TFRecord简介,原理分析,代码实现?
TFRecord简介,原理分析,代码实现?
在利用深度学习算法搭建完成网络之后,我们要对网络进行训练,要训练网络就要有训练数据,通常我们会直接对硬盘上存放数据进行操作,来fetch到网络中。这样直接从硬盘上读取 数据太慢了,为了加快数据读取,今天我们介绍一种比较好的数据格式 tfrecord,那么什么是tfrecord呢?
什么TFRecord格式的数据?
Tensorflow支持的一种数据格式,内部使用了“Protocol Buffer”二进制数据编码方案,方便我们模型训练,验证,测试数据集的输入。
为什么提出TFRecord格式的数据?
通常情况下,我们使用Tensorflow搭建好网络模型之后,要输入数据进行训练,验证,测试,其对应的文件夹经常为 train,val, test文件夹,这些文件夹内部往往会存着上百万的数据文件,这些文件散列存放在磁盘上,并且读取时候非常慢,繁琐,会有大量的I/O操作。同时,占用大量内存空间)。而TFRecord格式的文件存储形式会很合理的帮我们存储数据,其内部使用了“Protocol Buffer”二进制数据编码方案,它只占用一个内存块,只需要一次性加载一个二进制文件的方式即可,简单,快速,尤其对大型训练数据很友好。而且当我们的训练数据量比较大的时候,可以将数据分成多个TFRecord文件,来提高处理效率。
Tensorflow读取数据的机制大致可以分为三种:
- 直接从硬盘上读取文件数[如下图,来自慕课学习]

上述方式:tensorflow进行模型训练的时候,可以直接从硬盘上去读取数据,并将读出的数据喂给网络,从而完成运算。若数据读取和运算是不同步的【串行的】,那么意味着在完成了运算之后,需要进行IO来对硬盘上的数据进行读取,并将数据放入内存中,此时接着完成后续的运算,由于这个过程中存在IO操作,造成大部分资源处于等待中,造成大量浪费,训练时间比较长。
- 在内存中开辟读写队列,来读取数据[如下图,来自慕课学习]
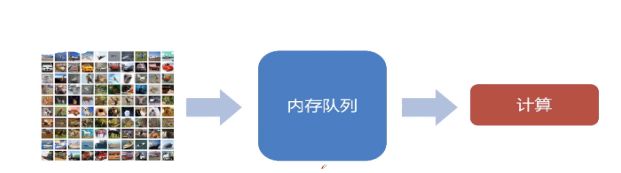
上述方式:若先在内存对数据进行缓存,相当于很大的buffer,对于硬盘上的数据,采用读取数据的线程,将硬盘的数据不断的向内存中开辟的buffer中进行搬运,对于计算设备,采用另一个数据读取的线程,每次计算时候,直接从内存中的buffer中读取数据。以此达到同步进行的目的,彼此之间不会发生阻塞,提高了对资源的利用率,也一定程度上加快了 网络的训练。
- 基于文件队列+内存队列结合的形式读取数据[如下图,来自慕课学习]

上述方式:对于硬盘上存放的数据,首先将硬盘上的数据文件名存放在文件名队列中,内存队列从文件名队列中进行数据的读取,计算设备之间从内存中读取运算所需数据。通过文件队列可以完成对epoch更好的管理,若训练要经过3个epoch,则在文件名队列中会形成A,B,C三个epoch,其中A,B,C分别包含了所有的文件列表,将A,B,C进行合并,最终形成文件名队列,之后内存队列从文件名队列中依次读取。
在Tensorflow中用来构建文件队列的函数主要有如下
- tf.train.slice_input_producer
import tensorflow as tf
# 数据文件的路径
image_files = ["a.jpg","b.jpg","c.jpg","d.jpg"]
image_size = len(image_files)
# 数据文件对应的label
image_labels = [1,2,3,4]
# 数据读取的轮数
epochs = 2
#使用tf.train.slice_input_producer()来构建文件队列,可以很好的num_epoch管理
[image_files,image_labels] = tf.train.slice_input_producer([image_files,image_labels],num_epochs=epochs,shuffle=True)
# 使用tf.Session() 完成后段数据读取
with tf.Session() as sess:
sess.run(tf.local_variables_initializer())
# 启动入队线程,由多个或单个线程,按照设定规则,把文件读入Filename Queue中
tf.train.start_queue_runners(sess=sess)
for i in range(epochs*image_size):
print(sess.run([image_files,image_labels]))上述代码执行结果 :

- tf.train.string_input_producer
import tensorflow as tf
# 数据文件的路径
image_files = ["cat.0.jpg","cat.1.jpg","cat.2.jpg"]
image_size = len(image_files)
# 数据读取的轮数
epochs = 2
#使用tf.train.string_input_producer()来构建文件队列,可以很好的num_epoch管理
file_queue = tf.train.string_input_producer(image_files,num_epochs=epochs,shuffle=True)
# 使用reader读取队列文件中数据
reader = tf.WholeFileReader()
# 返回文件名和对应数据
key,value = reader.read(file_queue)
# 对读出tfrecord序列化数据进行解码
value = tf.decode_raw(value,tf.uint8)
# 使用tf.Session() 完成后段数据读取
with tf.Session() as sess:
sess.run(tf.local_variables_initializer())
# 启动入队线程,由多个或单个线程,按照设定规则,把文件读入Filename Queue中
tf.train.start_queue_runners(sess=sess)
for i in range(epochs*image_size):
print(sess.run([key,value]))上述代码执行结果 :

- tf.data库
上述函数用来完成对文件队列的构造,通过sess.run来完成后端数据读取。而tf.data不使用sess.run,而是基于使用动态图的机制来完成数据的读取。对于slice_input_producer可以通过sess.run直接获取文件队列中的数据。而string_input_producer不可以,需要创建一个文件读写器来进行读取。利用读取器返回文件的名和里面的内容,之后通过sess.run()来进行文件内容的读取。具体操作后续补存。
如何生成TFRecord格式的数据?
首先数据文件目录如下图:dog和cat文件夹中分别存储对应的狗和猫:
------data
----------train
---------------dog
---------------cat
----------validation
---------------dog
---------------cat
上图为我们此次处理数据目录data为根目录,其下有两个文件夹train和validation,在train和validation下分别有dog和cat两个文件夹,其中存放对应图片数据。具体TFRecord格式数据转换如下代码:
# -*- coding:utf-8 -*-
import os
import numpy as np
import tensorflow as tf
from tensorflow.python.platform import gfile
# 定义函数转化变量类型
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
# 将数据转化为tf.train.Example格式
def _make_example(label, image):
image_raw = image.tostring()
example = tf.train.Example(features=tf.train.Features(feature={
'image/class/label': _int64_feature(label),
'image/encoded': _bytes_feature(image_raw}))
return example
# 读取图片
def read_images(sess,path,flag):
# 获取path下所有目录,同时包括path目录
sub_dirs = [x[0] for x in os.walk(path)]
# 去除path目录
is_root_dir = True
设置当前label标记为:0
current_label = 0
print("开始处理训练数据")
#开始生成TFRecord格式数据
with tf.python_io.TFRecordWriter("./data/dogsVScats_%s_.tfrecord" % flag) as writer:
# 读取所有的子目录
for sub_dir in sub_dirs:
if is_root_dir:
is_root_dir = False
continue
# 定义图像类型
extensions = ['jpg','png']
# 存放图像数据
file_list = []
# 获取文件的名字
dir_name = os.path.basename(sub_dir)
for extension in extensions:
# 文件匹配,类似正则表达式
file_glob = os.path.join(path, dir_name, '*.' + extension)
#将匹配数据加入列表
file_list.extend(glob.glob(file_glob))
if not file_list:
continue
print("processing:", dir_name)
i = 0
# 处理图片数据
for file_name in file_list:
i += 1
//读取图像,不过得到的结果是最原始的图像,是没有经过解码的图像,即为是一个字
//符串,没法显示,为byte类型
image_raw_data = gfile.FastGFile(file_name, 'rb').read()
//对上面函数读出的图像进行解码,得到图像的像素值,这个像素值可以用于显示图像
image = tf.image.decode_jpeg(image_raw_data)
if image.dtype != tf.float32:
//将image转换为dtype,并根据需要缩放其值.
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
//在进行tfrecord格式转之前要对所有图像的宽高变的一致
image = tf.image.resize(image, [299, 299])
image_value = sess.run(image)
example = _make_example(current_label, image_value)
writer.write(example.SerializeToString())
print("正在处理{}中的第{}张图片".format(dir_name,i))
current_label += 1
print("TFRecord %s 文件已保存" % flag)
# 执行产生tfrecord文件
with tf.Session() as sess:
read_images(sess,"./data/train","train")
read_images(sess,"./data/validation","validation")
将您的数据文件按照上面目录存放,之后会生成dogsVScats_train_.tfrecord和dogsVScats_validation_.tfrecord两个TFRecord格式的数据。
如何读取生成的TFRecord格式的数据进行训练?
# -*- coding:utf-8 -*-
import numpy as np
import tensorflow as tf
BATCH_SIZE = 32
#tfrecord文件路径
train_tf_path = "./data/dogsVScats_train_.tfrecord"
# 使用文件队列来填充数据
filename_queue =
tf.train.string_input_producer([train_tf_path],shuffle=True,num_epochs=None,seed=666)
# 创建TFRecoder读写器进行读写打包文件中数据serialized_example,该数据为序列化数据
reader = tf.TFRecordReader()
# 返回文件名和序列数据
_,serialized_example = reader.read(filename_queue)
feature = {
'image/encoded':tf.FixedLenFeature([],tf.string),
'image/class/label':tf.FixedLenFeature([],tf.int64)}
#将Example原型解析为张量的dict。
features = tf.parse_single_example(serialized_example,features=feature)
image = tf.decode_raw(features['image/encoded'],tf.uint8)
single_image = tf.reshape(image,[229,229,3])
single_label = features['image/class/label']
# 按顺序文件读取队列中的数据
img_batch,img_labels = tf.train.shuffle_batch([single_image, single_label],batch_size=BATCH_SIZE,capacity=BATCH_SIZE*10,min_after_dequeue=BATCH_SIZE*5)
with tf.Session() as sess:
sess.run(tf.local_variables_initializer())
tf.global_variables_initializer().run()
# 启动多线程处理输入数据
coord = tf.train.Coordinator()
# 启动入队线程,由多个或单个线程,按照设定规则,把文件读入文件队列中。
threads = tf.train.start_queue_runners(sess=sess,coord=coord)
//读取10个batch_size的数据
for i in range(10):
batch_data,batch_labels = sess.run([img_batch,img_labels])
print(batch_data.shape)
print(batch_labels.shape)上面是使用TFRecord格式数据生成,读取的方式。
另外补存图像解码代码实现,如下代码段
#-*-coding:utf-8-*-
import matplotlib.pyplot as plt
import tensorflow as tf
#tf.gfile.FastGFile读出文件数据为序列化数据
image_raw_data_jpg = tf.gfile.FastGFile('1.jpg', 'r').read()
image_raw_data_png = tf.gfile.FastGFile('2.png', 'r').read()
with tf.Session() as sess:
# 对序列化图像数据进行解码
img_data_jpg = tf.image.decode_jpeg(image_raw_data_jpg)
img_data_jpg = tf.image.convert_image_dtype(img_data_jpg, dtype=tf.uint8) # 改变图像数据的类型
img_data_png = tf.image.decode_png(image_raw_data_png)
img_data_png = tf.image.convert_image_dtype(img_data_png, dtype=tf.uint8)
plt.figure(1) # 图像显示
plt.imshow(img_data_jpg.eval())
plt.figure(2)
plt.imshow(img_data_png.eval())
plt.show()