语义分割动手实践 - labelme标注和标签生成
语义分割动手实践 - labelme标注和标签生成
最近接触到语义分割任务,借助deeplabv3+和BiSeNet v2对分割任务有了初步的了解,为自己记录下整个流程
1、语义分割数据标注
标注工具:由于语义/实例分割任务多是多边形(polygons)轮廓标注,在此选用labelme标注工具。
labelme安装,有需要可以创建虚拟环境,有python和pyqt5即可:
创建labelme虚拟环境
conda create -n labelme python=3.8
激活虚拟环境
conda activate labelme
pip安装pyqt5
pip install pyqt5
安装labelme
pip install labelme
界面:

语义分割标注需要十分精细化,标注过程很复杂耗时,便捷的工具很重要。labelme支持自定义快捷键,可提高标注效率:
在win10环境标注的话,在用户目录下,修改labelme的配置文件:C:\Users\yourUserName\.labelmerc
本文自定义快捷键 (可在.labelmerc对应位置修改):
左侧工具栏openDir:打开待标注的图像目录
按 A 和 D 进入上一张 / 下一张图像 (默认)
按 w - 进入多边形标注模式
按 E - 多边形框编辑模式 (可拖动点调整框的边缘和位置)
每标注完一张可以按E,观察一下这张图像是否有遗漏,是否紧密。
在编辑模式下按delete可以删除选中的多边形框
按ctrl + z 撤销上一步操作 ( 撤销上一个点 )
按Esc - 撤销当前未标注完的多边形框
需要在多边形的边上加点时,鼠标移动到polygons的边上,变成小手后,右键Add point to Edge, 或快捷键ctrl + shift + p
修改.labelmerc
auto_save: false,改为true,自动保存图像,标注完可以直接按D进入下一张
save: Ctrl+S 改为 save: [Space,Ctrl+S] 表示适用空格和Ctrl+s两种方法进行保存
create_polygon: Ctrl+N 改为 create_polygon: [W, Ctrl+N] 表示使用W 和ctrl+n 两种方式进行画框
edit_polygon: Ctrl+J 改为 edit_polygon: [E, Ctrl+J] 表示使用E 和Ctrl+j ;两种方式进行编辑框
2、根据json批量生成mask标签图像
- labelme_json_to_dataset脚本生成单张图像
labelme提供了生成数据的脚本:labelme_json_to_dataset
标注时如果没有取消File - save with image data,labelme会在json文件中自动保存该张图像的base64数据。
终端输入labelme_json_to_dataset + 文件名.json即可生成标签图像:
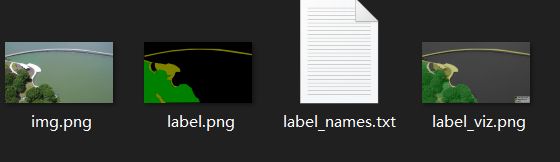
生成的__json文件夹中:
- img.png 对应的局部的jpg原图文件,训练时要用
- label.png 局部类别标签
- label_names.txt 在这张图像上目标的分类名称
- label_viz.png 可视化标签图,便于我们确认是否标记正确
观察labelme的源码可以发现,生成mask时会根据分类排序,自动从颜色表中匹配颜色。生成label.png,其中用到了imgviz库的label2rgb方法:
label_names=['_background_', 'person', 'car', 'land', 'sky']
# input: 从json中读取的标签分类lbl,灰度的img, label_names(分割种类字典)
lbl_viz = imgviz.label2rgb(
label=lbl, img=imgviz.asgray(img), label_names=label_names, loc="rb"
)
其中imgviz.label2rgb()的api:
我们只需修改前四个参数:label, image=None, alpha=0.5, label_names=None,本文浅显的理解是该函数根据分类序列分配alpha=0.5的颜色值,并将lbl当中的多边形数据copy - paste到输入的灰度图中,构成label_viz.png
alpha=0.5 即各个种类的颜色会128递增:颜色列表如下(最多可有256个分类):
return np.asarray([[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0],
[0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128],
[64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0],
[64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128],
[0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0],
[0, 64, 128]])
imgviz.label2rgb():
imgviz.label2rgb(label, image=None, alpha=0.5, label_names=None, font_size=30, thresh_suppress=0, colormap=None, loc='rb', font_path=None)[source]
-
labelme_json_to_dataset批量生成图像
我们经过上一步可以根据json生成原图.png和mask.png。这就是我们的训练数据所需。
但labelme提供的labelme_json_to_dataset脚本存在两个问题:
(1) 一次只能处理单张json文件,不能批量
(2) 因为该脚本默认根据json中的label标签序列生成mask图像,导致掩膜的颜色也是顺序排列的。当某张图像不包含全部分类时,掩膜(label.png)的颜色会错乱。如我们希望四个分类0,1,2,3分别对应0黑,1红,2绿,3橙。若某张图像中仅有类别0,2,3。该脚本生成的label.png颜色依然是 0黑,2红,3绿。导致颜色不一致的问题。
通过借鉴其他人的思路【链接:https://zhuanlan.zhihu.com/p/159837405 侵删】
问题1:加个for循环批量调用脚本生成
# json文件路径 def json2masksImg(json_path): files = os.listdir(json_path) for i in files: full_name = osp.join(json_path, i) if full_name.endswith(".json"): # 取后缀名 os.system("labelme_json_to_dataset.exe %s" % full_name) print("转换完成!")问题2:修改labelme脚本的源码
源码路径:通过anaconda 安装的路径在这里:
D:\Anaconda3\envs\labelme\Lib\site-packages\labelme\cli\json_to_dataset.py
import argparse
import base64
import json
import os
import os.path as osp
import imgviz
import PIL.Image
from labelme.logger import logger
from labelme import utils
# labelme_json_to_dataset source code
def main():
logger.warning(
"This script is aimed to demonstrate how to convert the "
"JSON file to a single image dataset."
)
logger.warning(
"It won't handle multiple JSON files to generate a "
"real-use dataset."
)
parser = argparse.ArgumentParser()
parser.add_argument("json_file")
parser.add_argument("-o", "--out", default=None)
args = parser.parse_args()
json_file = args.json_file
if args.out is None:
out_dir = osp.basename(json_file).replace(".", "_")
out_dir = osp.join(osp.dirname(json_file), out_dir)
else:
out_dir = args.out
if not osp.exists(out_dir):
os.mkdir(out_dir)
data = json.load(open(json_file))
imageData = data.get("imageData")
if not imageData:
imagePath = os.path.join(os.path.dirname(json_file), data["imagePath"])
with open(imagePath, "rb") as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode("utf-8")
img = utils.img_b64_to_arr(imageData)
#-----------------------------更改部分从这里开始------------------------------
# label_name_to_value = {"_background_": 0}
# for shape in sorted(data["shapes"], key=lambda x: x["label"]):
# label_name = shape["label"]
# if label_name in label_name_to_value:
# label_value = label_name_to_value[label_name]
# else:
# label_value = len(label_name_to_value)
# label_name_to_value[label_name] = label_value
#其中'_background_': 0为背景信息,如无特殊需要不需改变,后面则为你的自定义标签
# 加入字典索引后就会按照我们的分类选择label颜色
label_name_to_value={'_background_': 0, 'algae': 1, 'vegetation': 2, 'land': 3, 'structure': 4}
lbl, _, lbl_names = utils.shapes_to_label( # 为解决问题2的同时,保证label_names.txt只写入当前图像中出现的类别。
img.shape, data["shapes"], label_name_to_value
)
# label_names = [None] * (max(label_name_to_value.values()) + 1)
# for name, value in label_name_to_value.items():
# label_names[value] = name
# print(label_names)
# 此部分代码为在图像上显示标签入label_viz.png所示
label_names=['_background_', 'algae', 'vegetation', 'land', 'structure']
lbl_viz = imgviz.label2rgb(
label=lbl, img=imgviz.asgray(img), label_names=label_names, loc="rb"
)
PIL.Image.fromarray(img).save(osp.join(out_dir, "img.png"))
utils.lblsave(osp.join(out_dir, "label.png"), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, "label_viz.png"))
with open(osp.join(out_dir, "label_names.txt"), "w") as f: # 仅写入当前图像所含有的类别
for lbl_n in lbl_names:
f.write(lbl_names[lbl_n] + "\n")
logger.info("Saved to: {}".format(out_dir))
if __name__ == "__main__":
main()
修改utils/shape.py文件中的,多返回一个参数lbl_name存放当前图像含有的类别
def shapes_to_label(img_shape, shapes, label_name_to_value):
cls = np.zeros(img_shape[:2], dtype=np.int32)
ins = np.zeros_like(cls)
instances = []
lbl_name = []
for shape in shapes:
points = shape["points"]
label = shape["label"]
group_id = shape.get("group_id")
if group_id is None:
group_id = uuid.uuid1()
shape_type = shape.get("shape_type", None)
cls_name = label
instance = (cls_name, group_id)
if instance not in instances:
instances.append(instance)
ins_id = instances.index(instance) + 1
cls_id = label_name_to_value[cls_name]
mask = shape_to_mask(img_shape[:2], points, shape_type)
cls[mask] = cls_id
ins[mask] = ins_id
lbl_name.append(0) # 加入背景类别
lbl_name.sort() # 0 1 2 3 4
return cls, ins, lbl_name
3、批量生成json目录构建数据集
脚本帮我们生成大量_json结尾目录,我们还需要分别提取原图和mask,并划分数据集。
自己写的辣鸡处理脚本,不嫌弃可拿去用。
moveSrcMasksImage()
脚本input: 放有_json文件夹的目录
输出:在json_dir的上层目录创建JPEGImages和SegmentationClass目录存放以_json文件夹命名的原图和mask图像
def moveSrcMasksImage(json_dir):
# 获取_json文件夹上级目录
pre_dir = os.path.abspath(os.path.dirname(os.path.dirname(json_dir)))
img_dir = osp.join(pre_dir, "JPEGImages")
mask_dir = osp.join(pre_dir, "SegmentationClass")
# 目录不存在创建
if not osp.exists(img_dir):
os.makedirs(img_dir)
if not osp.exists(mask_dir):
os.makedirs(mask_dir)
# 批量移动srcimg和mask到指定目录
count = 0 # 记录移动次数
for dirs in os.listdir(json_dir):
dir_name = osp.join(json_dir, dirs)
if not osp.isdir(dir_name): # 不是目录
continue
if dir_name.rsplit('_', 1)[-1] != 'json': # 非_json文件夹
continue
if not os.listdir(dir_name): # 目录为空
continue
count += 1
# 所有__json目录下的img.png,label.png 用目录名改为同名文件
'''
img.png
label.png
label_names.txt
label_viz.png
'''
img_path = osp.join(dir_name, 'img.png')
label_path = osp.join(dir_name, 'label.png')
new_name = dirs.rsplit('_', 1)[0] + '.png'
# print('new_name: ', new_name)
# 先复制文件到源目录,再分别移动到img和masks
new_name_path = osp.join(dir_name, new_name)
shutil.copy(img_path, new_name_path) # copy srcimg
shutil.move(new_name_path, osp.join(img_dir, new_name)) # move img_dir
print('{} ====> {}'.format(new_name, "JPEGImages"))
shutil.copy(label_path, new_name_path) # copy srcimg
shutil.move(new_name_path, osp.join(mask_dir, new_name)) # move img_dir
print('{} ====> {}'.format(new_name, "SegmentationClass"))
print('共整理、移动{}张图像'.format(count))
return img_dir, mask_dir
couple_img_masks() 数据集划分脚本
输入JPEGImages和SegmentationClass的路径,
输出:分别在JPEGImages和SegmentationClass目录中创建train、test、val文件夹,并将划分的图像和mask复制到文件夹下。同事生成对应的txt标签文件。txt文件的格式为:原图路径.png,掩膜路径.png (用逗号分隔)
'''
针对原图和掩膜图像, 构建数据集
训练集、验证集、测试集划分
'''
def couple_img_masks(img_path, mask_path):
'''
JPEGImages / SegmentationClass已经存在
'''
# 获取img_path和mask_path的上级目录
pre_dir = os.path.abspath(os.path.dirname(os.path.dirname(img_path)))
img_dir = "JPEGImages/"
mask_dir = "SegmentationClass/"
list_dir = ['test', 'val', 'train']
for dirs in list_dir:
if not os.path.exists(osp.join(img_path, dirs)):
os.makedirs(osp.join(img_path, dirs))
if not os.path.exists(osp.join(mask_path, dirs)):
os.makedirs(osp.join(mask_path, dirs))
# 按照6:2:2构造数据集
count_test = 0
count_val = 0
count_train = 0
for files in os.listdir(img_path):
if files.split('.')[-1] != 'png':
continue
num = np.random.rand(1)
if num[0] < 0.2:
with open(osp.join(pre_dir, 'test.txt'), 'a', encoding='utf-8') as f_test:
print('{} ==> test '.format(files))
f_test.write(img_dir + 'test/' + files + ',' + mask_dir + 'test/' + files + '\n') # 写入数据
shutil.copyfile(osp.join(img_path, files), img_path + '\\test\\' + files) # 移动源文件
shutil.copyfile(osp.join(mask_path, files), mask_path + '\\test\\' + files) # 移动mask
count_test += 1
elif num[0] < 0.4:
with open(osp.join(pre_dir,'val.txt'), 'a', encoding='utf-8') as f_val:
print('{} ==> val '.format(files))
f_val.write(img_dir + 'val/' + files + ',' + mask_dir + 'val/' + files + '\n') # 写入数据
shutil.copyfile(osp.join(img_path, files), img_path + '\\val\\' + files) # 移动源文件
shutil.copyfile(osp.join(mask_path, files), mask_path + '\\val\\' + files) # 移动mask
count_val += 1
elif num[0] >= 0.4:
with open(osp.join(pre_dir, 'train.txt'), 'a', encoding='utf-8') as f_train:
print('{} ==> train '.format(files))
f_train.write(img_dir + 'train/' + files + ',' + mask_dir + 'train/' + files + '\n') # 写入数据
shutil.copyfile(osp.join(img_path, files), img_path + '\\train\\' + files) # 移动源文件
shutil.copyfile(osp.join(mask_path, files), mask_path + '\\train\\' + files) # 移动mask
count_train += 1
print("划分数据集结束: - 测试集:{}, 训练集:{}, 验证集:{}".format(count_test, count_train, count_val))
f_test.close()
f_val.close()
f_train.close()
最终数据集目录如下:
