Learning with Noisy Correspondencefor Cross-modal Matching(NCR)--文献翻译

NeurIPS 2021
摘要
跨模态匹配旨在建立两种不同模态之间的对应关系,是跨模态检索和视觉和语言理解等各种任务的基础。尽管近年来已经提出了大量的跨模态匹配方法并取得了显着进展,但几乎所有这些方法都隐含地假设多模态训练数据是正确对齐的。然而,在实践中,这样的假设是极其昂贵的,甚至不可能满足。基于这一观察,我们揭示并研究了跨模态匹配中一个潜在且具有挑战性的方向,称为噪声对应,它可以被视为噪声标签的新范式。与传统的噪声标签主要指类别标签中的错误不同,我们的噪声对应指的是不匹配的配对样本。为了解决这个新问题,我们提出了一种新的噪声通信学习方法,称为噪声通信整流器(NCR)。简而言之,NCR 根据神经网络的记忆效应将数据划分为干净和嘈杂的分区,然后通过自适应预测模型以协同教学的方式纠正对应关系。为了验证我们方法的有效性,我们通过使用图像文本匹配作为展示进行实验。在 Flickr30K、MS-COCO 和概念字幕上进行的大量实验验证了我们方法的有效性。
1 介绍
作为多模态学习中最基本的技术之一,跨模态匹配旨在连接不同的模态。近年来,一些基于深度神经网络(DNNs)的跨模态匹配方法[19,11,7,25]被提出,在各种应用,例如聚类 [28]、图像/视频字幕 [1、43、22]、跨模态检索 [39、19、13] 和视觉问答 [9]。
通常,大多数现有的跨模态匹配方法将不同的模态嵌入到一个公共空间中,其中正的跨模态对的相似性最大化,而负的跨模态对的相似性最小化。尽管这些方法取得了可喜的成果,但它们的成功取决于隐含的数据假设,即训练数据在不同模式之间正确对齐。例如,在视觉和语言任务中,文本需要准确地描述图像内容,反之亦然。然而,在实践中,注释或收集此类数据对非常昂贵且耗时。特别是考虑到从互联网上收集的数据[34, 14],不可避免地会收集到一些不匹配的对,这些对被错误地视为匹配的对。据我们所知,到目前为止,这种特殊的噪声标签(对应)问题已被忽略,这将显着降低匹配方法的性能,如我们的实验所示。
作者认为的区别:传统的判断单个样本类别标注错误,本文所提出的是关联错误。任务信任的退化包括跨膜态匹配。
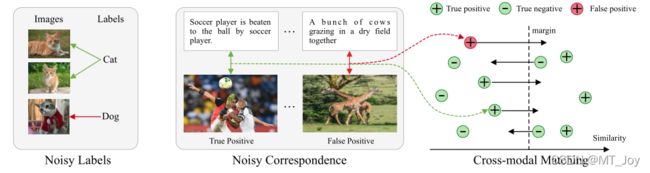
图 1:嘈杂的标签与嘈杂的通信。我们用红线表示嘈杂的样本,用绿线表示干净的样本。传统的噪声标签主要是指类别标签中的错误,而噪声对应是指配对数据中的对齐错误。对于跨模态匹配中的噪声对应,真阳性对正确引导跨模态匹配,而假阳性对导致训练监督不正确。
基于上述观察,我们揭示了噪声标签的新范式,称为噪声对应。与传统的噪声标签不同,噪声对应是指配对数据中的对齐错误,而不是类别注释中的错误(见图1)。据我们所知,没有人致力于研究这个新问题,最接近的范式可能是部分视图对齐问题 (PVP) [12, 40]。但是,PVP 与嘈杂的通信有很大的不同,后者比前者更实用。具体来说,PVP 侧重于跨模态对齐完全不可用,而噪声对应侧重于某些对应不正确。此外,PVP 假设一些正确对齐的数据可用于训练,而我们的噪声对应假设干净和噪声数据是混合的。
为了解决跨模态匹配中的噪声对应问题,我们提出了一种新方法,称为噪声对应整流(NCR)。我们的方法基于在 [3, 38] 中观察到的 DNN 的记忆效果,即 DNN 在拟合噪声样本之前倾向于学习简单的模式。受此经验观察的启发,NCR 根据其损失差异将数据分为两个相对准确的数据分区,即“嘈杂”和“干净”子集。之后,NCR 采用自适应预测功能进行标签校正,以便可以分别从“干净”和“嘈杂”子集中识别误报和真阳性。此外,我们通过将校正后的标签重铸为软边距,提出了一种新的三元组损失,用于稳健的跨模态匹配。
为了解决跨模态匹配中的噪声对应问题,我们提出一种新方法,称为噪声对应整流器(NCR)。我们的方法基于在中观察到的 DNN 的记忆效果,即 DNN 在拟合噪声样本之前倾向于学习简单的模式。受此经验观察的启发,NCR 根据其损失差异将数据分为两个相对准确的数据分区,即“嘈杂”和“干净”子集。之后,NCR 采用自适应预测功能进行标签校正,以便可以分别从“干净”和“嘈杂”子集中识别误报和真阳性。此外,我们通过将校正后的标签重铸为软边距,提出了一种新的三元组损失,用于稳健的跨模态匹配。
本文的主要贡献和新颖性可总结如下。 i) 我们揭示了跨模态分析中的一个新问题,这也是噪声标签的新范式,称为噪声对应。与传统的噪声标签不同,噪声对应是指配对数据中的对齐错误,而不是类别注释中的错误。据我们所知,这项工作可能是对这个问题的第一次研究。 ii) 为了解决噪声对应问题,我们提出了一种新的噪声对应学习方法,称为噪声对应整流器 (NCR)。 NCR 的一个主要新颖之处在于,校正后的标签被优雅地重铸为三元组损失的软边缘,从而可以实现稳健的跨模态匹配。 iii)为了验证我们方法的有效性,我们对图像文本匹配任务进行了实验。在三个具有挑战性的数据集上进行的大量实验验证了我们的方法在合成噪声和真实噪声中的有效性。
2 相关工作
在本节中,我们将简要介绍跨模态匹配和带噪声标签学习的一些最新进展
2.1 跨模态匹配
大多数现有的跨模式匹配工作试图学习一个公共空间,其中不同的模式是可比较的。一般来说,现有的工作可以大致分为两类:1)粗粒度匹配。它通常利用多个神经网络来计算全局特征,每个网络用于特定的模态 。例如,Kiros 等人使用卷积神经网络 (CNN) 和门控循环单元 (GRU) 来获取图像和文本特征,同时强制正对的相似度大于负对的相似度。为了进一步提高匹配性能,VSE++ 使用了一些具有代表性的负样本来提高模型的区分度。 2)细粒度匹配。它旨在测量跨模态匹配的细粒度相似性。例如,SCAN 提出学习图像区域和单词之间的潜在语义对应关系,它们分别由自下而上的注意力和 GRU 提取。 VSRN 采用图卷积网络进行语义推理。 SGRAF提出构建相似图来推理相似性,并采用注意力过滤技术来消除意义不大的对齐。最近 Chun 等人。引入了一种新的跨模态匹配范式,即图像和字幕中可能存在的多对多对应关系。为了实现这一点,他们建议使用概率表示来模拟可能的一对多对应关系。
尽管近年来取得了可喜的成果,但现有方法严重依赖于正确对齐的数据。然而,在实践中,这种匹配良好的数据收集起来既昂贵又耗时。此外,最近的一些工作 [34, 14] 表明,从野外收集的大规模数据集可以显着提高模型的性能。但是,这样的数据不可避免地会包含一些不匹配的对。因此,人们非常期望开发一些对噪声对应具有鲁棒性的方法,据我们所知,这些方法还没有被研究过。与图像和字幕之间的多对多对应 [6] 不同,NCR 揭示了噪声对应问题,即图像-文本对的对齐错误,并建议消除噪声对对下游任务的负面影响。
2.2学习噪声标签
为了处理训练数据中可能存在的噪声注释,已经提出了大量方法,并且几乎所有方法都集中在分类任务上 [35, 26]。为了减少噪声标签的负面影响,现有的工作通常采用稳健的架构设计、正则化、损失调整或样本选择方法。在这里,我们主要介绍与这项工作最相关的最后两种方法。具体来说,损失调整通过调整干净和噪声样本的贡献来实现鲁棒性。亏损。例如,里德等人。 [31] 提出了一种基于模型预测的自举损失来进行损失校正。张等人。 [44]为标签校正提供了一些理论解释以及新的标签校正算法。与损失调整方法不同,样本选择方法旨在从嘈杂的数据集中选择干净的样本。例如,Arpit 等人。 [3] 表明 DNN 在拟合噪声样本之前倾向于学习简单的模式,即记忆效应。受此启发,Arazo 等人。 [2]提出将损失小的样品作为清洁样品处理。为了避免干净样本的选择偏差,Co-teaching 方法 [10, 42] 使用损失较小的样本来迭代训练两个网络。最近,DivideMix [20] 采用 MixMatch 方法 [4] 对干净和嘈杂的样本进行半监督学习。
与上述噪声标签研究不同,本文关注噪声对应问题,该问题考虑不匹配的多模态数据对而不是错误注释的数据点。除了问题的不同之外,这项工作在方法论上也与上述研究不同。具体来说,在跨模态匹配中,由于以下两个原因,不可能直接采用这些噪声标签学习方法来解决噪声对应问题。首先,大多数嘈杂的标签学习方法建议在分类场景中使用模型的预测来进行标签校正,而直接预测匹配模型中给定对的对应关系是困难的。其次,即使我们能以某种方式纠正嘈杂的对应关系校正后的实值标签与现有的匹配方法不兼容,因为它们中的大多数都假设给定的标签是二进制的。为了解决这些问题,NCR 通过将软标签重铸为软边距,提出了一种自适应预测函数和一种新颖的三元组损失。
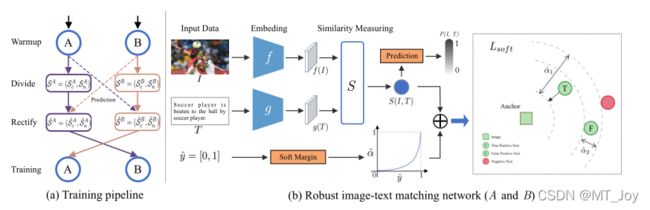
图 2:建议方法的概述。 (a) NCR 的培训管道。 NCR 由两个独立的网络(A、B)组成,它们以合作教学的方式工作。简而言之,NCR 首先使用损失 Lw 对原始训练数据上的网络 (A, B) 进行预热,该损失 Lw 也用于每样本损失计算。然后,基于 DNN 的记忆效果,NCR 在每个 epoch 使用 A 或 B 将训练数据划分为干净和嘈杂的子集,即 SA = (SAc , SAn ) 和 SB = (SBc , SBn )。之后,NCR 将共同校正 {SA, SB} 的对应关系,并使用自适应预测函数获得 { ^SA, ^SB}。最后,^SA 和 ^SB 将用于以交换方式训练网络 B 和 A。 (b) 健壮的图文匹配网络。例如,网络 A 分别通过特定于模态的网络 f 和 g 投影图像和文本。然后在提取的特征 f(I) 和 g(T) 上计算相似度 S(I, T)。为了实现鲁棒的图像-文本匹配,修正后的软标签被重铸为我们的损失 Lsof t 的软边距。如图所示,对于给定的anchor,Lsof t 将强制真阳性比阴性更接近它一个很大的边距^α1,同时假阳性将有一个小的边距^α2。
3 提出的方法
在本节中,我们详细说明了所提出的方法,即噪声对应整流器(NCR),它可能是解决跨模态匹配中噪声对应问题的第一项工作。在第 3.1 节中,我们介绍了 co-divide 模块,它将训练数据分成干净和嘈杂的子集。之后,我们将在第 3.2 节介绍如何使用自适应预测函数来纠正标签。最后,我们在 3.3 节详细介绍了如何结合 co-divide 和 co-rectify 模块来实现鲁棒的跨模态匹配。
3.1 共分
形式化:本文以图像-文本匹配(image-text match)作为一种跨模态匹配的具体实例进行方法的介绍。
首先使用两个模态相关的网络(modal-specific networks)f 和 g 分别将视觉和文本模态的数据映射到同一个特征空间中。然后计算一个图像-文本配对的相似度,为了简单起见,本文统一将该式记为。
之前的研究发现DNN网络在学习过程中倾向于先学习简单的模式然后逐渐拟合噪声模式,这被称为DNN网络的记忆效应(memorization effect),该效应会导致数据中的干净样本(clean samples)与噪声样本noisy samples相比拥有较低的loss值。
借助于这种记忆效应,本文通过干净样本和噪声样本的loss分布的差异来划分训练数据。给定一个本文的模型包含(f, g, S),通过下面的公式计算每一个数据样本的loss值:
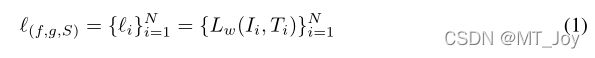
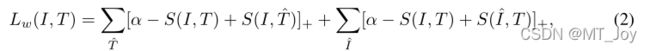
其中 (I, T ) 是正对,α > 0 表示给定的边距,[x]+ = max(x, 0)。在损失中,第一项将 I 视为接管所有负面文本 ^T 的查询,而第二项将 T 视为接管所有负面图像 ^I 的查询。然后,我们使用双分量高斯混合模型 [20, 29] 拟合所有训练数据的每个样本损失:

其中 βk 和 φ(‘|k) 分别是混合系数和第 k 个分量的概率密度。基于 DNN 的记忆效果,我们将具有较低平均值(即损失较低)的组件视为干净集,将另一个视为噪声集。为了优化 GMM,我们采用了期望最大化算法。此外,我们计算后验概率 wi = p(k|'i) = p(k)p('i|k)/p('i) 作为第 i 个样本的干净概率,其中 k 是高斯分量具有较低的平均值。通过将阈值设置为 {wi}Ni=1,我们将数据划分为干净和嘈杂的子集。为简单起见,我们通过所有实验将阈值设置为 0.5
2. 协同纠正模块(co-rectify module)
该部分的作用是对划分之后的数据进行标签的纠正。就是说划分后的noisy数据里面也许还有true positive数据,要找到它们并加入clean划分中;同时划分后的clean数据里面也许还有false positive数据,要降低它们的负面影响。具体的纠正过程如下,纠正之后得到新的划分情况:
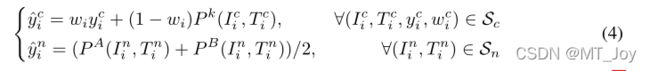
公式(4)中 P(I,T)代表本文的模型对配对的预测标签。公式(4)可以这样理解:对clean子集里的数据,它的新标签由旧标签和模型预测标签加权求和得到;对noisy子集里的数据标签则完全来自模型预测标签,不使用原来的标签了。
公式(4)的另一个贡献是设计了预测函数P。对于通常的noisy label问题而言,如果要重新给这种数据打标签,只需要预测一个label值就可以(比如0,1等)。但是对于图像-文本匹配问题而言,不存在一个具体的标签,通常计算的是图像和文本间的相似度。那么直观上看,设置一个相似度阈值,就能将数据区分开,但是该阈值需要设置为多少、不同数据集下该阈值是否不同?这又引入新的难题。
所以本文设计了一种数据驱动的自适应预测函数P(I,T)来预测给定图像-文本配对的标签:
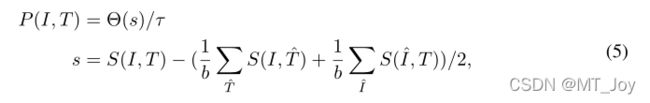
上式中b是batch size,s是相似度margin,它是在一个mini-batch中,给定的图像-文本配对(I,T)的相似度与其他所有negative配对的相似度的差值。tao是基于s的最大10%相似度配对的相似度margin的平均值。最后,相似度margin大于tao的配对被预测为1,其他配对的标签为[0,1)。
3. 鲁棒的跨模态匹配
本文提出了一个novel的三元组学习方法来解决噪声对应问题,将纠正的标签作为三元组loss中soft margin,具体公式如下:
![]()
公式(6)中 T^ 和 I^ 是hardest negative样本(意思是负样本中最难以区分的样本,具体解释说明见[2],使用该负样本的含义是:如果模型能够区分负样本中最难以区分的样本,那么其他所有的负样本模型都可以轻易区分了)。
soft margin alpha^的计算方式如下:

其中m是curve参数,y^是纠正后的标签。公式(7)实际意义是:当y^接近0时,也就是样本不太匹配时,alpha^是一个较小的值;反之当y^接近1,也就是样本配对很positive时,alpha^是个较大的值,也就是说模型能以较大的margin区分positive的配对和它对应的negative配对。

图 4 显示了由 NCR 识别的一些嘈杂的 CC152K 示例。如图所示,前四个图像-文本对完全不相关,NCR 将成功检测到。对于最后一对,即使视觉和文本模式在粗粒度级别相关,它也会被检测为噪声对应,例如,图像和文本都涉及“海滩”。
5 结论
本文可能是第一次尝试研究跨模态匹配中的一个新问题,即噪声对应,这可能是噪声标签的一个潜在新方向。为了解决跨模态匹配中的这个问题,我们建议通过自适应预测函数和具有软边距的新型三元组损失来纠正噪声对应,以实现稳健的跨模态匹配。大量实验验证了所提出的方法在处理合成和真实噪声对应方面的有效性。