地表建筑物识别——Task02数据扩增
前言: Task2主要学习对语义分割任务中常见的数据扩增方法,并使用OpenCV 和albumentations 两个库完成具体的数据扩增操作,同时也对pytorch数据读取做个介绍。
常见的数据扩增方法
数据扩增是一种有效的正则化方法,可以防止模型过拟合,在深度学习模型的训练过程中应用广泛。数据扩增的目的是增加数据集中样本的数据量,同时也可以有效增加样本的语义空间。使用时需注意:
1) 不同的数据,拥有不同的数据扩增方法;
2) 数据扩增方法需要考虑合理性,不要随意使用;
3)数据扩增方法需要与具体任何相结合,同时要考虑到标签的变化;
对于图像分类,数据扩增方法可以分为两类:
- 标签不变的数据扩增方法:数据变换之后图像类别不变;
- 标签变化的数据扩增方法:数据变换之后图像类别变化;
而对于语义分割而言,常规的数据扩增方法都会改变图像的标签。如水平翻转、垂直翻转、旋转90度等
课后作业
- 使用OpenCV 完成图像加噪数据扩增;
- 使用OpenCV 完成图像旋转数据扩增;
- 使用albumentations 其他的的操作完成扩增操作;
- 使用Pytorch 完成赛题数据读取;
1. OpenCV 数据扩增
OpenCV 是计算机视觉必备的库,可以很方便的完成数据读取、图像变化、边缘检测和模式识别等任务。先介绍OpenCV 完成数据扩增的操作。
- cv2.flip()翻转
'''
0: flipping around the x-axis
positive value (for example, 1): flipping around y-axis
negative value (for example, -1): flipping around both axes
'''
img_verflip, mask_verflip = cv2.flip(img, 0), cv2.flip(mask, 0)
img_horflip, mask_horflip = cv2.flip(img, 1), cv2.flip(mask, 1)
img_diagflip, mask_diagflip = cv2.flip(img, -1), cv2.flip(mask, -1)
- 加噪
def addNoise(type, img):
'''
type: string, 'sp'椒盐噪声 or 'gauss'高斯噪声
img: uint8 ndarray
'''
if type == 'sp':
p = 0.1
out = img.copy()
for i in range(img.shape[0]):
for j in range(img.shape[1]):
rdn = random.random()
if rdn < p:
out[i, j, :] = 0
elif rdn > 1-p:
out[i, j, :] = 255
elif type == 'gauss':
out = np.array(img.copy()/255, dtype=float)
mean, std = 0, 1e-1 #gauss noise distribution
noise = np.random.normal(mean, std, (img.shape[0], img.shape[1]))
for idx in range(img.shape[2]):
out[:, :, idx] += noise
out = np.clip(out, 0, 1.0)
out = np.uint8(out*255)
return out
椒盐噪声
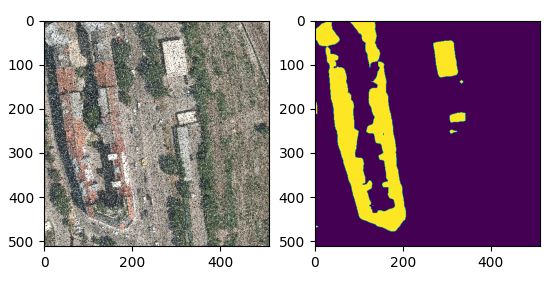
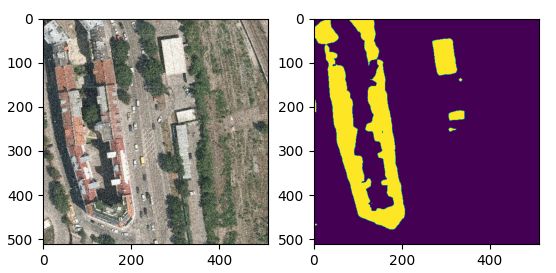
高斯噪声
- 旋转
def rotation(img, angle):
H,W = img.shape[:2]
newH = int(W*fabs(sin(radians(angle)))+H*fabs(cos(radians(angle))))
newW = int(H*fabs(sin(radians(angle)))+W*fabs(cos(radians(angle))))
matRotation = cv2.getRotationMatrix2D((W/2,H/2),angle,1)
matRotation[0,2] += (newW-W)/2 #加入平移操作
matRotation[1,2] += (newH-H)/2
imgRotation = cv2.warpAffine(img,matRotation,(newW,newH))
return imgRotation
逆时针旋转30度
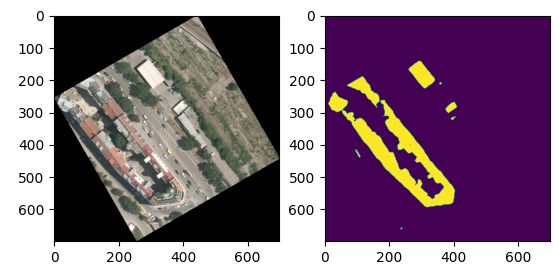
- 随机裁剪
x, y = np.random.randint(0, 256), np.random.randint(0, 256)
img_crop, mask_crop = img[x:x+256, y:y+256], mask[x:x+256, y:y+256]
随机裁剪 (256, 256)大小区域
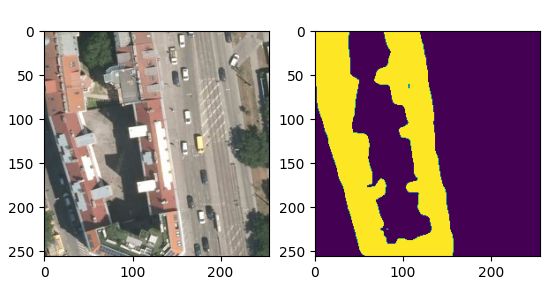
2. albumentations 数据扩增
albumentations 是基于OpenCV 的快速训练数据增强库,拥有非常简单且强大的可以用于多种任务(分割、检测)的接口,易于定制且添加其他框架非常方便。
albumentations 也是计算机视觉数据竞赛中最常用的库:
GitHub:https://github.com/albumentations-team/albumentations •
不同CV任务使用示例:https://github.com/albumentations-team/albumentations_examples
与OpenCV 相比albumentations 具有以下优点:
• albumentations 支持的操作更多,使用更加方便;
• albumentations 可以与深度学习框架(Keras 或Pytorch)配合使用;
• albumentations 支持各种任务(图像分流)的数据扩增操作
albumentations 可以对数据集进行逐像素的转换,如模糊、下采样、高斯造点、高斯模糊、动态模糊、RGB 转换、随机雾化等;也可以进行空间转换(同时也会对目标进行转换),如裁剪、翻转、随机裁剪等。
使用albumentations 在语义分割任务中的一些数据扩增示例可以参考[1,2],这里直接给出一些代码示例:
from albumentations import (
HorizontalFlip, IAAPerspective, ShiftScaleRotate, CLAHE, RandomRotate90,
Transpose, ShiftScaleRotate, Blur, OpticalDistortion, GridDistortion, HueSaturationValue,
IAAAdditiveGaussianNoise, GaussNoise, MotionBlur, MedianBlur, GaussianBlur,IAAPiecewiseAffine, RandomCrop,
PadIfNeeded, IAASharpen, IAAEmboss, RandomBrightnessContrast, Flip, OneOf, Compose, Resize, RandomSizedCrop
)
# 1)水平翻转
augments = HorizontalFlip(p=1)(image=img, mask=mask)
img_aug, mask_aug = augments['image'], augments['mask']
# 2)随机裁剪
augments = RandomCrop(p=1, height=256, width=256)(image=img, mask=mask)
img_aug, mask_aug = augments['image'], augments['mask']
# 3)随机仿射变换
augments = ShiftScaleRotate(p=1)(image=img, mask=mask)
img_aug, mask_aug = augments['image'], augments['mask']
# 4)填充
augments = PadIfNeeded(p=1, min_height=600, min_width=600)(image=img, mask=mask)
img_aug, mask_aug = augments['image'], augments['mask']
# 5)组合多个数据扩增操作
trfm = Compose([
Resize(256, 256),
HorizontalFlip(p=0.5),
RandomRotate90(),
Transpose(),
# 随机仿射变换
ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.50, rotate_limit=45, p=.75),
# 网格畸变
GridDistortion(),
OneOf([
# 高斯噪点
IAAAdditiveGaussianNoise(),
GaussNoise(),
], p=0.2),
OneOf([
# 模糊相关操作
MotionBlur(p=.2),
MedianBlur(blur_limit=3, p=0.1),
Blur(blur_limit=3, p=0.1),
GaussianBlur(blur_limit=3,p=0.5),
], p=0.2),
ShiftScaleRotate(shift_limit=0.0625, scale_limit=0.2, rotate_limit=45, p=0.2),
OneOf([
# 畸变相关操作
OpticalDistortion(p=0.3),
GridDistortion(p=.1),
IAAPiecewiseAffine(p=0.3),
], p=0.2),
])
augments = trfm(image=img, mask=mask)
img_aug, mask_aug = augments['image'], augments['mask']
- 注意
Compose可以将不同变换组合,顺序执行,Oneof选择变换组合的其中之一按概率执行。 - 为了防止充分变换后过度偏离原数据分布,可以在尾部加上概率,保证原图的数量;可以选用A.OneOf([op],p=0.5)来组合操作;也可以在Compose中套Compose(对吗?)
3. Pytorch 数据读取
在Pytorch 中数据是通过Dataset 进行封装,并通过DataLoder 进行并行读取。所以我们只需要重载一下数据读取的逻辑就可以完成数据的读取。
- Dataset:数据集,对数据进行读取并进行数据扩增;
- DataLoder:数据读取器,对Dataset 进行封装并进行批量读取;
这部分可参考余霆嵩 《PyTorch 模型训练实用教程》第一章,讲得很详细,同时网上也有很多优秀博客。直接给出如下代码:
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader, Subset
from torchvision import transforms as T
import albumentations as A
import cv2
from .rle import rle_encode, rle_decode
# Custom Dataset class
class TianChiDataset(Dataset):
def __init__(self, imgPaths, rles, IMAGE_SIZE, test_mode=False):
super(TianChiDataset, self).__init__()
self.imgPaths = imgPaths
self.rles = rles
self.test_mode = test_mode
self.transform = A.Compose([
A.Resize(IMAGE_SIZE, IMAGE_SIZE),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.RandomRotate90(),
])
self.as_tensor = T.Compose([
T.ToPILImage(),
T.Resize(IMAGE_SIZE),
T.ToTensor(),
T.Normalize([0.625, 0.448, 0.688],
[0.131, 0.177, 0.101]),
])
self.len = len(imgPaths)
# get data operation
def __getitem__(self, index):
img = cv2.imread(self.imgPaths[index])
if not self.test_mode:
mask = rle_decode(self.rles[index])
#data augmentation via albumentations
augments = self.transform(image = img, mask = mask)
return self.as_tensor(augments['image']), augments['mask'][None] #(256,256)的mask形状转为(1,256,256)
else:
return self.as_tensor(img), ''
def __len__(self):
return self.len
def get_dataloader(dataset, BATCH_SIZE):
train_idx, valid_idx = [], []
for i in range(len(dataset)):
if i % 300 == 0:
valid_idx.append(i)
# else:
elif i % 5 == 1: #pretrain
train_idx.append(i)
train_ds = Subset(dataset, train_idx)
valid_ds = Subset(dataset, valid_idx)
#define training and validation data loaders
train_loader = DataLoader(
train_ds, batch_size = BATCH_SIZE, shuffle=True, num_workers=0)
val_loader = DataLoader(
valid_ds, batch_size = BATCH_SIZE, shuffle=False, num_workers=0)
return train_loader, val_loader
注意如下几点:
-
albumentations嵌入到Dataset类中做数据扩增,通过对原图在一定概率下做变换组合,确实丰富了训练数据分布,但
__getitem__()方法单个索引,返回单个变换后的样本,导致Dataset中的训练集总数没变。 -
那么问题来了,如果对于小样本,需要极大增加训练样本数该怎么做呢?
- 可以先用opencv, albumentations等手动扩增数据,再用dataset读取;
- Dataset的原始机制为根据索引进行文件读取,如下代码:
class TianChiDataset(D.Dataset): def __init__(self, paths, rles, transform, test_mode=False): #....... pass def __getitem__(self, index): img = cv2.imread(self.paths[index]) #....... return img # 其本质就是按照索引输出相应的图片 def __len__(self): """ Total number of samples in the dataset """ return self.len如果需要自定义输出内容,可以在
__getitem__中增加随机机制,如random crop,并输出相应数量的数据。 -
Pytorch自带的transforms的使用。可以用transforms.Compose将所需要进行的处理给compose起来,例如代码中的self.as_tensor() 依次对图片进行以下操作:
- 将numpy array转换为PIL.Image格式;
- Totensor() 在这里会对数据进行transpose,原来是 h × w × c h \times w \times c h×w×c,会经过
img = img.transpose(0, 1).transpose(0, 2).contiguous(),变成 c × h × w c \times h \times w c×h×w 再除以255,使得像素值归一化至[0-1]之间; - 数据标准化(减均值,除以标准差),注意在进行Normalize时,需要先计算训练集图片在RGB三通道上的均值和方差。
参考文献
[1] Using Albumentations for a semantic segmentation task
[2] albumentations 数据增强工具的使用