Python 神经网络编程之学习笔记——第一个完美的神经网络学习程序,学习识别手写数据
这是我学习python神经网络编程的一个程序汇总,里面将学习过程的一些代码进行了备注,该程序不备注部分的代码是一个比较完美的神经网络学习代码,用于学习识别手写数据,我运行该程序花费了大约3个小时的时间,网络经过训练,识别手写数据的正确率可达0.9746。
以下为全部代码:
#第一个深度学习程序
#导入numpy扩展包,numpy是创建数组函数,用于定义矩阵函数、转换列表等,此函数用于处理矩阵、数组、列表等数据功能
import numpy
#导入scipy python库,用于调用s函数expit()
import scipy.special
#导入绘图拓展库
import matplotlib.pyplot
import pylab
#%matplotlib inline
#定义类别
class neuralNetwork():
# 初始化程序
def __init__(self,inputnodes,hiddennodes,outputnodes,learningrate):
#设置网络节点,输入层节点inputnodes,隐藏层节点hidnodes,输出层节点outnodes
self.inodes=inputnodes
self.hnodes=hiddennodes
self.onodes=outputnodes
#设置学习效率
self.lr=learningrate
#用随机函数生成3x3的矩阵权重矩阵,权重值为-0.5~+0.5
#生成输入层至阴藏层之间的权重矩阵,self.wih=(numpy.random.rand(self.hnodes,self.inodes)-0.5)
# 生成阴藏层至输出层之间的权重矩阵,self.who=(numpy.random.rand(self.onodes,self.hnodes)-0.5)
# 用正态分布生成3x3的矩阵权重矩阵
# 生成输入层至阴藏层之间的权重矩阵
self.wih=(numpy.random.normal(0.0,pow(self.hnodes,-0.5),(self.hnodes,self.inodes)))
# 生成阴藏层至输出层之间的权重矩阵
self.who=(numpy.random.normal(0.0,pow(self.onodes,-0.5),(self.onodes,self.hnodes)))
#打印显示随机生成的权重矩阵
#print("随机生成输入层至隐藏层之间权重矩阵:")
#print(self.wih)
#print("随机生成输入层至隐藏层之间权重矩阵:")
#print(self.who)
#在初始化程序中利用lambda创建s激活函数,并命名为self.activation_function()函数,用于接收x函数
self.activation_function=lambda x:scipy.special.expit(x)
pass
#训练函数,用于第二阶段反向传播误差,将计算得到的输出与所需输出对比,使用差值来指导网络 权重的更新。inputs_list是输入参数,targets_list期望的输出结果值(理想的结果值)
def train(self,inputs_list,targets_list):
# 将输入的列表inputs_list转换为二维数组
inputs = numpy.array(inputs_list, ndmin=2).T
# 将输入的列表targets_list转换为二维数组,targets_list是期望输出值,以此参数为参考训练网络
targets = numpy.array(targets_list, ndmin=2).T
# 利用numpy.dot矩阵点积函数将所有的输入与所有正确的链接权重组,生成了组合调节后的信号矩阵,传输给每个隐藏层节点
hidden_inputs = numpy.dot(self.wih, inputs)
# 利用s激活函数self.activation_function处理组合调整后准备进入隐藏层节点的信号矩阵进行再次处理
hidden_outputs = self.activation_function(hidden_inputs)
# 利用numpy.dot矩阵点积函数将所有隐藏层出来准备进入输出层的数据与所有正确的链接权重组,生成了组合调节后的信号矩阵,传输给每个输出层节点
final_inputs = numpy.dot(self.who, hidden_outputs)
# 利用s激活函数self.activation_function处理组合调整后准备进入输出层节点的信号矩阵进行再次处理
final_outputs = self.activation_function(final_inputs)
#计算理想值与计算输出值之间的误差,用于优化在隐蔽层和最终层之间的权重
output_errors=targets-final_outputs
#利用numpy.dot矩阵点积函数对输出的误差output_error按权重进行拆分,根据所连接的权重分割误差,为每个隐藏层节点重组这些误差,用于优化输入层和隐藏层之间的权重
hidden_errors=numpy.dot(self.who.T,output_errors)
#通过梯度下降法最小化网络误差,更新隐藏层与输出层之间的节点权重值,更新节点j与其下一层节点k之间链接权重的矩阵形式的表达式:=调整链接权重值=学习率*下一层节点数值*第一层数值(1-第一层数值)*第一层输出的转置,*号表示矩阵点乘
self.who+=self.lr*numpy.dot((output_errors*final_outputs*(1.0-final_outputs)),numpy.transpose(hidden_outputs))
# 通过梯度下降法最小化网络误差,更新输入层与隐藏层之间的节点权重值,更新节点j与其下一层节点k之间链接权重的矩阵形式的表达式:=调整链接权重值=学习率*下一层节点数值*第一层数值(1-第一层数值)*第一层输出的转置,*号表示矩阵点乘
self.wih+=self.lr*numpy.dot((hidden_errors*hidden_outputs*(1.0-hidden_outputs)),numpy.transpose(inputs))
pass
#查询函数,用于第一个阶段就,就是正向的计算输出阶段
def query(self,inputs_list):
#将输入的列表inputs_list转换为二维数组
inputs=numpy.array(inputs_list,ndmin=2).T
# 将所有的输入与所有正确的链接权重组,生成了组合调节后的信号矩阵,传输给每个隐藏层节点
hidden_inputs=numpy.dot(self.wih,inputs)
# 利用s激活函数self.activation_function处理组合调整后准备进入隐藏层节点的信号矩阵进行再次处理
hidden_outputs= self.activation_function(hidden_inputs)
# 将所有隐藏层出来准备进入输出层的数据与所有正确的链接权重组,生成了组合调节后的信号矩阵,传输给每个输出层节点
final_inputs=numpy.dot(self.who,hidden_outputs)
# 利用s激活函数self.activation_function处理组合调整后准备进入输出层节点的信号矩阵进行再次处理
final_outputs= self.activation_function(final_inputs)
#打印显示final_outputs参数
#print("输出final_outputs参数",final_outputs)
# 函数返回输出层输出的参数final_outputs,用于第二阶段反向传播误差
return final_outputs
pass
#给网格节点赋值
#为什么选择784个输入节点呢?请记住,这是28×28的结果,即组成手 写数字图像的像素个数。
input_nodes=784
#选择使用100个隐藏层节点并不是通过使用科学的方法得到的。我们认 为,神经网络应该可以发现在输入中的特征或模式,这些模式或特征可以 使用比输入本身更简短的形式表达,因此没有选择比784大的数字。
hiddea_nodes=200
#给定的输出层需要10个标签,对应于10个输出层节点
output_nodes=10
#给学习效率赋值
learning_rate=0.1
#定义神经网络(neuralNetwork类)n类组
n=neuralNetwork(input_nodes,hiddea_nodes,output_nodes,learning_rate)
打印显示随机生成的权重矩阵,输入函数为数组,用[]进行输入数组
#print(“随意检验演示检验查询函数输出结果:”)
#print(n.query([1.0,0.5,-1.5]))
#用训练的样本数据mnist_train。csv训练网络
#用python打开电脑文件,并创建data_file文件句柄用于后续调用和操作文件,文件名不能包含中文字符,不然会显示出错
training_data_file=open(“E:\mnist_train.csv”,‘r’)
#使用与文件句柄data_file相关的readlines()函数, 将文件中的所有行读入变量data _list。这个变量包含了一个列表,列表中 的一项是表示文件中一行的字符串
training_data_list=training_data_file.readlines()
#关闭文件
training_data_file.close()
#打印显示列表的长度和列表的内容,len()函数是查询列表长度的函数
#print(“样本数据库的数量为:”,len(data_list),“组样本”)
#print(data_list)
#利用split()函数对data_list的第一条记录,以“,”为分隔符号进行分隔,并将分隔好的数据存放到all_values
#all_values=data_list[0].split(’,’)
#利用numpy.asfarray()函数将文本字符串转换成实数,并创建这些数字的数组
##all_values[1:]中的[1:]是指将#all_values数组中除了第1个元素之外的所有元素进行操作
#reshape((28,28))是指将#all_values[1:]的值排成28x28的矩阵数组
#image_array=numpy.asfarray(all_values[1:]).reshape((28,28))
#使用imshow()函数绘出image_array,选择灰度调色板——cmap=“Greys(灰度)”,
#matplotlib.pyplot.imshow(image_array,cmap=‘Greys’,interpolation=‘None’)
#启动显示程序,显示画图输出
#pylab.show()
#显示像术数组
#print(image_array)
#用for循环语句逐个读取样本
#设置使用训练样本数据库重复进行训练5次
training_number=5
#for循环语句,for record in data_list:意思是从data_list数组中逐个读取数据并赋值给record
for number in range(training_number):
a=0
for record in training_data_list:
# 将从样本数据文件中读取出来的数据按“,”进行划分存放到all_values里面的像素数据进行缩放移位
all_values=record.split(’,’)
# 是将输入颜色值从较大的0到255的范围,缩放至较小的0.01 到 1.0的范围
inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
# 创建长度为10的数组,并用numpy.zeros()函数全部填充为0
# 但是输出值只能是0.01 到 1.0,所以数组末尾得+0.01
targets=numpy.zeros(output_nodes)+0.01
# int(all_values[0]函数将all_values[0]中的标签字符转换为数值
# targets[int(all_values[0])]在数组中对应的标签位置赋值为最大值0.99
targets[int(all_values[0])]=0.99
# 调用训练函数,调用时输入训练数据和正确标签值进行对比修正误差
n.train(inputs,targets)
a+=1
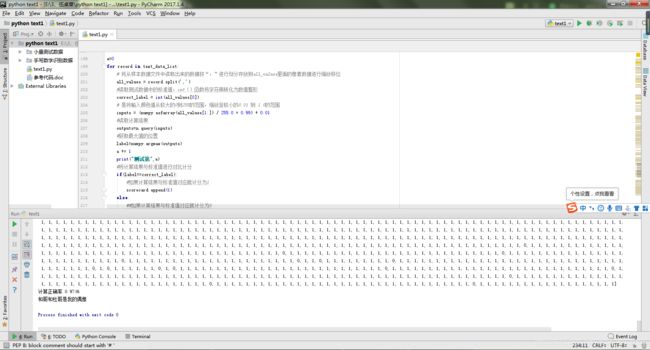
print(“程序进行第”,number,a)
pass
pass
#correct_label=int(all_values[0])
#print("数据的标准值为:",correct_label)
#显示缩放后的颜色值
#print("缩放到0.01 到 1.0的范围后的颜色值")
#print(scaled_input)
#
#outputs=n.query( scaled_input)
#
#label=numpy.argmax(outputs)
#
#print("网络计算结果为:",label)
#
#if(label==correct_label):
#
#scorecard.append(1)
#else:
#
#scorecard.append(0)
#pass
#pass
#用测试的样本数据mnist_test.csv训练网络
#用python打开电脑文件,并创建data_file文件句柄用于后续调用和操作文件,文件名不能包含中文字符,不然会显示出错
text_data_file=open(“E:\mnist_test.csv”,‘r’)
#使用与文件句柄data_file相关的readlines()函数, 将文件中的所有行读入变量data _list。这个变量包含了一个列表,列表中 的一项是表示文件中一行的字符串
text_data_list=text_data_file.readlines()
#关闭文件
text_data_file.close()
#用for循环语句逐个读取测试数据
#定义计分卡数组
scorecard=[]
a=0
for record in text_data_list:
# 将从样本数据文件中读取出来的数据按“,”进行划分存放到all_values里面的像素数据进行缩放移位
all_values = record.split(’,’)
#读取测试数据中的标准值,int()函数将字符串转化为数值整形
correct_label = int(all_values[0])
# 是将输入颜色值从较大的0到255的范围,缩放至较小的0.01 到 1.0的范围
inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
#读取计算结果
outputs=n.query(inputs)
#获取最大值的位置
label=numpy.argmax(outputs)
a += 1
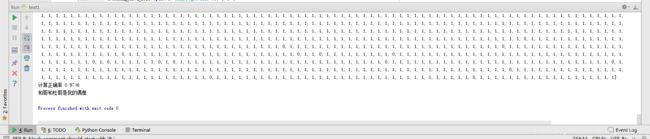
print(“测试第”,a)
#将计算结果与标准值进行对比计分
if(label==correct_label):
#如果计算结果与标准值对应就计分为1
scorecard.append(1)
else:
##如果计算结果与标准值对应就计分为0
scorecard.append(0)
pass
pass
#计算测试结果的正确率
#numpy.asarray()函数将列表转换为数据
scorecard_array=numpy.asarray(scorecard)
#计算比例
print(“计算正确率”,scorecard_array.sum()/scorecard_array.size)
#将样本数据转换为目标数组,准备进行输入网络进行查询和运算
将从样本数据文件中读取出来的数据按“,”进行划分存放到all_values里面的像素数据进行缩放移位
#all_values = record.split(’,’)
是将输入颜色值从较大的0到255的范围,缩放至较小的0.01 到 1.0的范围
#scaled_input = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
#因为需要判断的值为0-9,总共10个数据,所以需要10个输出端口分别对应输出值,所以将输出节点的数量设置为10
#onodes=10
#创建长度为10的数组,并用numpy.zeros()函数全部填充为0
#但是输出值只能是0.01 到 1.0,所以数组末尾得+0.01
#targets=numpy.zeros(onodes)+0.01
#int(all_values[0]函数将all_values[0]中的标签字符转换为数值
#targets[int(all_values[0])]在数组中对应的标签位置赋值为最大值0.99
#targets[int(all_values[0])]=0.99
#调用训练函数,调用时输入训练数据和正确标签值进行对比修正误差
#n.train(scaled_input,targets)
#调取查询函数返回值,查看神经网络计算的结果
#print(“神经网络计算的结果”)
#print(n.query([scaled_input]))
#随便乱显示输出
print(‘和哥和杜哥是我的偶像’)