机器学习笔记(2) -- 逻辑回归简单实现Kaggle泰坦尼克预测
预测Titanic乘客逃生
1、关于Kaggle
Kaggle成立于2010年,是一个进行数据发掘和预测竞赛的在线平台。从公司的角度来讲,可以提供一些数据,进而提出一个实际需要解决的问题;从参赛者的角度来讲,他们将组队参与项目,针对其中一个问题提出解决方案,最终由公司选出的最佳方案可以获得5K-10K美金的奖金。
除此之外,Kaggle官方每年还会举办一次大规模的竞赛,奖金高达一百万美金,吸引了广大的数据科学爱好者参与其中。从某种角度来讲,可以把它理解为一个众包平台,类似国内的猪八戒。但是不同于传统的低层次劳动力需求,Kaggle一直致力于解决业界难题,因此也创造了一种全新的劳动力市场——不再以学历和工作经验作为唯一的人才评判标准,而是着眼于个人技能,为顶尖人才和公司之间搭建了一座桥梁。
输入https://www.kaggle.com/即可进入Kaggle主页,网站有这么几个版块:
1、竞赛competitions
2、数据datasets
3、代码kernels
4、讨论区 Discussion
5、在线课程学习learn
2、如何上手Kaggle?
想要真正参与Kaggle,参赛者最好具有统计、计算机或数学相关背景,有一定的coding技能,对机器学习和深度学习有基本的了解,Kaggle任务虽然不限制编程语言,但绝大多数队伍会选用Python和R,所以至少熟悉其中一种。
如果从未独立做过一个项目,最好从练习赛开始熟悉。因为竞赛模式中的任务是公司悬赏发布的实际案例,并没有标准的答案;而练习赛不仅项目难度低,而且是有官方给出的参考方案的,大家可以用来对比改善自己的测试结果,从中进行提高。
3、关于泰坦尼克号之灾
这里是竞赛地址
这里是数据下载页。
4、用逻辑回归简单实现预测
import numpy as np # 数组常用库
import pandas as pd # 读入csv常用库
from patsy import dmatrices # 可根据离散变量自动生成哑变量
from sklearn.linear_model import LogisticRegression # sk-learn库Logistic Regression模型
from sklearn.model_selection import train_test_split, cross_val_score # sk-learn库训练与测试
from sklearn import metrics # 生成各项测试指标库
import matplotlib.pyplot as plt # 画图常用库
import matplotlib as mpl
从本地读入数据
data = pd.read_csv('F:/PycharmProjects/Titanic/train.csv')
观察逃生人数和未逃生人数
mpl.rcParams['font.sans-serif'] = ['SimHei']
data_train.Survived.value_counts().plot(kind='bar')# 柱状图
plt.title(u"获救情况 (1为获救)") # 标题
plt.ylabel(u"人数")
观察乘客等级分布
data_train.Pclass.value_counts().plot(kind="bar")
plt.ylabel(u"人数")
plt.title(u"乘客等级分布")
观察性别对获救的影响
Survived_m = data_train.Survived[data_train.Sex == 'male'].value_counts()
Survived_f = data_train.Survived[data_train.Sex == 'female'].value_counts()
df = pd.DataFrame({u'男性':Survived_m,u'女性':Survived_f})
# print(df)
df.plot(kind='bar', stacked=True)
plt.title(u"按性别看获救情况")
plt.xlabel(u"获救情况")
plt.ylabel(u"人数")
plt.show()
观察客舱等级对获救的影响
Survived_0 = data_train.Pclass[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Pclass[data_train.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各乘客等级的获救情况")
plt.xlabel(u"乘客等级")
plt.ylabel(u"人数")
plt.show()
用dmatrices将数据中的离散变量变成哑变量,并指明用Pclass, Sex, Embarked来预测Survived
y, X = dmatrices('Survived~ C(Pclass) + C(Sex) + Age + C(Embarked)', data = data_train, return_type='dataframe')
y = np.ravel(y)
model = LogisticRegression()
model.fit(X, y)

输出训练准确率
model.score(X, y)
![]()
输出控模型的正确率:空模型预测所有人都未逃生
1 - y.mean()
![]()
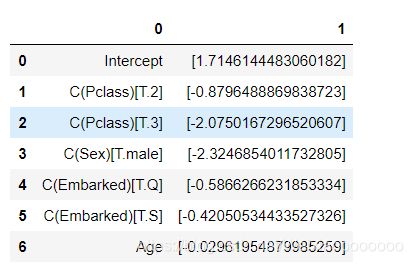
观察模型系数,即每种因素对于预测逃生的重要性
pd.DataFrame(list(zip(X.columns, np.transpose(model.coef_))))
对测试数据生成预测
test_data = pd.read_csv('F:/PycharmProjects/Titanic/test.csv')
test_data['Survived'] = 1
test_data.loc[np.isnan(test_data.Age), 'Age'] = np.mean(data_train['Age'])
ytest, Xtest = dmatrices('Survived~ C(Pclass) + C(Sex) + Age + C(Embarked)', data = test_data, return_type='dataframe')
pred = model.predict(Xtest).astype(int)
solution = pd.DataFrame(list(zip(test_data['PassengerId'], pred)), columns=['PassengerID', 'Survived'])
输出结果
solution.to_csv('my_prediction.csv', index = False)
写的很水。请各路大佬手下留情。