----------+------------+----------+
| a1 | int | |
| b | int | |
| c | int | |
+-----------+------------+----------+
3 rows selected (0.074 seconds)
0: jdbc:hive2://ops01:10000> ALTER TABLE test_change CHANGE a1 a2 STRING AFTER b;
No rows affected (0.123 seconds)
0: jdbc:hive2://ops01:10000> desc test_change;
+-----------+------------+----------+
| col_name | data_type | comment |
+-----------+------------+----------+
| b | int | |
| a2 | string | |
| c | int | |
+-----------+------------+----------+
3 rows selected (0.081 seconds)
8-3.Partition(分区)DDL操作
Hive中针对分区Partition的操作主要包括:
- 增加分区 add partition
- 删除分区 delete partition
- 重命名分区 rename partition
- 修复分区 MSCK partition
- 修改分区 alter partition
add partition
- ADD PARTITION会更改表元数据,但不会加载数据。如果分区位置中不存在数据,查询时将不会返回结果。
- 因此需要保证增加的分区位置路径下,数据已经存在,或者增加完分区之后导入分区数据
-- 增加一个分区
ALTER TABLE table_name ADD PARTITION (province='xxx') location '/user/hive/warehouse/database_name.db/table_name/province=xxx';
-- 一次增加多个分区
ALTER TABLE table_name ADD PARTITION (dt='2022-10-17', country='china') location 'xxx' PARTITION (dt='2022-10-18', country='china') location 'xxxxx';
rename partition
- 重命名已有分区
ALTER TABLE table_name PARTITION (province ="xxx") RENAME TO PARTITION (province ="yyy");
delete partition
- 删除表的分区。这将删除该分区的数据和元数据
ALTER TABLE table_name DROP [IF EXISTS] PARTITION (dt='xxx');
-- 带有PURGE参数时,直接删除对应数据,不进回收垃圾桶
ALTER TABLE table_name DROP [IF EXISTS] PARTITION (dt='xxx') PURGE;
alter partition
- 修改分区
--更改分区文件存储格式
ALTER TABLE table_name PARTITION (dt='2022-10-17') SET FILEFORMAT file_format;
--更改分区位置设置成新的路径xxx
ALTER TABLE table_name PARTITION (dt='2022-10-17') SET LOCATION "xxx";
MSCK partition
- Hive将每个表的分区列表信息存储在其metastore中。但是,如果将新分区直接添加到HDFS(例如通过使用hadoop fs -put命令)或从HDFS中直接删除分区文件夹,则除非用户ALTER TABLE table_name ADD/DROP PARTITION在每个新添加的分区上运行命令,否则metastore(也就是Hive)将不会意识到分区信息的这些更改。
- MSCK是metastore check的缩写,表示元数据检查操作,可用于元数据的修复
语法:
--4、修复分区
MSCK [REPAIR] TABLE table_name [ADD/DROP/SYNC PARTITIONS];
- MSCK默认行为ADD PARTITIONS,使用此选项,它将把HDFS上存在但元存储中不存在的所有分区添加到metastore。
- DROP PARTITIONS选项将从已经从HDFS中删除的metastore中删除分区信息。
- SYNC PARTITIONS选项等效于调用ADD和DROP PARTITIONS。
- 如果存在大量未跟踪的分区,则可以批量运行MSCK REPAIR TABLE,以避免OOME(内存不足错误)。
MSCK partition案例
背景:Hive MSCK 修复partition
- 创建一张分区表,直接使用HDFS命令在表文件夹下创建分区文件夹并上传数据,此时在Hive中查询是无法显示表数据的,因为metastore中没有记录,使用MSCK ADD PARTITIONS进行修复。
- 针对分区表,直接使用HDFS命令删除分区文件夹,此时在Hive中查询显示分区还在,因为metastore中还没有被删除,使用MSCK DROP PARTITIONS进行修复。
-- 创建分区表t_all_hero_part_msck
create table t_all_hero_part_msck(
id int,
name string,
hp_max int,
mp_max int,
attack_max int,
defense_max int,
attack_range string,
role_main string,
role_assist string
) partitioned by (role string)
row format delimited
fields terminated by "\t";
# 手动创建分区目录以及上传数据文件
wangting@ops01:/home/wangting/20221013 >cd hero/
wangting@ops01:/home/wangting/20221013/hero >ls
archer.txt assassin.txt mage.txt support.txt tank.txt warrior.txt
wangting@ops01:/home/wangting/20221013/hero >hadoop fs -mkdir -p /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part_msck/role=sheshou
wangting@ops01:/home/wangting/20221013/hero >hadoop fs -mkdir -p /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part_msck/role=tanke
wangting@ops01:/home/wangting/20221013/hero >hadoop fs -put archer.txt /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part_msck/role=sheshou
wangting@ops01:/home/wangting/20221013/hero >hadoop fs -put tank.txt /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part_msck/role=tanke
-- 查看表数据
0: jdbc:hive2://ops01:10000> select count(*) from t_all_hero_part_msck;
+------+
| _c0 |
+------+
| 0 |
+------+
1 row selected (0.167 seconds)
-- 修复表
0: jdbc:hive2://ops01:10000> MSCK repair table t_all_hero_part_msck add partitions;
No rows affected (0.191 seconds)
-- 再次查看表数据,数据文件修复后映射上
0: jdbc:hive2://ops01:10000> select count(*) from t_all_hero_part_msck;
+------+
| _c0 |
+------+
| 20 |
+------+
1 row selected (28.109 seconds)
尝试手动删除hdfs分区目录
wangting@ops01:/home/wangting/20221013/hero >hdfs dfs -ls /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part_msck/
Found 2 items
drwxr-xr-x - wangting supergroup 0 2022-10-17 13:59 /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part_msck/role=sheshou
drwxr-xr-x - wangting supergroup 0 2022-10-17 13:59 /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part_msck/role=tanke
wangting@ops01:/home/wangting/20221013/hero >hadoop fs -rm -r /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part_msck/role=sheshou
Deleted /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part_msck/role=sheshou
wangting@ops01:/home/wangting/20221013/hero >hdfs dfs -ls /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part_msck/
Found 1 items
drwxr-xr-x - wangting supergroup 0 2022-10-17 13:59 /user/hive/warehouse/hv_2022_10_13.db/t_all_hero_part_msck/role=tanke
-- 查看表的分区记录,已经删除hdfs的role=sheshou,但依旧可以查到
0: jdbc:hive2://ops01:10000> show partitions t_all_hero_part_msck;
+---------------+
| partition |
+---------------+
| role=sheshou |
| role=tanke |
+---------------+
2 rows selected (0.07 seconds)
-- 修复表drop partitions
0: jdbc:hive2://ops01:10000> MSCK repair table t_all_hero_part_msck drop partitions;
No rows affected (0.143 seconds)
-- 再次查看分区,结果正确显示
0: jdbc:hive2://ops01:10000> show partitions t_all_hero_part_msck;
+-------------+
| partition |
+-------------+
| role=tanke |
+-------------+
1 row selected (0.076 seconds)
第9章:Hive Show语法
- Show相关的语句提供了一种查询Hive metastore的方法。可以帮助用户查询相关信息。
常用语句:
--1、显示所有数据库
show databases;
show schemas;
--2、显示当前数据库所有表/视图/物化视图/分区/索引
show tables;
SHOW TABLES [IN database_name]; --指定某个数据库
--3、显示当前数据库下所有视图
Show Views;
-- test_开头的视图
SHOW VIEWS 'test_*';
-- test1库的所有视图
SHOW VIEWS FROM test1;
SHOW VIEWS [IN/FROM database_name];
--4、显示当前数据库下所有物化视图
SHOW MATERIALIZED VIEWS [IN/FROM database_name];
--5、显示表分区信息,分区按字母顺序列出,不是分区表执行该语句会报错
show partitions table_name;
--6、显示表/分区的扩展信息
SHOW TABLE EXTENDED [IN|FROM database_name] LIKE table_name;
show table extended like student;
describe formatted database_name.table_name;
--7、显示表的属性信息
SHOW TBLPROPERTIES table_name;
show tblproperties table_name;
--8、显示表、视图的创建语句
SHOW CREATE TABLE ([db_name.]table_name|view_name);
show create table table_name;
--9、显示表中的所有列,包括分区列。
SHOW COLUMNS (FROM|IN) table_name [(FROM|IN) db_name];
show columns in table_name;
--10、显示当前支持的所有自定义和内置的函数
show functions;
--11、Describe desc
--查看表信息
desc extended table_name;
--查看表信息(格式化美观)
desc formatted table_name;
--查看数据库相关信息
describe database database_name;
第10章:Hive SQL-DML-Load加载数据
10-1.Hive Load 功能与语法规则
load加载功能
- Load英文单词的含义为:加载、装载;
- 所谓加载是指:将数据文件移动到与Hive表对应的位置,移动时是纯复制、移动操作。
- 纯复制、移动指在数据load加载到表中时,Hive不会对表中的数据内容进行任何转换,任何操作
load语法规则
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] [INPUTFORMAT 'inputformat' SERDE 'serde'] (3.0 or later)
filepath
- filepath表示待移动数据的路径。可以指向文件(在这种情况下,Hive将文件移动到表中),也可以指向目录(在这种情况下,Hive将把该目录中的所有文件移动到表中)
- filepath文件路径支持下面三种形式,要结合LOCAL关键字一起考虑
- 相对路径,例如:project/data1
- 绝对路径,例如:/user/hive/project/data1
- 具有schema的完整URI,例如:hdfs://host_ip:9000/user/hive/project/data1
LOCAL
- 指定LOCAL, 将在本地文件系统中查找文件路径
- 若指定相对路径,将相对于用户的当前工作目录进行解释
- 用户也可以为本地文件指定完整的URI-例如:file:///user/hive/project/data1
- 没有指定LOCAL关键字
- 如果filepath指向的是一个完整的URI,会直接使用这个URI
- 如果没有指定schema,Hive会使用在hadoop配置文件中参数fs.default.name指定的
LOCAL本地概念
如果对HiveServer2服务运行此命令
则本地文件系统指的是Hiveserver2服务所在机器的本地Linux文件系统,不是Hive客户端所在的本地文件系统
OVERWRITE
如果使用了OVERWRITE关键字,则目标表(或者分区)中的已经存在的数据会被删除,然后再将filepath指向的文件/目录中的内容添加到表/分区中
10-2.使用Load加载数据到表中案例
背景:Load Data From Local FS or HDFS
1、练习Load Data From Local FS
2、练习Load Data From HDFS
3、理解Local关键字的含义
4、练习Load Dada To Partition Table
-- 创建表
--建表student_local 用于演示从本地加载数据
0: jdbc:hive2://ops01:10000> create table student_local(num int,name string,sex string,age int,dept string) row format delimited fields terminated by ',';
No rows affected (0.091 seconds)
--建表student_HDFS 用于演示从HDFS加载数据
0: jdbc:hive2://ops01:10000> create external table student_HDFS(num int,name string,sex string,age int,dept string) row format delimited fields terminated by ',';
No rows affected (0.07 seconds)
--建表student_HDFS_p 用于演示从HDFS加载数据到分区表
0: jdbc:hive2://ops01:10000> create table student_HDFS_p(num int,name string,sex string,age int,dept string) partitioned by(country string) row format delimited fields terminated by ',';
No rows affected (0.067 seconds)
0: jdbc:hive2://ops01:10000> select count(*) from student_local;
+------+
| _c0 |
+------+
| 0 |
+------+
1 row selected (0.143 seconds)
0: jdbc:hive2://ops01:10000> select count(*) from student_HDFS;
+------+
| _c0 |
+------+
| 0 |
+------+
1 row selected (18.857 seconds)
0: jdbc:hive2://ops01:10000> select count(*) from student_HDFS_p;
+------+
| _c0 |
+------+
| 0 |
+------+
1 row selected (0.168 seconds)
# 数据文件位置
wangting@ops01:/home/wangting/20221013 >ls
archer.txt hero hot_hero_skin_price.txt part-m-00000 students.txt team_ace_player.txt usa user.txt
wangting@ops01:/home/wangting/20221013 >pwd
/home/wangting/20221013
连接hive数据库操作并验证student_local表
wangting@ops02:/home/wangting >beeline -u jdbc:hive2://ops01:10000 -n wangting
Connecting to jdbc:hive2://ops01:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
0: jdbc:hive2://ops01:10000> use hv_2022_10_13;
No rows affected (0.134 seconds)
0: jdbc:hive2://ops01:10000> LOAD DATA LOCAL INPATH '/home/wangting/20221013/students.txt' INTO TABLE student_local;
No rows affected (0.173 seconds)
0: jdbc:hive2://ops01:10000> select count(*) from student_local;
+------+
| _c0 |
+------+
| 22 |
+------+
1 row selected (24.244 seconds)
[ 注意 ]:数据文件在服务器ops01上,但是命令行连接hive的客户端是从另外一台服务器ops02上操作,但是文件可以load,所以load时,beeline -u jdbc:hive2://ops01:10000 -n wangting,连接的是hive2协议,机器为ops01,那么INPATH路径则指的是ops01上的路径位置
student_HDFS表操作验证
wangting@ops01:/home/wangting/20221013 >hdfs dfs -put students.txt /
wangting@ops01:/home/wangting/20221013 >hdfs dfs -ls /students.txt
-rw-r--r-- 3 wangting supergroup 527 2022-10-17 16:19 /students.txt
0: jdbc:hive2://ops01:10000> LOAD DATA INPATH '/students.txt' INTO TABLE student_HDFS;
No rows affected (0.158 seconds)
0: jdbc:hive2://ops01:10000> select count(*) from student_HDFS;
+------+
| _c0 |
+------+
| 22 |
+------+
1 row selected (26.083 seconds)
student_HDFS_p表操作验证
wangting@ops01:/home/wangting/20221013 >hdfs dfs -put students.txt /
0: jdbc:hive2://ops01:10000> LOAD DATA INPATH '/students.txt' INTO TABLE student_HDFS_p partition(country ="China");
No rows affected (0.354 seconds)
0: jdbc:hive2://ops01:10000> select count(*) from student_HDFS_p;
+------+
| _c0 |
+------+
| 22 |
+------+
1 row selected (26.044 seconds)
10-3.Hive3.0 Load 新特性
-
Hive3.0+,load加载数据时除了移动、复制操作之外,在某些场合下还会将加载重写为INSERT AS SELECT
-
Hive3.0+,还支持使用inputformat、SerDe指定输入格式,例如Text,ORC等
如果表具有分区,则load命令没有指定分区,则将load转换为INSERT AS SELECT,并假定最后一组列为分区列,如果文件不符合预期,则报错
示例:
背景:
本来加载的时候没有指定分区,语句是报错的,但是文件的格式符合表的结构,前两个是col1,col2,最后一个是分区字段col3,则此时会将load语句转换成为insert as select语句
准备样例数据文件:
wangting@ops01:/home/wangting/20221013 >echo "11,22,1" >> tab1.txt
wangting@ops01:/home/wangting/20221013 >echo "33,44,2" >> tab1.txt
wangting@ops01:/home/wangting/20221013 >echo "55,66,3" >> tab1.txt
wangting@ops01:/home/wangting/20221013 >cat tab1.txt
11,22,1
33,44,2
55,66,3
wangting@ops01:/home/wangting/20221013 >pwd
/home/wangting/20221013
-- 建测试表
CREATE TABLE if not exists tab1 (col1 int, col2 int)
PARTITIONED BY (col3 int)
row format delimited fields terminated by ',';
-- 加载数据
LOAD DATA LOCAL INPATH '/home/wangting/20221013/tab1.txt' INTO TABLE tab1;
-- 查询验证
0: jdbc:hive2://ops01:10000> desc tab1;
+--------------------------+------------+----------+
| col_name | data_type | comment |
+--------------------------+------------+----------+
| col1 | int | |
| col2 | int | |
| col3 | int | |
| | NULL | NULL |
| # Partition Information | NULL | NULL |
| # col_name | data_type | comment |
| col3 | int | |
+--------------------------+------------+----------+
7 rows selected (0.084 seconds)
0: jdbc:hive2://ops01:10000> select * from tab1;
+------------+------------+------------+
| tab1.col1 | tab1.col2 | tab1.col3 |
+------------+------------+------------+
| 11 | 22 | 1 |
| 33 | 44 | 2 |
| 55 | 66 | 3 |
+------------+------------+------------+
3 rows selected (0.179 seconds)
第11章:Hive SQL-DML-Insert
11-1.Hive Insert使用方式
-
在MySQL这样的RDBMS中,通常使用insert+values的方式来向表插入数据,并且执行速度很快
-
insert+values是RDBMS中表插入数据的核心方式
RDBMS的insert语法:
INSERT INTO table_name ( field1, field2,...fieldN )
VALUES
( value1, value2,...valueN );
假如把Hive当成RDBMS,用insert+values的方式插入数据,会如何?
执行过程非常非常慢! 原因在于底层是使用MapReduce把数据写入Hive表中
如果在Hive中使用insert+values,对于大数据环境一条条插入数据,用时相对RDBMS非常耗时
Hive官方推荐加载数据的方式:
清洗数据成为结构化文件,再使用Load语法加载数据到表中。这样的效率更高
- hive的insert+select表示:将后面查询返回的结果作为内容插入到指定表中,注意OVERWRITE将覆盖已有数据
- 需要保证查询结果列的数目和需要插入数据表格的列数目一致。
- 如果查询出来的数据类型和插入表格对应的列数据类型不一致,将会进行转换,但是不能保证转换一定成功,转换失败的数据将会为NULL
hve的insert语法:
--语法规则
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
使用示例:
0: jdbc:hive2://ops01:10000> select * from student limit 2;
+--------------+---------------+--------------+--------------+---------------+
| student.num | student.name | student.sex | student.age | student.dept |
+--------------+---------------+--------------+--------------+---------------+
| 95001 | 李勇 | 男 | 20 | CS |
| 95002 | 刘晨 | 女 | 19 | IS |
+--------------+---------------+--------------+--------------+---------------+
2 rows selected (0.158 seconds)
0: jdbc:hive2://ops01:10000> create table student_from_insert(sno int,sname string);
No rows affected (0.069 seconds)
0: jdbc:hive2://ops01:10000> insert into table student_from_insert select num,name from student;
No rows affected (25.325 seconds)
0: jdbc:hive2://ops01:10000> select * from student_from_insert limit 2;
+--------------------------+----------------------------+
| student_from_insert.sno | student_from_insert.sname |
+--------------------------+----------------------------+
| 95001 | 李勇 |
| 95002 | 刘晨 |
+--------------------------+----------------------------+
2 rows selected (0.155 seconds)
11-2.Multiple Inserts多重插入
- 多重插入,其核心功能是:一次扫描,多次插入
- 语法目的就是减少扫描的次数,在一次扫描中,完成多次insert操作
语法:
from old_table
insert overwrite table new_table_1 select column1,column2...
insert overwrite table new_table_2 select column1,column2...
...
insert overwrite table new_table_n select column1,column2...;
注意,这是一条sql语句,from old_table会扫描表,之后insert执行均使用档次扫描结果
而如果使用以下传统方式则每次insert执行都将意味着扫描一次原表
insert into new_table_1 select column1,column2… from old_table;
insert into new_table_2 select column1,column2… from old_table;
insert into new_table_n select column1,column2… from old_table;
使用示例:
0: jdbc:hive2://ops01:10000> select * from student limit 2;
+--------------+---------------+--------------+--------------+---------------+
| student.num | student.name | student.sex | student.age | student.dept |
+--------------+---------------+--------------+--------------+---------------+
| 95001 | 李勇 | 男 | 20 | CS |
| 95002 | 刘晨 | 女 | 19 | IS |
+--------------+---------------+--------------+--------------+---------------+
2 rows selected (0.144 seconds)
0: jdbc:hive2://ops01:10000> create table student_insert1(snum int);
No rows affected (0.094 seconds)
0: jdbc:hive2://ops01:10000> create table student_insert2(sname string);
No rows affected (0.152 seconds)
0: jdbc:hive2://ops01:10000> create table student_insert3(ssex string);
No rows affected (0.134 seconds)
0: jdbc:hive2://ops01:10000> create table student_insert4(sage int);
No rows affected (0.076 seconds)
-- 注意这是一条完整sql,只有最后一行才有分号字符
0: jdbc:hive2://ops01:10000> from student
. . . . . . . . . . . . . .> insert overwrite table student_insert1 select num
. . . . . . . . . . . . . .> insert overwrite table student_insert2 select name
. . . . . . . . . . . . . .> insert overwrite table student_insert3 select sex
. . . . . . . . . . . . . .> insert overwrite table student_insert4 select age;
No rows affected (99.564 seconds)
0: jdbc:hive2://ops01:10000> select * from student_insert1 limit 1;
+-----------------------+
| student_insert1.snum |
+-----------------------+
| 95001 |
+-----------------------+
0: jdbc:hive2://ops01:10000> select * from student_insert2 limit 1;
+------------------------+
| student_insert2.sname |
+------------------------+
| 李勇 |
+------------------------+
0: jdbc:hive2://ops01:10000> select * from student_insert3 limit 1;
+-----------------------+
| student_insert3.ssex |
+-----------------------+
| 男 |
+-----------------------+
0: jdbc:hive2://ops01:10000> select * from student_insert4 limit 1;
+-----------------------+
| student_insert4.sage |
+-----------------------+
| 20 |
+-----------------------+
11-3.Dynamic Partition Inserts动态分区插入
- 对于分区表的数据导入加载,最基础的是通过load命令加载数据
- 在load过程中,分区值是手动指定写死的,叫做静态分区
但是静态分区会面临一个问题:
例如一张表对应的分区有几百个,每个分区对应一个单独的映射文件,那么使用load命令导入则会反复执行几百次,
此时则需要有办法来处理这样的耗时操作,那么需要引入一个动态分区插入的概念
动态分区插入概念
- 分区的值是由后续的select查询语句的结果来动态确定的
- 根据查询结果自动分区
动态分区启动相关配置参数
- hive.exec.dynamic.partition
- true; 需要设置true为启用动态分区插入
- hive.exec.dynamic.partition.mode
- nonstrict; 在strict模式下,用户必须至少指定一个静态分区,以防用户意外覆盖所有分区;在nonstrict模式下,允许所有分区都是动态的
动态分区插入示例
-- 原表student,原表5个字段num,name,sex,age,dept
0: jdbc:hive2://ops01:10000> select * from student limit 1;
+--------------+---------------+--------------+--------------+---------------+
| student.num | student.name | student.sex | student.age | student.dept |
+--------------+---------------+--------------+--------------+---------------+
| 95001 | 李勇 | 男 | 20 | CS |
+--------------+---------------+--------------+--------------+---------------+
1 row selected (0.163 seconds)
-- 创建一张新表student_partition,注意创建时是4个字段Sno,Sname,Sex,Sage
0: jdbc:hive2://ops01:10000> create table student_partition(Sno int,Sname string,Sex string,Sage int) partitioned by(Sdept string);
No rows affected (0.085 seconds)
-- 此时show partitions还没有记录
0: jdbc:hive2://ops01:10000> show partitions student_partition;
+------------+
| partition |
+------------+
+------------+
No rows selected (0.065 seconds)
-- 不设置配置参数情况下,尝试insert into执行
0: jdbc:hive2://ops01:10000> insert into table student_partition partition(Sdept) select num,name,sex,age,dept from student;
Error: Error while compiling statement: FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict (state=42000,code=10096)
-- 执行数据插入,发现报错了;报错内容意思为:动态分区严格模式需要至少一个静态分区列。要禁用此功能,请设置hive.exec.dynamic.partition。模式=非严格nonstrict
-- set 参数
0: jdbc:hive2://ops01:10000> set hive.exec.dynamic.partition = true;
No rows affected (0.005 seconds)
0: jdbc:hive2://ops01:10000> set hive.exec.dynamic.partition.mode = nonstrict;
No rows affected (0.005 seconds)
-- 再次执行insert则不再有报错
0: jdbc:hive2://ops01:10000> insert into table student_partition partition(Sdept) select num,name,sex,age,dept from student;
No rows affected (27.919 seconds)
-- 验证student_partition表,数据成功写入
0: jdbc:hive2://ops01:10000> select tb1.* from student_partition tb1 limit 1;
+----------+------------+----------+-----------+------------+
| tb1.sno | tb1.sname | tb1.sex | tb1.sage | tb1.sdept |
+----------+------------+----------+-----------+------------+
| 95001 | 李勇 | 男 | 20 | CS |
+----------+------------+----------+-----------+------------+
1 row selected (0.166 seconds)
-- 分区正确识别
0: jdbc:hive2://ops01:10000> show partitions student_partition;
+------------+
| partition |
+------------+
| sdept=CS |
| sdept=IS |
| sdept=MA |
+------------+
3 rows selected (0.073 seconds)
11-4.Insert Directory导出数据
- Hive支持将select查询的结果导出成文件存放在文件系统中
注意:导出操作是一个OVERWRITE覆盖操作 !
导出语法:
- 目录可以是完整的URI。如果未指定scheme,则Hive将使用hadoop配置变量fs.default.name来决定导出位置
- 如果使用LOCAL关键字,则Hive会将数据写入本地文件系统上的目录
- 写入文件系统的数据被序列化为文本,列之间用\001隔开,行之间用换行符隔开。如果列都不是原始数据类型,那么这些列将序列化为JSON格式。也可以在导出的时候指定分隔符换行符和文件格式
--标准语法:
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format] (Note: Only available starting with Hive 0.11.0)
SELECT ... FROM ...
--Hive extension (multiple inserts):
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1
[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ...
--row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
示例:
0: jdbc:hive2://ops01:10000> select * from student limit 1;
+--------------+---------------+--------------+--------------+---------------+
| student.num | student.name | student.sex | student.age | student.dept |
+--------------+---------------+--------------+--------------+---------------+
| 95001 | 李勇 | 男 | 20 | CS |
+--------------+---------------+--------------+--------------+---------------+
1 row selected (0.153 seconds)
--1、导出查询结果到HDFS指定目录下
0: jdbc:hive2://ops01:10000> insert overwrite directory '/tmp/hive_export/20221018' select num,name,age from student limit 5;
No rows affected (25.166 seconds)
--2、导出查询结果到HDFS指定目录下,并且指定分隔符和文件存储格式
0: jdbc:hive2://ops01:10000> insert overwrite directory '/tmp/hive_export/20221019' row format delimited fields terminated by ',' stored as orc select * from student;
No rows affected (17.693 seconds)
--3、导出数据到本地文件系统指定目录下,本地文件指连接的hive2服务所在的环境对应本地路径,jdbc:hive2://ops01:10000>则对应为ops01服务器对应的路径
0: jdbc:hive2://ops01:10000> insert overwrite local directory '/home/wangting/hive_export/' select * from student limit 5;
No rows affected (26.139 seconds)
验证:
# 验证1:
wangting@ops01:/home/wangting >hdfs dfs -ls /tmp/hive_export/20221018
Found 1 items
-rw-r--r-- 3 wangting supergroup 80 2022-10-18 10:10 /tmp/hive_export/20221018/000000_0
wangting@ops01:/home/wangting >hdfs dfs -cat /tmp/hive_export/20221018/000000_0
2022-10-18 10:16:56,407 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
95005刘刚18
95004张立19
95003王敏22
95002刘晨19
95001李勇20
# 验证2:(导出stored as orc,二进制存储不可直接查看)
wangting@ops01:/home/wangting >hdfs dfs -ls /tmp/hive_export/20221019
Found 1 items
-rw-r--r-- 3 wangting supergroup 831 2022-10-18 10:12 /tmp/hive_export/20221019/000000_0
# hive提供了工具orcfiledump可以查看解析hdfs的orc文件,hive --orcfiledump
wangting@ops01:/home/wangting >hive --orcfiledump /tmp/hive_export/20221019/000000_0
Rows: 22
Compression: ZLIB
Compression size: 262144
Type: struct<_col0:int,_col1:string,_col2:string,_col3:int,_col4:string>
Stripe Statistics:
2022-10-18 10:33:09,824 INFO [main] impl.OrcCodecPool (OrcCodecPool.java:getCodec(56)) - Got brand-new codec ZLIB
Stripe 1:
Column 0: count: 22 hasNull: false
Column 1: count: 22 hasNull: false bytesOnDisk: 9 min: 95001 max: 95022 sum: 2090253
Column 2: count: 22 hasNull: false bytesOnDisk: 150 min: 冯伟 max: 钱国 sum: 153
Column 3: count: 22 hasNull: false bytesOnDisk: 32 min: 女 max: 男 sum: 66
Column 4: count: 22 hasNull: false bytesOnDisk: 27 min: 17 max: 23 sum: 426
Column 5: count: 22 hasNull: false bytesOnDisk: 32 min: CS max: MA sum: 44
# 验证3:
wangting@ops01:/home/wangting >ls /home/wangting/hive_export/
000000_0
wangting@ops01:/home/wangting >cat /home/wangting/hive_export/000000_0
95005刘刚男18MA
95004张立男19IS
95003王敏女22MA
95002刘晨女19IS
95001李勇男20CS
第12章:Hive Transaction事务表
12-1.Hive事务背景知识
-
Hive设计之初时,并不支持事务,原因如下:
- Hive的核心目标是将已经存在的结构化数据文件映射成为表,然后提供基于表的SQL分析处理,是一款面向历史、面向分析的工具
- Hive作为数据仓库,是分析数据规律的,而不是创造数据规律的
- Hive中表的数据存储于HDFS上,而HDFS是不支持随机修改文件数据的,其常见的模型是一次写入,多次读取
-
但从Hive0.14版本开始,hive具有ACID语义的事务(支持INSERT,UPDATE和DELETE)已添加到Hive中,以解决以下场景下遇到的问题:
- 流式传输数据
- 使用如Apache Flume或Apache Kafka之类的工具将数据流式传输到现有分区中,可能会有脏读(开始查询后能看到写入的数据)
- 变化缓慢数据更新
- 星型模式数据仓库中,维度表随时间缓慢变化。例如,零售商将开设新商店,需要将其添加到商店表中,或者现有商店可能会更改其平方英尺或某些其他跟踪的特征。这些更改需要插入单个记录或更新记录(取决于所选策略)
- 数据修正
- 有时发现收集的数据不正确,需要局部更正
- 流式传输数据
12-2.Hive事务表实现原理
-
Hive的文件是存储在HDFS上的,而HDFS上又不支持对文件的任意修改,只能是采取另外的手段来完成
- 用HDFS文件作为原始数据(基础数据),用delta保存事务操作的记录增量数据
- 正在执行中的事务,是以一个staging开头的文件夹维护的,执行结束就是delta文件夹。每次执行一次事务操作都会有这样的一个delta增量文件夹
- 当访问Hive数据时,根据HDFS原始文件和delta增量文件做合并,查询最新的数据
-
INSERT语句会直接创建delta目录;
-
DELETE目录的前缀是delete_delta;
-
UPDATE语句采用了split-update特性,即先删除、后插入
delta文件夹命名格式
-
delta_minWID_maxWID_stmtID,即delta前缀、写事务的ID范围、以及语句ID;删除时前缀是delete_delta,里面包含了要删除的文件
-
Hive会为写事务(INSERT、DELETE等)创建一个写事务ID(Write ID),该ID在表范围内唯一
-
语句ID(Statement ID)则是当一个事务中有多条写入语句时使用的,用作唯一标识
-
每个事务的delta文件夹下,都有两个文件
- _orc_acid_version的内容是2,即当前ACID版本号是2。和版本1的主要区别是UPDATE语句采用了split-update特性,即先删除、后插入。这个文件不是ORC文件,可以下载下来直接查看
- bucket_00000文件则是写入的数据内容。如果事务表没有分区和分桶,就只有一个这样的文件。文件都以ORC格式存储,底层二级制
operation:0 表示插入,1 表示更新,2 表示删除。由于使用了split-update,UPDATE是不会出现的,所以delta文件中的operation是0 , delete_delta 文件中的operation是2。
originalTransaction、currentTransaction:该条记录的原始写事务ID,当前的写事务ID。
rowId:一个自增的唯一ID,在写事务和分桶的组合中唯一。
row:具体数据。对于DELETE语句,则为null,对于INSERT就是插入的数据,对于UPDATE就是更新后的数据
合并器(Compactor):
- 随着表的修改操作,创建了越来越多的delta增量文件,就需要合并以保持足够的性能。
- 合并器Compactor是一套在Hive Metastore内运行,支持ACID系统的后台进程。所有合并都是在后台完成的,不会阻止数据的并发读、写。合并后,系统将等待所有旧文件的读操作完成后,删除旧文件。
- 合并操作分为两种,minor compaction(小合并)、major compaction(大合并)
- 小合并会将一组delta增量文件重写为单个增量文件,默认触发条件为10个delta文件;
- 大合并将一个或多个增量文件和基础文件重写为新的基础文件,默认触发条件为delta文件相应于基础文件占比,10%
12-3.Hive事务表使用设置与局限性
局限性
虽然Hive支持了具有ACID语义的事务,但是在使用起来,并没有像在MySQL中使用那样方便,有很多限制
- 尚不支持BEGIN,COMMIT和ROLLBACK,所有语言操作都是自动提交的
- 表文件存储格式仅支持ORC(STORED AS ORC)
- 需要配置参数开启事务使用
- 外部表无法创建为事务表,因为Hive只能控制元数据,无法管理数据
- 表属性参数transactional必须设置为true
- 必须将Hive事务管理器设置为org.apache.hadoop.hive.ql.lockmgr.DbTxnManager才能使用ACID表
- 事务表不支持LOAD DATA …语句
相关配置参数设置
Client端:
set hive.support.concurrency = true; --Hive是否支持并发
set hive.enforce.bucketing = true; --从Hive2.0开始不再需要 是否开启分桶功能
set hive.exec.dynamic.partition.mode = nonstrict; --动态分区模式 非严格
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
服务端:
set hive.compactor.initiator.on = true; --是否在Metastore实例上运行启动压缩合并
set hive.compactor.worker.threads = 1; --在此metastore实例上运行多少个压缩程序工作线程
12-4.案例:创建使用Hive事务表
0: jdbc:hive2://ops01:10000> use hv_2022_10_13;
No rows affected (0.028 seconds)
0: jdbc:hive2://ops01:10000> set hive.support.concurrency = true;
No rows affected (0.005 seconds)
0: jdbc:hive2://ops01:10000> set hive.enforce.bucketing = true;
No rows affected (0.004 seconds)
0: jdbc:hive2://ops01:10000> set hive.exec.dynamic.partition.mode = nonstrict;
No rows affected (0.003 seconds)
0: jdbc:hive2://ops01:10000> set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
No rows affected (0.003 seconds)
0: jdbc:hive2://ops01:10000> set hive.compactor.initiator.on = true;
No rows affected (0.003 seconds)
0: jdbc:hive2://ops01:10000> set hive.compactor.worker.threads = 1;
No rows affected (0.005 seconds)
0: jdbc:hive2://ops01:10000> CREATE TABLE emp (id int, name string, salary int) STORED AS ORC TBLPROPERTIES ('transactional' = 'true');
No rows affected (0.192 seconds)
0: jdbc:hive2://ops01:10000> INSERT INTO emp VALUES
. . . . . . . . . . . . . .> (1, 'Jerry', 5000),
. . . . . . . . . . . . . .> (2, 'Tom', 8000),
. . . . . . . . . . . . . .> (3, 'Kate', 6000);
No rows affected (24.278 seconds)
0: jdbc:hive2://ops01:10000> select * from emp;
+---------+-----------+-------------+
| emp.id | emp.name | emp.salary |
+---------+-----------+-------------+
| 1 | Jerry | 5000 |
| 2 | Tom | 8000 |
| 3 | Kate | 6000 |
+---------+-----------+-------------+
3 rows selected (0.203 seconds)
# insert数据后查看映射文件目录为delta_0000001_0000001_0000
wangting@ops01:/home/wangting >hdfs dfs -ls /user/hive/warehouse/hv_2022_10_13.db/emp
Found 1 items
drwxr-xr-x - wangting supergroup 0 2022-10-18 11:19 /user/hive/warehouse/hv_2022_10_13.db/emp/delta_0000001_0000001_0000
-- 再次插入数据
0: jdbc:hive2://ops01:10000> INSERT INTO emp VALUES(4, 'Allen', 8000);
No rows affected (26.292 seconds)
# 因为再次插入数据后会有新的事务产生,所以查看hdfs上映射变化,多了一个映射文件目录delta_0000002_0000002_0000
wangting@ops01:/home/wangting >hdfs dfs -ls /user/hive/warehouse/hv_2022_10_13.db/emp
Found 2 items
drwxr-xr-x - wangting supergroup 0 2022-10-18 11:19 /user/hive/warehouse/hv_2022_10_13.db/emp/delta_0000001_0000001_0000
drwxr-xr-x - wangting supergroup 0 2022-10-18 11:22 /user/hive/warehouse/hv_2022_10_13.db/emp/delta_0000002_0000002_0000
wangting@ops01:/home/wangting >hdfs dfs -ls /user/hive/warehouse/hv_2022_10_13.db/emp/delta_0000001_0000001_0000
Found 2 items
-rw-r--r-- 3 wangting supergroup 1 2022-10-18 11:19 /user/hive/warehouse/hv_2022_10_13.db/emp/delta_0000001_0000001_0000/_orc_acid_version
-rw-r--r-- 3 wangting supergroup 837 2022-10-18 11:19 /user/hive/warehouse/hv_2022_10_13.db/emp/delta_0000001_0000001_0000/bucket_00000
wangting@ops01:/home/wangting >hdfs dfs -ls /user/hive/warehouse/hv_2022_10_13.db/emp/delta_0000002_0000002_0000
Found 2 items
-rw-r--r-- 3 wangting supergroup 1 2022-10-18 11:22 /user/hive/warehouse/hv_2022_10_13.db/emp/delta_0000002_0000002_0000/_orc_acid_version
-rw-r--r-- 3 wangting supergroup 795 2022-10-18 11:22 /user/hive/warehouse/hv_2022_10_13.db/emp/delta_0000002_0000002_0000/bucket_00000
-- update修改数据验证
0: jdbc:hive2://ops01:10000> UPDATE emp set name = 'Allennnnn' where id = 4;
No rows affected (26.149 seconds)
# 修改数据多了delta_0000003_0000003_0000和delete_delta_0000003_0000003_0000
wangting@ops01:/home/wangting >hdfs dfs -ls /user/hive/warehouse/hv_2022_10_13.db/emp/
Found 4 items
drwxr-xr-x - wangting supergroup 0 2022-10-18 11:27 /user/hive/warehouse/hv_2022_10_13.db/emp/delete_delta_0000003_0000003_0000
drwxr-xr-x - wangting supergroup 0 2022-10-18 11:19 /user/hive/warehouse/hv_2022_10_13.db/emp/delta_0000001_0000001_0000
drwxr-xr-x - wangting supergroup 0 2022-10-18 11:22 /user/hive/warehouse/hv_2022_10_13.db/emp/delta_0000002_0000002_0000
drwxr-xr-x - wangting supergroup 0 2022-10-18 11:27 /user/hive/warehouse/hv_2022_10_13.db/emp/delta_0000003_0000003_0000
-- 删除数据验证
0: jdbc:hive2://ops01:10000> DELETE FROM emp where id = 4;
No rows affected (27.142 seconds)
# 删除数据多了delete_delta_0000004_0000004_0000目录,没有新增delta目录
wangting@ops01:/home/wangting >hdfs dfs -ls /user/hive/warehouse/hv_2022_10_13.db/emp/
Found 5 items
drwxr-xr-x - wangting supergroup 0 2022-10-18 11:27 /user/hive/warehouse/hv_2022_10_13.db/emp/delete_delta_0000003_0000003_0000
drwxr-xr-x - wangting supergroup 0 2022-10-18 11:30 /user/hive/warehouse/hv_2022_10_13.db/emp/delete_delta_0000004_0000004_0000
drwxr-xr-x - wangting supergroup 0 2022-10-18 11:19 /user/hive/warehouse/hv_2022_10_13.db/emp/delta_0000001_0000001_0000
drwxr-xr-x - wangting supergroup 0 2022-10-18 11:22 /user/hive/warehouse/hv_2022_10_13.db/emp/delta_0000002_0000002_0000
drwxr-xr-x - wangting supergroup 0 2022-10-18 11:27 /user/hive/warehouse/hv_2022_10_13.db/emp/delta_0000003_0000003_0000
第13章:Hive SQL-DML-Update、Delete
概述
- Hive是基于Hadoop的数据仓库,是面向分析支持分析工具。将已有的结构化数据文件映射成为表,然后提供SQL分析数据的能力
- 因此在Hive中常见的操作就是分析查询select操作
- Hive早期是不支持update和delete语法的,因为Hive所处理的数据都是已经存在的的数据、历史数据
- 后续Hive支持了相关的update和delete操作,不过有很多约束局限性
update操作
-- 1. 更新配置参数
set hive.support.concurrency = true;
set hive.enforce.bucketing = true;
set hive.exec.dynamic.partition.mode = nonstrict;
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
set hive.compactor.initiator.on = true;
set hive.compactor.worker.threads = 1;
-- 2.对表进行update操作
insert into table (col1,col2...) values (xxx,222)
update table set k = v where col = xxx;
delete操作
-- 1. 更新配置参数
set hive.support.concurrency = true;
set hive.enforce.bucketing = true;
set hive.exec.dynamic.partition.mode = nonstrict;
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
set hive.compactor.initiator.on = true;
set hive.compactor.worker.threads = 1;
-- 2.对表进行delete操作
delete from table where col = xxx;
第14章:Hive SQL-DQL-Select查询数据
14-1.Select语法
- 从哪里查询取决于FROM关键字后面的table_reference。可以是普通物理表、视图、join结果或子查询结果
- 表名和列名不区分大小写
语法数:
[WITH CommonTableExpression (, CommonTableExpression)*]
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT [offset,] rows];
查询案例环境准备:
链接:https://pan.baidu.com/s/1cWq6wd0pfqaCRuBijt1WKg?pwd=cc6v
提取码:cc6v
背景:美国Covid-19新冠数据之select查询
现有美国2021-1-28号,各个县county的新冠疫情累计案例信息,包括确诊病例和死亡病例,数据格式如下所示;
字段含义:count_date(统计日期),county(县),state(州),fips(县编码code),cases(累计确诊病例),deaths(累计死亡病例)数据文件us-covid19-counties.dat
下载解压文件包:
wangting@ops01:/home/wangting/20221013/usa >unzip us-civid19.zip
wangting@ops01:/home/wangting/20221013/usa >ll
total 46864
-rw-rw-r-- 1 wangting wangting 4318157 Jan 29 2021 COVID-19-Cases-USA-By-County.csv
-rw-rw-r-- 1 wangting wangting 116254 Jan 29 2021 COVID-19-Cases-USA-By-State.csv
-rw-rw-r-- 1 wangting wangting 2988679 Jan 29 2021 COVID-19-Deaths-USA-By-County.csv
-rw-rw-r-- 1 wangting wangting 86590 Jan 29 2021 COVID-19-Deaths-USA-By-State.csv
-rw-rw-r-- 1 wangting wangting 39693686 Jan 29 2021 us-counties.csv
-rw-rw-r-- 1 wangting wangting 136795 Sep 16 23:23 us-covid19-counties.dat
-rw-rw-r-- 1 wangting wangting 9135 Jan 29 2021 us.csv
-rw-rw-r-- 1 wangting wangting 620291 Jan 29 2021 us-states.csv
样例数据:
2021-01-28,Autauga,Alabama,01001,5554,69
2021-01-28,Baldwin,Alabama,01003,17779,225
2021-01-28,Barbour,Alabama,01005,1920,40
2021-01-28,Bibb,Alabama,01007,2271,51
2021-01-28,Blount,Alabama,01009,5612,98
2021-01-28,Bullock,Alabama,01011,1079,29
2021-01-28,Butler,Alabama,01013,1788,60
2021-01-28,Calhoun,Alabama,01015,11833,231
2021-01-28,Chambers,Alabama,01017,3159,76
2021-01-28,Cherokee,Alabama,01019,1682,35
创建实验表:
--step1:创建普通表t_usa_covid19
drop table if exists t_usa_covid19;
CREATE TABLE t_usa_covid19(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int)
row format delimited fields terminated by ",";
--step2:将源数据load加载到t_usa_covid19表对应的路径下
load data local inpath '/home/wangting/20221013/usa/us-covid19-counties.dat' into table t_usa_covid19;
--step3:查看验证是否成功
0: jdbc:hive2://ops01:10000> select tb1.* from t_usa_covid19 tb1 limit 2;
+-----------------+-------------+------------+-----------+------------+-------------+
| tb1.count_date | tb1.county | tb1.state | tb1.fips | tb1.cases | tb1.deaths |
+-----------------+-------------+------------+-----------+------------+-------------+
| 2021-01-28 | Autauga | Alabama | 1001 | 5554 | 69 |
| 2021-01-28 | Baldwin | Alabama | 1003 | 17779 | 225 |
+-----------------+-------------+------------+-----------+------------+-------------+
2 rows selected (0.197 seconds)
--step1:创建一张分区表 基于count_date日期,state州进行分区
CREATE TABLE if not exists t_usa_covid19_p(
county string,
fips int,
cases int,
deaths int)
partitioned by(count_date string,state string)
row format delimited fields terminated by ",";
--step2:使用动态分区插入将数据导入t_usa_covid19_p中
0: jdbc:hive2://ops01:10000> set hive.exec.dynamic.partition.mode = nonstrict;
No rows affected (0.005 seconds)
0: jdbc:hive2://ops01:10000> insert into table t_usa_covid19_p partition (count_date,state) select county,fips,cases,deaths,count_date,state from t_usa_covid19;
No rows affected (36.857 seconds)
--step3:查看验证是否成功
0: jdbc:hive2://ops01:10000> select tb2.* from t_usa_covid19_p tb2 limit 2;
+-------------+-----------+------------+-------------+-----------------+------------+
| tb2.county | tb2.fips | tb2.cases | tb2.deaths | tb2.count_date | tb2.state |
+-------------+-----------+------------+-------------+-----------------+------------+
| Autauga | 1001 | 5554 | 69 | 2021-01-28 | Alabama |
| Baldwin | 1003 | 17779 | 225 | 2021-01-28 | Alabama |
+-------------+-----------+------------+-------------+-----------------+------------+
2 rows selected (0.257 seconds)
HDFS映射文件查看:
# 普通表t_usa_covid19文件信息:
wangting@ops01:/home/wangting/20221013/usa >hdfs dfs -ls /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19/
Found 1 items
-rw-r--r-- 3 wangting supergroup 136795 2022-10-18 11:58 /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19/us-covid19-counties.dat
# 分区表t_usa_covid19_p文件信息:
wangting@ops01:/home/wangting/20221013/usa >hdfs dfs -ls /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19_p/
Found 1 items
drwxr-xr-x - wangting supergroup 0 2022-10-18 13:51 /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19_p/count_date=2021-01-28
wangting@ops01:/home/wangting/20221013/usa >hdfs dfs -ls /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19_p/count_date=2021-01-28 | head -5
Found 55 items
drwxr-xr-x - wangting supergroup 0 2022-10-18 13:50 /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19_p/count_date=2021-01-28/state=Alabama
drwxr-xr-x - wangting supergroup 0 2022-10-18 13:50 /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19_p/count_date=2021-01-28/state=Alaska
drwxr-xr-x - wangting supergroup 0 2022-10-18 13:50 /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19_p/count_date=2021-01-28/state=Arizona
drwxr-xr-x - wangting supergroup 0 2022-10-18 13:50 /user/hive/warehouse/hv_2022_10_13.db/t_usa_covid19_p/count_date=2021-01-28/state=Arkansas
14-2.Hive SQL select查询基础语法
ALL | DISTINCT
- 用于指定查询返回结果中重复的行如何处理
- 如果没有给出这些选项,则默认值为ALL(返回所有匹配的行)
- DISTINCT指定从结果集中删除重复的行
0: jdbc:hive2://ops01:10000> select count(count_date) from t_usa_covid19;
+-------+
| _c0 |
+-------+
| 3245 |
+-------+
1 row selected (27.073 seconds)
0: jdbc:hive2://ops01:10000> select count(DISTINCT(count_date)) from t_usa_covid19;
+------+
| _c0 |
+------+
| 1 |
+------+
1 row selected (28.106 seconds)
WHERE
-
WHERE后面是一个布尔表达式,用于查询过滤
-
在WHERE表达式中,可以使用Hive支持的任何函数和运算符,但聚合函数除外
聚合函数要使用它的前提是结果集已经确定。而where子句还处于“确定”结果集的过程中,因而不能使用聚合函数
-
WHERE子句支持某些类型的子查询
0: jdbc:hive2://ops01:10000> select t1.* from t_usa_covid19_p t1 where deaths > 10000;
+----------------+----------+-----------+------------+----------------+-------------+
| t1.county | t1.fips | t1.cases | t1.deaths | t1.count_date | t1.state |
+----------------+----------+-----------+------------+----------------+-------------+
| Los Angeles | 6037 | 1098363 | 16107 | 2021-01-28 | California |
| New York City | NULL | 591160 | 26856 | 2021-01-28 | New York |
+----------------+----------+-----------+------------+----------------+-------------+
2 rows selected (0.377 seconds)
分区查询、分区裁剪
- 针对Hive分区表,在查询时可以指定分区查询,减少全表扫描,也叫做分区裁剪
- 所谓分区裁剪指:对分区表进行查询时,会检查WHERE子句或JOIN中的ON子句中是否存在对分区字段的过滤,如果存在,则仅访问查询符合条件的分区,即裁剪掉没必要访问的分区
-- 找出来自加州,累计死亡人数大于1000的县 state字段就是分区字段 进行分区裁剪 避免全表扫描
0: jdbc:hive2://ops01:10000> select t.* from t_usa_covid19_p t where state ="California" and deaths > 1000;
+-----------------+---------+----------+-----------+---------------+-------------+
| t.county | t.fips | t.cases | t.deaths | t.count_date | t.state |
+-----------------+---------+----------+-----------+---------------+-------------+
| Fresno | 6019 | 86886 | 1122 | 2021-01-28 | California |
| Los Angeles | 6037 | 1098363 | 16107 | 2021-01-28 | California |
| Orange | 6059 | 241648 | 2868 | 2021-01-28 | California |
| Riverside | 6065 | 270105 | 3058 | 2021-01-28 | California |
| Sacramento | 6067 | 85427 | 1216 | 2021-01-28 | California |
| San Bernardino | 6071 | 271189 | 1776 | 2021-01-28 | California |
| San Diego | 6073 | 233033 | 2534 | 2021-01-28 | California |
| Santa Clara | 6085 | 100468 | 1345 | 2021-01-28 | California |
+-----------------+---------+----------+-----------+---------------+-------------+
8 rows selected (0.206 seconds)
-- 多分区裁剪
0: jdbc:hive2://ops01:10000> select t.* from t_usa_covid19_p t where count_date = "2021-01-28" and state ="California" and deaths > 1000;
+-----------------+---------+----------+-----------+---------------+-------------+
| t.county | t.fips | t.cases | t.deaths | t.count_date | t.state |
+-----------------+---------+----------+-----------+---------------+-------------+
| Fresno | 6019 | 86886 | 1122 | 2021-01-28 | California |
| Los Angeles | 6037 | 1098363 | 16107 | 2021-01-28 | California |
| Orange | 6059 | 241648 | 2868 | 2021-01-28 | California |
| Riverside | 6065 | 270105 | 3058 | 2021-01-28 | California |
| Sacramento | 6067 | 85427 | 1216 | 2021-01-28 | California |
| San Bernardino | 6071 | 271189 | 1776 | 2021-01-28 | California |
| San Diego | 6073 | 233033 | 2534 | 2021-01-28 | California |
| Santa Clara | 6085 | 100468 | 1345 | 2021-01-28 | California |
+-----------------+---------+----------+-----------+---------------+-------------+
8 rows selected (0.212 seconds)
GROUP BY
-
GROUP BY语句用于结合聚合函数,根据一个或多个列对结果集进行分组
出现在GROUP BY中select_expr的字段:要么是GROUP BY分组的字段;要么是被聚合函数应用的字段
-
出现在GROUP BY中select_expr的字段:要么是GROUP BY分组的字段;要么是被聚合函数应用的字段
-
原因:避免出现一个字段多个值的歧义
- 分组字段出现select_expr中,一定没有歧义,因为就是基于该字段分组的,同一组中必相同
- 被聚合函数应用的字段,也没歧义,因为聚合函数的本质就是多进一出,最终返回一个结果
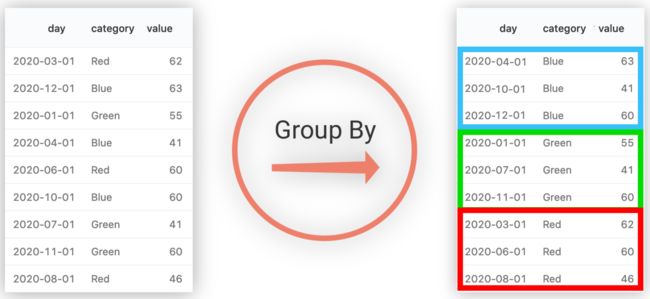
0: jdbc:hive2://ops01:10000> select state,sum(deaths) from t_usa_covid19_p where count_date = "2021-01-28" group by state limit 5;
+-------------+--------+
| state | _c1 |
+-------------+--------+
| Alabama | 7340 |
| Alaska | 253 |
| Arizona | 12861 |
| Arkansas | 4784 |
| California | 39521 |
+-------------+--------+
5 rows selected (28.432 seconds)
HAVING
- 在SQL中增加HAVING子句原因是,WHERE关键字无法与聚合函数一起使用
- HAVING子句可以让我们筛选分组后的各组数据,并且可以在Having中使用聚合函数,因为此时where,group by已经执行结束,结果集已经确定
select state,sum(deaths)
from t_usa_covid19_p
where count_date = "2021-01-28"
group by state
having sum(deaths) > 10000;
+----------------+--------+
| state | _c1 |
+----------------+--------+
| Arizona | 12861 |
| California | 39521 |
| Florida | 26034 |
| Georgia | 13404 |
| Illinois | 21074 |
| Massachusetts | 14348 |
| Michigan | 15393 |
| New Jersey | 21301 |
| New York | 42639 |
| Ohio | 11006 |
| Pennsylvania | 21350 |
| Texas | 36434 |
+----------------+--------+
12 rows selected (29.332 seconds)
-- 使用别名
select state,sum(deaths) as cnts
from t_usa_covid19_p
where count_date = "2021-01-28"
group by state
having cnts> 10000;
HAVING与WHERE区别
- having是在分组后对数据进行过滤
- where是在分组前对数据进行过滤
- having后面可以使用聚合函数
- where后面不可以使用聚合函数
LIMIT
- LIMIT用于限制SELECT语句返回的行数
- LIMIT接受一个或两个数字参数,这两个参数都必须是非负整数常量
- 第一个参数指定要返回的第一行的偏移量,第二个参数指定要返回的最大行数。当给出单个参数时,它代表最大行数,并且偏移量默认为0
-- 5条数据,对应顺序为0,1,2,3,4
0: jdbc:hive2://ops01:10000> select t.* from t_usa_covid19 t limit 5;
+---------------+-----------+----------+---------+----------+-----------+
| t.count_date | t.county | t.state | t.fips | t.cases | t.deaths |
+---------------+-----------+----------+---------+----------+-----------+
| 2021-01-28 | Autauga | Alabama | 1001 | 5554 | 69 |
| 2021-01-28 | Baldwin | Alabama | 1003 | 17779 | 225 |
| 2021-01-28 | Barbour | Alabama | 1005 | 1920 | 40 |
| 2021-01-28 | Bibb | Alabama | 1007 | 2271 | 51 |
| 2021-01-28 | Blount | Alabama | 1009 | 5612 | 98 |
+---------------+-----------+----------+---------+----------+-----------+
5 rows selected (0.184 seconds)
-- limit 2,2表示从顺序为2开始的数据取2条,即为第3条和第4条,从0开始
0: jdbc:hive2://ops01:10000> select t.* from t_usa_covid19 t limit 2,2;
+---------------+-----------+----------+---------+----------+-----------+
| t.count_date | t.county | t.state | t.fips | t.cases | t.deaths |
+---------------+-----------+----------+---------+----------+-----------+
| 2021-01-28 | Barbour | Alabama | 1005 | 1920 | 40 |
| 2021-01-28 | Bibb | Alabama | 1007 | 2271 | 51 |
+---------------+-----------+----------+---------+----------+-----------+
2 rows selected (0.172 seconds)
执行顺序
- 在查询过程中执行顺序:from > where > group(含聚合)> having >order > select
- 聚合语句(sum,min,max,avg,count)要比having子句优先执行
- where子句在查询过程中执行优先级别优先于聚合语句(sum,min,max,avg,count)
14-3.Hive SQL select查询高阶语法
ORDER BY
-
Hive SQL中的ORDER BY语法类似于标准SQL语言中的ORDER BY语法,会对输出的结果进行全局排序
当底层使用MapReduce引擎执行的时候,只会有一个reducetask执行。如果输出的行数太大,会导致需要很长的时间才能完成全局排序
-
默认排序为升序(ASC),也可以指定为DESC降序
-
在Hive 2.1.0和更高版本中,支持在ORDER BY子句中为每个列指定null类型结果排序顺序
-
ASC顺序的默认空排序顺序为NULLS FIRST,而DESC顺序的默认空排序顺序为NULLS LAST
-- 1、order by 根据字段进行排序
select t.* from t_usa_covid19_p t
where count_date = "2021-01-28"
and state ="California"
order by deaths limit 5;
+------------+---------+----------+-----------+---------------+-------------+
| t.county | t.fips | t.cases | t.deaths | t.count_date | t.state |
+------------+---------+----------+-----------+---------------+-------------+
| Sierra | 6091 | 44 | 0 | 2021-01-28 | California |
| Alpine | 6003 | 72 | 0 | 2021-01-28 | California |
| Del Norte | 6015 | 883 | 3 | 2021-01-28 | California |
| Modoc | 6049 | 297 | 4 | 2021-01-28 | California |
| Mono | 6051 | 1131 | 4 | 2021-01-28 | California |
+------------+---------+----------+-----------+---------------+-------------+
5 rows selected (25.055 seconds)
-- 1、order by desc 根据字段进行倒叙
select t.* from t_usa_covid19_p t
where count_date = "2021-01-28"
and state ="California"
order by deaths desc limit 5;
+-----------------+---------+----------+-----------+---------------+-------------+
| t.county | t.fips | t.cases | t.deaths | t.count_date | t.state |
+-----------------+---------+----------+-----------+---------------+-------------+
| Los Angeles | 6037 | 1098363 | 16107 | 2021-01-28 | California |
| Riverside | 6065 | 270105 | 3058 | 2021-01-28 | California |
| Orange | 6059 | 241648 | 2868 | 2021-01-28 | California |
| San Diego | 6073 | 233033 | 2534 | 2021-01-28 | California |
| San Bernardino | 6071 | 271189 | 1776 | 2021-01-28 | California |
+-----------------+---------+----------+-----------+---------------+-------------+
CLUSTER BY
- 根据指定字段将数据分组,每组内再根据该字段正序排序(只能正序),根据同一个字段,分且排序
- 分组规则hash散列(分桶表规则一样):Hash_Func(col_name) % reducetask个数
- 分为几组取决于reducetask的个数
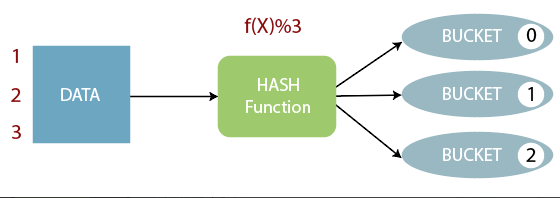
CLUSTER BY局限性
- CLUSTER BY无法单独完成,因为分和排序的字段只能是同一个
- ORDER BY更不能在这里使用,因为是全局排序,只有一个输出,无法满足分的需求
DISTRIBUTE BY +SORT BY
-
DISTRIBUTE BY +SORT BY就相当于把CLUSTER BY的功能一分为二
- DISTRIBUTE BY负责根据指定字段分组
- SORT BY负责分组内排序规则
-
分组和排序的字段可以不同
-
如果DISTRIBUTE BY +SORT BY的字段一样,则:CLUSTER BY=DISTRIBUTE BY +SORT BY
CLUSTER、 DISTRIBUTE、SORT、ORDER BY
- order by全局排序,因此只有一个reducer,结果输出在一个文件中,当输入规模大时,需要较长的计算时间
- distribute by根据指定字段将数据分组,算法是hash散列。sort by是在分组之后,每个组内局部排序
- cluster by既有分组,又有排序,但是两个字段只能是同一个字段
- 如果distribute和sort的字段是同一个时,此时,cluster by = distribute by + sort by
Union联合查询
- UNION用于将来自于多个SELECT语句的结果合并为一个结果集
- 使用DISTINCT关键字与只使用UNION默认值效果一样,都会删除重复行。1.2.0之前的Hive版本仅支持UNION ALL,在这种情况下不会消除重复的行
- 使用ALL关键字,不会删除重复行,结果集包括所有SELECT语句的匹配行(包括重复行)
- 每个select_statement返回的列的数量和名称必须相同
语法:
select_statement
UNION [ALL | DISTINCT]
select_statement
UNION [ALL | DISTINCT]
select_statement ...;
--使用DISTINCT关键字与使用UNION默认值效果一样,都会删除重复行。
select num,name from student_local
UNION
select num,name from student_hdfs;
-- 和上面效果一致
select num,name from student_local
UNION DISTINCT
select num,name from student_hdfs;
-- ORDER BY,SORT BY,CLUSTER BY,DISTRIBUTE BY或LIMIT放在最后
select num,name from student_local
UNION
select num,name from student_hdfs
order by num desc;
from子句中子查询
- Hive支持任意级别的子查询,也就是所谓的嵌套子查询
- 子查询名称之前可以包含可选关键字AS
-- 子查询
SELECT num
FROM (
select num,name from student_local
) tmp;
-- 包含UNION ALL的子查询的示例
SELECT t3.name
FROM (
select num,name from student_local
UNION distinct
select num,name from student_hdfs
) t3;
where子句中子查询
- 不相关子查询:该子查询不引用父查询中的列,可以将查询结果视为IN和NOT IN语句的常量
- 相关子查询:子查询引用父查询中的列
-- 执行子查询,其结果不被显示,而是传递给外部查询,作为外层查询的条件使用
SELECT *
FROM student_hdfs
WHERE student_hdfs.num IN (select num from student_local limit 2);
CTE介绍
- 公用表表达式(CTE)是一个临时结果集:该结果集是从WITH子句中指定的简单查询派生而来的,紧接在SELECT或INSERT关键字之前
- CTE仅在单个语句的执行范围内定义
- CTE可以在 SELECT,INSERT, CREATE TABLE AS SELECT或CREATE VIEW AS SELECT语句中使用
-- select语句中的CTE
0: jdbc:hive2://ops01:10000> with q1 as (select num,name,age from student where num = 95002)
. . . . . . . . . . . . . .> select *
. . . . . . . . . . . . . .> from q1;
+---------+----------+---------+
| q1.num | q1.name | q1.age |
+---------+----------+---------+
| 95002 | 刘晨 | 19 |
+---------+----------+---------+
1 row selected (0.205 seconds)
-- from风格
0: jdbc:hive2://ops01:10000> with q1 as (select num,name,age from student where num = 95002)
. . . . . . . . . . . . . .> from q1
. . . . . . . . . . . . . .> select *;
+---------+----------+---------+
| q1.num | q1.name | q1.age |
+---------+----------+---------+
| 95002 | 刘晨 | 19 |
+---------+----------+---------+
1 row selected (0.191 seconds)
-- chaining CTEs 链式
0: jdbc:hive2://ops01:10000> with q1 as ( select * from student where num = 95002),
. . . . . . . . . . . . . .> q2 as ( select num,name,age from q1)
. . . . . . . . . . . . . .> select * from (select num from q2) a;
+--------+
| a.num |
+--------+
| 95002 |
+--------+
1 row selected (0.189 seconds)
-- union
0: jdbc:hive2://ops01:10000> with q1 as (select * from student where num = 95002),
. . . . . . . . . . . . . .> q2 as (select * from student where num = 95004)
. . . . . . . . . . . . . .> select * from q1 union all select * from q2;
+----------+-----------+----------+----------+-----------+
| _u1.num | _u1.name | _u1.sex | _u1.age | _u1.dept |
+----------+-----------+----------+----------+-----------+
| 95002 | 刘晨 | 女 | 19 | IS |
| 95004 | 张立 | 男 | 19 | IS |
+----------+-----------+----------+----------+-----------+
2 rows selected (18.803 seconds)
0: jdbc:hive2://ops01:10000>
--视图,CTAS和插入语句中的CTE
-- insert
0: jdbc:hive2://ops01:10000> create table s1 like student;
No rows affected (0.218 seconds)
0: jdbc:hive2://ops01:10000> with q1 as ( select * from student where num = 95002)
. . . . . . . . . . . . . .> from q1
. . . . . . . . . . . . . .> insert overwrite table s1
. . . . . . . . . . . . . .> select *;
No rows affected (25.261 seconds)
0: jdbc:hive2://ops01:10000>
0: jdbc:hive2://ops01:10000> select * from s1;
+---------+----------+---------+---------+----------+
| s1.num | s1.name | s1.sex | s1.age | s1.dept |
+---------+----------+---------+---------+----------+
| 95002 | 刘晨 | 女 | 19 | IS |
+---------+----------+---------+---------+----------+
1 row selected (0.179 seconds)
0: jdbc:hive2://ops01:10000>
-- ctas
0: jdbc:hive2://ops01:10000> create table s2 as
. . . . . . . . . . . . . .> with q1 as ( select * from student where num = 95002)
. . . . . . . . . . . . . .> select * from q1;
No rows affected (16.987 seconds)
0: jdbc:hive2://ops01:10000>
-- view
0: jdbc:hive2://ops01:10000> create view v1 as
. . . . . . . . . . . . . .> with q1 as ( select * from student where num = 95002)
. . . . . . . . . . . . . .> select * from q1;
No rows affected (0.204 seconds)
0: jdbc:hive2://ops01:10000> select * from v1;
+---------+----------+---------+---------+----------+
| v1.num | v1.name | v1.sex | v1.age | v1.dept |
+---------+----------+---------+---------+----------+
| 95002 | 刘晨 | 女 | 19 | IS |
+---------+----------+---------+---------+----------+
1 row selected (0.212 seconds)
Hive3入门至精通(基础、部署、理论、SQL、函数、运算以及性能优化)1-14章
Hive3入门至精通(基础、部署、理论、SQL、函数、运算以及性能优化)15-28章