FCN源码解读之score.py
转载自 https://blog.csdn.net/qq_21368481/article/details/80424754
score.py是FCN中用于测试测试集/验证集的,并输出相应的像素准确度、平均准确度、mean IU和频率加权交并比(frequency weighted IU)四个指标的python文件。score.py的源码如下:
-
from __future__
import division
-
import caffe
-
import numpy
as np
-
import os
-
import sys
-
from datetime
import datetime
-
from PIL
import Image
-
-
def fast_hist(a, b, n):
-
k = (a >=
0) & (a < n)
-
return np.bincount(n * a[k].astype(int) + b[k], minlength=n**
2).reshape(n, n)
-
-
def compute_hist(net, save_dir, dataset, layer='score', gt='label'):
-
n_cl = net.blobs[layer].channels
-
if save_dir:
-
os.mkdir(save_dir)
-
hist = np.zeros((n_cl, n_cl))
-
loss =
0
-
for idx
in dataset:
-
net.forward()
-
hist += fast_hist(net.blobs[gt].data[
0,
0].flatten(),
-
net.blobs[layer].data[
0].argmax(
0).flatten(),
-
n_cl)
-
-
if save_dir:
-
im = Image.fromarray(net.blobs[layer].data[
0].argmax(
0).astype(np.uint8), mode=
'P')
-
im.save(os.path.join(save_dir, idx +
'.png'))
-
# compute the loss as well
-
loss += net.blobs[
'loss'].data.flat[
0]
-
return hist, loss / len(dataset)
-
-
def seg_tests(solver, save_format, dataset, layer='score', gt='label'):
-
print
'>>>', datetime.now(),
'Begin seg tests'
-
solver.test_nets[
0].share_with(solver.net)
-
do_seg_tests(solver.test_nets[
0], solver.
iter, save_format, dataset, layer, gt)
-
-
def do_seg_tests(net, iter, save_format, dataset, layer='score', gt='label'):
-
n_cl = net.blobs[layer].channels
-
if save_format:
-
save_format = save_format.format(iter)
-
hist, loss = compute_hist(net, save_format, dataset, layer, gt)
-
# mean loss
-
print
'>>>', datetime.now(),
'Iteration', iter,
'loss', loss
-
# overall accuracy
-
acc = np.diag(hist).sum() / hist.sum()
-
print
'>>>', datetime.now(),
'Iteration', iter,
'overall accuracy', acc
-
# per-class accuracy
-
acc = np.diag(hist) / hist.sum(
1)
-
print
'>>>', datetime.now(),
'Iteration', iter,
'mean accuracy', np.nanmean(acc)
-
# per-class IU
-
iu = np.diag(hist) / (hist.sum(
1) + hist.sum(
0) - np.diag(hist))
-
print
'>>>', datetime.now(),
'Iteration', iter,
'mean IU', np.nanmean(iu)
-
freq = hist.sum(
1) / hist.sum()
-
print
'>>>', datetime.now(),
'Iteration', iter,
'fwavacc', \
-
(freq[freq >
0] * iu[freq >
0]).sum()
-
return hist
详细解读如下:
(1)fast_hist()函数
-
'''
-
产生n×n的分类统计表
-
参数a:标签图(转换为一行输入),即真实的标签
-
参数b:score层输出的预测图(转换为一行输入),即预测的标签
-
参数n:类别数
-
'''
-
def fast_hist(a, b, n):
-
#k为掩膜(去除了255这些点(即标签图中的白色的轮廓),其中的a>=0是为了防止bincount()函数出错)
-
k = (a >=
0) & (a < n)
-
#bincount()函数用于统计数组内每个非负整数的个数
-
#详见https://docs.scipy.org/doc/numpy/reference/generated/numpy.bincount.html
-
return np.bincount(n * a[k].astype(int) + b[k], minlength=n**
2).reshape(n, n)
此函数用于产生n*n的分类统计表,还不理解的可以看如下分析:
假如输入的标签图a是3*3的,如下左图,图中的数字表示该像素点的归属,即每个像素点所属的类别(其中n=3,即共有三种类别);预测标签图b的大小和a相同,如右图所示(图中的数字也代表每个像素点的类别归属)。


直观上看,b中预测的标签有两个像素点预测出错,即
b01,b20b01,b20
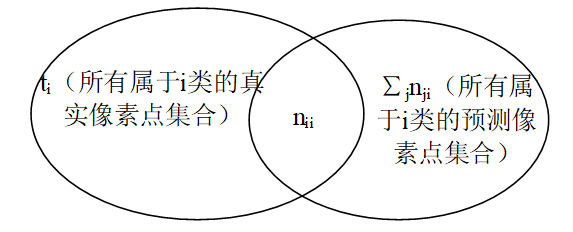
表示属于第i类的所有像素数目
对应do_seg_tests()函数中的源码,相信大家肯定能更好理解和掌握这四个指标的计算技巧。
其中还有一点,就是交并比IU,为所有真实属于第i类的像素点所组成的集合A与所有预测属于第i类的像素点所组成的集合B的交集和并集之比,如下图