【论文解读】AAAI21最佳论文Informer:效果远超Transformer的长序列预测神器!
炼丹笔记干货
作者:一元,四品炼丹师
Informer:最强最快的序列预测神器
01
简介
在很多实际应用问题中,我们需要对长序列时间序列进行预测,例如用电使用规划。长序列时间序列预测(LSTF)要求模型具有很高的预测能力,即能够有效地捕捉输出和输入之间精确的长程相关性耦合。最近的研究表明,Transformer具有提高预测能力的潜力。
然而,Transformer存在一些严重的问题,如:
二次时间复杂度、高内存使用率以及encoder-decoder体系结构的固有限制。
为了解决这些问题,我们设计了一个有效的基于变换器的LSTF模型Informer,它具有三个显著的特点:
ProbSparse Self-Attention,在时间复杂度和内存使用率上达到了 ,在序列的依赖对齐上具有相当的性能。
self-attention 提取通过将级联层输入减半来突出控制注意,并有效地处理超长的输入序列。
产生式decoder虽然概念上简单,但在一个正向操作中预测长时间序列,而不是一步一步地进行,这大大提高了长序列预测的推理速度。
在四个大规模数据集上的大量实验表明,Informer的性能明显优于现有的方法,为LSTF问题提供了一种新的解决方案。
02
背景
Intuition:Transformer是否可以提高计算、内存和架构效率,以及保持更高的预测能力?


原始Transformer的问题
self-attention的二次计算复杂度,self-attention机制的操作,会导致我们模型的时间复杂度为 ;
长输入的stacking层的内存瓶颈:J个encoder/decoder的stack会导致内存的使用为 ;
预测长输出的速度骤降:动态的decoding会导致step-by-step的inference非常慢。
本文的重大贡献
本文提出的方案同时解决了上面的三个问题,我们研究了在self-attention机制中的稀疏性问题,本文的贡献有如下几点:
我们提出Informer来成功地提高LSTF问题的预测能力,这验证了类Transformer模型的潜在价值,以捕捉长序列时间序列输出和输入之间的单个的长期依赖性;
我们提出了ProbSparse self-attention机制来高效的替换常规的self-attention并且获得了 的时间复杂度以及 的内存使用率;
我们提出了self-attention distilling操作全县,它大幅降低了所需的总空间复杂度 ;
我们提出了生成式的Decoder来获取长序列的输出,这只需要一步,避免了在inference阶段的累计误差传播;
问题定义
在固定size的窗口下的rolling预测中,我们在时刻 的输入为,我们需要预测对应的输出序列,LSTF问题鼓励输出一个更长的输出,特征维度不再依赖于univariate例子( ).
Encoder-decoder框架:许多流行的模型被设计对输入表示 进行编码,将 编码为一个隐藏状态表示 并且将输出的表示 解码.在推理的过程中设计到step-by-step的过程(dynamic decoding),decoder从前一个状态 计算一个新的隐藏状态 以及第 步的输出,然后对 个序列进行预测 ;
输入表示:为了增强时间序列输入的全局位置上下文和局部时间上下文,给出了统一的输入表示。
03
方法
现有时序方案预测可以被大致分为两类:
高效的Self-Attention机制
传统的self-attention主要由(query,key,value)组成,,其中;第 个attention被定义为核平滑的概率形式:
self-attention需要 的内存以及二次的点积计算代价,这是预测能力的主要缺点。
我们首先对典型自我注意的学习注意模式进行定性评估。“稀疏性” self-attention得分形成长尾分布,即少数点积对主要注意有贡献,其他点积对可以忽略。那么,下一个问题是如何区分它们?
Query Sparsity评估
我们定义第 个query sparsity第评估为:
第一项是 在所有keys的Log-Sum-Exp(LSE),第二项是arithmetic均值。
ProbSparse Self-attention
其中 是和q相同size的稀疏矩阵,它仅包含稀疏评估下 下Top-u的queries,由采样factor 所控制,我们令 , 这么做self-attention对于每个query-key lookup就只需要计算 的内积,内存的使用包含 ,但是我们计算 的时候需要计算没对的dot-product,即, ,同时LSE还会带来潜在的数值问题,受此影响,本文提出了query sparsity 评估的近似,即:
这么做可以将时间和空间复杂度控制到
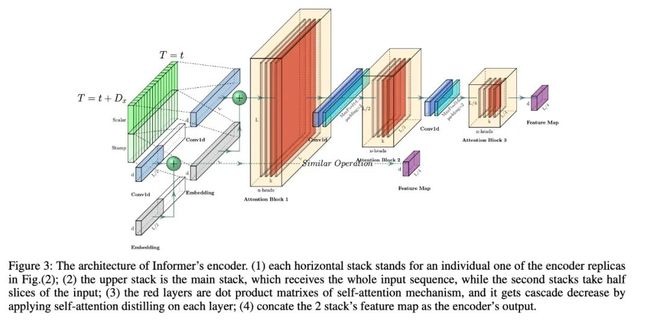
04
方法Encoder + Decoder
1. Encoder: Allowing for processing longer sequential inputs under the memory usage limitation
encoder被设计用来抽取鲁棒的长序列输入的long-range依赖,在第 个序列输入 被转为矩阵
Self-attention Distilling
作为ProbSparse Self-attention的自然结果,encoder的特征映射会带来 值的冗余组合,利用distilling对具有支配特征的优势特征进行特权化,并在下一层生成focus self-attention特征映射。
它对输入的时间维度进行了锐利的修剪,如上图所示,n个头部权重矩阵(重叠的红色方块)。受扩展卷积的启发,我们的“distilling”过程从第j层往 推进:
其中 包含Multi-Head ProbSparse self-attention以及重要的attention block的操作。
为了增强distilling操作的鲁棒性,我们构建了halving replicas,并通过一次删除一层(如上图)来逐步减少自关注提取层的数量,从而使它们的输出维度对齐。因此,我们将所有堆栈的输出串联起来,并得到encoder的最终隐藏表示。
2. Decoder: Generating long sequential outputs through one forward procedure
此处使用标准的decoder结构,由2个一样的multihead attention层,但是,生成的inference被用来缓解速度瓶颈,我们使用下面的向量喂入decoder:
其中,是start tocken, ~~是一个placeholder,将Masked multi-head attention应用于ProbSparse self-attention,将mask的点积设置为 。它可以防止每个位置都关注未来的位置,从而避免了自回归。一个完全连接的层获得最终的输出,它的超大小取决于我们是在执行单变量预测还是在执行多变量预测。
Generative Inference
我们从长序列中采样一个 ,这是在输出序列之前的slice。
以图中预测168个点为例(7天温度预测),我们将目标序列已知的前5天的值作为“start token”,并将 , 输入生成式推理解码器。
包含目标序列的时间戳,即目标周的上下文。注意,我们提出的decoder通过一个前向过程预测所有输出,并且不存在耗时的“dynamic decoding”。
Loss Function
此处选用MSE 损失函数作为最终的Loss。
05
实验
1. 实验效果
从上表中,我们发现:
所提出的模型Informer极大地提高了所有数据集的推理效果(最后一列的获胜计数),并且在不断增长的预测范围内,它们的预测误差平稳而缓慢地上升。
query sparsity假设在很多数据集上是成立的;
Informer在很多数据集上远好于LSTM和ERNN
2. 参数敏感性
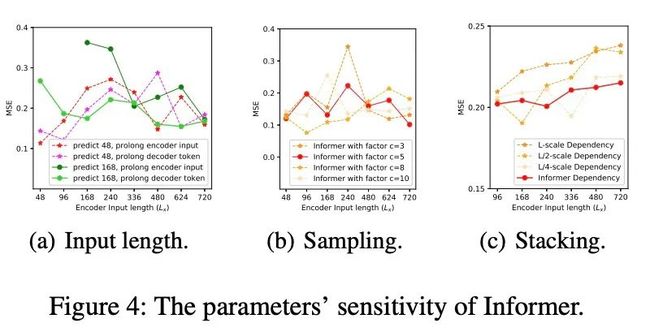
从上图中,我们发现:
Input Length:当预测短序列(如48)时,最初增加编码器/解码器的输入长度会降低性能,但进一步增加会导致MSE下降,因为它会带来重复的短期模式。然而,在预测中,输入时间越长,平均误差越低:信息者的参数敏感性。长序列(如168)。因为较长的编码器输入可能包含更多的依赖项;
Sampling Factor:我们验证了冗余点积的查询稀疏性假设;实践中,我们把sample factor设置为5即可,即 ;
Number of Layer Stacking:Longer stack对输入更敏感,部分原因是接收到的长期信息较多
3. 解耦实验
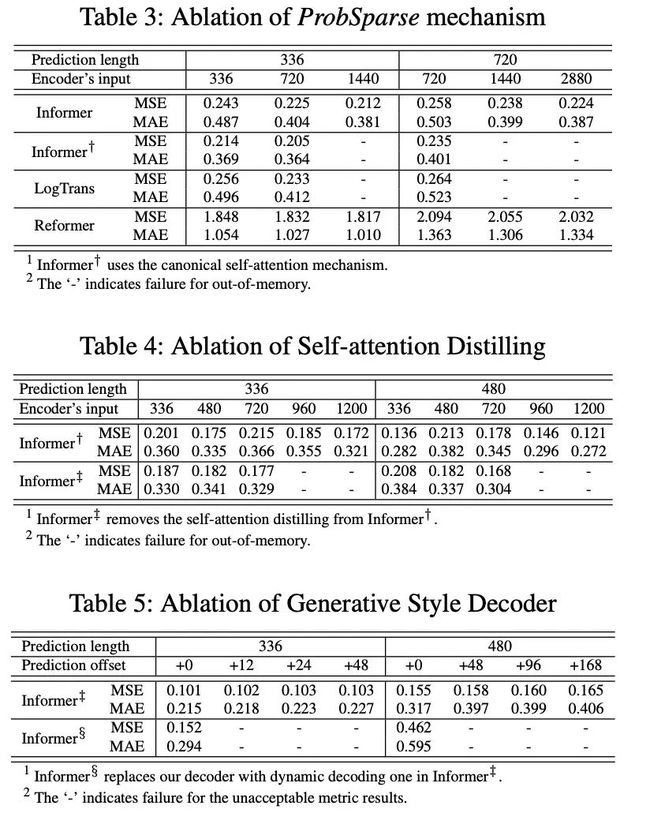
从上表中我们发现,
ProbSparse self-attention机制的效果:ProbSparse self-attention的效果更好,而且可以节省很多内存消耗;
self-attention distilling:是值得使用的,尤其是对长序列进行预测的时候;
generative stype decoderL:它证明了decoder能够捕获任意输出之间的长依赖关系,避免了误差的积累;
4. 计算高效性
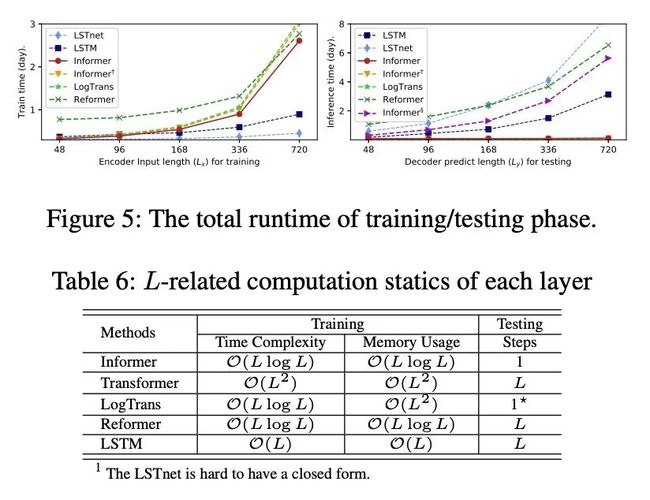
在训练阶段,在基于Transformer的方法中,Informer获得了最佳的训练效率。
在测试阶段,我们的方法比其他生成式decoder方法要快得多。
06
小结
本文研究了长序列时间序列预测问题,提出了长序列预测的Informer方法。具体地:
设计了ProbSparse self-attention和提取操作来处理vanilla Transformer中二次时间复杂度和二次内存使用的挑战。
generative decoder缓解了传统编解码结构的局限性。
通过对真实数据的实验,验证了Informer对提高预测能力的有效性
参考文献

Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting:https://arxiv.org/pdf/2012.07436.pdf

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑
本站qq群704220115,加入微信群请扫码: