NNDL 实验六 卷积神经网络(5)使用预训练resnet18实现CIFAR-10分类
5.5 实践:基于ResNet18网络完成图像分类任务
图像分类(Image Classification)
计算机视觉中的一个基础任务,将图像的语义将不同图像划分到不同类别。
很多任务可以转换为图像分类任务。
比如人脸检测就是判断一个区域内是否有人脸,可以看作一个二分类的图像分类任务。
数据集:CIFAR-10数据集,
网络:ResNet18模型,
损失函数:交叉熵损失,
优化器:Adam优化器,Adam优化器的介绍参考NNDL第7.2.4.3节。
评价指标:准确率。
5.5.1 数据处理
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
trainset = torchvision.datasets.CIFAR10(root='./cifar10', train=True, download=True,
transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=0)
testset = torchvision.datasets.CIFAR10(root='./cifar10', train=False, download=True,
transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=0)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
5.5.2 模型构建
使用pyotorch高层API中的resnet18进行图像分类实验。
torchvision.models.resnet18()
什么是“预训练模型”?什么是“迁移学习”?(必做)
预训练属于迁移学习的范畴。预训练的思想是:模型参数不再是随机初始化的,而是通过一些任务进行预先训练,得到一套模型参数,然后用这套参数对模型进行初始化,再进行训练。
比如在 CV(Computer Vision) 领域,多个 CNN 构成的 model 在训练后,越浅的层学到的特征越通用。因此,在大规模图片数据上预先获取的“通用特征”,会对下游任务有非常大的帮助。
在NLP(Natural Language Processing)领域,预训练通过自监督学习从大规模数据中获得与具体任务无关的预训练模型。体现某一个词在一个特定上下文中的语义表征。第二个步骤是微调,针对具体的任务修正网络。训练数据可以是文本、文本-图像对、文本-视频对。预训练模型的训练方法可使用自监督学习技术(如自回归的语言模型和自编码技术)。可训练单语言、多语言和多模态的模型。此类模型可经过微调之后,用于支持分类、序列标记、结构预测和序列生成等各项技术,并构建文摘、机器翻译、图片检索、视频注释等应用。
为什么我们要做预训练模型?首先,预训练模型是一种迁移学习的应用,利用几乎无限的文本,学习输入句子的每一个成员的上下文相关的表示,它隐式地学习到了通用的语法语义知识。第二,它可以将从开放领域学到的知识迁移到下游任务,以改善低资源任务,对低资源语言处理也非常有利。第三,预训练模型在几乎所有 NLP 任务中都取得了目前最佳的成果。最后,这个预训练模型+微调机制具备很好的可扩展性,在支持一个新任务时,只需要利用该任务的标注数据进行微调即可,一般工程师就可以实现。
ref:
https://www.zhihu.com/question/327642286
https://zhuanlan.zhihu.com/p/370859857
https://yubincloud.github.io/notebook/pages/dl/pretrained-lang-model/overview
比较“使用预训练模型”和“不使用预训练模型”的效果。(必做)
resnet = models.resnet18(pretrained=True)
resnet = models.resnet18(pretrained=False)
ref:
【深度学习】使用预训练模型_DrCrypto的博客-CSDN博客_深度学习预训练模型操作
pytorch学习笔记之加载预训练模型_AI算法札记的博客-CSDN博客_pytorch加载预训练模型
5.5.3 模型训练
import torch
import torchvision
from torch import nn, optim
from torchvision import transforms
if __name__=='__main__':
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
trainset = torchvision.datasets.CIFAR10(root='./cifar10', train=True, download=True,
transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=0)
testset = torchvision.datasets.CIFAR10(root='./cifar10', train=False, download=True,
transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=0)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
model=torchvision.models.resnet18()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
################训练网络###################
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
i = 0
for data in trainloader:
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
print(labels)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
i += 1
if i % 2000 == 1999:
print('[%d,%5d] loss:%.3f' % (epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
5.5.4 模型评价
correct=0
total=0
with torch.no_grad():
for data in testloader:
images,labels=data
outputs=net(images)
_,predicted=torch.max(outputs.data,1)
total+=labels.size(0)
correct+=(predicted==labels).sum().item()#.item()用于取出tensor中的值。
print("Accuracy of the network on the 10000 test images: %d %%"%(100*correct/total))
5.5.5 模型预测
class_correct=list(0. for i in range(10))
class_total=list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images,labels=data
outputs=net(images)
_,predicted=torch.max(outputs,1)
c=(predicted==labels).squeeze()
for i in range(4):
label=labels[i]
class_correct[label]+=c[i].item()
class_total[label]+=1
for i in range(10):
print('Accuracy of %5s : %2d %%'%(classes[i],100*class_correct[i]/class_total[i]))
全部代码:
import torch
import torchvision
from torch import nn, optim
from torchvision import transforms
if __name__=='__main__':
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
train_batch=100
test_batch=100
trainset = torchvision.datasets.CIFAR10(root='./cifar10', train=True, download=True,
transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=train_batch,
shuffle=True, num_workers=4)
testset = torchvision.datasets.CIFAR10(root='./cifar10', train=False, download=True,
transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=test_batch,
shuffle=False, num_workers=0)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
model=torchvision.models.resnet18()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
################训练网络###################
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
i = 0
for data in trainloader:
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
#print(labels)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
i += 1
if i % 10 == 0:
print('[train] [epoch:%4d,progress:%8d/60000] current loss: %.8f,total loss:%.8f'
% (epoch + 1, train_batch*(i + 1),loss.item(), running_loss))
print('Finished Training')
correct=0
total=0
with torch.no_grad():
for data in testloader:
images,labels=data
outputs=model(images)
_,predicted=torch.max(outputs.data,1)
total+=labels.size(0)
correct+=(predicted==labels).sum().item()#.item()用于取出tensor中的值。
print("[test] Accuracy of the network on the 10000 test images: %d %%"%(100*correct/total))
class_correct=list(0. for i in range(10))
class_total=list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images,labels=data
outputs=model(images)
_,predicted=torch.max(outputs,1)
c=(predicted==labels).squeeze()
for i in range(4):
label=labels[i]
class_correct[label]+=c[i].item()
class_total[label]+=1
for i in range(10):
print('[test] Accuracy of %5s : %2d %%'%(classes[i],100*class_correct[i]/class_total[i]))
运行结果;
E:\anaconda\envs\pytorch\pythonw.exe "C:/Users/lenovo/PycharmProjects/pythonProject1/deep_learning/实验六 卷积/resNet18/ResNet in pytorch.py"
Files already downloaded and verified
Files already downloaded and verified
[train] [epoch: 1,progress:1100] current loss: 6.13624811,total loss:67.25609064
[train] [epoch: 1,progress:2100] current loss: 3.69358182,total loss:114.05571795
[train] [epoch: 1,progress:3100] current loss: 2.41907239,total loss:142.13164544
[train] [epoch: 1,progress:4100] current loss: 2.10539055,total loss:163.48878336
[train] [epoch: 1,progress:5100] current loss: 2.11376381,total loss:184.81297827
[train] [epoch: 1,progress:6100] current loss: 1.83994770,total loss:204.64863205
[train] [epoch: 1,progress:7100] current loss: 1.94955289,total loss:223.99884737
[train] [epoch: 1,progress:8100] current loss: 1.88638508,total loss:242.97893214
[train] [epoch: 1,progress:9100] current loss: 1.98708820,total loss:261.45233059
[train] [epoch: 1,progress:10100] current loss: 1.70154142,total loss:279.22251356
[train] [epoch: 1,progress:11100] current loss: 1.74335659,total loss:296.87130320
[train] [epoch: 1,progress:12100] current loss: 1.64032352,total loss:314.56489134
[train] [epoch: 1,progress:13100] current loss: 1.75656176,total loss:331.98152947
[train] [epoch: 1,progress:14100] current loss: 1.74398732,total loss:349.29421329
[train] [epoch: 1,progress:15100] current loss: 1.66823888,total loss:365.72766638
[train] [epoch: 1,progress:16100] current loss: 1.47559083,total loss:381.95194674
[train] [epoch: 1,progress:17100] current loss: 1.53814316,total loss:398.54586196
[train] [epoch: 1,progress:18100] current loss: 1.55379140,total loss:414.95456207
[train] [epoch: 1,progress:19100] current loss: 1.54837346,total loss:431.01225412
[train] [epoch: 1,progress:20100] current loss: 1.65494418,total loss:447.14281750
[train] [epoch: 1,progress:21100] current loss: 1.48972285,total loss:463.32969725
[train] [epoch: 1,progress:22100] current loss: 1.49170697,total loss:479.29953611
[train] [epoch: 1,progress:23100] current loss: 1.61608922,total loss:495.17103708
[train] [epoch: 1,progress:24100] current loss: 1.66991305,total loss:511.00380814
[train] [epoch: 1,progress:25100] current loss: 1.58090734,total loss:527.19501138
[train] [epoch: 1,progress:26100] current loss: 1.71078098,total loss:543.50543725
[train] [epoch: 1,progress:27100] current loss: 1.47546220,total loss:559.09065187
[train] [epoch: 1,progress:28100] current loss: 1.54058039,total loss:574.31891251
[train] [epoch: 1,progress:29100] current loss: 1.53338611,total loss:589.91774333
[train] [epoch: 1,progress:30100] current loss: 1.51238012,total loss:604.97928488
[train] [epoch: 1,progress:31100] current loss: 1.41037512,total loss:620.50196207
[train] [epoch: 1,progress:32100] current loss: 1.61836588,total loss:636.55371666
[train] [epoch: 1,progress:33100] current loss: 1.70835185,total loss:651.46703780
[train] [epoch: 1,progress:34100] current loss: 1.54495025,total loss:665.80766940
[train] [epoch: 1,progress:35100] current loss: 1.34018981,total loss:681.05385697
[train] [epoch: 1,progress:36100] current loss: 1.46212566,total loss:695.95114207
[train] [epoch: 1,progress:37100] current loss: 1.70622098,total loss:711.47018182
[train] [epoch: 1,progress:38100] current loss: 1.56217837,total loss:726.26467133
[train] [epoch: 1,progress:39100] current loss: 1.31694758,total loss:740.98932743
[train] [epoch: 1,progress:40100] current loss: 1.59784877,total loss:755.40761220
[train] [epoch: 1,progress:41100] current loss: 1.30187213,total loss:769.68363965
[train] [epoch: 1,progress:42100] current loss: 1.43963933,total loss:784.08686852
[train] [epoch: 1,progress:43100] current loss: 1.44313598,total loss:798.40551054
[train] [epoch: 1,progress:44100] current loss: 1.36186385,total loss:812.66105425
[train] [epoch: 1,progress:45100] current loss: 1.30904973,total loss:827.12454164
[train] [epoch: 1,progress:46100] current loss: 1.35123813,total loss:841.01580155
[train] [epoch: 1,progress:47100] current loss: 1.56383514,total loss:855.66456175
[train] [epoch: 1,progress:48100] current loss: 1.41810346,total loss:870.12578535
[train] [epoch: 1,progress:49100] current loss: 1.38629162,total loss:884.52344751
[train] [epoch: 1,progress:50100] current loss: 1.59774721,total loss:898.81356180
[train] [epoch: 2,progress:1100] current loss: 1.23712122,total loss:12.86300862
[train] [epoch: 2,progress:2100] current loss: 1.20775127,total loss:25.88925457
[train] [epoch: 2,progress:3100] current loss: 1.33718967,total loss:39.67399979
[train] [epoch: 2,progress:4100] current loss: 1.33741367,total loss:53.10009599
[train] [epoch: 2,progress:5100] current loss: 1.45158601,total loss:66.73144758
[train] [epoch: 2,progress:6100] current loss: 1.39321029,total loss:80.11322498
[train] [epoch: 2,progress:7100] current loss: 1.17969263,total loss:92.90521169
[train] [epoch: 2,progress:8100] current loss: 1.29362595,total loss:105.59648585
[train] [epoch: 2,progress:9100] current loss: 1.30120885,total loss:118.46285558
[train] [epoch: 2,progress:10100] current loss: 1.34807515,total loss:131.06931067
[train] [epoch: 2,progress:11100] current loss: 1.19644570,total loss:143.75968862
[train] [epoch: 2,progress:12100] current loss: 1.28910077,total loss:157.09737194
[train] [epoch: 2,progress:13100] current loss: 1.38730693,total loss:170.07862926
[train] [epoch: 2,progress:14100] current loss: 1.28000081,total loss:182.90565944
[train] [epoch: 2,progress:15100] current loss: 1.47037995,total loss:196.15138328
[train] [epoch: 2,progress:16100] current loss: 1.30195904,total loss:209.52546656
[train] [epoch: 2,progress:17100] current loss: 1.26683009,total loss:222.52538347
[train] [epoch: 2,progress:18100] current loss: 1.13300931,total loss:235.24764097
[train] [epoch: 2,progress:19100] current loss: 1.40119016,total loss:248.23708284
[train] [epoch: 2,progress:20100] current loss: 1.39123642,total loss:261.42587984
[train] [epoch: 2,progress:21100] current loss: 1.46321583,total loss:274.26788199
[train] [epoch: 2,progress:22100] current loss: 1.51543629,total loss:286.93508935
[train] [epoch: 2,progress:23100] current loss: 1.49615324,total loss:299.90845728
[train] [epoch: 2,progress:24100] current loss: 1.14281559,total loss:312.73510349
[train] [epoch: 2,progress:25100] current loss: 1.26437175,total loss:325.40820491
[train] [epoch: 2,progress:26100] current loss: 1.48527348,total loss:337.82042229
[train] [epoch: 2,progress:27100] current loss: 1.34424579,total loss:350.83329690
[train] [epoch: 2,progress:28100] current loss: 1.30290103,total loss:363.87074721
[train] [epoch: 2,progress:29100] current loss: 1.31180251,total loss:376.80115938
[train] [epoch: 2,progress:30100] current loss: 1.34749556,total loss:389.46883082
[train] [epoch: 2,progress:31100] current loss: 1.29698610,total loss:402.38504517
[train] [epoch: 2,progress:32100] current loss: 1.33517551,total loss:414.87528050
[train] [epoch: 2,progress:33100] current loss: 1.34424698,total loss:427.12457216
[train] [epoch: 2,progress:34100] current loss: 1.13221002,total loss:439.47065020
[train] [epoch: 2,progress:35100] current loss: 1.23041677,total loss:452.33514583
[train] [epoch: 2,progress:36100] current loss: 1.34823978,total loss:464.71715105
[train] [epoch: 2,progress:37100] current loss: 1.09089589,total loss:477.11281085
[train] [epoch: 2,progress:38100] current loss: 1.16201735,total loss:489.57728660
[train] [epoch: 2,progress:39100] current loss: 1.11253071,total loss:501.81550026
[train] [epoch: 2,progress:40100] current loss: 1.06689942,total loss:514.17565215
[train] [epoch: 2,progress:41100] current loss: 1.31519747,total loss:527.20973372
[train] [epoch: 2,progress:42100] current loss: 1.19840765,total loss:539.82242930
[train] [epoch: 2,progress:43100] current loss: 1.18474913,total loss:551.48127282
[train] [epoch: 2,progress:44100] current loss: 1.28006673,total loss:563.43119252
[train] [epoch: 2,progress:45100] current loss: 1.15449870,total loss:575.84575450
[train] [epoch: 2,progress:46100] current loss: 0.98517221,total loss:587.85547847
[train] [epoch: 2,progress:47100] current loss: 1.29166782,total loss:600.48864514
[train] [epoch: 2,progress:48100] current loss: 1.38885558,total loss:612.82138389
[train] [epoch: 2,progress:49100] current loss: 1.10498428,total loss:625.17819303
[train] [epoch: 2,progress:50100] current loss: 1.21590030,total loss:637.23801953
Finished Training
Accuracy of the network on the 10000 test images: 54 %
Accuracy of plane : 72 %
Accuracy of car : 62 %
Accuracy of bird : 28 %
Accuracy of cat : 34 %
Accuracy of deer : 38 %
Accuracy of dog : 40 %
Accuracy of frog : 77 %
Accuracy of horse : 50 %
Accuracy of ship : 54 %
Accuracy of truck : 62 %
Process finished with exit code 0
预训练的:
代码和想象中的不太一样,没想到是直接赋权重,这就是预训练吗。把别处训练过的权重赋上,迁移训练。
model=torchvision.models.resnet18(weights=torchvision.models.ResNet18_Weights.DEFAULT)
数据集cifar10和resnet的预训练权重都是需要联网下载的,而且可能会有些慢,耐心等待即可。
全部代码:
import torch
import torchvision
from torch import nn, optim
from torchvision import transforms
if __name__=='__main__':
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
train_batch=100
test_batch=100
trainset = torchvision.datasets.CIFAR10(root='./cifar10', train=True, download=True,
transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=train_batch,
shuffle=True, num_workers=4)
testset = torchvision.datasets.CIFAR10(root='./cifar10', train=False, download=True,
transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=test_batch,
shuffle=False, num_workers=0)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
model=torchvision.models.resnet18(weights=torchvision.models.ResNet18_Weights.DEFAULT)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
################训练网络###################
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
i = 0
for data in trainloader:
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
#print(labels)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
i += 1
if i % 10 == 0:
print('[train] [epoch:%4d,progress:%8d/60000] current loss: %.8f,total loss:%.8f'
% (epoch + 1, train_batch*(i + 1),loss.item(), running_loss))
print('Finished Training')
correct=0
total=0
with torch.no_grad():
for data in testloader:
images,labels=data
outputs=model(images)
_,predicted=torch.max(outputs.data,1)
total+=labels.size(0)
correct+=(predicted==labels).sum().item()#.item()用于取出tensor中的值。
print("[test] Accuracy of the network on the 10000 test images: %d %%"%(100*correct/total))
class_correct=list(0. for i in range(10))
class_total=list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images,labels=data
outputs=model(images)
_,predicted=torch.max(outputs,1)
c=(predicted==labels).squeeze()
for i in range(4):
label=labels[i]
class_correct[label]+=c[i].item()
class_total[label]+=1
for i in range(10):
print('[test] Accuracy of %5s : %2d %%'%(classes[i],100*class_correct[i]/class_total[i]))
运行结果:
E:\anaconda\envs\pytorch\pythonw.exe "C:/Users/lenovo/PycharmProjects/pythonProject1/deep_learning/实验六 卷积/resNet18/ResNet in pytorch.py"
Files already downloaded and verified
Files already downloaded and verified
Downloading: "https://download.pytorch.org/models/resnet18-f37072fd.pth" to C:\Users\lenovo/.cache\torch\hub\checkpoints\resnet18-f37072fd.pth
100.0%
[train] [epoch: 1,progress: 1100/60000] current loss: 6.44962502,total loss:104.23545074
[train] [epoch: 1,progress: 2100/60000] current loss: 3.64255428,total loss:149.51087689
[train] [epoch: 1,progress: 3100/60000] current loss: 2.23366070,total loss:178.05312848
[train] [epoch: 1,progress: 4100/60000] current loss: 1.95446157,total loss:200.64753437
[train] [epoch: 1,progress: 5100/60000] current loss: 1.92531002,total loss:220.13063157
[train] [epoch: 1,progress: 6100/60000] current loss: 1.72997355,total loss:237.03692865
[train] [epoch: 1,progress: 7100/60000] current loss: 1.53561401,total loss:252.96579027
[train] [epoch: 1,progress: 8100/60000] current loss: 1.47000706,total loss:267.74324155
[train] [epoch: 1,progress: 9100/60000] current loss: 1.50263107,total loss:281.62122726
[train] [epoch: 1,progress: 10100/60000] current loss: 1.62587798,total loss:296.52530277
[train] [epoch: 1,progress: 11100/60000] current loss: 1.33825588,total loss:309.34918058
[train] [epoch: 1,progress: 12100/60000] current loss: 1.37812579,total loss:322.54413462
[train] [epoch: 1,progress: 13100/60000] current loss: 1.45693970,total loss:335.07965386
[train] [epoch: 1,progress: 14100/60000] current loss: 1.37883687,total loss:347.76122677
[train] [epoch: 1,progress: 15100/60000] current loss: 1.35625279,total loss:359.88248348
[train] [epoch: 1,progress: 16100/60000] current loss: 1.18618429,total loss:371.86908638
[train] [epoch: 1,progress: 17100/60000] current loss: 1.13633084,total loss:384.25688338
[train] [epoch: 1,progress: 18100/60000] current loss: 0.98062050,total loss:395.79614460
[train] [epoch: 1,progress: 19100/60000] current loss: 1.22239566,total loss:407.57580829
[train] [epoch: 1,progress: 20100/60000] current loss: 1.05237806,total loss:418.57438403
[train] [epoch: 1,progress: 21100/60000] current loss: 1.16758525,total loss:429.48532301
[train] [epoch: 1,progress: 22100/60000] current loss: 1.07608497,total loss:440.76221782
[train] [epoch: 1,progress: 23100/60000] current loss: 1.09740746,total loss:451.73765355
[train] [epoch: 1,progress: 24100/60000] current loss: 1.07278252,total loss:462.04030168
[train] [epoch: 1,progress: 25100/60000] current loss: 1.22691488,total loss:472.72880459
[train] [epoch: 1,progress: 26100/60000] current loss: 0.92724061,total loss:482.70489424
[train] [epoch: 1,progress: 27100/60000] current loss: 1.09177864,total loss:492.90063387
[train] [epoch: 1,progress: 28100/60000] current loss: 1.00049543,total loss:503.16061181
[train] [epoch: 1,progress: 29100/60000] current loss: 1.04018176,total loss:512.95926744
[train] [epoch: 1,progress: 30100/60000] current loss: 1.26912296,total loss:523.08658010
[train] [epoch: 1,progress: 31100/60000] current loss: 0.95660293,total loss:532.97739303
[train] [epoch: 1,progress: 32100/60000] current loss: 0.82775354,total loss:542.33793402
[train] [epoch: 1,progress: 33100/60000] current loss: 1.11581945,total loss:552.57173121
[train] [epoch: 1,progress: 34100/60000] current loss: 1.02144253,total loss:562.60286856
[train] [epoch: 1,progress: 35100/60000] current loss: 1.25376332,total loss:572.63706434
[train] [epoch: 1,progress: 36100/60000] current loss: 1.02658212,total loss:582.03729939
[train] [epoch: 1,progress: 37100/60000] current loss: 0.77835333,total loss:591.09992331
[train] [epoch: 1,progress: 38100/60000] current loss: 0.73844427,total loss:600.48195493
[train] [epoch: 1,progress: 39100/60000] current loss: 0.96010339,total loss:610.29105914
[train] [epoch: 1,progress: 40100/60000] current loss: 0.98078936,total loss:619.15847605
[train] [epoch: 1,progress: 41100/60000] current loss: 1.24802184,total loss:628.35113668
[train] [epoch: 1,progress: 42100/60000] current loss: 0.79461062,total loss:637.14486843
[train] [epoch: 1,progress: 43100/60000] current loss: 0.85933167,total loss:645.33803612
[train] [epoch: 1,progress: 44100/60000] current loss: 0.85465872,total loss:654.52570778
[train] [epoch: 1,progress: 45100/60000] current loss: 0.88379282,total loss:663.62296861
[train] [epoch: 1,progress: 46100/60000] current loss: 0.87264657,total loss:672.80134958
[train] [epoch: 1,progress: 47100/60000] current loss: 0.81886160,total loss:680.97741282
[train] [epoch: 1,progress: 48100/60000] current loss: 0.96110243,total loss:689.83836997
[train] [epoch: 1,progress: 49100/60000] current loss: 0.77773172,total loss:698.52863169
[train] [epoch: 1,progress: 50100/60000] current loss: 0.65966088,total loss:706.87339854
[train] [epoch: 2,progress: 1100/60000] current loss: 0.70355201,total loss:7.39392358
[train] [epoch: 2,progress: 2100/60000] current loss: 0.69628495,total loss:14.92925715
[train] [epoch: 2,progress: 3100/60000] current loss: 0.87743086,total loss:22.84547877
[train] [epoch: 2,progress: 4100/60000] current loss: 0.74076307,total loss:30.55666602
[train] [epoch: 2,progress: 5100/60000] current loss: 0.72083169,total loss:37.74871439
[train] [epoch: 2,progress: 6100/60000] current loss: 0.71627802,total loss:45.34429926
[train] [epoch: 2,progress: 7100/60000] current loss: 0.67249179,total loss:52.74229586
[train] [epoch: 2,progress: 8100/60000] current loss: 0.65453970,total loss:59.81792611
[train] [epoch: 2,progress: 9100/60000] current loss: 0.65962923,total loss:66.80921549
[train] [epoch: 2,progress: 10100/60000] current loss: 0.85754585,total loss:74.63119823
[train] [epoch: 2,progress: 11100/60000] current loss: 0.67190123,total loss:82.03544819
[train] [epoch: 2,progress: 12100/60000] current loss: 0.62019897,total loss:88.82898015
[train] [epoch: 2,progress: 13100/60000] current loss: 0.63945836,total loss:96.64557558
[train] [epoch: 2,progress: 14100/60000] current loss: 0.61524874,total loss:103.92505318
[train] [epoch: 2,progress: 15100/60000] current loss: 0.67298448,total loss:110.65860122
[train] [epoch: 2,progress: 16100/60000] current loss: 0.67155039,total loss:117.33448493
[train] [epoch: 2,progress: 17100/60000] current loss: 0.77725840,total loss:124.39044738
[train] [epoch: 2,progress: 18100/60000] current loss: 0.76899725,total loss:131.67402887
[train] [epoch: 2,progress: 19100/60000] current loss: 0.70169699,total loss:138.87943202
[train] [epoch: 2,progress: 20100/60000] current loss: 0.76491112,total loss:145.58823180
[train] [epoch: 2,progress: 21100/60000] current loss: 0.84268522,total loss:153.16941404
[train] [epoch: 2,progress: 22100/60000] current loss: 0.79165113,total loss:160.33974516
[train] [epoch: 2,progress: 23100/60000] current loss: 0.64944369,total loss:167.81325036
[train] [epoch: 2,progress: 24100/60000] current loss: 0.70604932,total loss:175.18442589
[train] [epoch: 2,progress: 25100/60000] current loss: 0.74584913,total loss:182.53578365
[train] [epoch: 2,progress: 26100/60000] current loss: 0.77742791,total loss:189.62329739
[train] [epoch: 2,progress: 27100/60000] current loss: 0.61005616,total loss:197.09843433
[train] [epoch: 2,progress: 28100/60000] current loss: 0.62526590,total loss:203.91446370
[train] [epoch: 2,progress: 29100/60000] current loss: 0.71333641,total loss:210.62251931
[train] [epoch: 2,progress: 30100/60000] current loss: 0.71446037,total loss:217.29327658
[train] [epoch: 2,progress: 31100/60000] current loss: 0.91388643,total loss:224.21985617
[train] [epoch: 2,progress: 32100/60000] current loss: 0.72928602,total loss:231.23119250
[train] [epoch: 2,progress: 33100/60000] current loss: 0.63907015,total loss:238.59305924
[train] [epoch: 2,progress: 34100/60000] current loss: 0.68230683,total loss:245.65837508
[train] [epoch: 2,progress: 35100/60000] current loss: 0.69273710,total loss:252.00835150
[train] [epoch: 2,progress: 36100/60000] current loss: 0.79625666,total loss:259.00467783
[train] [epoch: 2,progress: 37100/60000] current loss: 0.56628156,total loss:265.83091813
[train] [epoch: 2,progress: 38100/60000] current loss: 0.74482799,total loss:273.03627270
[train] [epoch: 2,progress: 39100/60000] current loss: 0.65263849,total loss:279.59109795
[train] [epoch: 2,progress: 40100/60000] current loss: 0.68548876,total loss:286.77913612
[train] [epoch: 2,progress: 41100/60000] current loss: 0.77134734,total loss:293.82879484
[train] [epoch: 2,progress: 42100/60000] current loss: 0.57886291,total loss:300.74744368
[train] [epoch: 2,progress: 43100/60000] current loss: 0.68060601,total loss:307.41130221
[train] [epoch: 2,progress: 44100/60000] current loss: 0.74839175,total loss:313.92025071
[train] [epoch: 2,progress: 45100/60000] current loss: 0.82524073,total loss:320.42816576
[train] [epoch: 2,progress: 46100/60000] current loss: 0.63565874,total loss:327.79208472
[train] [epoch: 2,progress: 47100/60000] current loss: 0.64497083,total loss:334.99261996
[train] [epoch: 2,progress: 48100/60000] current loss: 0.64834648,total loss:342.30415812
[train] [epoch: 2,progress: 49100/60000] current loss: 0.47383699,total loss:348.38413984
[train] [epoch: 2,progress: 50100/60000] current loss: 0.77741671,total loss:355.53344983
Finished Training
[test] Accuracy of the network on the 10000 test images: 74 %
[test] Accuracy of plane : 86 %
[test] Accuracy of car : 90 %
[test] Accuracy of bird : 52 %
[test] Accuracy of cat : 67 %
[test] Accuracy of deer : 67 %
[test] Accuracy of dog : 68 %
[test] Accuracy of frog : 81 %
[test] Accuracy of horse : 87 %
[test] Accuracy of ship : 79 %
[test] Accuracy of truck : 75 %
Process finished with exit code 0
对比:
两个都训练了两轮,不预训练的网络的正确率为54%,预训练的为74%,相去甚远。
思考题
1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。(选做)
全英的,没点水平还看不了。。。挑了几个具有代表性的图片和表格解释一下。

这是说只增加网络层数会导致一种后果就是,当网络层数达到一定程度上,网络训练的效果会下降,途中很清晰的说明了,当训练迭代数均为10^4时,20层的神经网络的准确率要高于56层的。稍微思考一下就会想到是梯度消失问题,之前说到过。哪怕是用偏导数大的激活函数也会有梯度消失问题的。
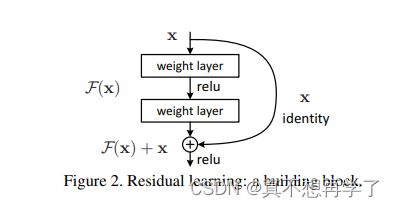
于是发明了这种,残差网络,有效缓解了梯度消失问题,于是基于这种残差单元,研究了不同层数的resnet网络。包括18,34,50,101和152这么几个层数。
上面的这张图pain在网上看了n多次了。
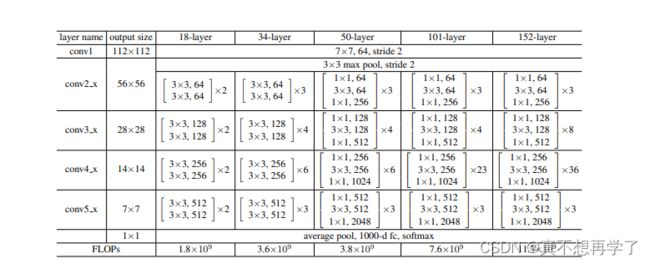
根据表格,可以看出虽然层数有较大差距,但是具体的每一层都是差不多的,只是数量上的差别。
值得注意到的是,当层数达到50时,就开始为每一个卷积单元(conv?_x)的每一个残差单元加上一个1x1的卷积核,用来进行对参数升降维,应该是减少参数量以提高训练效率。
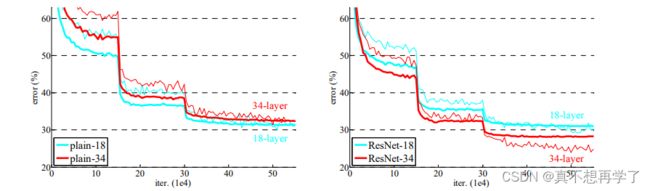
论文进行了一个对比,左边的是没有加残差单元的18层网络,右边的是加了的,可以看到右边的34层resnet明显训练效果要优于18层resnet。
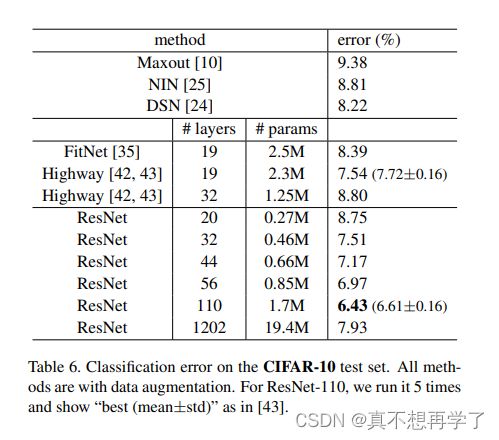
各个层数训练cifar10数据集。参数量是逐级上升的,损失比较起来却比较均衡。加粗的那个110层训练了5次,得到了一个最优的损失率。
网上很多博客、论文都用到了以上图片,这下找到源头了。
2.用自己的话简单评价:LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)
LeNet是7层的,有用于解决手写数字识别的网络,十分经典。
AlexNet与LeNet相比,具有更深的网络结构,包含5层卷积和3层全连接,同时使用了如下三种方法改进模型的训练过程:
1)数据增广:深度学习中常用的一种处理方式,通过对训练随机加一些变化,比如平移、缩放、裁剪、旋转、翻转或者增减亮度等,产生一系列跟原始图片相似但又不完全相同的样本,从而扩大训练数据集。通过这种方式,可以随机改变训练样本,避免模型过度依赖于某些属性,能从一定程度上抑制过拟合。
2)使用Dropout抑制过拟合
3)使用ReLU激活函数减少梯度消失现象
VGG有13层卷积和3层全连接层。VGG网络的设计严格使用3×3的卷积层和池化层来提取特征,并在网络的最后面使用三层全连接层,将最后一层全连接层的输出作为分类的预测。由于卷积核比较小,可以堆叠更多的卷积层,加深网络的深度,这对于图像分类任务来说是有利的。VGG模型的证明了增加网络的深度,可以更好的学习图像中的特征。
GooLeNet的主要特点是网络不仅有深度,还在横向上具有“宽度”。GoogLeNet提出了一种被称为Inception模块的方案。使用3个不同大小的卷积核对输入图片进行卷积操作,并附加最大池化,将这4个操作的输出沿着通道这一维度进行拼接,构成的输出特征图将会包含经过不同大小的卷积核提取出来的特征。同时为了减少参数量,在每个3x3和5x5的卷积层之前,增加1x1的卷积层来控制输出通道数;在最大池化层后面增加1x1卷积层减小输出通道数。GooLeNet使用多通路计算,每个通路用不同的卷积核计算。这也是为什么参数量很大,需要降低参数量。
ResNet设计了残差模块,使网络能叠加更多的层数从而提高模型的训练效果,其也沿用了使用1*1卷积核控制通道数。
ref:
https://zhuanlan.zhihu.com/p/162881214
总结:
实验尝试了LeNet、ResNet,而AlexNet、VGG、GoogLeNet也都学过了,可以说他们的发展是一个循序渐进的过程。
感觉学到了挺多,挺好的。成就感拉满,但是也有不少遗憾,也是可以接受的。
使用思维导图全面总结CNN(必做)