字典树(Trie,前缀树)
目录
一,字典树
二,OJ实战
CSU 1115 最短的名字
HDU 1075 What Are You Talking About
力扣 1804. 实现 Trie (前缀树) II
一,字典树
字典树,又称前缀树。
前缀树的3个基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
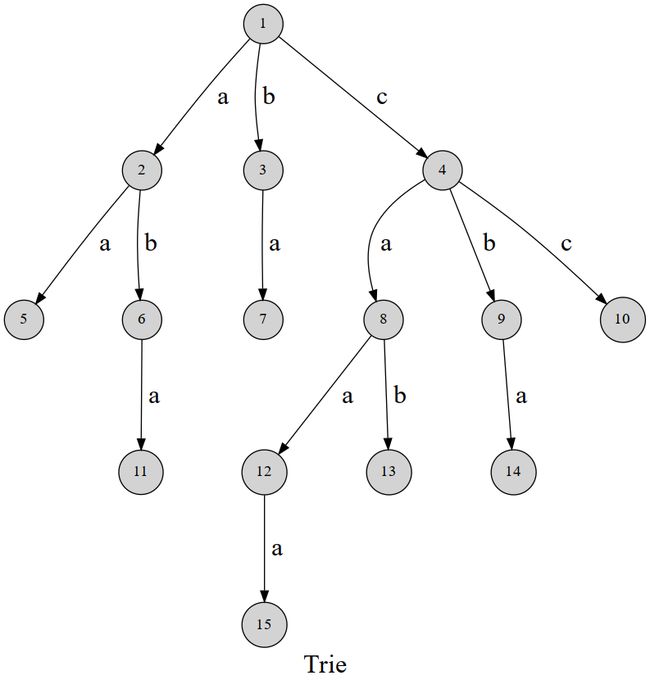
如图,没画出来的代表空指针。
节点11对应的字符串金山aba,节点15对应的字符串就是caaa
应用场景:存储大量字符串并频繁查找
二,OJ实战
CSU 1115 最短的名字
题目:
Description
在一个奇怪的村子中,很多人的名字都很长,比如aaaaa, bbb and abababab。
名字这么长,叫全名显然起来很不方便。所以村民之间一般只叫名字的前缀。比如叫'aaaaa'的时候可以只叫'aaa',因为没有第二个人名字的前三个字母是'aaa'。不过你不能叫'a',因为有两个人的名字都以'a'开头。村里的人都很聪明,他们总是用最短的称呼叫人。输入保证村里不会有一个人的名字是另外一个人名字的前缀(作为推论,任意两个人的名字都不会相同)。
如果村里的某个人要叫所有人的名字(包括他自己),他一共会说多少个字母?
Input
输入第一行为数据组数T (T<=10)。每组数据第一行为一个整数n(1<=n<=1000),即村里的人数。以下n行每行为一个人的名字(仅有小写字母组成)。输入保证一个村里所有人名字的长度之和不超过1,000,000。
Output
对于每组数据,输出所有人名字的字母总数。
Sample Input
1
3
aaaaa
bbb
abababab
Sample Output
5
思路:字典树
ans[i][j]表示第i个节点的第j个孩子的编号,j>0
ans[i][0]表示第i个节点的所有后代中叶子节点的个数
代码:
#include
#include
using namespace std;
const int m = 500000;
int ans[m][27], key = 0;
int f(int k)
{
if (ans[k][0] == 1)return 1;
int r = ans[k][0];
for (int i = 1; i <= 26; i++)
if (ans[k][i])r += f(ans[k][i]);
return r;
}
int main()
{
int T,n;
string s;
cin >> T;
while (T--)
{
cin >> n;
memset(ans[0], 0, sizeof(ans[0]));
while (n--)
{
cin >> s;
for (int i = 0,j=0; s[i]; i++)
{
if (ans[j][s[i] - 'a' + 1] == 0)
{
ans[j][s[i] - 'a' + 1] = ++key;
memset(ans[key], 0, sizeof(ans[key]));
}
ans[j][0]++;
j = ans[j][s[i] - 'a' + 1];
}
}
cout << f(0) - ans[0][0] << endl;
}
return 0;
} HDU 1075 What Are You Talking About
Ignatius is so lucky that he met a Martian yesterday. But he didn't know the language the Martians use. The Martian gives him a history book of Mars and a dictionary when it leaves. Now Ignatius want to translate the history book into English. Can you help him?
Input
The problem has only one test case, the test case consists of two parts, the dictionary part and the book part. The dictionary part starts with a single line contains a string "START", this string should be ignored, then some lines follow, each line contains two strings, the first one is a word in English, the second one is the corresponding word in Martian's language. A line with a single string "END" indicates the end of the directory part, and this string should be ignored. The book part starts with a single line contains a string "START", this string should be ignored, then an article written in Martian's language. You should translate the article into English with the dictionary. If you find the word in the dictionary you should translate it and write the new word into your translation, if you can't find the word in the dictionary you do not have to translate it, and just copy the old word to your translation. Space(' '), tab('\t'), enter('\n') and all the punctuation should not be translated. A line with a single string "END" indicates the end of the book part, and that's also the end of the input. All the words are in the lowercase, and each word will contain at most 10 characters, and each line will contain at most 3000 characters.
Output
In this problem, you have to output the translation of the history book.
Sample Input
START
from fiwo
hello difh
mars riwosf
earth fnnvk
like fiiwj
END
START
difh, i'm fiwo riwosf.
i fiiwj fnnvk!
ENDSample Output
hello, i'm from mars.
i like earth!AC代码一(Map实现):
#include
#include
#include AC代码二(字典树实现):
#include
#include
#include
using namespace std;
string a[1000000], b;
const int m = 5000000;
int ans[m][27], key = 0, ka = 0;
void insert(string s)
{
int i,j;
for (i = 0, j = 0; s[i]; i++)
{
if (ans[j][s[i] - 'a' + 1] == 0)
{
ans[j][s[i] - 'a' + 1] = ++key;
memset(ans[key], 0, sizeof(ans[key]));
}
j = ans[j][s[i] - 'a' + 1];
}
ans[j][0] = ka;
}
int find(string s)
{
int i, j;
for (i = 0, j = 0; s[i]; i++)
{
if (ans[j][s[i] - 'a' + 1] == 0)return 0;
j = ans[j][s[i] - 'a' + 1];
}
return ans[j][0];
}
int main()
{
char *ch = new char[3005], *p;
cin >> b;
memset(ans[0], 0, sizeof(ans[0]));
while (cin >> a[++ka] >> b)
{
if (a[ka][0] == 'E')break;
insert(b);
}
cin.get();
while (cin.getline(ch,3005))
{
p = ch;
if (ch[0] == 'E')break;
while (ch[0] != '\0')
{
b = "";
while (ch[0] >= 'a' && ch[0] <= 'z')b += ch[0], ch++;
if (find(b) ==0)cout << b;
else cout << a[find(b)];
while (ch[0] != '\0' && ch[0] < 'a' || ch[0] > 'z')
{
cout << ch[0];
ch++;
}
}
cout << endl;
ch = p;
}
return 0;
} PS:a数组不能开小了,10万是不够的,100万是够的。
力扣 1804. 实现 Trie (前缀树) II
前缀树(trie ,发音为 "try")是一个树状的数据结构,用于高效地存储和检索一系列字符串的前缀。前缀树有许多应用,如自动补全和拼写检查。
实现前缀树 Trie 类:
Trie() 初始化前缀树对象。
void insert(String word) 将字符串 word 插入前缀树中。
int countWordsEqualTo(String word) 返回前缀树中字符串 word 的实例个数。
int countWordsStartingWith(String prefix) 返回前缀树中以 prefix 为前缀的字符串个数。
void erase(String word) 从前缀树中移除字符串 word 。
示例 1:
输入
["Trie", "insert", "insert", "countWordsEqualTo", "countWordsStartingWith", "erase", "countWordsEqualTo", "countWordsStartingWith", "erase", "countWordsStartingWith"]
[[], ["apple"], ["apple"], ["apple"], ["app"], ["apple"], ["apple"], ["app"], ["apple"], ["app"]]
输出
[null, null, null, 2, 2, null, 1, 1, null, 0]
解释
Trie trie = new Trie();
trie.insert("apple"); // 插入 "apple"。
trie.insert("apple"); // 插入另一个 "apple"。
trie.countWordsEqualTo("apple"); // 有两个 "apple" 实例,所以返回 2。
trie.countWordsStartingWith("app"); // "app" 是 "apple" 的前缀,所以返回 2。
trie.erase("apple"); // 移除一个 "apple"。
trie.countWordsEqualTo("apple"); // 现在只有一个 "apple" 实例,所以返回 1。
trie.countWordsStartingWith("app"); // 返回 1
trie.erase("apple"); // 移除 "apple"。现在前缀树是空的。
trie.countWordsStartingWith("app"); // 返回 0
提示:
1 <= word.length, prefix.length <= 2000
word 和 prefix 只包含小写英文字母。
insert、 countWordsEqualTo、 countWordsStartingWith 和 erase 总共调用最多 3 * 104 次。
保证每次调用 erase 时,字符串 word 总是存在于前缀树中。
class Trie {
public:
Trie() {
memset(ans[key], 0, sizeof(ans[key]));
}
void insert(string s)
{
int i, j;
for (i = 0, j = 0; s[i]; i++)
{
if (ans[j][s[i] - 'a' + 1] == 0)
{
ans[j][s[i] - 'a' + 1] = ++key;
memset(ans[key], 0, sizeof(ans[key]));
}
j = ans[j][s[i] - 'a' + 1];
}
ans[j][0] = ka;
m[j]++;
}
int find(string s)
{
int i, j;
for (i = 0, j = 0; s[i]; i++)
{
if (ans[j][s[i] - 'a' + 1] == ka)return 0;
j = ans[j][s[i] - 'a' + 1];
}
return j;
}
int countWordsEqualTo(string s) {
return m[find(s)];
}
int dfs(int id)
{
int s = m[id];
for (int i = 1; i <= 26; i++)if (ans[id][i])s += dfs(ans[id][i]);
return s;
}
int countWordsStartingWith(string s) {
if (find(s) == 0)return 0;
return dfs(find(s));
}
void erase(string s) {
m[find(s)]--;
}
int ans[50000][27];
mapm;
int key = 0;
int ka = 0;
};