Incremental Graph Convolutional Network for Collaborative Filtering(阅读论文笔记)
Incremental Graph Convolutional Network for Collaborative Filtering(阅读论文笔记)
In terms of data storage, IGCN does not require to store all the historical data to complete the training, but only stores a small amount of historical data. When taking interactions from a new time period, IGCN will update the stored historical data with the new data at the same time
文章综述(是我比较粗浅的理解):
本文提出的,是一种新的基于神经网络的CF算法。
一方面,通过增量学习的方式,改进先前基于RNN的CF算法中,存在的“灾难性遗忘的问题”。
做到这一点,通过使用MAML、堆叠iTCN,从而提高模型从新数据中整合新知识和提炼已有知识的能力(可塑性);
Q&A
- 为什么GNN能够提高CF算法的效率
First, the ability to leverage local neighborhood information among users and/or items
其次,可以灵活合并辅助信息,如社会信息、知识图等,可以帮助缓解协同过滤中众所周知的数据稀疏性问题。 - 本文中所说的subgraph:
newly observed user-item interactions can be regarded as a subgraph, which only contains the users and items (as nodes) and their interactions (as edges) over a short period of time, e.g., one week, one month. - 实现的小细节:
It is worth noting that we set different and for different periods in GCN in temporal
feature extraction module, instead of sharing the same parameters among periods, so that the features extracted from the user-item interaction network in each period with GCN are not affected by the other periods, which can better represent the features of users and items in that period.
现存的问题
- 图神经网络(GNN)由于其有用的图结构信息,最近在协同过滤(CF)方面取得了巨大的成功。然而,由于用户持续和商品进行交互,这将导致用户-item交互图随着时间的推移而变化,经过良好训练的GNN模型很快就会过时。
- 解决这个问题的一个简单的方法是在获得新的交互作用后对GNN模型进行再训练。然而,再训练在计算上是昂贵的,再者,有用的时间信息可能会在再训练过程中丢失,因为最近的interactions通常被视为与旧的interactions同等重要。
- 最近利用RNN保持GNN更新的研究可能会遭受“灾难性遗忘”问题,并遭受新用户和项目的冷开始问题。
创新之处
- 提出了一种新的增量时间卷积网络(iTCN),该网络将逐步融合上一个周期和当前周期的时间信息,能够实现高效、准确的时间感知特征学习。
- 提出IGCN,这是一个新颖的基于GNN增量推荐算法,使用
1)GCN to extract higher level interaction features on user-item interaction graph,
2) iTCN学习用户和项目时间感知特性
3)model agnostic meta-learning (MAML)初始化用户和项目历史嵌入缓解冷启动问题,确保快速模型适应 - 在5个真实数据集上进行了大量的实验,结果表明,IGCN可以优于最先进的推荐方法,包括基于GNN的顺序方法和其他增量方法。
主要组成
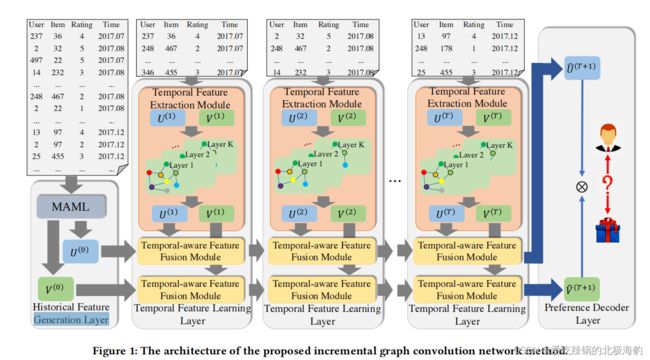
- a historical feature generation layer,通过模型不可知的meta-learning生成初始user/item嵌入,确保良好的初始状态和快速的模型自适应;
- a temporal feature learning layer,首先聚合特征从neighborhood更新每个user/item的嵌入在每个子图通过图卷积网络(GCN)然后融合user/item嵌入从最后子图和当前子图通过增量时间卷积网络(iTCN)。
模型结构
优点:
- ) incremental training. IGCN只需要在最近交互形成的子图上训练一个时间特征提取模块,然后分别为用户和项目重新训练时间感知的特征融合模块,自动将新特征与最后一段时间的特征融合。这两个模块都只在新的用户-项目交互上执行,即IGCN的训练是增量的;
- temporal-awareness and global-awareness.基于时间最近的交互训练,时间感知特征融合模块可以通过扫描整个用户和项目特征轨迹(全局感知),自动发现最重要的特征来预测时间用户行为和项目属性(时间感知)。因此,IGCN可以解决模型再训练中的时间信息丢失问题和基于RNN的方法中的“灾难性遗忘”问题。
注意:
- newly observed user-item interactions can be regarded as a subgraph, which only contains the users and items (as nodes) and their interactions (as edges) over a short period of time, e.g., one week, one month.
- Unlike traditional model training, which divides the dataset into training, validation and test sets, MAML uses a task as the minimum unit of the dataset
historical feature generation layer
综述:
historical feature generation layer,生成用户/项目嵌入,称为历史嵌入,在第一阶段使用 model agnostic meta learning(MAML)之前,以解决两个挑战:
- 快速模型适应。由于用户评分在每个时间段内都很少出现,因此基于MAML的初始化将有助于在每个时间段内以很少的评分实现更快的收敛。
- 新的新用户或新项目。由于可能有一些用户/项目只出现在测试时间内,通过MAML初始化他们的嵌入可以获得比随机初始化更好的性能
Incremental model按找顺序的方式更新,会有两个问题:
- Sparse data in each time period
- 仅出现在测试期的User/Item数据,无法合理的初始话其embedding;如果随机或者恒定一个embedding会导致poor performance
因此,当historical embedding缺失时,本文中用MAML来进行初始话historical embedding(此处呼应本文中提出的第一个现有问题,即当用户和item持续交互的时候,训练好的GNN会很快过时的问题)
When new users/items appear, their historical representations can be reasonably initialized by MAML. In addition, when new user-item interactions are available, user/item representations can quickly adapt and converge to the optimal ones.
temporal feature learning layer
综述:
用于处理本文中发现的第二个问题,即考虑到有用的时间信息,不让其丢失。
通过图卷积网络(GCN)聚合局部邻域的特征,更新每个用户/项目在每个子图中的嵌入,然后通过增量时间卷积网络(iTCN)融合最后一个和当前子图的用户/项目嵌入的特征。
iTCN采用扩张的因果卷积来确保:
- 大的接受域,因为分层的扩张的卷积可以产生指数增长的接受域;
- 因果关系,因为因果卷积可以确保当前的特征只依赖于所有过去的特征
组成:
one temporal feature extraction module and two temporal-aware feature fusion modules
temporal feature extraction module
temporal feature extraction module.使用图卷积在一个较短的period(例如一个月)从当前时期的用户-项目交互中提取时间特征
以下介绍在一个时间区间中图卷积的操作:
- first pretrain the node embedding of the subgraph at time period with matrix factorization(这一步之后可以得到用户特征矩阵和Item特征矩阵)
- To better capture the neighborhood information, we stack multiple graph convolutional layers to achieve more comprehensive feature aggregation.(此处提出了另外一种聚合的方法)
temporal-aware feature fusion module
temporal-aware feature fusion module 用于捕捉用户和项目特征如何随时间变化
CNN处理sequential data的局限性
- 在预测中考虑未来的特征,这违反了序列数据的结构;
- 受限的接受域,通常不能从用户和项目中获取早期的历史信息。
TCN可以解决这些问题,但是TCN也有着自身的局限性,并不是incremental recommendation problem的最优解:
- TCN是一个-to-结构,它要求将周期的输入表示同时作为一个序列,然后输出预测表示。而在增量推荐中,它通常需要一个1比1的结构,它接受当前周期的输入表示,并输出下一个周期的预测表示。
- TCN需要保存所有的历史数据和模型的中间结果,这大大增加了训练阶段的模型存储消耗。
因此本文中又提出了ITCN,其相较于TCN改进如下
- remove the residual connection
- 将分层的多层卷积简化为单层卷积
- 这种简化不仅学习了更准确的时间感知特性,而且还减少了训练过程中的存储消耗
- 为了实现1-1的增强推荐,本文中给iTCN设计了一个存储单元
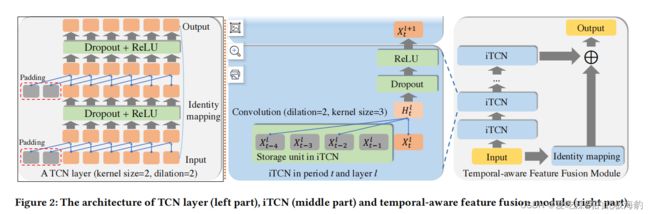
temporal-aware feature fusion module正是由多个iTCN堆叠而成(identity mapping component的作用在于解决堆叠iTCN时出现的梯度消失的问题)
A preference decoder layer
用于预测给定用户和给定项目之间交互的可能性。我们选择点积作为交互函数,因为它在精度和效率方面的优势,而MLP和其他交互函数也可以用于此处。
模型训练
Loss function:
explicit feedback datasets:MSE
implicit feedback datasets:cross-entropy
训练过程:
在每个时间段中,我们使用在时间段中观察到的interactions来训练多个时期的模型。我们不是直接使用上一个时期模型可能出现过拟合问题的参数,而是选择验证数据上损失最小的参数,并将其设置为训练时间周期+1的参数的初始值。
参与比较的CF methods的类别:
non-deep learning method (ND), deep learning method (D),
non-temporal method(NT), temporal method (T), non-graph based method (NG), graph based method (G), non-incremental method (NI) and incremental method(I).
实现细节:
- We use Adam optimizer with the initial learning rates from [0.0005, 0.001, 0.005]
- For all datasets, initial embedding size is fixed to 60
- In meta-learning, we tune the number of tasks from [5, 7, 10] and task size from [150, 200, 250, 300] for MovieLens and Netflix, and tune the number of tasks from [10, 12, 14] and task size from [400, 500] for Amazon Books and Yelp.
- In the GCN part of the temporal feature extraction module, the number of layers is fixed to 3 and the embedding size in each layer is fixed to 60.
- For iTCN, the kernel size is fixed to 3, and dropout rate is searched from [0.45, 0.5, 0.55].
- In the training process of IGCN the hyper-parameters in each period are kept the same。我们根据在训练阶段的最后一个时间段内对验证集的性能来调整所有方法(包括IGCN和比较方法)的超参数。
评价指标:
1)F1-score,即精度和召回率的调和平均值;
2)平均倒数排名(MRR),通过推荐列表中第一个真实项目的排名来评价绩效;
3)Normalized Discounted Cumulative Gain 归一化贴现累积增益(NDCG),评估推荐项目列表与最佳排名项目列表之间的差距。请注意,我们只使用四个sta
实验结果
- Sequential methods outperform non-sequential methods.
- Adopting graph structure can help to improve recommendation accuracy。主要原因是图结构为CF算法提供了额外的信息,可以帮助用户/项目增强他们的neighborhoods表示
- IGCN在所有数据集上的性能始终优于所有最先进的方法。主要原因是:
a)时间感知特征融合是通过CNN而不是RNN实现的,可以解决RRN、gcmcrnn、深度协同和jodie的“灾难性遗忘”问题;
b)基于MAML的参数初始化可以进一步提高性能,特别是在很少甚至没有评级的用户/项目上。与RNN相比,iTCN可以使每个用户/项目通过从早期阶段之前的特征中提取信息来丰富自己的特征学习,而没有任何遗忘机制,这有助于提高性能。(参考的主要指标是F1-score、MRR、NDCG)
消融分析
因为模型使用了GCN,MAML,iTCN,因此能够取得超过state-of-the-art的表现。
Terminology
- MAML
2.Feature learning(Representation learning)
In machine learning, feature learning or representation learning[1] is a set of techniques that allows a system to automatically discover the representations needed for feature detection or classification from raw data. This replaces manual feature engineering and allows a machine to both learn the features and use them to perform a specific task.
Feature learning is motivated by the fact that machine learning tasks such as classification often require input that is mathematically and computationally convenient to process. However, real-world data such as images, video, and sensor data has not yielded to attempts to algorithmically define specific features. An alternative is to discover such features or representations through examination, without relying on explicit algorithms.
3.交互函数
Efficient Neural Interaction Function Search for Collaborative Filtering这篇论文中有关于交换函数的详细解释,并且这篇文章提出了一种 search for simple neural interaction functions(SIF)的方法,旨在根据不同的数据集,为CF提供不同的交互函数。
4.灾难性遗忘
造成灾难性遗忘的一个主要原因是「传统模型假设数据分布是固定或平稳的,训练样本是独立同分布的」,所以模型可以一遍又一遍地看到所有任务相同的数据,但当数据变为连续的数据流时,训练数据的分布就是非平稳的,模型从非平稳的数据分布中持续不断地获取知识时,新知识会干扰旧知识,从而导致模型性能的快速下降,甚至完全覆盖或遗忘以前学习到的旧知识。
In this paper, we propose an AutoML approach to search for interaction functions in CF
交互函数的作用是capturing interactions among items and users。
最常见的交互函数是inner product,成功应用于低秩矩阵分解中。
总结
GNN模型的增量训练在协同过滤中具有局限性,现有的再训练或基于RNN的方法不能最优地解决这个问题。本文提出了增量图卷积网络,利用GCN和增量时间卷积网络进行高精度和高效的增量GNN训练。采用MAML初始化用户/项目嵌入,加速模型自适应,缓解冷启动问题。在5个真实数据集上的实验表明,IGCN在顺序推荐任务中可以优于最先进的CF方法。此外,与增量CF方法相比,IGCN表现出竞争效率。