LS-CNN: Characterizing Local Patches at Multiple Scales for Face Recognition--Qiangchang Wang
- 0、摘要
- 1、引入
-
- 1.1 学习多尺度信息
- 1.2 空间注意力
- 1.3 通道注意力
- 1.4 小结
- 2、结构详解
-
- 2.1 Inception Module
- 2.2 DenseNet Module
- 2.3 LANet Module
- 2.4 Local and multi-scale convolutional neural networks(LS-CNN,整体结构)
- 3、实验
-
- 3.1 消融实验
- 3.2 不同注意力
- 3.3 不同姿态人脸识别的实验
0、摘要
本文要解决的问题:人脸识别因各种光照姿态等造成类间距大,但是很少有工作学习局部和多尺度的表征。
为什么要考虑多尺度:因为一些有区分性的特征可能存在不同的尺度中
如何解决:在单层利用不同卷积核提取特征(Inception-like),聚合不同层的特征(Dencse-like)。
为什么要考虑局部patch:因为在全局或者显著特征丢失后,一些局部patch仍然可以帮助我们进行识别或分类。
如何解决:换句话说不同区域有不同重要性,所以设计了一个空间注意力模块。
为什么要加入通道注意力:使用多尺度的一个问题是,来自不同卷积核运算后或者不同层的特征聚合时,他们应该包含不同的信息重要性应该是不同的,所以不能够直接聚合。(低层通道描述局部细节或小尺度部分,高层通道表征高级抽象或者大尺度部分,通过通道注意力来决定是局部细节更重要还是抽象特征更重要)
解决办法:设计通道注意力模块
1、引入
1.1 学习多尺度信息
具有判别性的人脸区域可能出现在不同的尺度特征中。比如图1中,第一行和第二行是同一个人的不同照片,人脸识别时有些人的显著特征是嘴巴,有的人是眼睛,甚至有的只是小小的单个眼睛。那么问题来了,这些不同尺寸的特征,比如较大区域的特征在高层仍可能出现,而较小区域的特征可能只在低层出现,如果要同时考虑到这些不同尺寸的特征,就必须要引入多尺度将他们聚合起来。

其他工作在考虑多尺度一般只聚合最后两个层,但是本文通过两个方面的“多尺度”来进行大跨越的聚合。
1)Inception式的聚合。我们都比较了解了,在同一层使用不同尺寸的卷积核进行特征提取。
2)DenseNet式的聚合。我们知道DenseNet就是复用前面几层的特征,同时DenseNet的残差连接保证了梯度流,使得具有ResNet的优点。
负责这块的模块名为Harmonious multi-Scale Networks(HSNet),意为“和谐的多尺度网络”。
1.2 空间注意力
空间注意力有两层原因:
1)一些背景是无用的。比如人脸识别中背景、头发等像素是没有价值的,所以使用空间注意力抑制这些像素。
2)对于人脸区域也是分重要和不那么重要的,所以用空间注意力突出有判别性的local patch。
所以如图2,背景基本被过滤,而脸部也聚焦于有判别性的区域。

在本文的空间注意力模块被命名为local aggregation network(LANet),意为“局部聚合网络”。
1.3 通道注意力
在1.1节中的多尺度聚合中,来自同一层不同卷积核尺寸的特征通道、不同层的特征是有主次之分的,因为某些层希望能够聚合特征,但是更希望高级抽象特征更重要,所以需要通道注意力来重新分配这些通道的重要。

比如图3,对于该图像眼睛是重要的特征,那么希望在特征聚合时,饱含眼睛特征的通道能够被增强。
本文是使用SENet作为通道注意力模块。
1.4 小结
综上,
| 模块名 | 用处 | 备注 |
|---|---|---|
| HSNet | 多尺度特征聚合 | 结合Inception+DenseNet |
| DFA | 通道和空间注意力 | 通道注意力SENet+空间注意力LANet |
| LS-CNN | 结合HSNet+DFA | 即Local and multi-Scale Convolutional Neural Networks |
有模块化那味了,层层打包取名…
2、结构详解
2.1 Inception Module
Inception 模块都很经典了,在本文中作者设计了两种Inception,一种用于特征提取的LS-CNN-D:输入输出的特征尺寸不变;另一种是用于转换LS-CNN-T:输出的特征尺寸减半,充当pooling层的功能。
- LS-CNN-D
如果了解DenseNet的应该知道,在DenseNet Block中的层用于特征提取,在Block之间的就是用于转换的层。那么LS-CNN-D就是用于Block内部的特征提取,而LS-CNN-T就是用于Block之间的转换层。
如图4所示,LS-CNN-D就是LANet(空间注意力)+SENet(通道注意力)+Inception构成。
需要注意的是:
1)DFA注意力模块没有改变特征尺寸
2)Inception多分支第一个1x1卷积用于降低计算量(相比于用3x3卷积来将特征数从mxk升到4k)。
3)使用两个3x3卷积代替5x5卷积,扩大感受野。

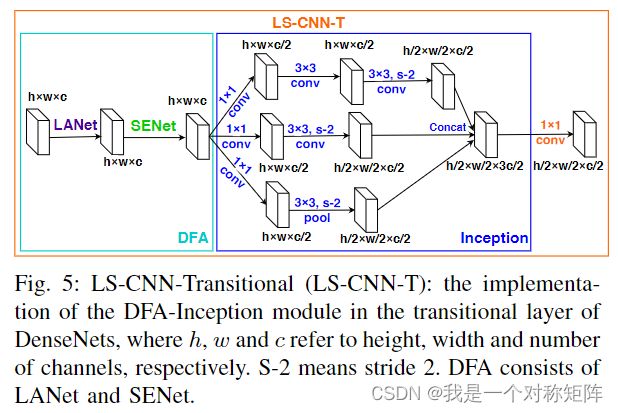
- LS-CNN-T
在转换层也使用Inception结构,如图5所示。
需要注意的是:
1)在结构上和LS-CNN-D相似,但1x1分支换成maxpool
2)但空间上使用stride=2来缩减,通道上也减半
3)尺寸变化 h ∗ w ∗ c − > h 2 ∗ w 2 ∗ c 2 h*w*c->\frac{h}{2}*\frac{w}{2}*\frac{c}{2} h∗w∗c−>2h∗2w∗2c
2.2 DenseNet Module
为了提高信息和梯度流,dense connections被使用。
关于DenseNet可以看DenseNet论文和本文原文,都是在介绍DenseNet结构。
2.3 LANet Module
了解注意力的人很容易理解,非常简单。不同的是这里有个r即通道压缩率(不知道是不是从SENet学习过来的)
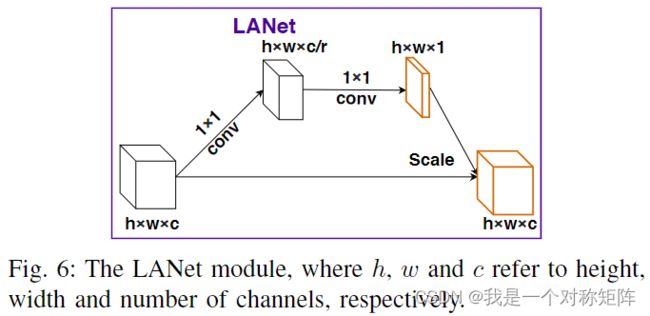
具体结构是:conv+relu+conv+sigmoid
通道注意力是SENet:

2.4 Local and multi-scale convolutional neural networks(LS-CNN,整体结构)
介绍了LS-CNN的基本组件:LANet、SENet、LS-CNN-D、LS-CNN-T后,来看看他们是怎么组合成整体结构的

1)全面的conv、pooling相当于stem layer,初步提取特征
2)一个Dense Block中多个LS-CNN-D通过dense connection方式连接,用于特征提取
3)LS-CNN-T用于尺寸缩减,相当于pooling减小特征尺寸
4)LANet和SENet如图4、5被嵌入到LS-CNN-D和LS-CNN-T中了。
具体配置见表1。

3、实验
3.1 消融实验
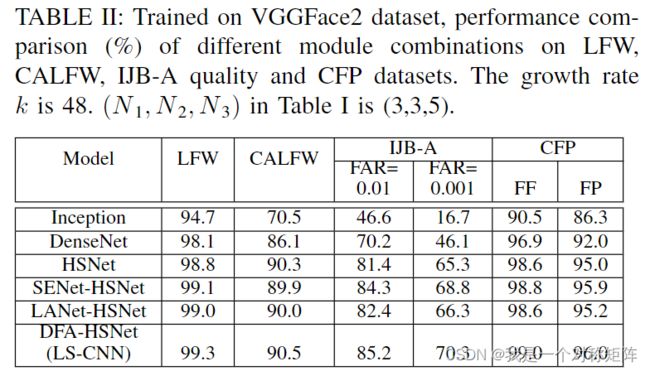
1)Inception与DenseNet相比效果很差。因为Inception虽然有多尺度能力,但是层和通道还是比较少,表征能力不强。但是DenseNet通过多尺度和特征复用,有很强的表征能力。
2)HSNet是Inception和DenseNet的结合,效果更强。一方面,Inception模块在单个层中学习具有不同大小卷积核的特征。另一方面,Dense Connection使DenseNet模块能够组合来自多个层的特征。可以理解为DenseNet只能复用每层固定卷积核尺寸的特征,而HSNet使得DenseNet复用每层不同卷积核尺寸的特征,是对DenseNet特征复用的加强核优化
3)对于注意力,可以通过可视化效果研究有效性。如图9和图10是SENet+HSNet和LS-CNN(LANet+SENet+HSNet)的比较,可以看出加了LANet(列3和6)能有效强化一些局部特征,强化了表征能力。


3.2 不同注意力
DFA是包含LANet+SENet的,这里我们将DFA替换为如下几个注意力,探究其效果。
SENet:通道注意力。在这里将SENet代替DFA,也就是只有通道注意力
CBAM:穿行考虑通道注意力和空间注意力
BAM:并行考虑通道注意力和空间注意力,在空间注意力部分使用空洞卷积扩大感受野

1)SENet只考虑通道注意力,所以与考虑空间和通道的DFA比在所有数据集上都要差一些
2)CBAM也比DFA差,都是考虑了空间和通道注意力为啥CBAM更差呢?考虑到CBAM中使用了maxpooling和avgpooling,于是作者将DFA中的avgpooling改为了maxpooling和avgpooling称为DFA(Max&Avg pool)(其实也就DFA中的SENet的avgpooling),然后发现效果差了,所以maxpooling(在本文任务中)是不合适的。其实考虑到数据集中的背景,maxpooling可能保留了背景等噪音,而使用avgpooling还能通道保留信息和噪声。反过来讲如果没有背景的任务,是否avgpooling+maxpooling就能更好呢?
3)对于BAM更差的原因,作者将DAF中的LANet空间注意力改为空洞卷积操作,即DFA(Dilated conv),发现与DFA比效果差了,一种解释是在后期通过多层叠加其实感受野已经很大了,此时每一个像素值都有丰富的信息,而空洞卷积忽略某些像素造成轻微退化。(如果是这样,那么使用更大的普通卷积的DFA既能捕获每个像素,也能扩大感受野,是不是就表现更高呢?)
3.3 不同姿态人脸识别的实验
在这部分使用CFP人脸数据集,这是一个拥有多姿态人脸识别的数据集。
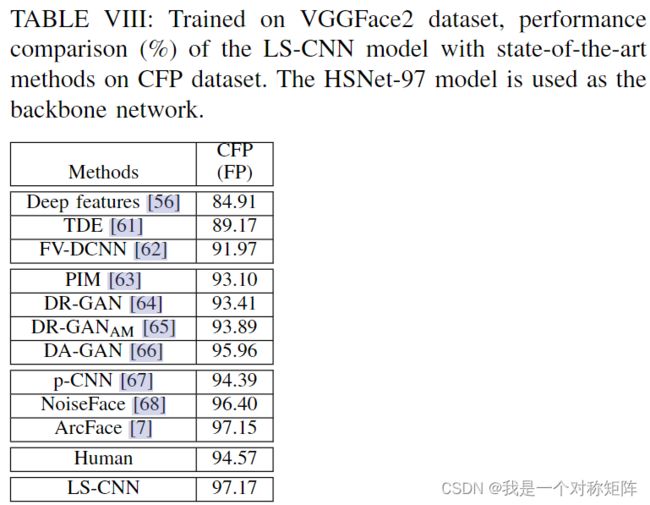

我们注意到,由于轮廓人脸旋转造成的遮挡,有区别性的local patch比正脸的可用区域要小。而HSNet(Inception和Densenet构建的多尺度模块)可以捕获丰富的多尺度信息。
然而,随着网络的深入,较低通道中的局部面部区域可能无法传播到更深的层(比如太小的区域)。为了缓解这一问题,在HSNet多尺度特征融合部分加了SENet强调较低层的重要通道,如图9所示。
此外,还引入了LANET模块,以减轻背景不一致的影响(同一个人的脸,但是背景不同可能会影响)。如图9所示,与SENet-HSNet模型相比,LS-CNN模型生成的类激活映射(CAM)倾向于在正面定位更具区别性的部分(第3至2栏),并抑制侧面信息较少的区域(第6至5栏)。最后,与需要复杂数据增强(DR-GAN,DR-GANAM,PIM,DA-GAN)或多任务训练(p-CNN)或噪声容忍范例(NoiseFace)或更高级损失函数(ArcFace)的最新技术相比,我们的方法简单有效。