One-Stage Visual Grounding via Semantic-Aware Feature Filter
**本文内容仅代表个人理解,如有错误,欢迎指正**
隐约感觉到最近看的几篇论文都指出之前One-stage visual grounding methods大多利用pre-trained BERT将query编码为一个holistic vector,比较方便简单。但这样做的话,弱化了query中存在的语义信息,即对query的信息挖掘不足。所以,最近的文章都立足于如何能够更好地挖掘并利用query中存在的语义信息,从而辅助模型更准确地进行目标物体的框选。
1. Problem
本篇论文主要解决的问题:之前的一些方法直接将提取出的textual feature和visual feature map简单concatenate(拼接)起来,忽略了textual semantics(query中存在的语义信息),即没有很好地利用起query中包含的信息,从而降低了模型的表现。(其实说得有点笼统,只能说这个问题是存在的,但是这个解释有点弱)
2. Point
本篇论文的亮点在于:
1. 利用Standford Scene Graph Parser将query转化为Scene graph作为除Visual feature maps和query representations之外的一个额外输入,帮助模型更好地理解query中存在的语义信息(论文作者认为,"different aspects of the query have different effects on visual grounding and should be dealt with separately",个人理解是,要对query进行分析、分解,并根据query中词的不同有针对性地进行处理)。
2. 提出Entity-Attribute-Location Module(Filters),充分利用query representation和scene graph信息逐步过滤visual feature map中不相关的部分,从而准确框选出目标物体。
3. Main Components
- 本篇论文的模型主要可以分为三个部分 1. Image and text representation 2. Entity-Attribute-Location filtering module 3. grounding module 具体模型图如Figure 2所示,简单来说就是当我们得到visual feature map之后,我们通过Entity Filter、Attribute Filter以及Location Filter逐步过滤掉该feature map中不相关的部分,得到最终的一个相关性被增强了的feature map输入到grounding module中进行目标物体的预测。接下来我们将依次介绍以上三个部分。
3.1. Image and text representation
- 首先要清楚的是,我们的输入有两部分,1. Input image 2. Input query。
针对Input image,该模型通过Darknet-53+Path Aggregation Network得到visual feature map,并加入一个spatial feature map(因为Darknet53更注重于object的appearance,对位置信息不是非常敏感)与visual feature map进行拼接,得到最终的feature map。
针对Input query,主要做了两个操作。
1. 利用pre-trained BERT提取textual feature。
2. 利用Scene Graph Parser,依据query构建一个scene graph来捕捉query中的语义结构(论文作者在文中提到,虽然有些works表示Pre-trained BERT具有从句子中提取出语义结构的能力,但还是很难在vector representation中体现出来)。
* 针对scene graph,举个例子辅助理解。给定一个句子s,利用scene graph parser将句子s构建为一个scene graph,()=〈(),(),()〉,其中,(),(),()分别表示实体集、关系集和属性集,表示为()={}=1,()={(,,)}=1,()={,}=1。
***按照论文作者的描述(即我不确定是否真的能做到这些),该scene graph parser可以能够实现能够厘清句子s中体现出的实体有哪些、每个实体相对应的属性有哪些、以及两两实体之间的相关关系是什么样的(例如 next to, in front of),并在scene graph中体现出来。这个scene graph也作为模型额外的输入。
3.2. Entity-Attribute-Location filtering module
* 在这篇论文中,作者将Visual grounding的问题看作是a filtering-based reasoning process,即基于过滤的推理过程。与这一思想相似的论文还有2020年CVPR论文,RCCF: A Real-Time Cross-modality Correlation Filtering Method for ReferringExpression Comprehension,有兴趣的同学可以去下载原论文看看。
Entity Filter、Attribute Filter以及Location Filter所进行的操作大同小异(结构相同,但参数不同),都有三个输入(1. input feature map,来自visual extractor或者来自上一个Filter 2. textual feature 3.scene graph),一个输出(output feature map),所以论文作者统一就Filter中主要进行了什么操作进行介绍。
可以从Figure 2中看出,在每个Filter中主要进行了三个操作。1. Vision Query Interaction (基于asymmetric-attention mechanism) 2. Vision Graph Interaction (基于asymmetric-attention mechanism) 3. Semantic-Aware Guidance
3.2.1. Vision Query Interaction / Vision Graph interaction

- 文中提到,"Extracting text-conditioned visual feature maps is equivalent to taking pixel-level visual feature maps as Query vectors and perform attention between them and Key-Value pairs based on textual features."
- 这两个Interactions中的attention操作大致相同,都是以visual feature map作为Query,以query representation或者scene graph作为Key 和Value。
在Vision Query Interaction中的输出一共有两个,一个是V^{q},一个是a。其中,a可以用来表示每个filter对query中词的关注程度。
在Vision Graph Interaction中的输出有一个,一个是V^{g}。在Graph这边,论文作者有提到说直接flatten graph nodes into a sequence会丢失掉图结构信息,所以用了一个图卷积网络将图结构信息编码至图节点中(我图确实比较差,不多解释了)。
****至于这个attention为什么是非对称的我不大理解,网络上好像不是那么容易搜到,论文作者引用的论文我也涉及不到。但猜测可能是因为Skip connection的位置原因?因为对比了原本Transformer中的attention结构,skip connection传递的是整个x,即分为Q、K、V的前一部分。而这个非对称的注意力机制仅仅传递的是Q的信息,所以称为非对称?(希望有了解这部分的同学可以告知一下、讨论一下)
3.2.2. Semantic-Aware Guidance
这部分应该是做了两方面的工作
1. 一方面是对三个feature maps进行融合(如模型图所示,但文中这部分好像没怎么提及,主要在讲loss的问题)。
2. 引入Reconstruction loss和Utilization loss来指导filters。
其中,
- Reconstruction loss(我个人理解得比较模糊),大概是利用一个重构网络(Reconstruction Network),将每个filter输出的feature map作为输入,重构出每个filter相对应的textual feature(scene graph上的Entity、attribute、location),并用均方误差损失计算重构出的feature与实际textual feature之间的差距。
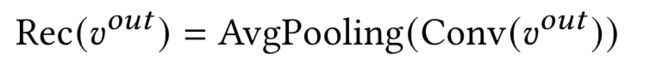
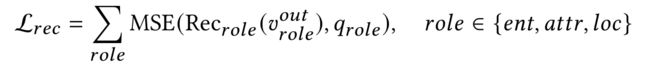
- Utilization loss中的div loss用来保证每一个词不会被多次关注,cover loss用来保证每个词都会被关注到。
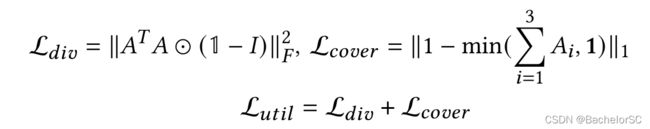
3.3. grounding module
最后将Location Filter输出的Feature map作为grounding module的输入,进行目标物体的框选,即预测bounding box的中心点坐标、长宽以及置信度。
通过均方误差损失和CIoU loss来对中心点坐标和长宽进行回归:

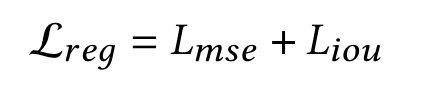
通过Binary Cross Entropy Loss对置信度进行预测:

**最终模型的loss由这四个部分组成:

4. Experimental Results
4.1 Overall performance
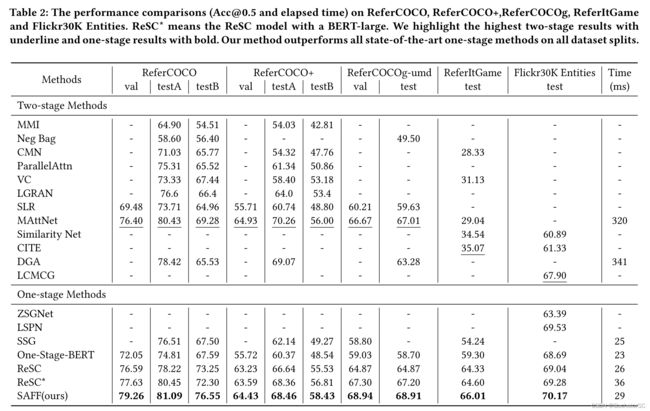
- 具体模型的实验结果如Table 2所示。
* 个人感觉针对一阶段模型的对比不够全面,有很多很好的一阶段方法没有体现在表格中,但总的来说,表现还是蛮不错的。
* 论文作者特别分析了两个问题,
1. One-stage-BERT方法直接将textual feature与visual feature map进行简单地拼接,没有更多地利用query的信息,难以超过部分两阶段的方法。而ReSC与本文方法均对query进行了进一步地处理,在一定程度上得到了提升,体现出对query进行挖掘处理的重要性。
2. 两阶段的方法大多先采用预训练的检测器框选出预选框(Proposals, 一般在MSCOCO上进行预训练利用Faster R-CNN),而RefCOCO系列数据集中的图片大多来自MSCOCO数据集,所以两阶段的模型在RefCOCO系列数据集上表现良好,但在其他来源的数据集(ReferItGame与Flicker30K Entities)中,表现有明显下降。
4.2 Ablation Study
消融实验的结果如Table 3所示,主要分析了Filters与scene graph带来的效果。
从Table 3中主要可以得到,Entity Filter所带来的提升最高,尤其是在testB中(因为在testA中,目标都是人;而在testB中,目标是非人的任意物体,所以entity filter的效果就更好地体现出来了)。
4.3 Qualitative Results
Figure 4主要是与One-Stage-BERT进行一个比较。三行分别体现所提出模型能够对Entity、Attribute与Location有更好地捕捉。
Figure 5主要是对不同filter的feature map进行一个可视化
* 论文作者解释:
1. 当句子中没有相对应于该filter的Q时,该filter不会对feature map进行大的变动。
2. 在最后两行中大家可以看到,当前两个filters发生错误的判断时,第三个filter是有能力对其进行纠正的。